目录
1. 注意力机制
1.1 SENet(Squeeze-and-Excitation Network)
1.1.1 SENet原理
1.1.2 SENet代码示例
1.2 CBAM(Convolutional Block Attention Module)
1.2.1 CBAM原理
1.2.2 CBAM代码示例
1.3 ECA(Efficient Channel Attention)
1.3.1 ECA原理
1.3.2 ECA代码示例
1. 注意力机制
注意力机制最初是为了解决自然语言处理(NLP)任务中的问题而提出的,它使得模型能够在处理序列数据时动态地关注不同位置的信息。随后,注意力机制被引入到图像处理任务中,为深度学习模型提供了更加灵活和有效的信息提取能力。注意力机制的核心思想是根据输入数据的不同部分,动态地调整模型的注意力,从而更加关注对当前任务有用的信息。
在图像处理中,注意力机制广泛应用于图像分类、目标检测、图像分割等任务。通过引入注意力机制,模型能够在图像的不同位置或通道上分配不同的权重,从而更好地捕捉图像中重要的信息。在图像分类任务中,注意力机制可以帮助模型关注图像中与分类有关的区域;在目标检测任务中,注意力机制可以帮助模型更好地定位和检测目标;在图像分割任务中,注意力机制可以帮助模型更准确地分割目标。
1.1 SENet(Squeeze-and-Excitation Network)
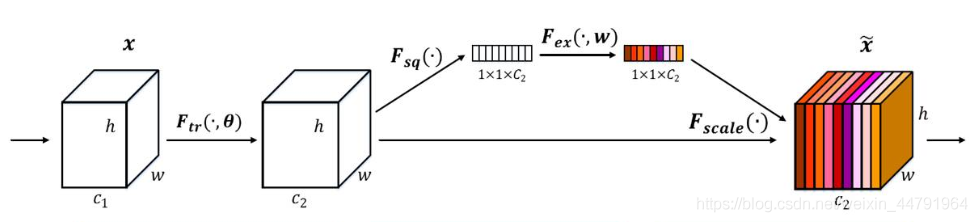
SENet(Squeeze-and-Excitation Network)是一种基于通道的注意力机制,旨在学习通道权重以增强特征图中每个通道的重要性。它是由Jie Hu等人在2017年的论文《Squeeze-and-Excitation Networks》中提出的。
1.1.1 SENet原理
SENet通过以下两个步骤来实现通道注意力:
-
Squeeze:对于每个通道,计算其全局平均池化,得到一个通道特征值。这相当于将每个通道的空间信息进行压缩。
-
Excitation:使用一个全连接层来学习通道权重,该全连接层包含一个Sigmoid激活函数,用于生成一个通道注意力向量。这个注意力向量表示每个通道的重要性。
最后,将学习到的通道注意力向量乘以原始特征图,得到加权后的特征图,增强了每个通道的重要性。
1.1.2 SENet代码示例
import torch
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
在上述代码中,我们定义了一个SEBlock类,它是SENet的基本构建块。SEBlock通过一个全局平均池化层和两个全连接层来实现通道注意力。在使用SEBlock时,将其插入到模型中需要增强通道注意力的位置。
然后之前的博客使用迁移学习Resnet50模块进行猫狗二分类,然后我们可以添加SE注意力机制。
Pytorch迁移学习使用Resnet50进行模型训练预测猫狗二分类_山河亦问安的博客-CSDN博客
