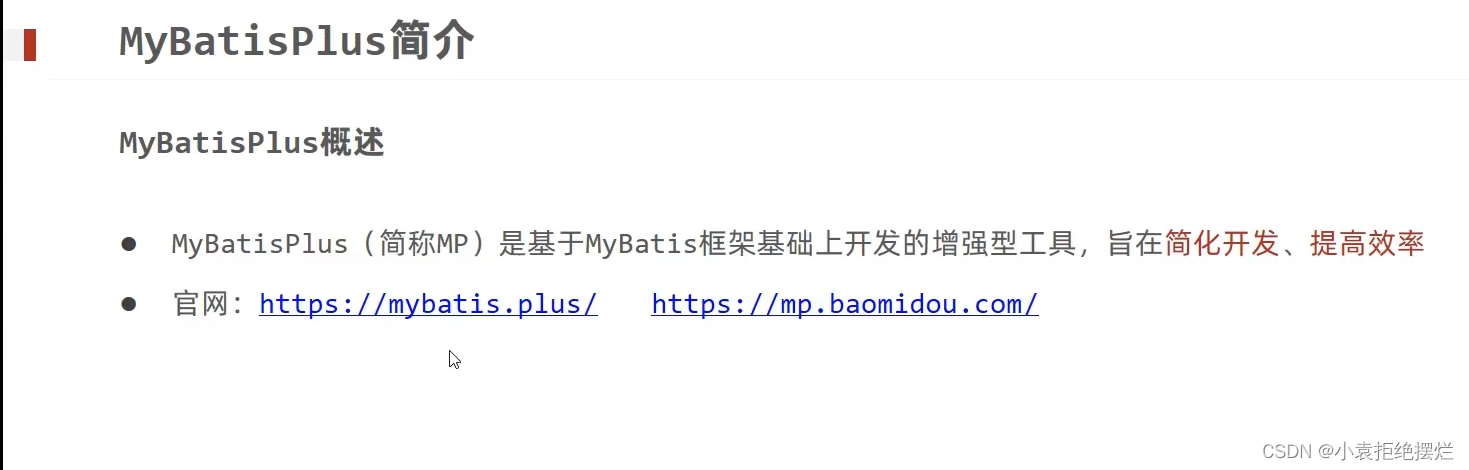
MyBatisPlus(简称MP)
这篇博客主要讲解用MyBatisPlus进行三层架构中Dao层的开发
以这个为目的来进行我们的学习
我们会先通过一个概述和入门案例进行快速上手
之后我们再通过对我们原先的案列的问题进行分析
来进一步了解MP操作数据库的知识
快速入门
MP简介
MP是国人开发的插件,so他那个官网不是有点像拼音,他就是拼音
baomidou
他是在mybatis基础上做增强
不影响你原来mybatis使用,一下特殊需求肯定还是要我们用mybatis做自己实现的

案例
基于SpringBoot进行开发
就大致两件事
创建工程以及对应实体类
导入配置文件后,将对应的实体类和我们的配置进来的jar包新技术结合一下(其实是先导入依赖,然后直接写集合后的类)
1.创建工程
这里我们只练习MP,so不导入Web
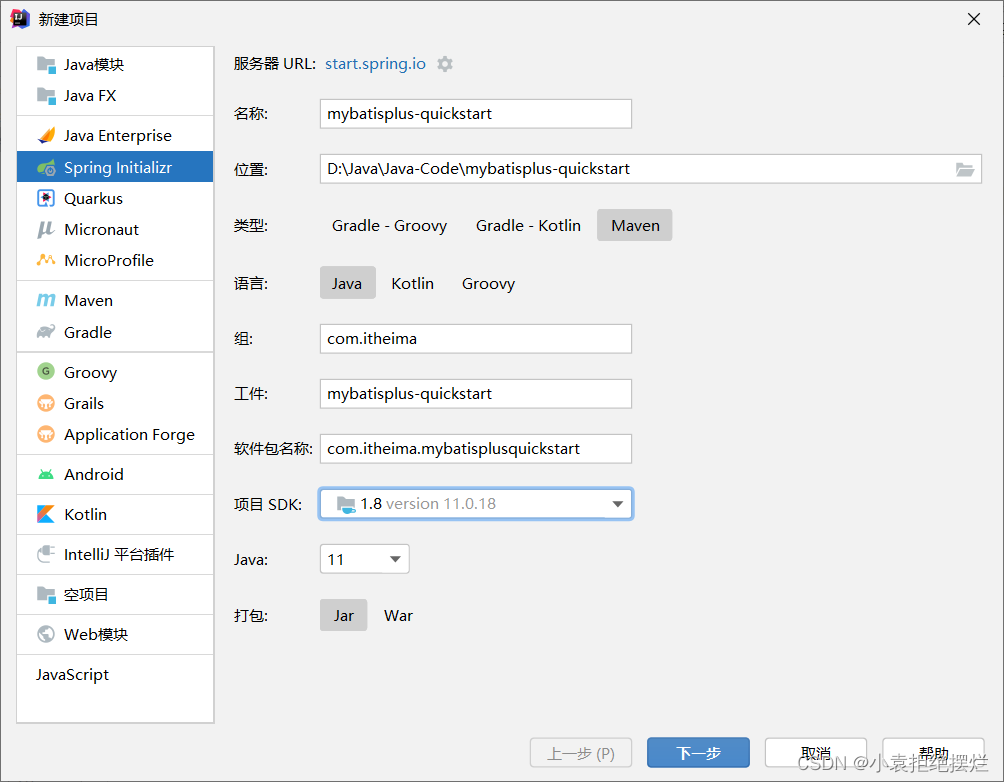
