动动发财的小手,点个赞吧!
什么是正则表达式?
正则表达式通常缩写为 regex,是处理文本的有效工具。本质上,它们由一系列建立搜索模式的字符组成。该模式可用于广泛的字符串操作,包括匹配模式、替换文本和分割字符串。
历史

数学家 Stephen Cole Kleene 在 20 世纪 50 年代首次引入正则表达式作为描述正则集或正则语言的表示法。
如今,正则表达式已成为程序员、数据科学家和 IT 专业人员的一项基本技能。
重要性
在深入研究如何使用这些正则表达式之前,让我们通过使用Python来看看它的不同应用范围,以激励我们自己。
-
数据验证:正则表达式对于验证不同类型的数据非常有用。 (电子邮件地址、电话号码) -
网页抓取:通过网页抓取数据时,可以使用正则表达式来解析 HTML 并隔离必要的信息。 -
搜索和替换:正则表达式擅长识别符合特定模式的字符串并用替代项替换它们。此功能在文本编辑器、数据库和编码中尤其有价值。 -
语法突出显示:许多文本编辑器使用正则表达式来进行语法突出显示。 -
自然语言处理 (NLP):在 NLP 中,正则表达式可用于标记化、词干提取和一系列其他文本处理函数等任务。 -
日志分析:在处理日志文件时,正则表达式可以有效地提取特定日志条目或分析一段时间内的模式。
现在我希望你有足够的动力!
让我们开始使用 re 模块,它是关于正则表达式的。
re 模块简介
Python 通过 re 模块提供对正则表达式的固有支持。
该模块是Python的标准库,这意味着您不必在外部安装它,它会随每个Python安装一起提供。
re 模块包含用于使用正则表达式的各种函数和类。一些函数用于匹配文本,一些函数用于分割文本,还有一些函数用于替换文本。
它包括为处理正则表达式而定制的各种函数和类。其中,某些函数被指定用于文本匹配,其余函数被指定用于文本分割或文本替换。
导入 re 模块
正如我们已经提到的,它附带安装,因此无需担心安装。
这就是为什么要开始在 Python 中使用正则表达式,您需要首先导入 re 库。您可以使用 import 语句来执行此操作,如下所示。
import re
导入库后,您可以启动 re 模块提供的函数和类等功能。
让我们从一个简单的例子开始。
假设您想要查找字符串中出现的所有单词“Python”。
我们可以使用 re 模块中的 findall() 函数。
这是代码。
import re
# Sample text
text = "Python is an amazing programming language. Python is widely used in various fields."
# Find all occurrences of 'Python'
matches = re.findall("Python", text)
# Output the matches
print(matches)
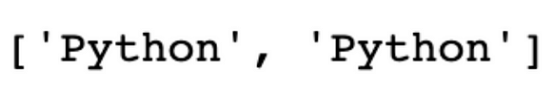
re 模块中有更多函数可以用来构建更复杂的模式。但首先,让我们看看 re 模块中的常用函数。
常用函数
在向您介绍 Python RegEx 的基础知识之前,我们先看看常用函数,以便更好地掌握其余概念。 re 模块包含许多不同的功能。通过使用它们,我们可以执行不同的操作。
在接下来的部分中,我们将发现其中的一些。

re.match()
re.match() 捕获正则表达式是否以特定字符串开头。
如果存在匹配,该函数返回一个匹配对象;如果没有,则不返回任何内容。
接下来,我们将使用 re.match() 函数。这里我们将检查字符串文本是否以单词“Python”开头。然后我们将结果打印到控制台。
import re
pattern = "Python"
text = "Python is amazing."
# Check if the text starts with 'Python'
match = re.match(pattern, text)
# Output the result
if match:
print("Match found:", match.group())
else:
print("No match found")
-
输出

输出显示模式“Python”与文本的开头匹配。
re.search()
与 re.match() 相比,re.search() 函数扫描整个字符串来搜索匹配项,如果发现匹配项,则生成一个匹配对象。
在下面的代码中,我们使用 re.search() 函数在字符串文本中的任意位置搜索单词“amazing”。如果找到该单词,我们将其打印出来;否则,我们打印“未找到匹配项”。
pattern = "amazing"
text = "Python is amazing."
# Search for the pattern in the text
match = re.search(pattern, text)
# Output the result
if match:
print("Match found:", match.group())
else:
print("No match found")
-
输出
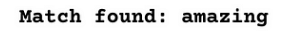
输出显示我们的代码从给定的文本中捕捉到了令人惊奇的结果。
re.findall()
re.findall() 函数用于收集字符串中某个模式的所有非重叠匹配项。它将这些匹配项作为字符串列表返回。
在下面的示例中,我们使用 re.findall() 函数查找字符串中的所有“a”。匹配项作为列表返回,然后我们将其打印到控制台。
pattern = "a"
text = "This is an example text."
# Find all occurrences of 'a' in the text
matches = re.findall(pattern, text)
# Output the matches
print(matches)
-
输出
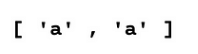
输出表示在我们的文本中找到的字母“a”的所有非重叠出现。
re.finditer()
re.finditer() 函数与 re.findall() 类似,但它返回一个迭代器,该迭代器产生匹配对象。
在下面的代码中,re.finditer()函数用于查找字符串文本中所有出现的字母“a”。它返回匹配对象的迭代器,我们打印每个匹配的索引和值。
pattern = "a"
text = "This is an example text."
# Find all occurrences of 'a' in the text
matches = re.finditer(pattern, text)
# Output the matches
for match in matches:
print(f"Match found at index {match.start()}: {match.group()}")
-
输出

输出显示文本中模式“a”的索引。
re.sub()
re.sub() 函数用于将一个字符串替换为另一个字符串。接下来,我们将使用 re.sub() 函数将“Python”替换为“Java”。然后我们打印修改后的字符串。
pattern = "Python"
replacement = "Java"
text = "I love Python. Python is amazing."
# Replace 'Python' with 'Java'
new_text = re.sub(pattern, replacement, text)
# Output the new text
print(new_text) # Output: "I love Java. Java is amazing."
-
输出

输出显示我们可以成功地将文本中的“Python”替换为“Java”。
本文由 mdnice 多平台发布





![[JavaWeb]MySQL的安装与介绍](https://img-blog.csdnimg.cn/18521df59daa490ba3133746a11d0499.png#pic_center)