前言
项目名:VITS-fast-fine-tuning (VITS 快速微调)
项目地址:https://github.com/Plachtaa/VITS-fast-fine-tuning
支持语言:中、日、英
官方简介:
这个代码库会指导你如何将自定义角色(甚至你自己),加入预训练的VITS模型中,在1小时内的微调使模型具备如下功能:
在 模型所包含的任意两个角色 之间进行声线转换
以 你加入的角色声线 进行中日英三语 文本到语音合成。
本项目使用的底模涵盖常见二次元男/女配音声线(来自原神数据集)以及现实世界常见男/女声线(来自VCTK数据集),支持中日英三语,保证能够在微调时快速适应新的声线。
数据集
干声数据收集
干声,一般指录音以后未经过任何空间性质或的后期处理和加工的纯人声。
为了保证最好的合成效果,数据集越干净越好。当然也不是必须使用干声数据,也可以使用从视频中分离的人声来进行训练,效果也还可以。
录制可以直接使用手机进行录音,如果电脑有效果较好的麦克风,也可以使用麦克风进行录制(如果可以自定义录制音频格式,建议选择wav)。
如果进行视频人声分离,我这给大家推荐几个分离相关的网站和项目。
-
vocalremover:https://vocalremover.org/zh/

-
tme_studio:https://y.qq.com/tme_studio/index.html#/editor
-
UVR5:https://github.com/Anjok07/ultimatevocalremovergui
-
demucs:https://github.com/facebookresearch/demucs
音频转码
将音频转码为wav格式,码率等配置保持原始音频质量即可。可以使用格式工厂、ShanaEncoder等转码软件进行音频转码。