我们首先创建了一个新的ResNet-50模型,然后在其每个卷积块后添加SEAttention模块,从而实现了SENet的通道注意力机制。最后,我们将全连接层适配为新的分类数目。接下来,我们可以像之前一样定义超参数、数据转换和加载数据集。然后,创建模型、优化器和损失函数,并进行训练和测试。这里给出添加注意力机制的关键代码:
class ResNetSE(nn.Module):
def __init__(self, num_classes, reduction=16):
super(ResNetSE, self).__init__()
self.resnet = resnet50(pretrained=True)
in_channels = self.resnet.fc.in_features
self.resnet.fc = nn.Linear(in_channels, num_classes)
self.se1 = SEAttention(256, reduction)
self.se2 = SEAttention(512, reduction)
self.se3 = SEAttention(1024, reduction)
self.se4 = SEAttention(2048, reduction)
def forward(self, x):
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
x = self.resnet.layer1(x)
x = self.se1(x)
x = self.resnet.layer2(x)
x = self.se2(x)
x = self.resnet.layer3(x)
x = self.se3(x)
x = self.resnet.layer4(x)
x = self.se4(x)
x = self.resnet.avgpool(x)
x = torch.flatten(x, 1)
x = self.resnet.fc(x)
return x1.2 CBAM(Convolutional Block Attention Module)
CBAM(Convolutional Block Attention Module)是一种基于通道和空间的注意力机制,它结合了SENet的通道注意力和Spatial Attention机制。CBAM是由Sanghyun Woo等人在2018年的论文《CBAM: Convolutional Block Attention Module for Visual Attention》中提出的。CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
1.2.1 CBAM原理
下图是通道注意力机制和空间注意力机制的具体实现方式:
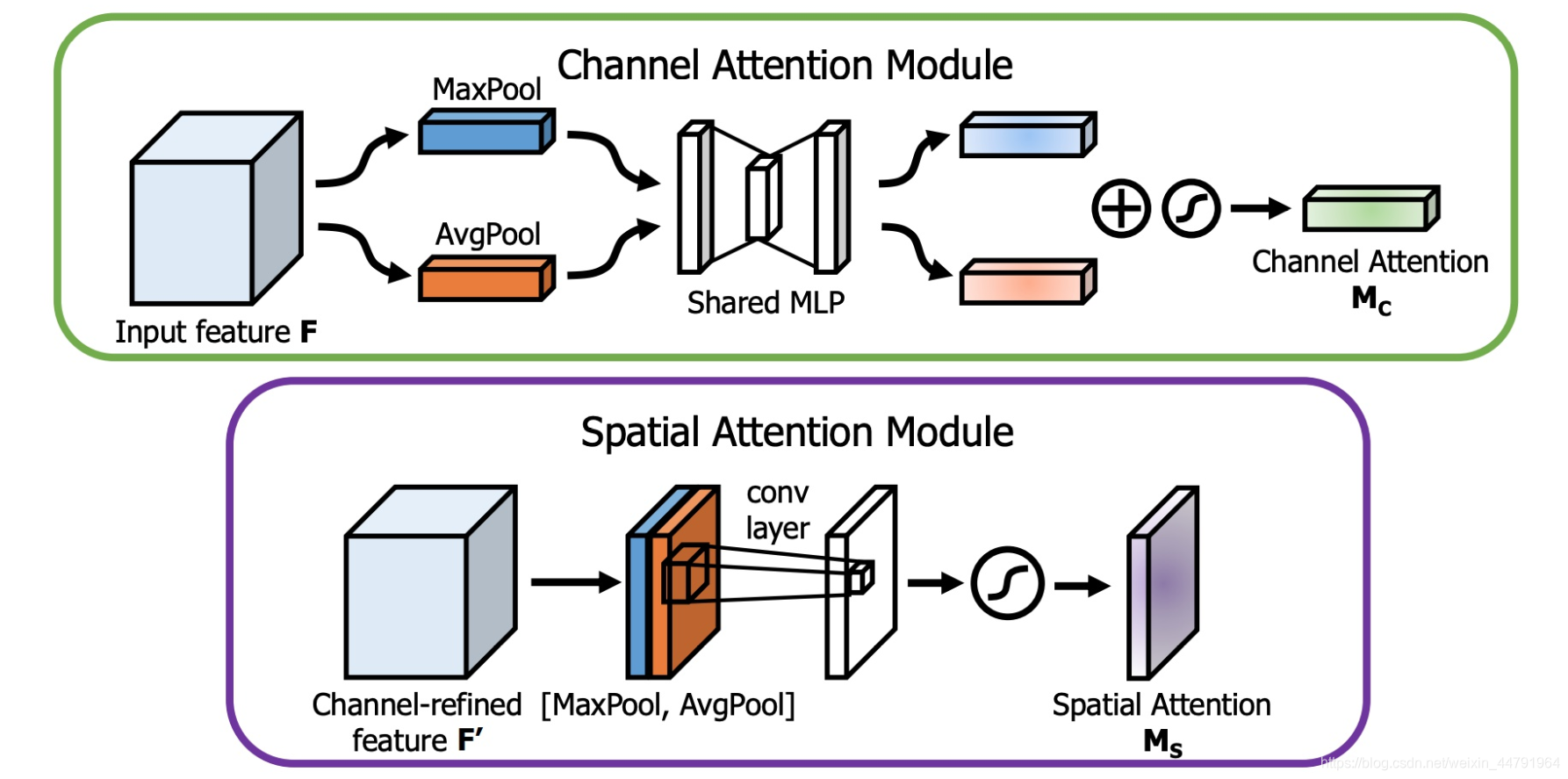
