如果您有更大的pb级工作负载,则可能需要多个TimescaleDB实例。TimescaleDB多节点允许您运行和管理数据库集群,这可以为您提供更快的数据摄取,以及对大型工作负载响应更快、更高效的查询。
多节点架构
多节点TimescaleDB允许您将多个数据库连接到一个逻辑分布式数据库中,以组合许多物理PostgreSQL实例的处理能力。
其中一个数据库存在于一个访问节点上,并存储其他数据库的元数据。其他数据库位于数据节点上并保存实际数据。理论上,一个PostgreSQL实例可以同时作为不同数据库中的访问节点和数据节点。但是,建议不要使用混合设置,因为它可能会很复杂,并且服务器实例的配置通常会根据它们所服务的角色而有所不同。
对于自托管安装,创建一个可以充当访问节点的服务器,然后使用该访问节点在其他服务器上创建数据节点。
当您配置了多节点TimescaleDB时,访问节点协调数据块在数据节点上的放置和访问。在大多数情况下,建议您使用多维分区在时间和空间两个维度上跨块分发数据。本节图展示了一个接入节点如何在同一时间间隔内跨多个数据节点(DN1、DN2和DN3)进行数据分区。
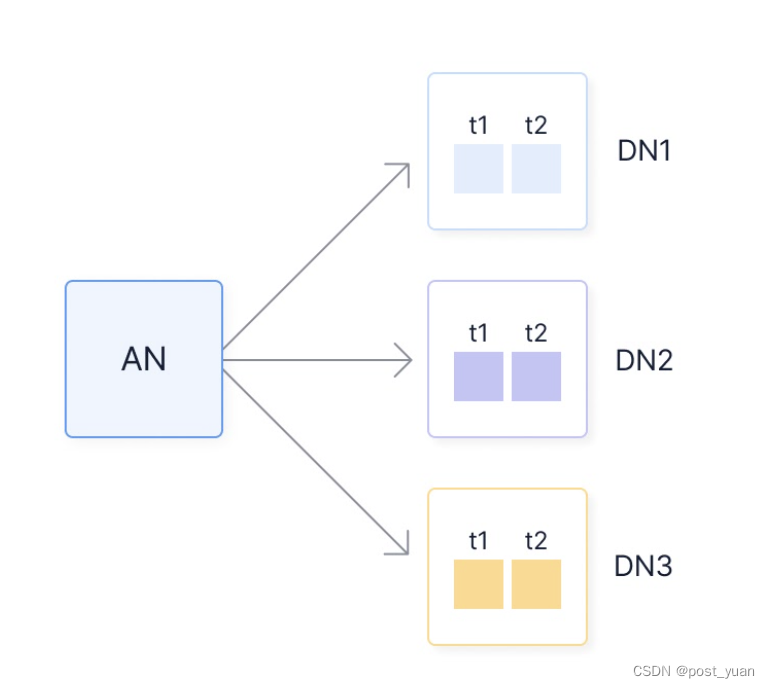
数据库用户连接到访问节点以发出命令和执行查询,类似于连接到常规单节点TimescaleDB实例的方式。在大多数情况下,不需要直接连接到数据节点。
由于TimescaleDB作为特定数据库中的扩展而存在,因此可以在同一访问节点上同时拥有分布式和非分布式数据库。也可以使用几个使用不同物理实例集作为数据节点的分布式数据库。然而,在本节中,假设您有一个具有一致数据节点集的单一分布式数据库。
分布式超表
如果在分布式数据库上使用常规表或超级表,则它们不会自动分布。常规表和超级表继续像往常一样工作,即使底层数据库是分布式的。要启用多节点功能,需要在访问节点上显式创建一个分布式超表,以使用数据节点。分布式超级表与常规超级表类似,但不同之处在于,块分布在数据节点上,而不是在本地存储上。通过分布数据块,可以将数据节点的处理能力结合起来,以实现更高的摄取吞吐量和更快的查询。然而,实现良好性能的能力高度依赖于数据如何跨数据节点进行分区。
为了获得良好的摄取性能,可以分批写入数据,每个批次包含可以分布在多个数据节点上的数据。要获得良好的查询性能,请将查询分散到许多节点,并使结果集相对于处理的数据量较小。要实现这一点,重要的是要考虑适当的分区方法。
分区方式
摄取到分布式超级表中的数据根据所选择的分区方法分布在数据节点上。可以从访问节点发送到多个数据节点并同时处理的查询通常比在单个数据节点上运行的查询运行得更快,因此考虑您拥有的数据类型以及希望运行的查询类型非常重要。
TimescaleDB多节点目前支持的功能使其最适合按时间和位置等空间维度进行分区的大容量时间序列工作负载。如果您经常运行跨多个位置和设备聚合数据的广泛查询,请选择这种分区方法。例如,这样的查询在按时间和位置分区的数据库上更快,因为它将工作并行地分布在所有数据节点上:
SELECT time_bucket('1 hour', time) AS hour, location, avg(temperature)
FROM conditions
GROUP BY hour, location
ORDER BY hour, location
LIMIT 100;
如果您需要更快的插入性能,那么根据时间和空间维度(如位置)进行分区也是最好的。如果只按时间进行分区,并且插入通常是按时间顺序进行的,那么每次总是写入一个数据节点。按时间和位置进行分区意味着按时间排序的插入分布在多个数据节点上,这可以带来更好的性能。
如果您主要在单个位置上运行深度时间查询,那么仅根据时间维度或位置以外的空间维度进行分区可能会获得更好的性能。例如,这样的查询在仅按时间分区的数据库上更快,因为单个位置的数据分布在所有数据节点上,而不是在单个数据节点上:
SELECT time_bucket('1 hour', time) AS hour, avg(temperature)
FROM conditions
WHERE location = 'office_1'
GROUP BY hour
ORDER BY hour
LIMIT 100;
事务与一致性模型
发生在分布式超级表上的事务是原子的,就像常规超级表上的事务一样。这意味着涉及多个数据节点的分布式事务保证要么在所有节点上成功,要么在任何节点上都不成功。这种保证是由两阶段提交协议提供的,该协议用于在TimescaleDB中实现分布式事务。
但是,分布式超级表的读一致性与常规超级表不同。由于分布式事务是跨多个节点的一组单独事务,因此由于网络传输延迟或其他小波动,每个节点可以在略有不同的时间提交其本地事务。因此,接入节点无法保证跨所有数据节点的数据快照完全一致。例如,当另一个并发写事务处于提交阶段并且在某些数据节点上提交而其他数据节点上没有提交时,可能会启动分布式读事务。因此,读事务可以在一个节点上使用包含其他事务修改的快照,而另一个数据节点上的快照可能不包括这些修改。
如果在分布式事务中需要更强的读一致性,那么可以跨所有数据节点使用一致性快照。然而,这需要大量的协调和管理,这可能会对性能产生负面影响,因此它没有在默认情况下为分布式超级表实现。