音频分割
将我们的音频数据切分成多个5-15s的小段,这个范围仅供参考。需要注意的是,如果音频时长过长,在训练过程中会占用更多的显存,所以为了降低显存和显卡负担,建议大家切分成小段。
那么切分方式同样也多种多样,可以使用视频剪辑软件、音频编辑软件、格式转换软件、第三方软件等。
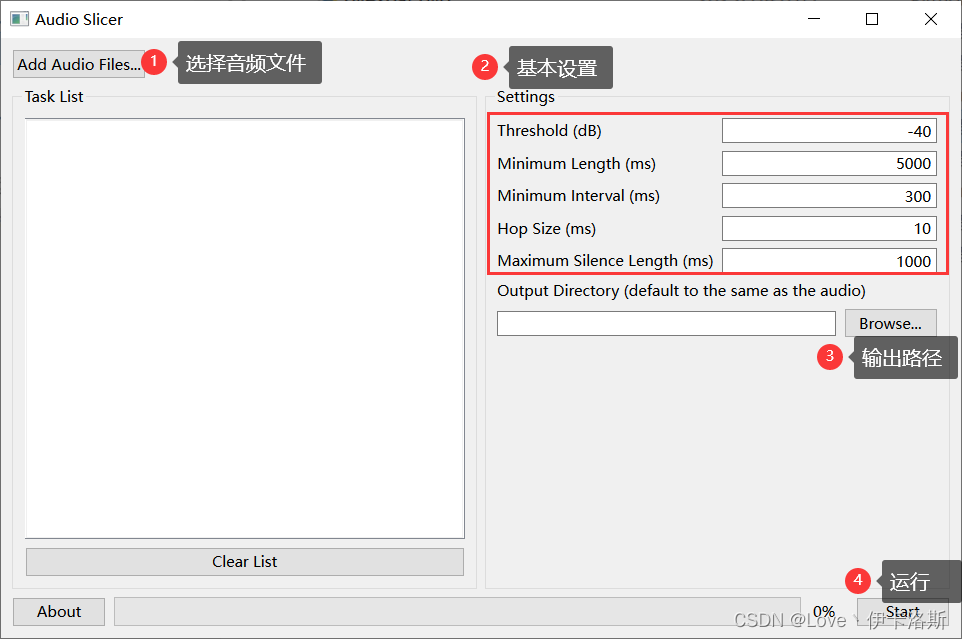
我这边就以windows用户为例,给大家推荐一款开源的音频批量自动分割软件slicer-gui(源自b站),官方下载地址:https://github.com/flutydeer/audio-slicer/releases/download/v1.1.0/slicer-gui-windows-v1.1.0.zip
下载完成,解压后打开,运行slicer-gui.exe

选择待处理的音频文件,设置需要切分的音频参数,选择输出路径,点击start即可。默认配置运行也可以,视情况可以微调参数。(需要注意,软件需要
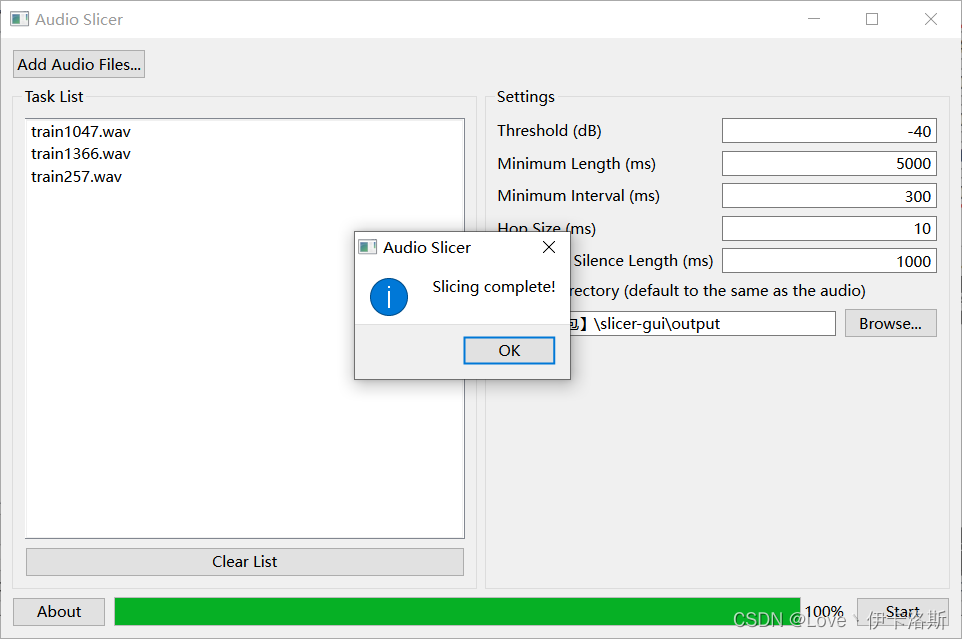
完成以上分割后,我们将我们分割好的音频文件,存入一个文件夹中,需要注意的是,此文件夹的命名就是我们训练时的说话人配置,所以需要慎重取名,并不要和其他说话人重复。最后将存放音频的文件夹再存入一个名为:custom_character_voice 的文件夹中,最后打包压缩包即可。需要注意,此文件夹在源码中是默认的配置,所以建议大家保持一致,可以避免不必要的麻烦。那么最终的文件目录结构如下:
custom_character_voice
├───speaker0
│ ├───1.wav
│ ├───...
│ └───2.wav
└───speaker1
├───1.wav
├───...