这个创建的依赖项是没有MP选项的,我们需要后期手动加
这里就Mysql和Lombok即可
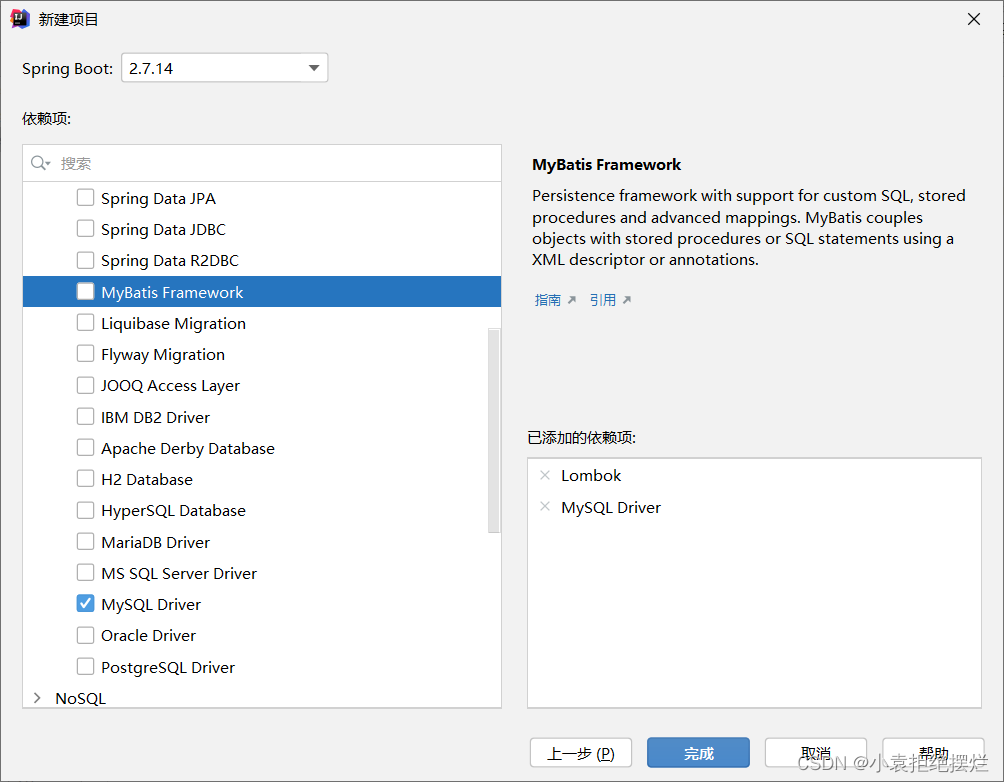
2.写入对应的依赖
德鲁伊连接池的和mybatisplus的起步依赖
注意:利用maven的多重继承,MP依赖下面有一个mybatis的依赖(我们就不需要导入了),所以是是依赖着mybatis开发的,仔细看还能看见JDBC(本来JDBC就是最底层)
<!--myBatisPlus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!--德鲁伊连接池依赖导入 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>
3.写SpringBoot的配置文件和类
配置文件改成yml文件
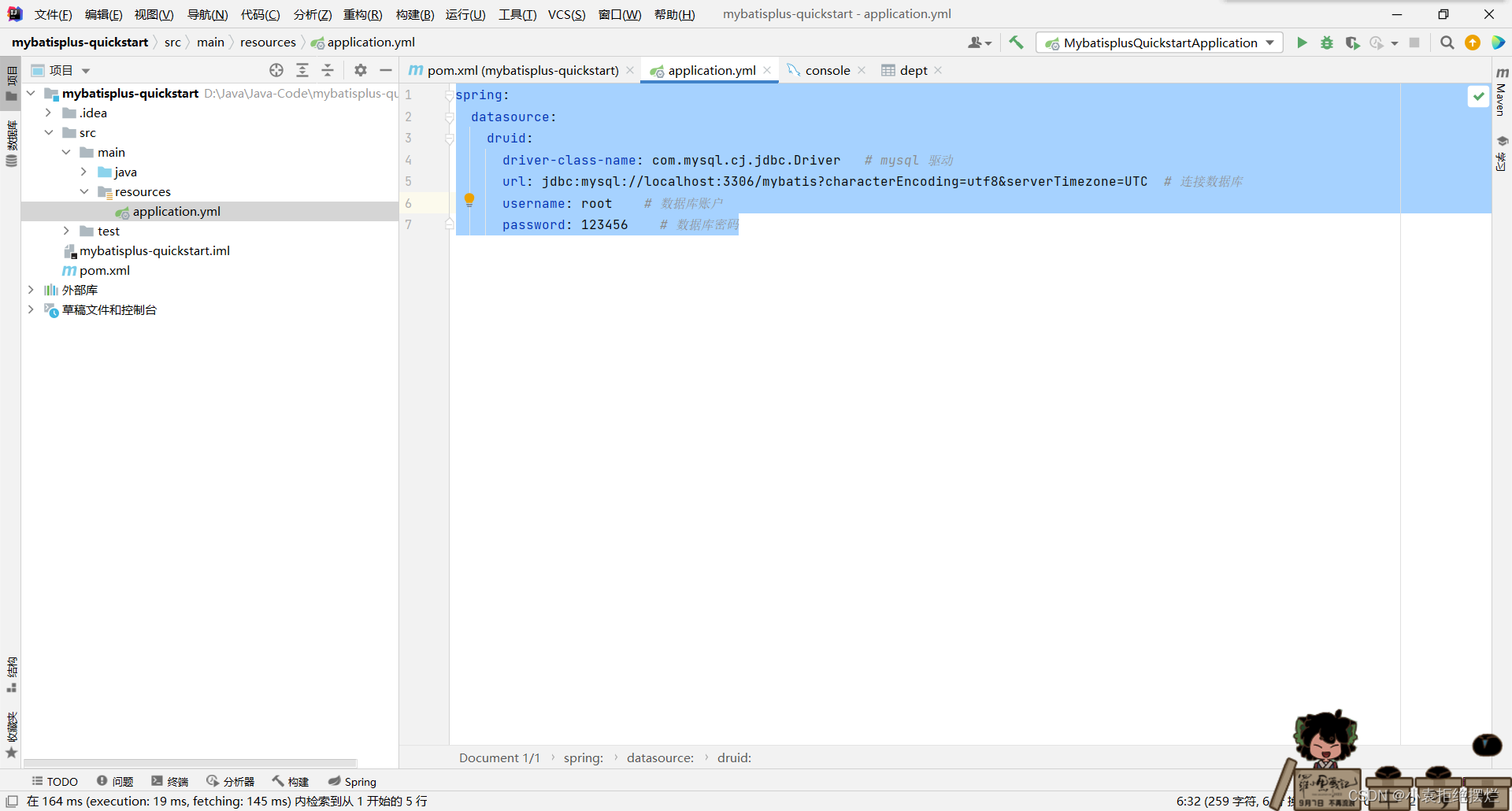
代码格式是固定的,自己搜搜,然后改成自己得的信息
