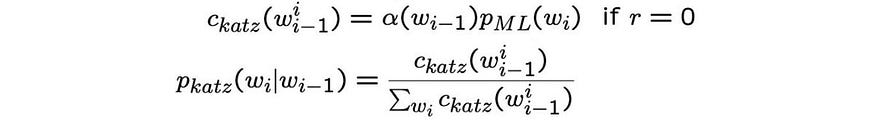简介
一夕轻雷落万丝,霁光浮瓦碧参差。

紧接之前LangChain专题文章:
- 15:如何用LangChain做长文档问答?
- 16:如何基于LangChain打造联网版ChatGPT?
- 17:ChatGPT应用框架LangChain速成大法
今天这篇小作文是LangChain实践专题的第4篇,主要介绍如何用LangChain进行网页问答。前文介绍用LangChain做文档问答,需要先将网页另存为pdf或者其他文档格式,再读取文件做问答。今天这篇小作文介绍如何直接做网页问答,本质上是将前文的数据本地存储改为数据在线爬取。
网页爬取
这里使用LLMRequestsChain从 URL 获取 HTML 结果,然后使用 LLM 解析结果。以下以罗大佑百科网页为例,说明如何用LangChain进行web QA。
示例1: 信息抽取
import os
os.environ['OPENAI_API_KEY'] ="sk-XXXX"
import warnings
warnings.filterwarnings("ignore")
# model_name = "gpt-3.5-turbo"
model_name = "gpt-3.5-turbo-16k"
task_url = "https://baike.baidu.com/item/%E7%BD%97%E5%A4%A7%E4%BD%91/236869"
llm = OpenAI(model_name=model_name, temperature=0)
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
请抽取表格中的信息。
>>> {requests_result} <<<
请使用JSON格式返回你抽取的结果。
Extracted:"""
prompt = PromptTemplate(
input_variables=["requests_result"],
template=template
)
chain = LLMRequestsChain(llm_chain=LLMChain(llm=llm, prompt=prompt))
inputs = {
"url": task_url
}
response = chain(inputs)
print(response['output'])
输出结果如下:
{
"姓名": "罗大佑",
"性别": "男",
"民族": "汉族",
"国籍": "中国",
"出生地": "台湾省台北市",
"出生日期": "1954年7月20日",
"毕业院校": "台湾中山医学院",
"星座": "巨蟹座",
"血型": "O型",
"身高": "172 cm",
"经纪公司": "种子音乐",
"擅长乐器": "吉他、钢琴",
"代表作品": "东方之珠、明天会更好、鹿港小镇、光阴的故事、童年、恋曲1990、之乎者也、你的样子、亚细亚的孤儿、恋曲1980、爱人同志、闪亮的日子、爱的箴言、未来的主人翁、沉默的表示、穿过你的黑发的我的手、野百合也有春天",
"主要成就": "台湾金曲奖特别贡献奖、hito流行音乐奖颁奖典礼乐坛成就大奖、中国金唱片奖艺术成就奖、音乐风云榜歌坛杰出贡献奖、亚洲最杰出艺人奖"
}
示例2: 指定字段抽取信息
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
请抽取表格中的信息。
>>> {requests_result} <<<
请使用如下JSON格式返回你抽取的结果。
{{"中文名": "a", "代表作品": "b", "祖籍": "c", "妻子": "d"}}
Extracted:"""
prompt = PromptTemplate(
input_variables=["requests_result"],
template=template
)
chain = LLMRequestsChain(llm_chain=LLMChain(llm=llm, prompt=prompt))
inputs = {
"url": task_url
}
response = chain(inputs)
print(response['output'])
输出结果如下:
{"中文名": "罗大佑", "代表作品": "东方之珠、明天会更好、鹿港小镇、光阴的故事、童年、恋曲1990、之乎者也、你的样子、亚细亚的孤儿、恋曲1980、爱人同志、闪亮的日子、爱的箴言、未来的主人翁、沉默的表示、穿过你的黑发的我的手、野百合也有春天", "祖籍": "广东省梅州市梅县区", "妻子": "李烈、Elaine"}
查阅原文:

网页问答
示例1: 数据统计
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMRequestsChain, LLMChain
import os
os.environ['OPENAI_API_KEY'] ="sk-XXXX"
os.environ['HTTP_PROXY'] = "XXX"
os.environ['HTTPS_PROXY'] = "XXX"
import warnings
warnings.filterwarnings("ignore")
# model_name = "gpt-3.5-turbo"
model_name = "gpt-3.5-turbo-16k"
task_url = "https://baike.baidu.com/item/%E7%BD%97%E5%A4%A7%E4%BD%91/236869"
llm = OpenAI(model_name=model_name, temperature=0)
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
>>> {requests_result} <<<
根据网页内容,回答问题:{query}。"""
prompt = PromptTemplate(
input_variables=["requests_result", "query"],
template=template
)
chain = LLMRequestsChain(llm_chain=LLMChain(llm=llm, prompt=prompt))
inputs = {
"url": task_url,
"query":"罗大佑有几个老婆",
}
response = chain(inputs)
print(response['output'])
输出结果如下:
根据网页内容,罗大佑有两个老婆。他与李烈结婚后仅维持了一年半的婚姻,然后在2010年与Elaine结婚。
示例2: 时间类
# model_name = "gpt-3.5-turbo"
model_name = "gpt-3.5-turbo-16k"
task_url = "https://baike.baidu.com/item/%E7%BD%97%E5%A4%A7%E4%BD%91/236869"
llm = OpenAI(model_name=model_name, temperature=0)
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
>>> {requests_result} <<<
根据网页内容,回答问题:{query}。"""
prompt = PromptTemplate(
input_variables=["requests_result", "query"],
template=template
)
chain = LLMRequestsChain(llm_chain=LLMChain(llm=llm, prompt=prompt))
inputs = {
"url": task_url,
"query":"罗大佑最近获得的奖是什么?",
}
response = chain(inputs)
print(response['output'])
输出结果如下:
根据网页内容,罗大佑最近获得的奖是第32届台湾金曲奖特别贡献奖。


![【C++】堆和栈的区别以及delete和delete[]的区别](https://img-blog.csdnimg.cn/74918d9ca72547c1b498f066eb72091a.png)