└───2.wav
环境搭建
服务器选购
本文中,以AutoDL平台为例,如果您的个人计算机显卡显存在4GB及以上(建议4GB+),可以使用个人来进行训练。
AutoDL官网:https://www.autodl.com/home
完成注册后,我们选购一台合适的服务器,我这以Tesla T4为例(期间的付费实名等操作这里不做展开)。
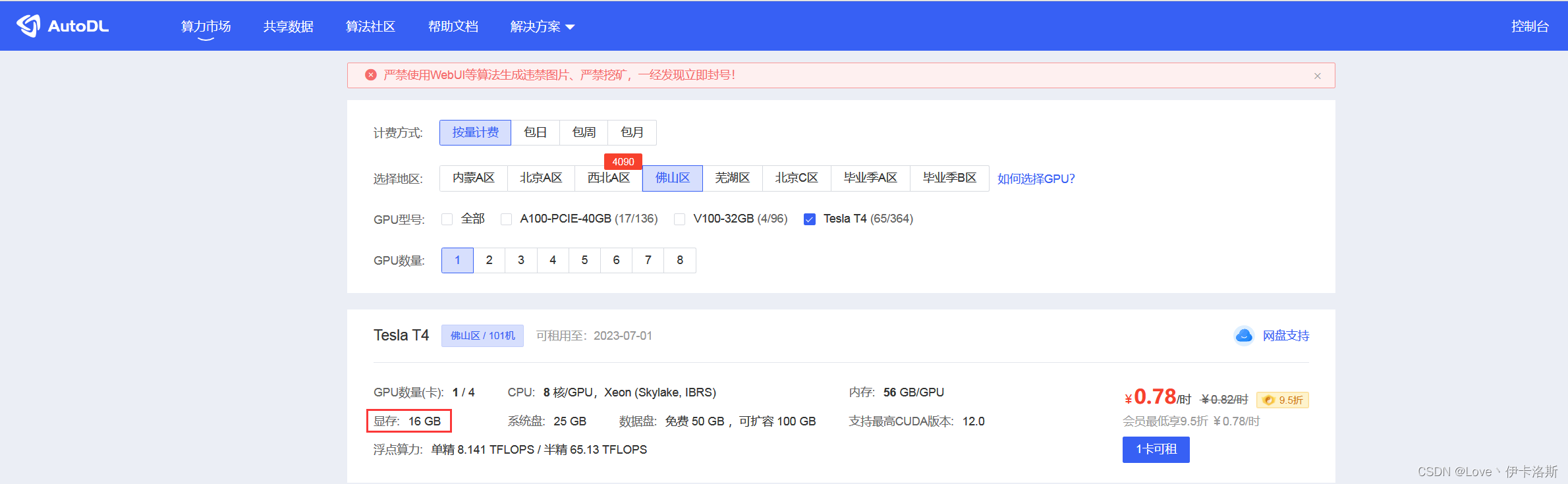
服务器购买后,可以使用镜像,平台社区有很多作者发布了自己的镜像,可以搜索vits查找相关镜像。选择做好的镜像可以大大降低我们的环境部署的时间。大家可以直接选择以下的vits-fast的镜像,然后运行我们的服务器。
开机后,在右上角控制台,容器实例中,我们可以看到我们的服务器的相关信息。
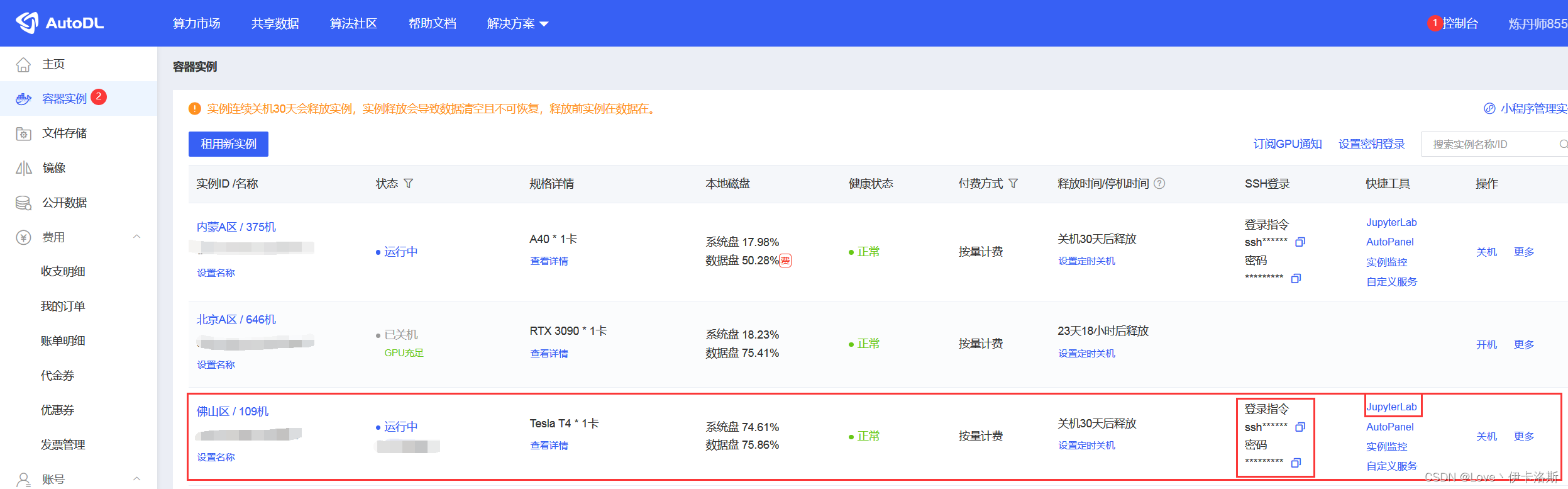
点击JupyterLab,打开在线面板,再打开终端。

运行环境和前期准备
由于我选择的镜像是so-vits-svc-v10,会有些许出入,但整体不会对项目运行使用造成影响。
python:3.8.10
我们先安装git,在终端运行命令sudo apt install git -y
然后clone项目到/root目录。(注意,如果您选择的VITS-fast-fine-tuning的镜像,那可能需要先删除默认的VITS-fast-fine-tuning文件夹,重新clone项目)
git clone https://github.com/Plachtaa/VITS-fast-fine-tuning.git
如果您没有选择做好的官方镜像,则需要手动安装相关环境,具体可以参考官方笔记:https://colab.research.google.com/drive/1pn1xnFfdLK63gVXDwV4zCXfVeo8c-I-0?usp=sharing
1. 安装运行环境
cd VITS-fast-fine-tuning
python -m pip install --upgrade --force-reinstall regex
python -m pip install --upgrade --force-reinstall numba
python -m pip install --force-reinstall soundfile