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver # mysql 驱动
url: jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf8&serverTimezone=UTC # 连接数据库
username: root # 数据库账户
password: 123456 # 数据库密码
实体类
对应的表
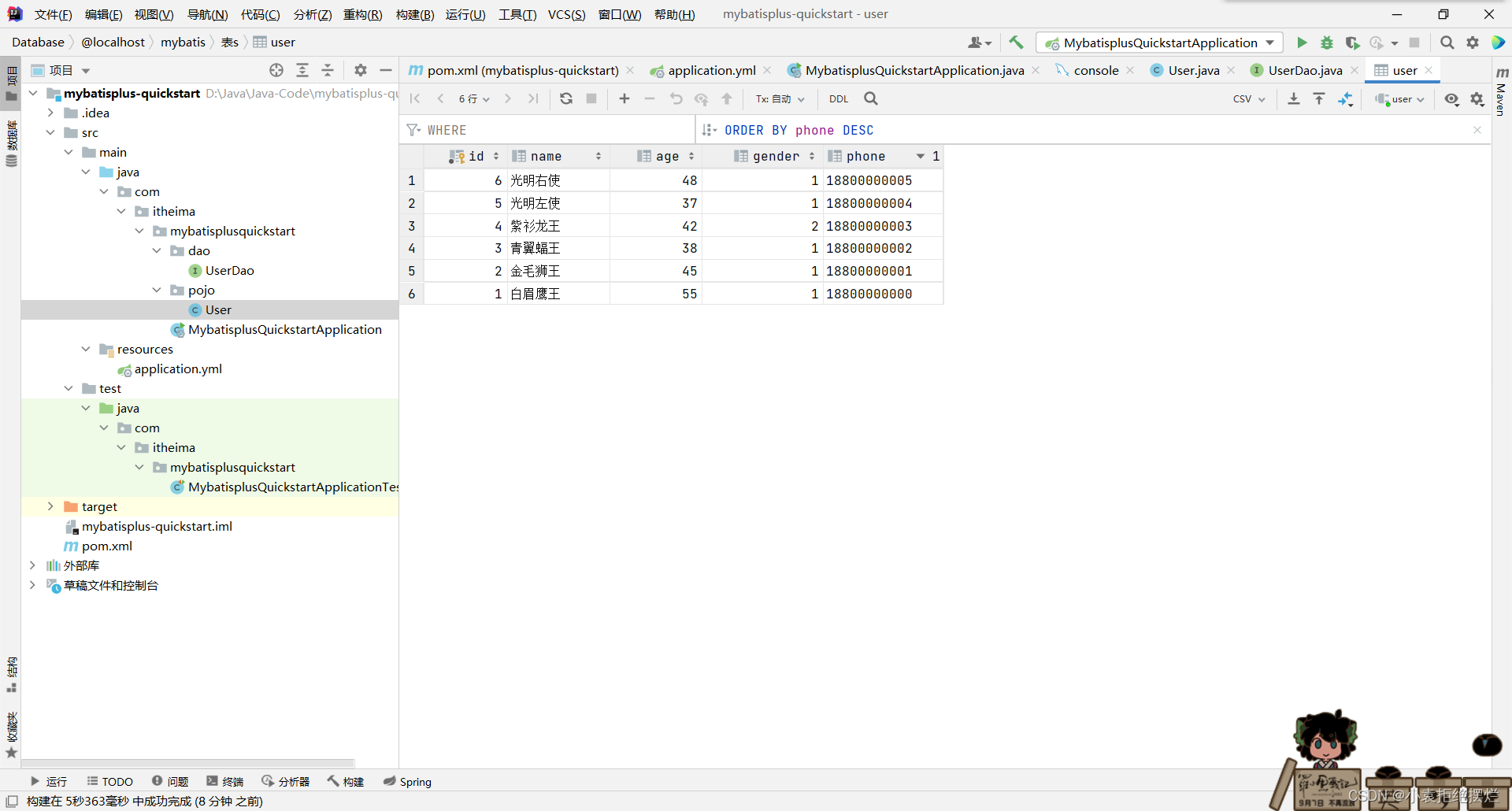
important point
看我们这里的接口定义
我们直接继承BaseMapper然后泛型写上我们的实体类
然后就不用做了,他会自动帮我们配置对应的有一些比较简答的方法
之前mybatis是需要你写方法和语句的,而这个有一些已经配置好的
4.测试
可以发现计算我们没有写,他也是有一些方法的
芜湖,成功输出我们的数据

就这样其实挺简单的一个入门程序
MP提供的功能
一些标准功能
CRUD
这是对于的实验mybatis和MP的方法对应
