注1:本文系“简要介绍”系列之一,仅从概念上对自编码器进行非常简要的介绍,不适合用于深入和详细的了解。
自编码器:神经网络中的自我复制艺术
Autoencoders Explained - MATLAB & Simulink
一、背景介绍
自编码器(Autoencoder)是一种无监督学习的神经网络,常用于学习高维数据的有效表示(也称为编码),特别是在降维和特征学习场景中。简单来说,自编码器是试图使用较少数量的神经元复制输入。
二、原理介绍和推导
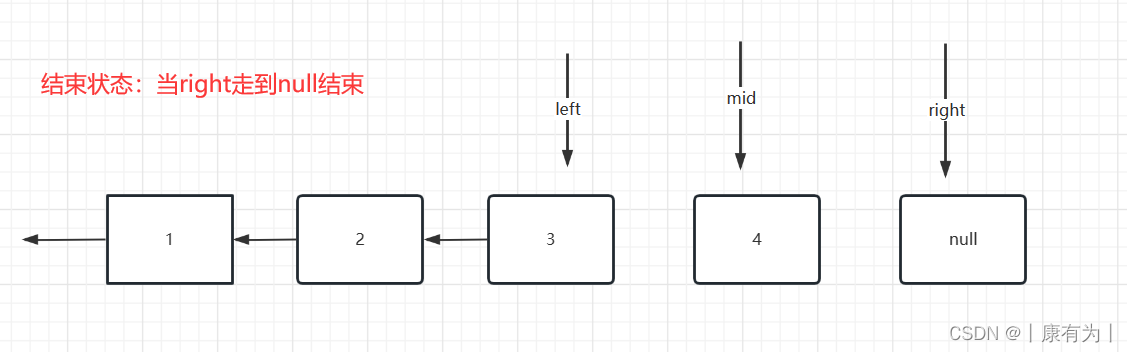
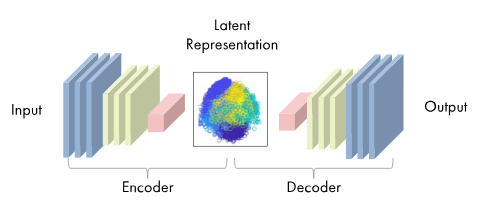
自编码器由两部分组成:编码器和解码器。编码器负责将输入数据压缩成一种更紧凑的形式,而解码器则将这种压缩的形式重新展开,生成与原始输入相似的数据。
一个典型的自编码器的结构如下:
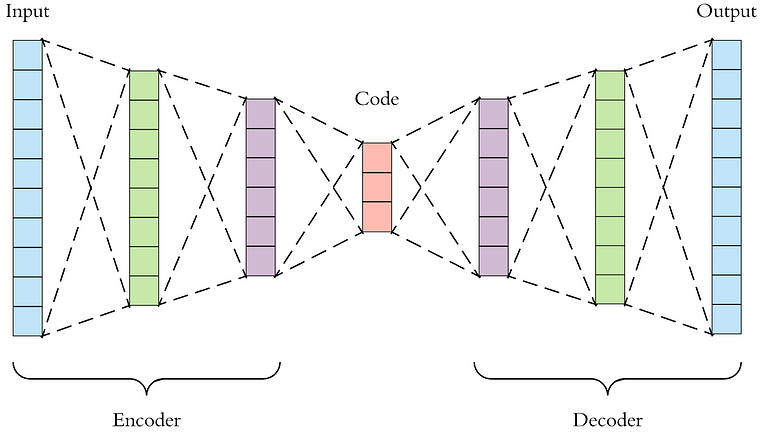
编码器(Encoder)
编码器可以视为一个函数,记作 f ( x ) f(x) f(x),将原始数据空间映射到编码空间。编码器试图保留输入数据中的重要信息,并舍弃不重要的信息。编码器的设计取决于我们试图学习的特定任务。
解码器(Decoder)
解码器可以视为一个函数,记作 g ( y ) g(y) g(y),将编码空间映射回原始数据空间。解码器试图从压缩表示中恢复出原始数据。
自编码器的目标是最小化重构误差,即原始数据和由自编码器重构的数据之间的差异。一种常见的度量方法是均方误差(MSE):
L ( x , g ( f ( x ) ) ) = ∣ ∣ x − g ( f ( x ) ) ∣ ∣ 2 L(x, g(f(x))) = ||x - g(f(x))||^2 L(x,g(f(x)))=∣∣x−g(f(x))∣∣2
其中, L L L是损失函数, x x x是原始输入, g ( f ( x ) ) g(f(x)) g(f(x))是重构的输入,||·||表示欧几里得范数。
三、研究现状
自编码器已经被广泛应用在各种领域,包括降维、特征学习、异常检测以及生成模型等。例如,在深度学习中,自编码器常用于在无标签数据上预训练网络。
目前,自编码器的一种重要扩展是变分自编码器(VAE),通过引入随机性,VAE能够生成新的数据,使其在生成模型中有着重要的应用。
四、挑战
尽管自编码器在许多方面都表现出强大的性能,但也面临着一些挑战:
- 如何选择恰当的损失函数: 不同的任务和数据可能需要不同的损失函数。选择合适的损失函数是一个重要而又困难的问题。
- 如何防止编码器过于复杂: 如果编码器过于复杂,可能会导致它简单地记忆输入,而不是学习有用的表示。这通常被称为“过拟合”问题。
- 如何选择编码的维度: 编码的维度会影响模型的性能。过高的维度可能会导致过拟合,而过低的维度可能会导致信息丢失。
五、未来展望
自编码器的研究仍在继续,人们希望通过改进自编码器,解决上述挑战,使其在更多的场景下发挥作用。例如,通过引入更复杂的损失函数,使自编码器能够学习更复杂的数据分布;通过引入正则化项,防止自编码器过拟合;通过设计自适应的方法,自动确定编码的维度。
六、代码示例
下面是一个使用PyTorch实现的自编码器的例子:
import torch
import torch.nn as nn
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28 * 28),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
在此模型中,我们首先通过编码器将输入(例如,大小为28×28的图片)压缩为3维的编码,然后通过解码器将这个编码解压为原始的28×28的图片。ReLU激活函数和最后的Sigmoid激活函数分别负责增加模型的非线性和保证输出在[0, 1]范围内。
训练这个模型的方法是通过最小化重构误差来调整模型的参数。例如,我们可以使用均方误差作为损失函数:
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(100): # 迭代100次
for data in dataloader:
img, _ = data
img = img.view(img.size(0), -1)
img = Variable(img)
# 向前传播
output = model(img)
loss = criterion(output, img)
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
在每个迭代过程中,我们首先通过模型获取输出,然后计算输出和原始输入之间的MSE,最后通过反向传播和优化器更新模型的参数。
在训练完成后,我们可以使用这个自编码器来降维或者生成新的图片。例如,我们可以随机生成一些编码,然后通过解码器生成图片:
z = torch.randn(1, 3)
img = model.decoder(z)
七、结语
自编码器是一种强大的无监督学习工具,它试图从数据中学习有用的表示。尽管自编码器面临着一些挑战,但人们仍然对其寄予厚望,希望通过研究和改进,使自编码器在更多的场景下发挥作用。
![【C++】堆和栈的区别以及delete和delete[]的区别](https://img-blog.csdnimg.cn/74918d9ca72547c1b498f066eb72091a.png)