python -m pip install --force-reinstall gradio
python -m pip install imageio==2.4.1
python -m pip install --upgrade youtube-dl
python -m pip install moviepy
python -m pip install -r requirements.txt
python -m pip install --upgrade pyzmq
cd monotonic_align/
mkdir monotonic_align
python setup.py build_ext --inplace
cd ..
mkdir pretrained_models
wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip
unzip sampled_audio4ft_v2.zip
mkdir video_data
mkdir raw_audio
mkdir denoised_audio
mkdir custom_character_voice
mkdir segmented_character_voice
2.下载预训练模型(以下步骤如果不进行训练,皆可以跳过)
可以根据自己的需求下载对应的模型,不一定全部都下载。
mkdir pretrained_models/{C,CJ,CJE}
wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/D_0-p.pth -O ./pretrained_models/CJ/D_0.pth
wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/G_0-p.pth -O ./pretrained_models/CJ/G_0.pth
wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/config.json -O ./pretrained_models/CJ/finetune_speaker.json
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth -O ./pretrained_models/CJE/D_0.pth
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth -O ./pretrained_models/CJE/G_0.pth
wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json -O ./pretrained_models/CJE/finetune_speaker.json
wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/D_0.pth -O ./pretrained_models/C/D_0.pth
wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/G_0.pth -O ./pretrained_models/C/G_0.pth
wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/config.json -O ./pretrained_models/C/finetune_speaker.json
下载好后,需要将配置文件和预训练模型移动到指定路径,我这里提供了shell脚本,您可以创建名为 init.sh 的文件,贴入以下内容,然后通过 bash init.sh CJE 来运行脚本,选择需要使用的预训练模型。最后就是预训练模型的传参,分别是 CJE、CJ、C。
#!/bin/bash
if [ "$1" = "CJE" ]
then
cp -rf pretrained_models/CJE/* pretrained_models/
rm -rf OUTPUT_MODEL/*
#rm -rf custom_character_voice/*
cp -rf pretrained_models/CJE/finetune_speaker.json configs/
elif [ "$1" = "CJ" ]
then
cp -rf pretrained_models/CJ/* pretrained_models/
rm -rf OUTPUT_MODEL/*
#rm -rf custom_character_voice/*
cp -rf pretrained_models/CJ/finetune_speaker.json configs/