MP实现了我们对于表的基本CRUD功能
这些功能就不用自己定义了

那我们来测测呗
1.insert
返回的应该是变动的数据条数
数据库成功变化
忘了设置gender了,等会改一下
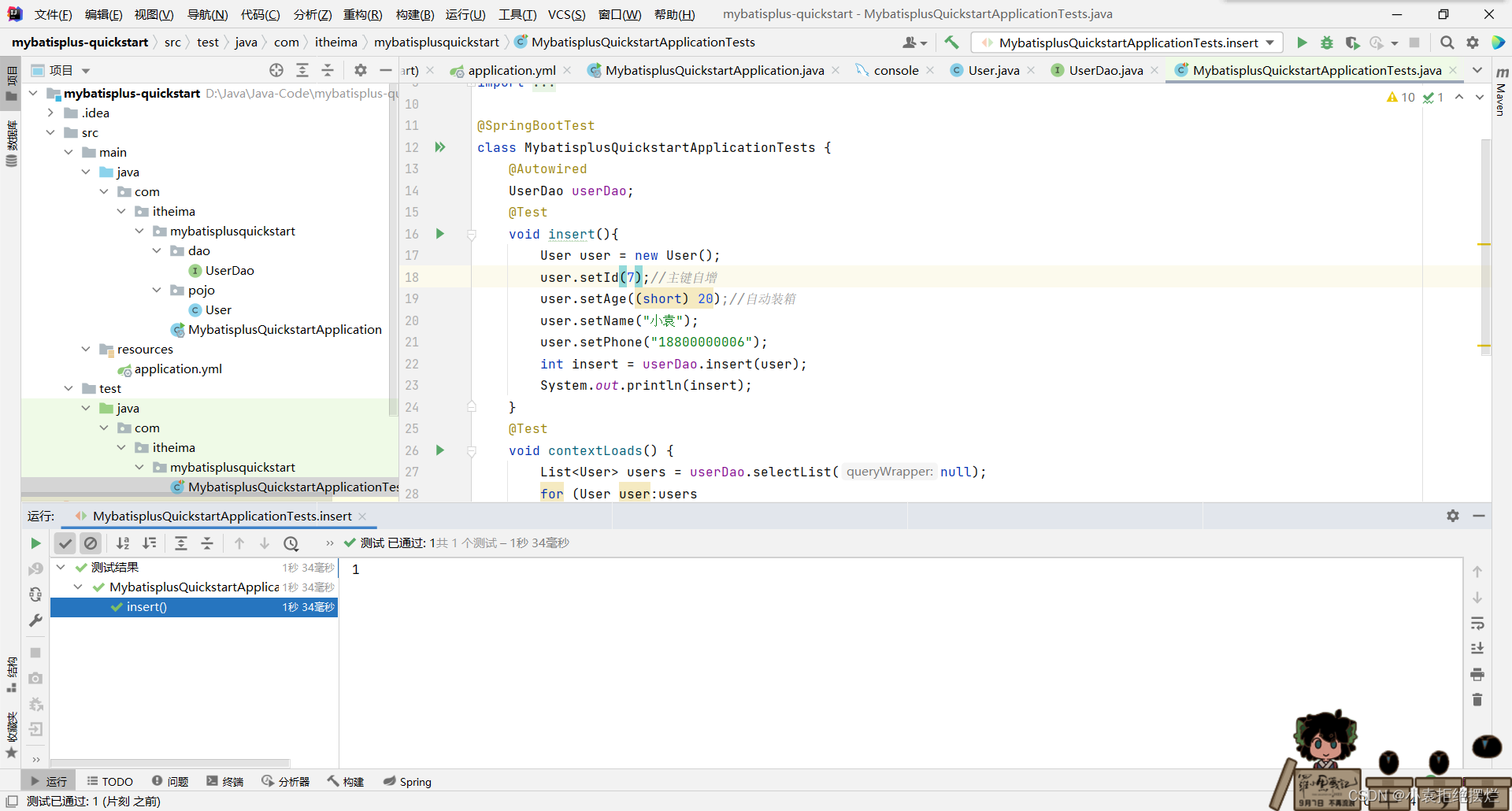
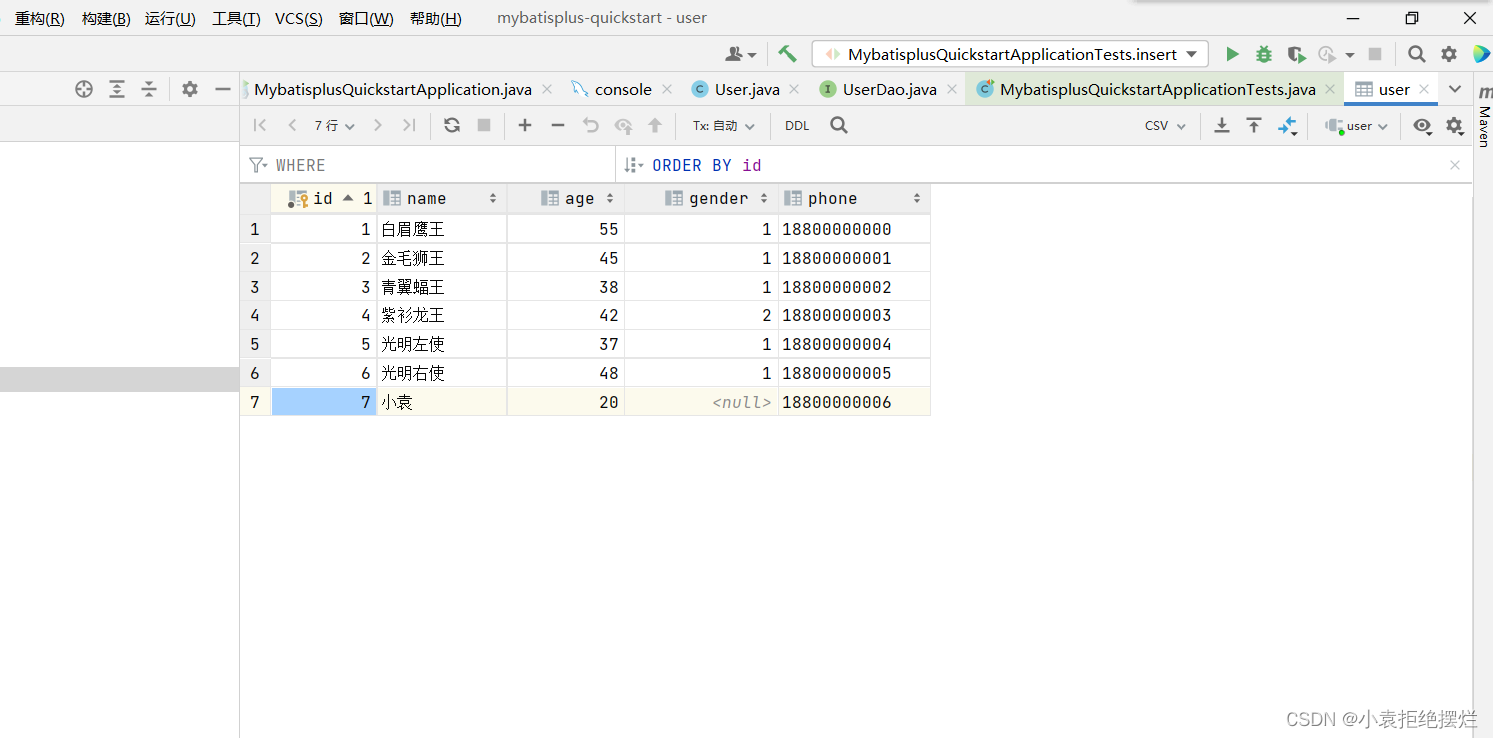
值得注意的就是我没有设置ID1的话,他会操作,但是不是因为没有ID,而是因为太大了超出了Integer的范围,我们给换成Long,再把Mysql表里的换成bigint即可添加成功
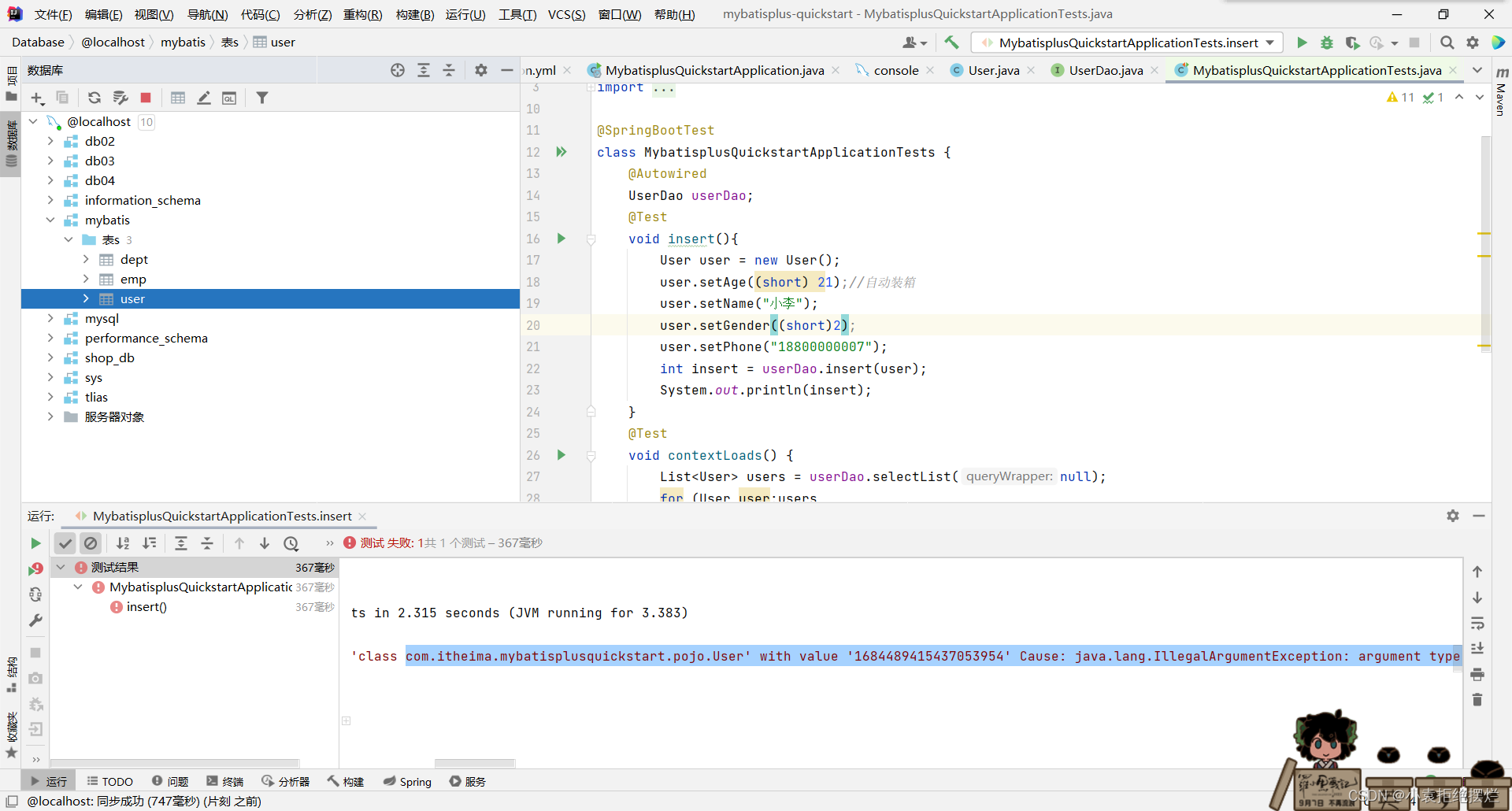
但你会发现这个ID还不是自增长的,它本身内部有一个算法,等会我们讲解一下
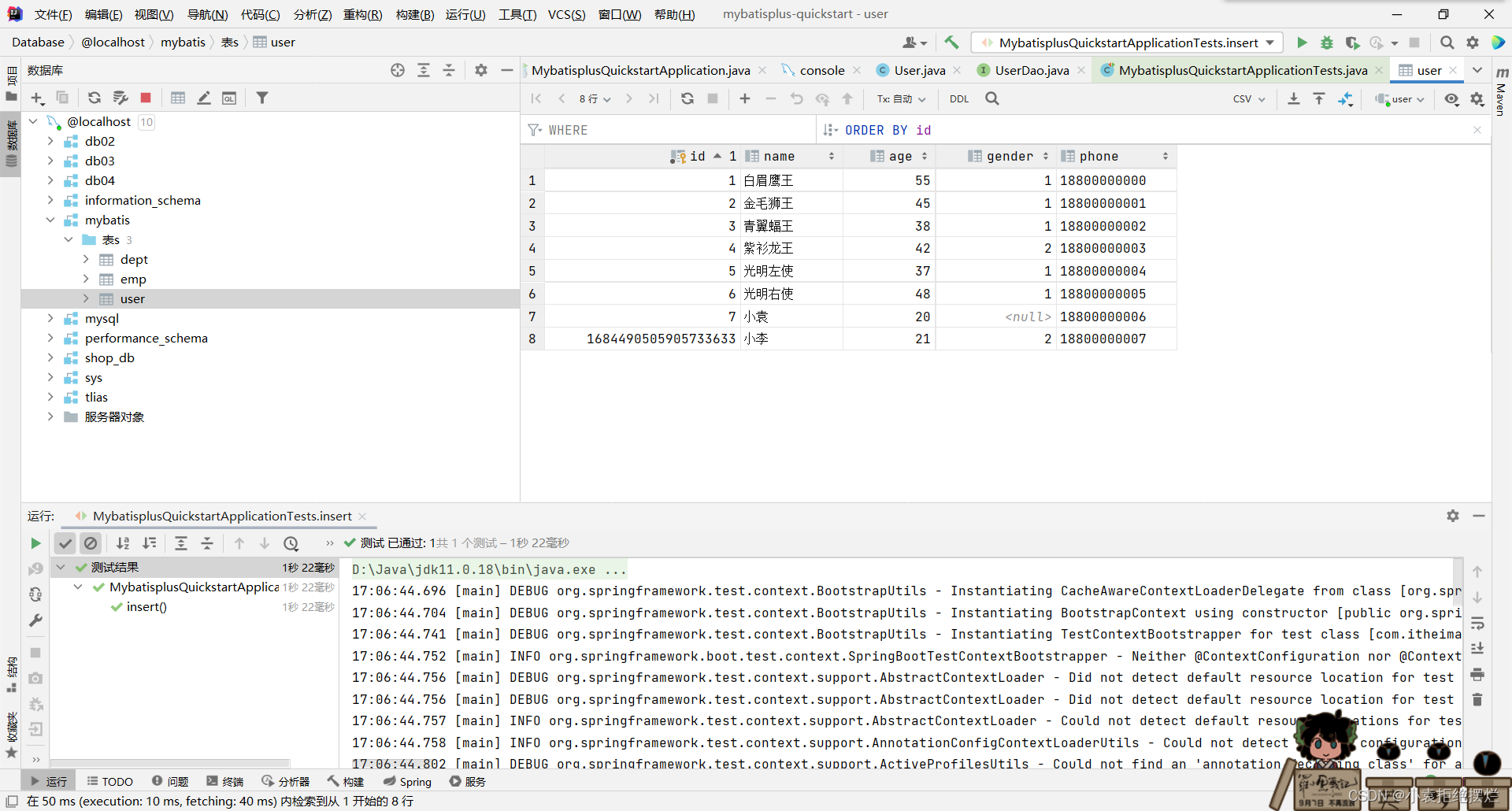
测试删除
代码
@Test
void delete(){
int i = userDao.deleteById(Long.valueOf("1684490505905733633"));