1. 图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
2. 图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
1.2.2 CBAM代码示例
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
avg_y = self.avg_pool(x).view(b, c)
max_y = self.max_pool(x).view(b, c)
y = self.fc(avg_y + max_y).view(b, c, 1, 1)
return x * y
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return x * self.sigmoid(x)
class CBAMBlock(nn.Module):
def __init__(self, in_channels, reduction=16, kernel_size=7):
super(CBAMBlock, self).__init__()
self.channel_attention = ChannelAttention(in_channels, reduction)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x
1.3 ECA(Efficient Channel Attention)
ECA(Efficient Channel Attention)是一种轻量级的通道注意力机制,它提出通过一个1D卷积层来学习通道注意力,以减少计算复杂度。ECA是由Zhang et al.在2019年的论文《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》中提出的。
1.3.1 ECA原理
ECA采用了一种更加高效的方法来学习通道注意力。它使用一个1D卷积层,对每个通道的特征进行卷积,然后使用Sigmoid函数来学习通道注意力。这样可以大大降低计算复杂度,并在一定程度上提高模型性能。
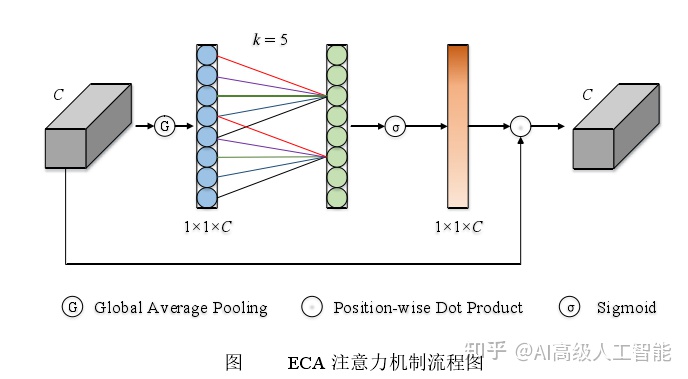
SE 注意力机制首先对输入特征图进行了通道压缩,而这样的压缩降维对于学习通道之间的依赖关系有不利影响,基于此理念,ECA 注意力机制避免降维,用1 维卷积高效实现了局部跨通道交互,提取通道间的依赖关系。具体步骤如下:
①将输入特征图进行全局平均池化操作;
②进行卷积核大小为 k 的 1 维卷积操作,并经过 Sigmoid 激活函数得到各个通道的权重w ,如公式如下所示;
![]()
③将权重与原始输入特征图对应元素相乘,得到最终输出特征图。
1.3.2 ECA代码示例
class eca_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
这篇文章到此结束。