elif [ "$1" = "C" ]
then
cp -rf pretrained_models/C/* pretrained_models/
rm -rf OUTPUT_MODEL/*
#rm -rf custom_character_voice/*
cp -rf pretrained_models/C/finetune_speaker.json configs/
else
cp -rf pretrained_models/CJE/* pretrained_models/
rm -rf OUTPUT_MODEL/*
#rm -rf custom_character_voice/*
cp -rf pretrained_models/CJE/finetune_speaker.json configs/
fi
3.上传数据集并解压
将我们前面准备好的数据集上传到服务器中
然后使用unzip命令(如果没有可以使用apt安装),解压到项目路径中,注意图片路径

4.数据预处理
我这里提供了shell脚本,您可以创建一个data_pre.sh的文件,将以下内容写入,然后使用bash data_pre.sh 运行,第一个传参是选择训练的目标语言(需要有配套的预训练模型),第二个传参为0表示不使用预训练模型,直接进行训练,非0则使用预训练模型。例如: bash data_pre.sh CJE 就是使用预训练模型CJE训练CJE三语模型。
#!/bin/bash
if [ $# -eq 1 ]; then
lang=$1
else
lang=CJE
fi
python scripts/video2audio.py
python scripts/denoise_audio.py
python scripts/long_audio_transcribe.py --languages "$lang" --whisper_size large
python scripts/short_audio_transcribe.py --languages "$lang" --whisper_size large
python scripts/resample.py
if [ "$2" = "0" ]
then
python preprocess_v2.py --languages "$lang"
else