System.out.println(i);
}
测试结果
同样返回的是修改的条数
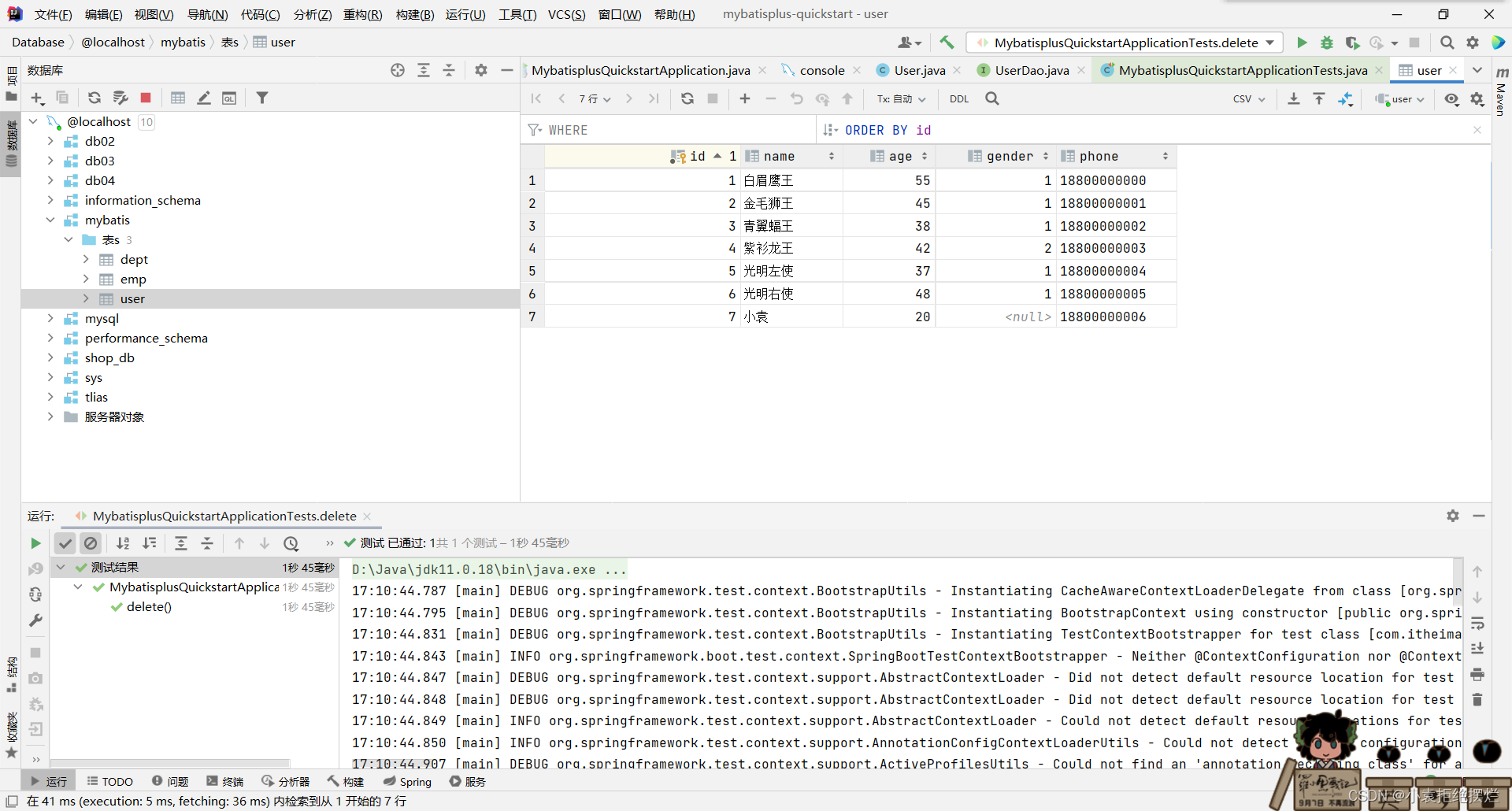
3.测试修改
@Test
void update(){
User user = new User();
user.setId(7L);//数据后加L代表Long类型!!!
user.setGender((short)1);
userDao.updateById(user);
}
修改成功
但是想想我们之前做修改是很麻烦的
还要判断什么是不是null,是null的话不进行替换,不是的话进行替换
他都给设置好了,没值就不会修改对应项
对应的select上面也也有
selectById我有也就不演示了
那这些功能怎么来的呢?
答案显而易见,继承来的
继承我们BaseMapper的类实现的功能
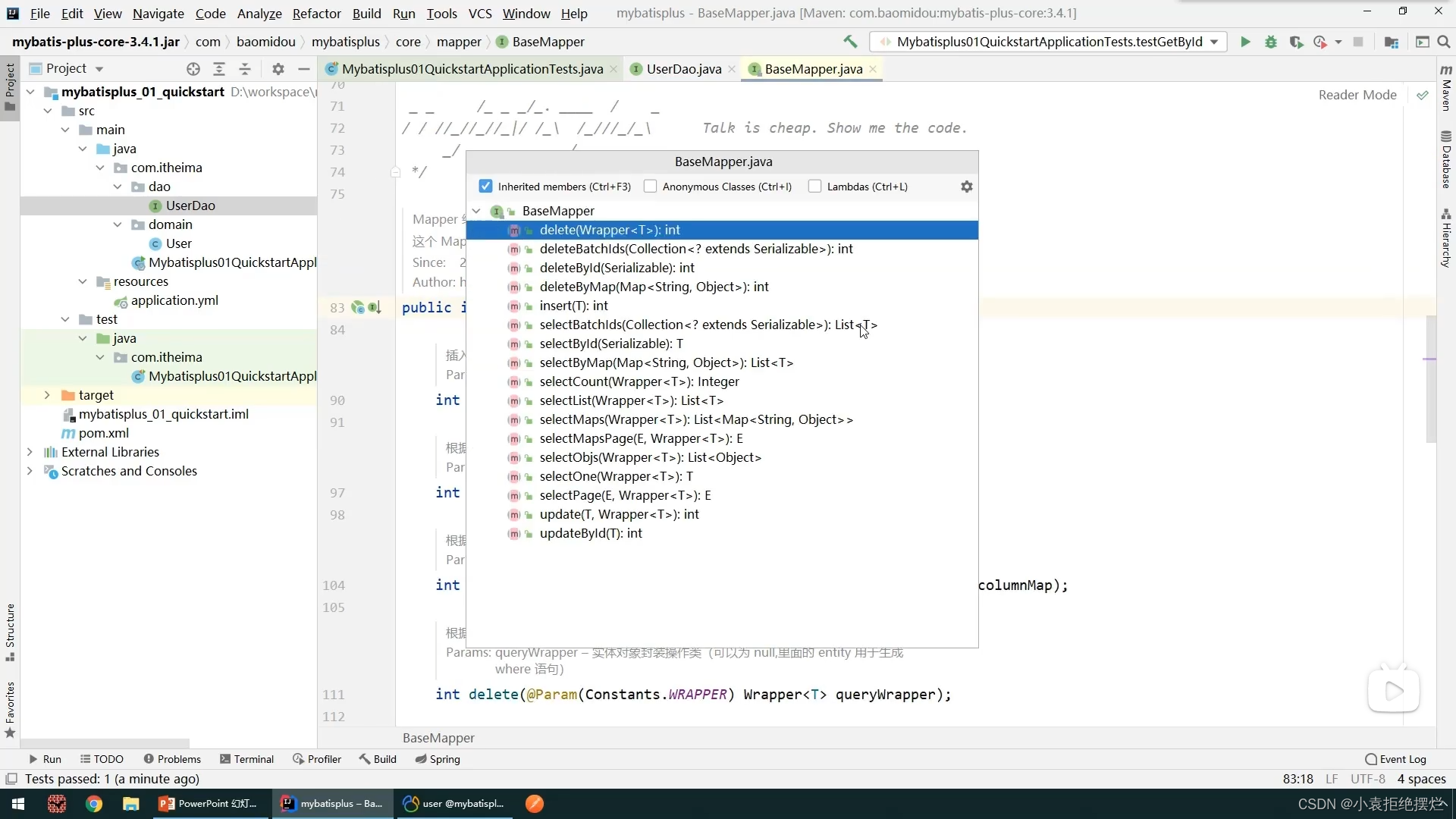
