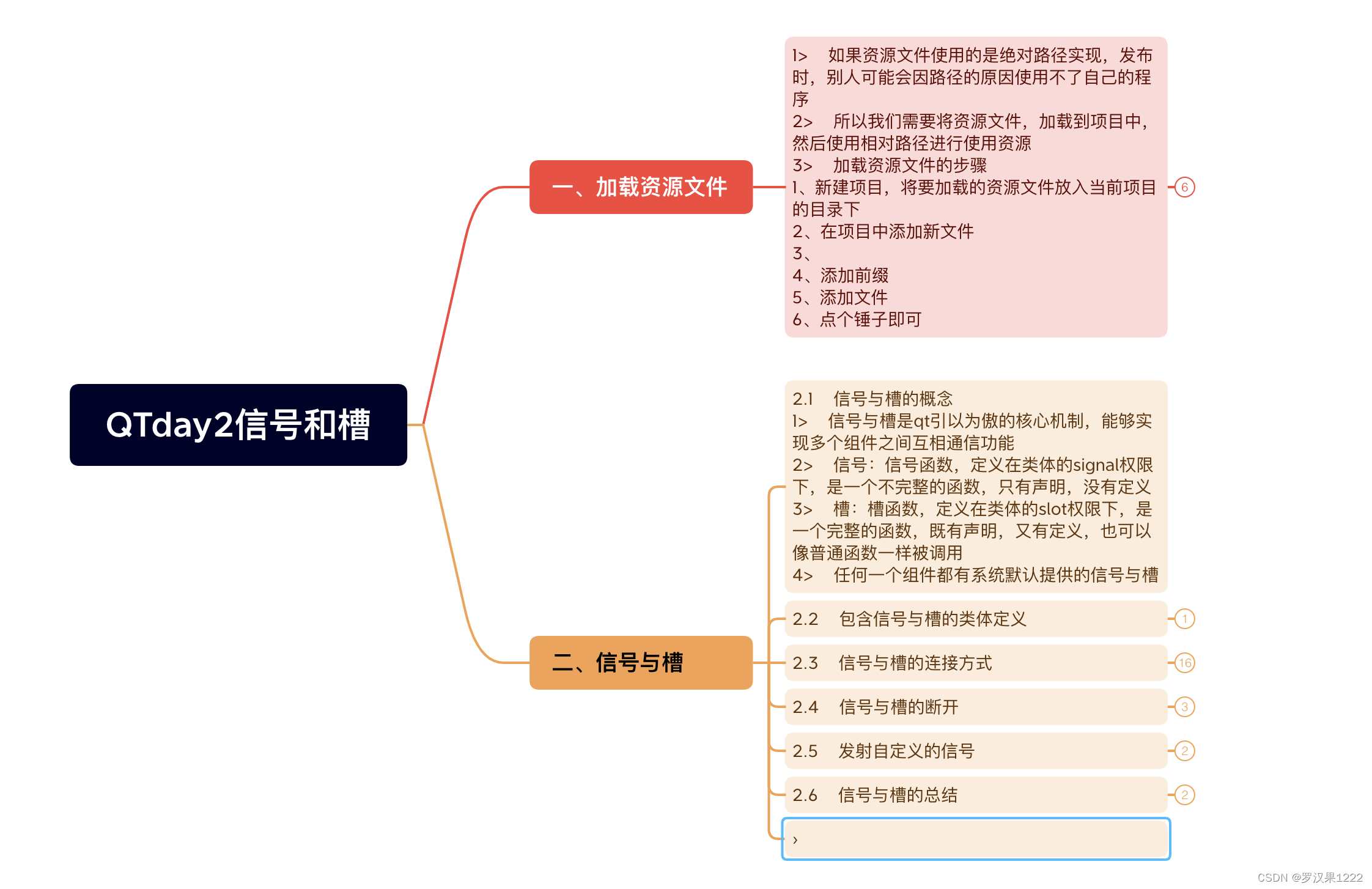
服务层-引擎层-硬盘层
一条语句执行的整体过程:
先建立连接(mysql -h -p 密码)–预处理-词法分析-语法分析-优化器选择用什么索引表如何连接等-执行器
到这里都是属于server层,大多数功能包括视图,存储过程,触发器都是这里实现的(索引不是)
接下来执行器就会调用引擎层接口,引擎负责和文件具体交互,存取数据。下面的引擎层具体结构(innodb为例)
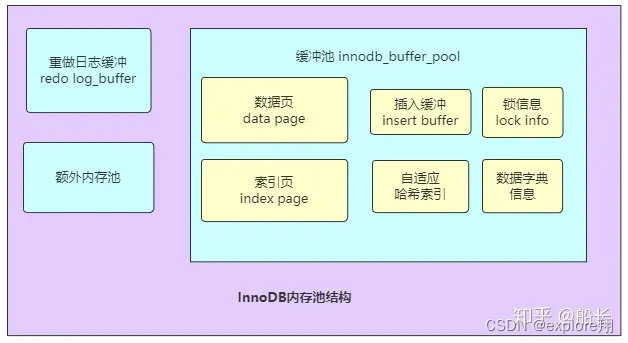
主体是内存池和后台线程
先说内存池。
缓冲池、redo_log缓冲、额外缓冲组成。
缓冲池存在意义是弥补IO和CPU速度不匹配问题。数据库读取页时,首先去缓冲池中查找该页是否存在,若不存在再去磁盘查找是否存在,若存在则将页放在缓冲池中,以便下次查找时,可以直接取出来。数据库修改页时,首先修改缓冲池中的页,然后再以一定的频率刷新到磁盘中。并不是每次修改都去修改磁盘,那样的话性能还是很低,而是通过一种称为Checkpoint的机制将数据刷新回磁盘。
relog缓冲:为了实现数据持久化,避免宕机数据丢失,先写到缓冲中,由innodb负责写到文件中。
而且是循环写的这个,两个文件循环写会覆盖,所以不适合全库备份(binlog可以)
额外的:堆数据结构分配的,在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,会从缓冲池中申请。
后台线程
主线程:主线程负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲等等。合并插入缓冲是如果IO压力小,就先把索引放到缓存池,合并若干再刷新。
IO线程:负责读写请求处理
undo回收线程: 事务完成undolog就可以回收了。
脏页清除线程:减轻主线程脏页的刷新操作。
再往下就是具体的文件操作了。