python preprocess_v2.py --add_auxiliary_data True --languages "$lang"
fi
训练
在完成运行环境和前期准备后,则可以进行我们的训练了。
打开终端,在项目根目录运行以下命令即可,其中 -m 后为模型输出路径, --max_epochs 后为最大迭代次数,到达后会自动停止。您可以根据自己需求自行更改,默认为存储在 OUTPUT_MODEL文件夹中,训练100个迭代。
mkdir OUTPUT_MODEL
python finetune_speaker_v2.py -m "./OUTPUT_MODEL" --max_epochs "100" --drop_speaker_embed True
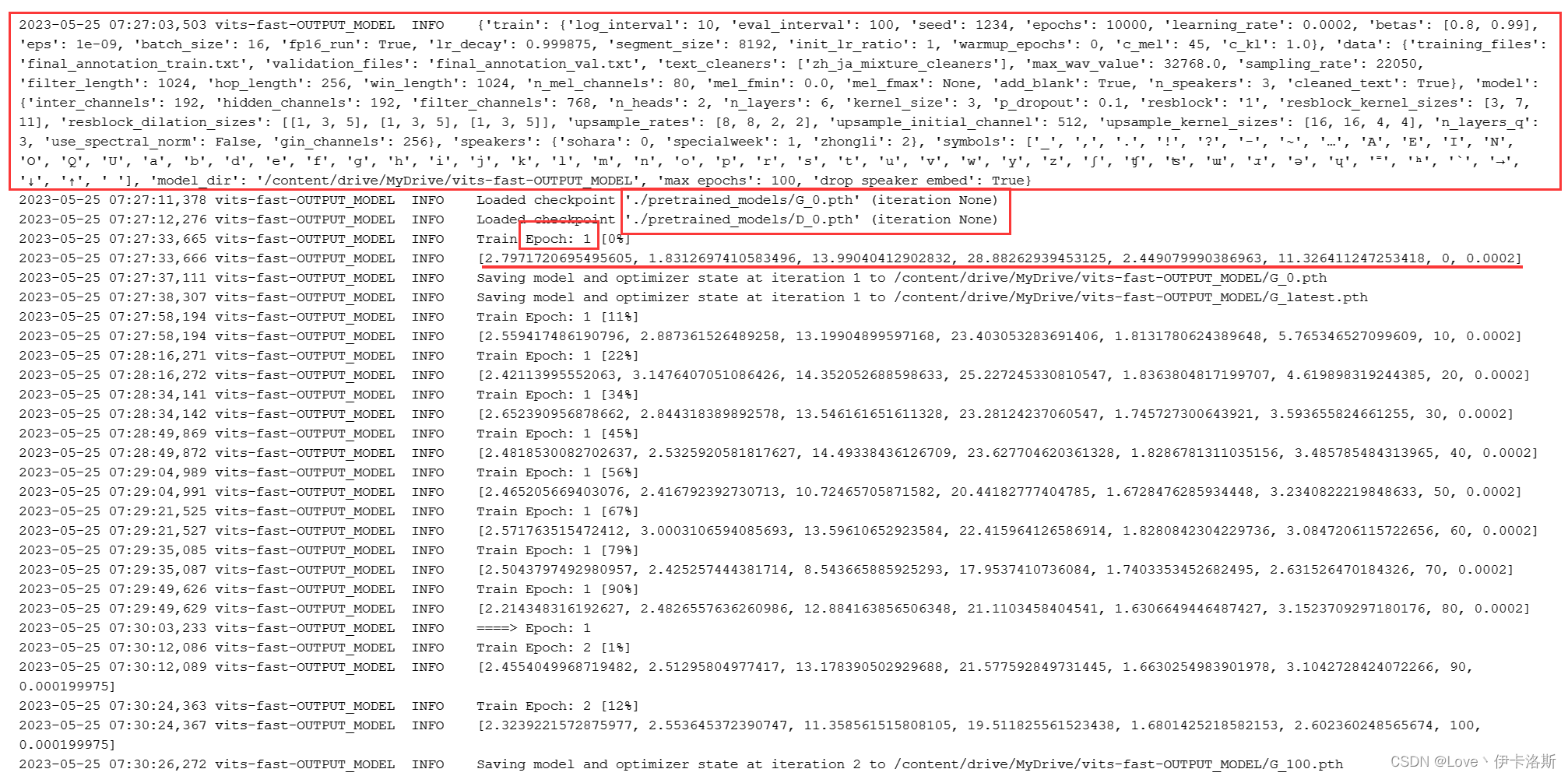
下面是训练日志内容,可以看到训练相关的配置,迭代次数,损失率,输出的模型等内容。等待训练完成即可,期间也可以随时终止训练。
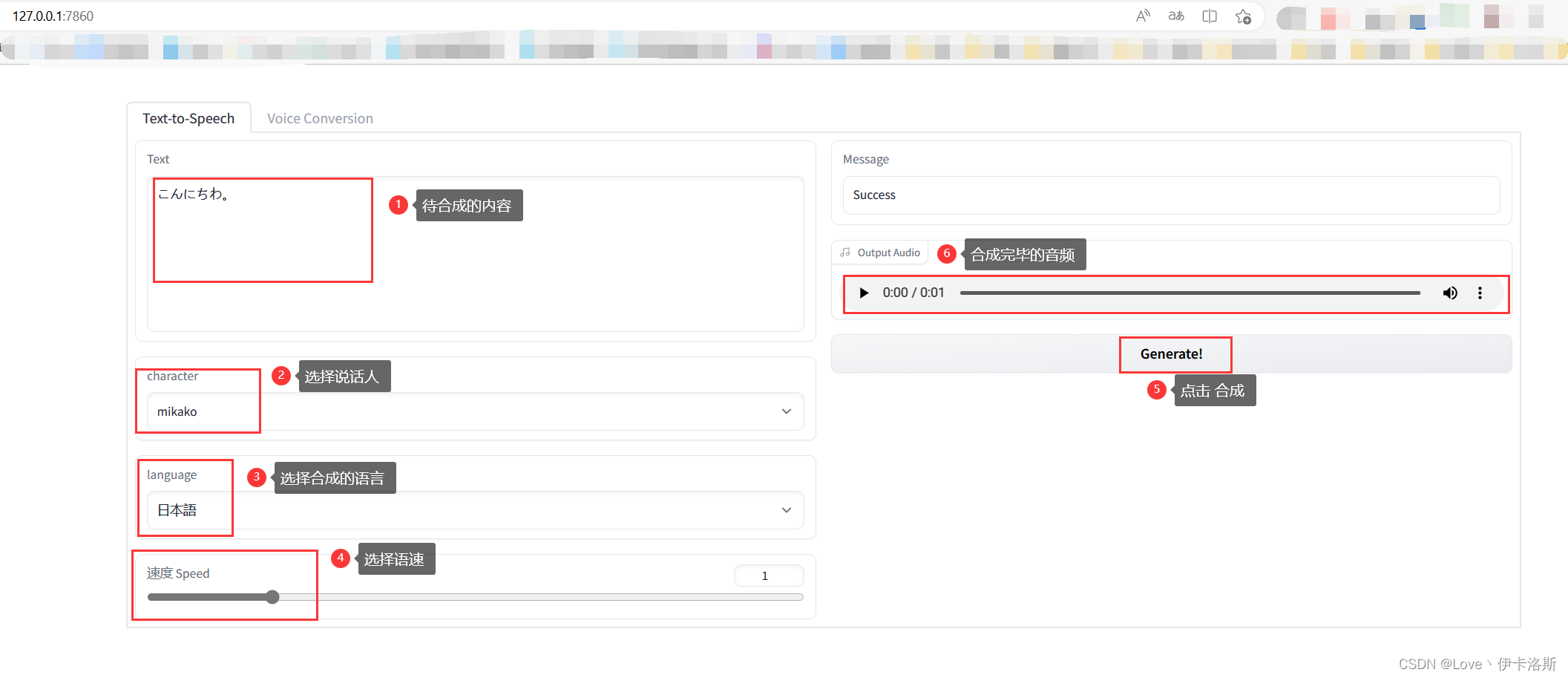
推理合成
将我们的模型和配置文件放到指定文件夹下(配置文件放到项目根目录,模型放到OUTPUT_MODEL文件夹下),项目根目录运行以下命令,打开web UI服务,进行推理。其中 --model_dir 后就是模型路径,可以自行修改,配置文件默认读取的 项目路径下的 finetune_speaker.json 。
需要注意的是,默认服务跑在 http://127.0.0.1:7860,如果您需要公网访问,可以做修改端口至6006,开放AutoDL对应实例的自定义服务功能,或者自建内网穿透。
python VC_inference.py --model_dir ./OUTPUT_MODEL/G_latest.pth --share True
为了方便,可以在个人电脑上进行合成,将模型和配置文件下载到本地,然后使用官方提供的windows合成包,下载链接:https://github.com/Plachtaa/VITS-fast-fine-tuning/releases/download/webui-v1.1/inference.rar
解压后,将我们的模型和配置文件都放到解压后的根目录内,模型改名为G_latest.pth,配置文件改名为finetune_speaker.json,运行inference.exe即可自动加载。
页面简单易懂,就可以尽情合成了。