分页查询功能(带Mp分页拦截器)
MP里是有这个功能的,对应的方法的效果如图
@Test
void PageSelect(){
IPage<User> page = new Page<>(1,2);
IPage<User> page1 = userDao.selectPage(page, null);
System.out.println("当前页码"+page1.getCurrent());
System.out.println("每页显示数"+page1.getSize());
System.out.println("一共多少页"+page1.getPages());
System.out.println("一共多少条"+page1.getTotal());
System.out.println("真正的数据"+page1.getRecords());
}
但是运行出来的结果,还是查询全部的数据,而且对应页数和条数为0
想想select分页查询,其实也就是在select * from user 后加上
limit 第几条数据开始,一个查询的数据条数
我们MP底层是用拦截器来做的,拦截并增强(AOP)
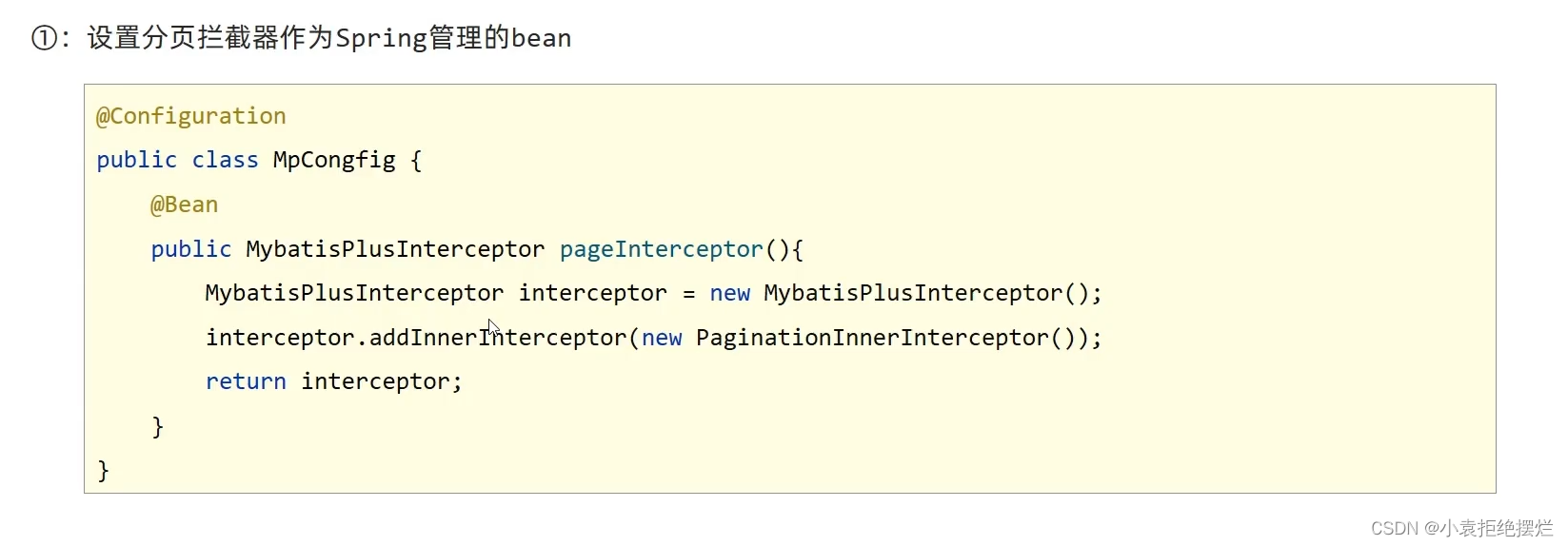
so需要配置拦截器开启MP提供的分页拦截器
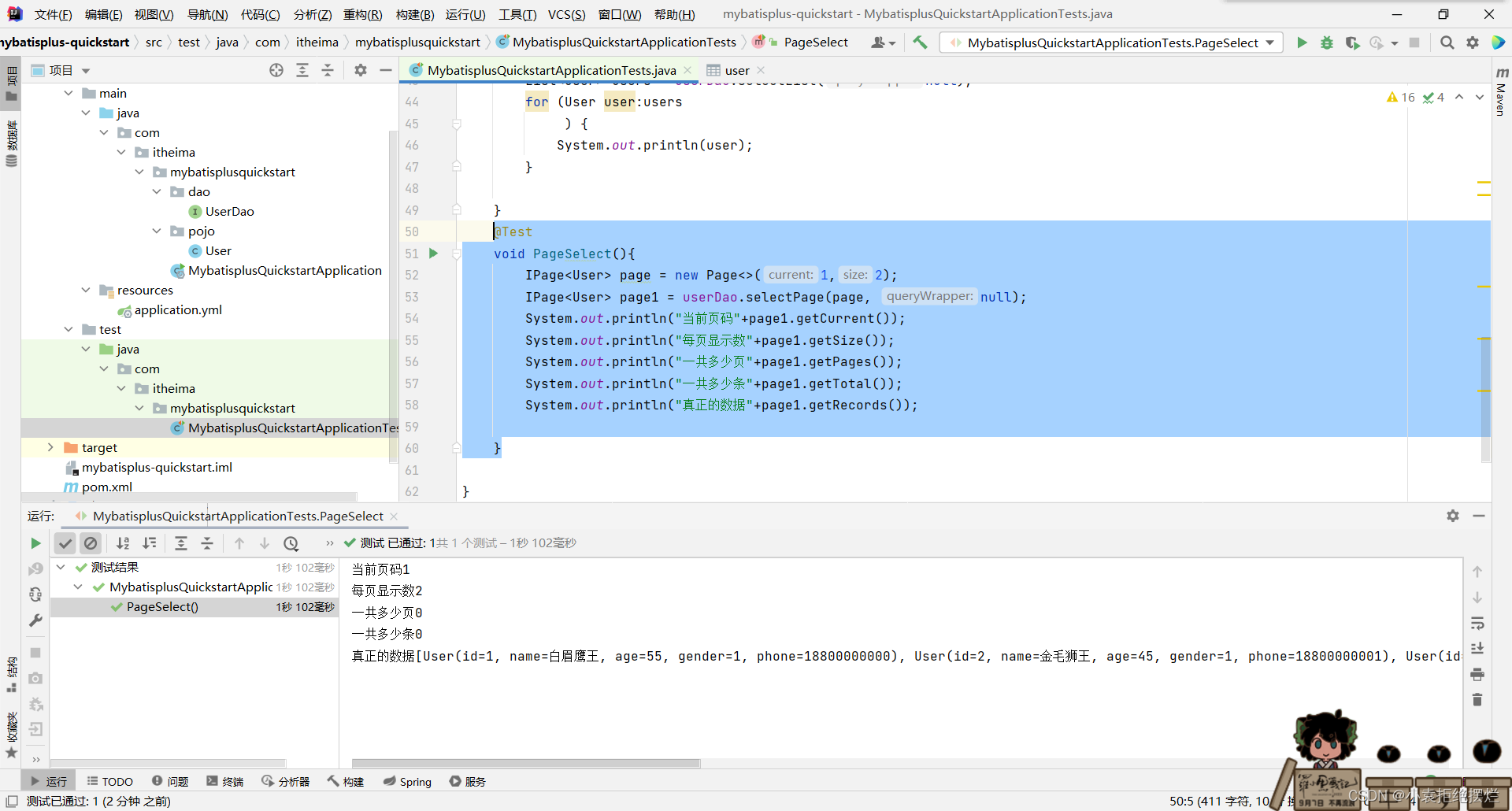
mpInterceptor拦截器
我们定义一个拦截器
bean注释,可以用@import不过我这里直接配置类了
public class MpConfig {
@Bean
@Configuration
public MybatisPlusInterceptor mpInterceptor(){
//1.定义Mp拦截器
MybatisPlusInterceptor mpInterceptor = new MybatisPlusInterceptor();
//2.添加具体的拦截器
mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mpInterceptor;
