基于规则指导的知识图谱推理协作代理学习
- 摘要
- 介绍
- 问题和准备工作
- 问题公式
- 基于符号的方法
- 基于游走的方法
- RuleGuider
- 模型架构
- 实体代理
- 策略网络
- 模型学习
- 奖励设计
- 训练过程
- 实验
- 实验设置
- 数据集
- 实验结果
- 消融研究
- 人工评估
- 总结

摘要
基于 行走模型 是通过在提供可解释决策的同时实现良好的性能,在知识图(KG)推理中显示了其优势。
然而,KG在行走过程中提供的稀疏信号通常不足以指导复杂的基于行走的强化学习(Reinforcement learning RL)模型。
行走(walk)模型
是一种用于学习图形嵌入(graph embedding)的方法,图形嵌入是将图形中的节点映射到低维向量空间中的过程。走路模型通过模拟在图形中“走路”来学习节点之间的关系,从而为每个节点分配一个嵌入向量。这些嵌入向量可以用于许多图形分析任务,如节点分类、链路预测和社区检测等。
在走路模型中,我们首先选择一个起始节点,然后从该节点开始在图形中随机游走。在每一步中,我们根据一定的概率选择一个相邻的节点,并将其添加到我们的“走路路径”中。最终,我们得到了一个包含许多节点的路径。我们可以使用这些路径来学习节点之间的关系,并将每个节点映射到一个嵌入向量。
另一种方法是使用传统的符号方法(例如,规则推理),这种方法取得了良好的性能,但由于符号表示的复杂性,很难推广。
在本文中,我们提出了RuleGuider,它利用基于符号的方法生成的高质量规则 来为基于行走的代理提供奖励监督。
在基准数据集上的实验表明,RuleGuider在不损失可解释性的情况下提高了基于行走的模型的性能。
介绍
虽然知识图谱在自然语言处理应用中被广泛采用,但阻碍其使用的一个主要瓶颈是数据的稀疏性,导致了对KG完成(或推理)的广泛研究。许多关于KG推理任务的传统方法都是基于逻辑规则的。这些方法被称为基于符号的方法。尽管它们表现出了良好的性能,但它们本质上受到给定规则的关联关系的表示和可推广性的限制。
为了改善这种限制,基于嵌入的方法被提出了。他们学习实体和关系的分布式表示,并使用表示进行预测。尽管它们有着卓越的性能,但却无法做出人性化的诠释。
为了提高解释性,最近的许多研究使用强化学习(RL)技术将任务表述为 多跳推理 问题,称为基于行走的方法。这些方法的一个主要问题是奖励函数。一个“命中与否”的奖励过于稀疏,而使用基于嵌入的距离测量的成形奖励可能并不总是产生理想的路径。
多跳推理(multi-hop reasoning)
是一种常见的人工智能技术,用于通过多步推理来回答自然语言问题。在多跳推理中,系统需要从给定的文本中推导出一系列逻辑关系,以回答问题。
例如,考虑以下问题:“谁是美国第一位总统?”为了回答这个问题,系统可能需要进行以下多跳推理:
美国有总统。
第一位总统是谁?
第一位总统是乔治·华盛顿。
在这个例子中,系统需要通过多步推理才能回答问题,因为问题的答案不直接在原始文本中给出。
在本文中,我们提出了RuleGuider,借助符号规则来解决基于步行的方法中的上述奖励问题。我们希望在不失去可解释性的情况下提高基于步行的方法的性能。RuleGuider由一个获取逻辑规则的基于符号的模型和一个在规则指导下搜索推理路径的基于行走的Agent组成。我们还介绍了一种分离基于行走的代理的方法,以提高效率。我们在不丧失可解释性的情况下,通过实验证明了我们模型的有效性。
问题和准备工作
在本节中回顾了KG推理任务。我们还描述了RuleGuider中使用的基于符号和基于行走的方法。
问题公式
基于符号的方法
基于游走的方法
RuleGuider
RuleGuider包括一个基于符号的方法,称为规则挖掘器,以及一个基于行走的方法,称为代理。
规则挖掘器首先挖掘逻辑规则,代理遍历KG,以学习在规则指导下(通过奖励)推理路径的概率分布。当代理交替地穿过关系和实体时,我们建议将主体分为两个子主体:一个关系和实体代理。
在分离之后,搜索空间被显著地修剪。如图。
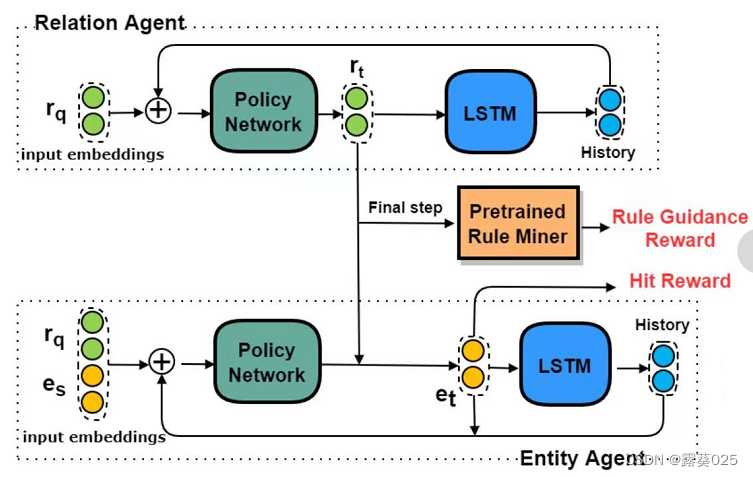
关系和实体代理相互作用以生成路径。在每个步骤中,实体代理首先从有效实体中选择一个实体。然后,关系代理基于所选实体对关系进行采样。在最后一步,他们根据最后的选择获得命中奖励,并根据所选路径从布雷前集合中获得规则指导奖励。