}
}
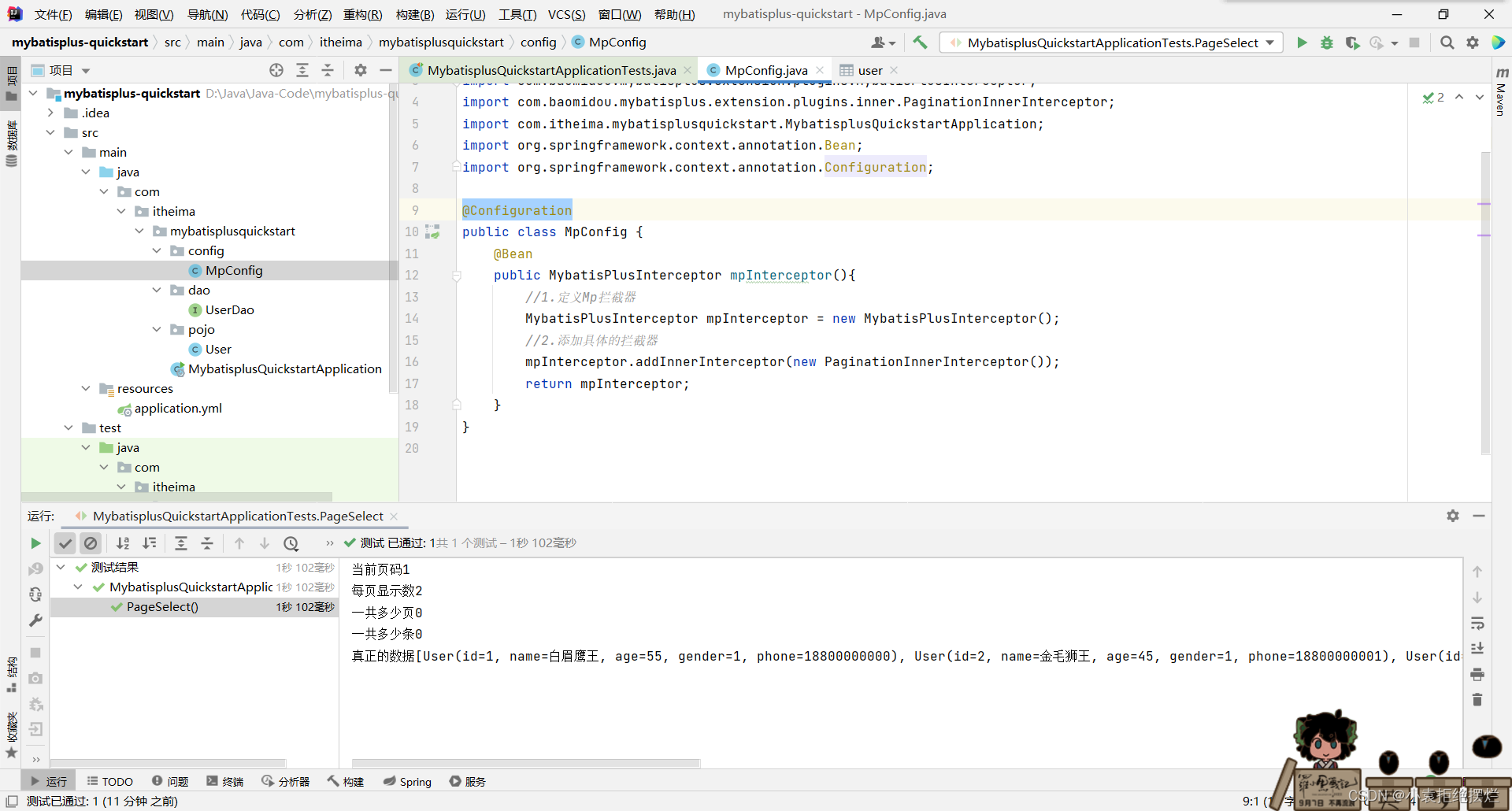
现在就能正常查询了
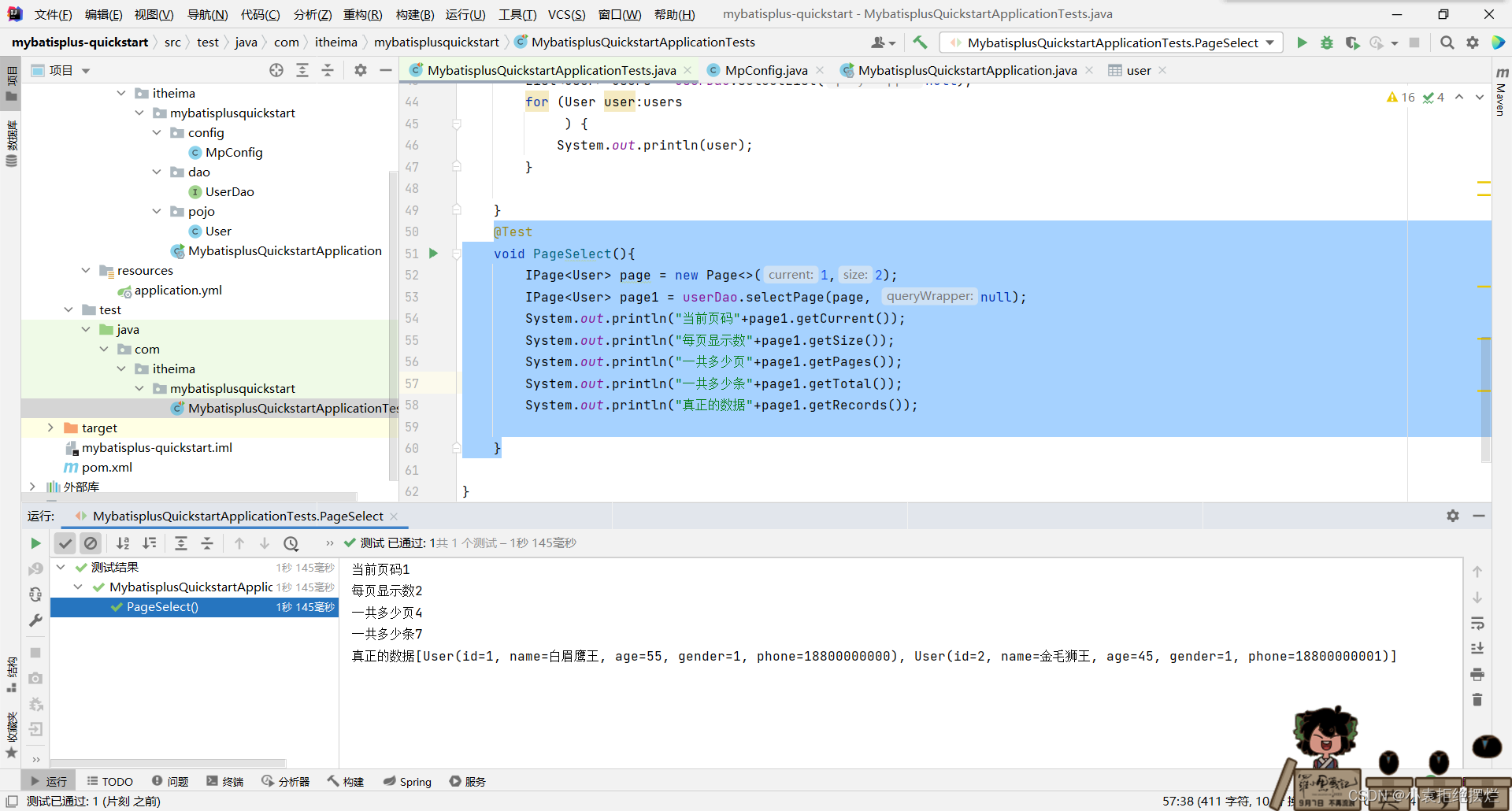
分页底层
我们就看一看他的sql语句呗
从日志看,需要吧Mp运行日志配上
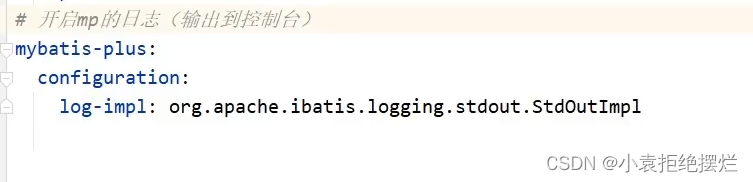
然后输出的日志
也是哪个预编译参数的由于我们写的页数是1条数是3,1对应就是从头开始呗
所以那个从头开始不用写就直接写查询多少条数据即可
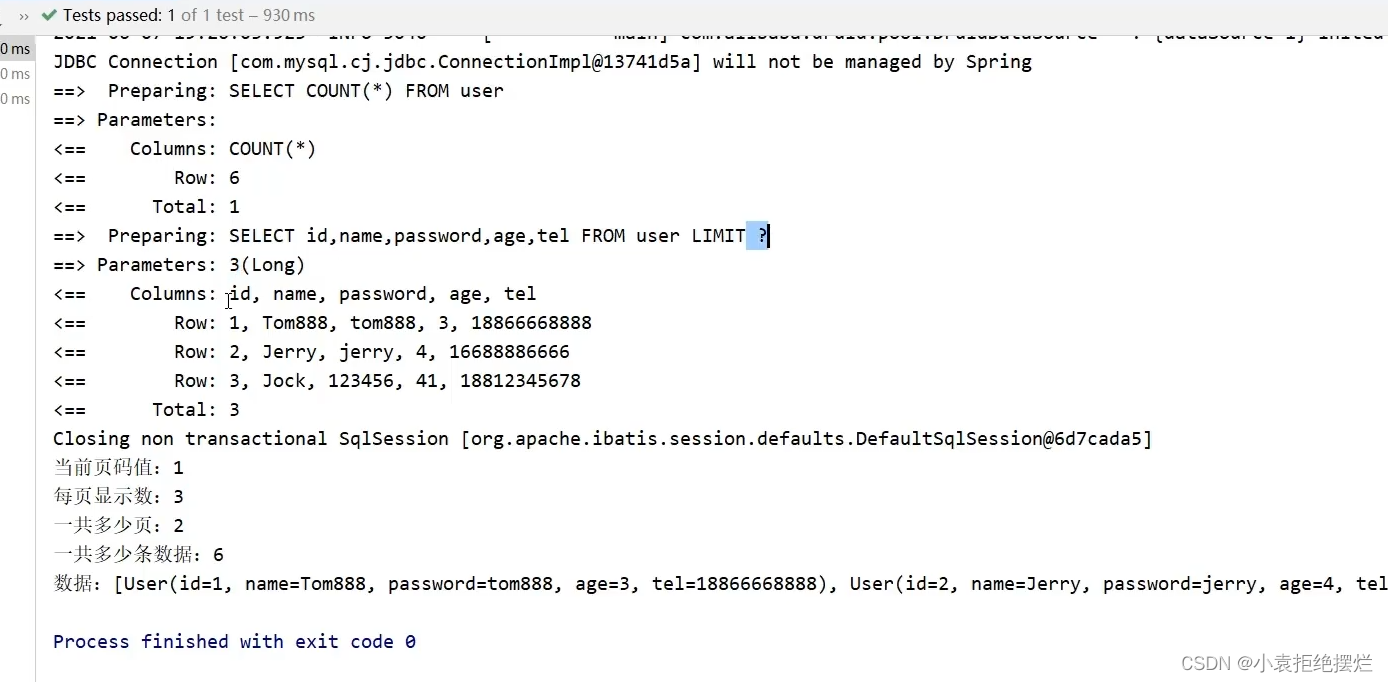
如果是2,3,查询第二页,每页三行
他就会自己做一个计算
每页三行从第二页开始,起始条数就是(page-1)*页数
查询数据数还是没有多少条数据
so传参就是3,3
他底层都弄好了!

分页小结
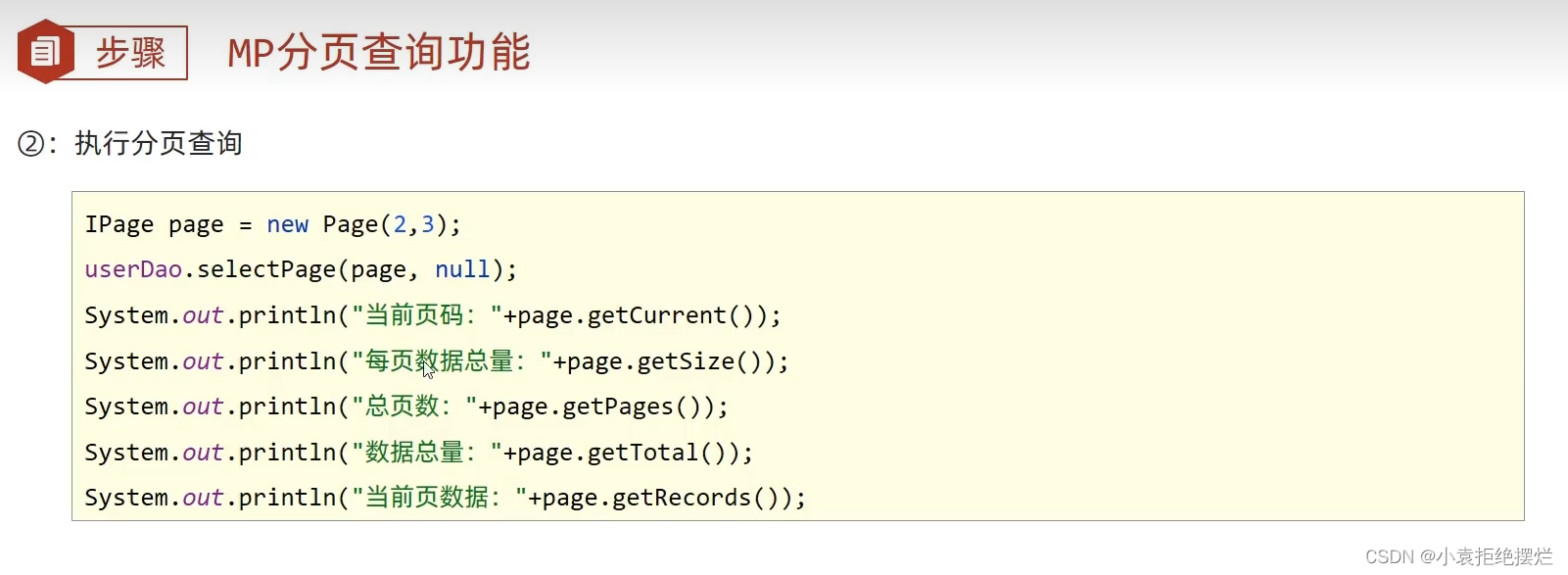
需要的话可以开启Mp的日志