文章目录
- 前言
- 运行效果截图
- 导入requests库
- 获取集数音频ID的链接
- 提取音频ID和名称
- 循环处理每个音频
- 完整代码
- 分点讲解
- 结束语

前言
本文介绍了如何使用Python中的requests库来获取音频文件并保存到本地。在这个例子中,我们使用了喜马拉雅平台上的一个API接口来获取音频ID和名称,并使用这些信息构造音频地址,然后通过发送HTTP请求将音频内容下载保存到本地。
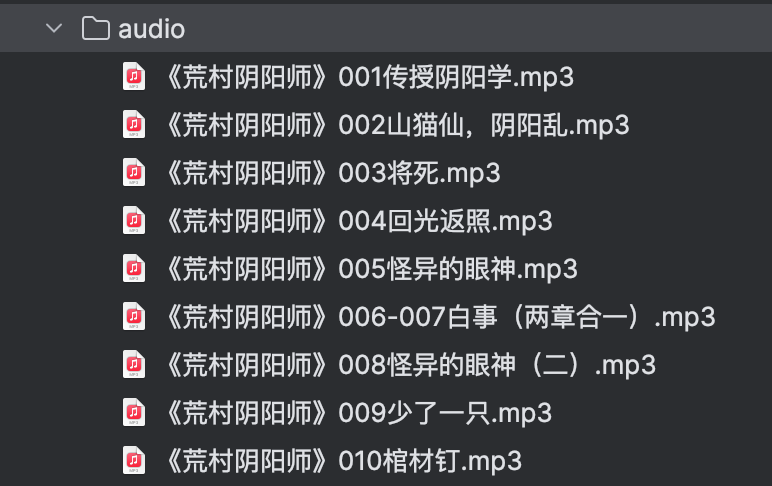
运行效果截图
导入requests库

import requests
这行代码导入了requests库,它是一个常用的HTTP请求库,用于发送HTTP请求和处理响应。
获取集数音频ID的链接

url_list = 'https://www.ximalaya.com/revision/play/v1/show?id=67641798&sort=0&size=30&ptype=1'
url_list_resp = requests.get(url_list,headers=headers)
这两行代码分别定义了一个获取音频ID列表的链接url_list,并使用requests.get()方法发送GET请求获取响应。headers变量用于设置请求头信息,其中User-Agent字段指定了发送请求的浏览器标识。
提取音频ID和名称

track_list = [(tack.get('trackId'),tack.get('trackName')) for tack in url_list_resp.json().get('data').get('tracksAudioPlay')]
这行代码通过解析响应的JSON数据,提取了音频的ID和名称,并将其存储在列表对象track_list中。
循环处理每个音频

for id, name in track_list:
# 获取音频地址的链接
audio_src= f'https://www.ximalaya.com/revision/play/v1/audio?id={id}&ptype=1'
src = requests.get(audio_src,headers=headers)
audio_url = src.json().get('data').get('src')
# audio_url = 'https://aod.cos.tx.xmcdn.com/group39/M07/34/82/wKgJnlqChT2jRXU8AEn2S2TpSzo586.m4a'
# 发送请求
resp = requests.get(audio_url,headers=headers)
print(f'正在保存{name}音频')
# 保存数据 w写文件 b字节流
with open(f'audio/{name}.mp3','wb') as f:
# resp.text 文本 resp.content 内容 resp.json()
f.write(resp.content)
这部分代码中使用了一个for循环来遍历track_list列表中的每个音频。首先,它构造了获取音频地址的链接audio_src,然后发送GET请求获取响应并解析出音频地址audio_url。接下来,它再次发送GET请求获取音频的内容,并将其保存到以音频名称命名的文件中。
注意:代码中注释的部分表示了一些其他可能的音频链接和文件保存方式。具体选择哪种方式取决于你的需求和实际情况。
完整代码
import requests
# 导入requests库,用于发送HTTP请求和处理响应
# pip install requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
# 设置请求头信息,其中User-Agent字段指定了发送请求的浏览器标识
url_list = 'https://www.ximalaya.com/revision/play/v1/show?id=67641798&sort=0&size=30&ptype=1'
# 定义了一个获取音频ID列表的链接
url_list_resp = requests.get(url_list, headers=headers)
# 发送GET请求获取响应
track_list = [(track.get('trackId'), track.get('trackName')) for track in url_list_resp.json().get('data').get('tracksAudioPlay')]
# 提取音频ID和名称
for id, name in track_list:
# 循环处理每个音频
audio_src = f'https://www.ximalaya.com/revision/play/v1/audio?id={id}&ptype=1'
# 构造获取音频地址的链接
src = requests.get(audio_src, headers=headers)
# 发送GET请求获取音频地址的响应
audio_url = src.json().get('data').get('src')
# 从响应的JSON数据中提取音频地址
resp = requests.get(audio_url, headers=headers)
# 发送GET请求获取音频文件内容
print(f'正在保存{name}音频')
# 打印正在保存的音频名称
with open(f'audio/{name}.mp3', 'wb') as f:
# 打开一个文件,并以二进制写入模式写入文件中
f.write(resp.content)
# 将音频文件内容写入文件中
分点讲解
import requests
这行代码导入了requests库,用于发送HTTP请求和处理响应。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
这行代码定义了一个字典 headers,用于设置请求头信息。在这个例子中,我们设置了一个User-Agent字段,模拟浏览器的标识。
url_list = 'https://www.ximalaya.com/revision/play/v1/show?id=67641798&sort=0&size=30&ptype=1'
这行代码定义了一个字符串变量 url_list,它是用来获取音频ID列表的链接。在这个例子中,链接是喜马拉雅平台提供的一个API接口。
url_list_resp = requests.get(url_list, headers=headers)
这行代码发送一个GET请求去获取响应。使用 requests.get() 方法发送GET请求,并将响应保存到变量 url_list_resp 中。
track_list = [(track.get('trackId'), track.get('trackName')) for track in url_list_resp.json().get('data').get('tracksAudioPlay')]
这行代码提取音频ID和名称。通过解析JSON格式的响应数据,我们从中提取出音频的ID和名称,并将它们存储在一个列表对象 track_list 中。这里使用了列表推导式,遍历了 tracksAudioPlay 字段中的每个元素,提取出 trackId 和 trackName 字段的值。
for id, name in track_list:
这行代码开始循环处理每个音频。我们从 track_list 列表中依次取出音频的ID和名称,赋值给变量 id 和 name。
audio_src = f'https://www.ximalaya.com/revision/play/v1/audio?id={id}&ptype=1'
这行代码构造了获取音频地址的链接。我们通过字符串格式化将音频的ID插入到链接中,创建一个完整的URL,以便获取音频的地址。
src = requests.get(audio_src, headers=headers)
这行代码发送一个GET请求去获取音频地址的响应。我们使用 requests.get() 方法再次发送GET请求,获取音频地址的响应,并将其保存到变量 src 中。
audio_url = src.json().get('data').get('src')
这行代码从响应的JSON数据中提取出音频地址。我们解析JSON格式的响应数据,并从中获取 data 字段的值,然后再从 data 字段中获取 src 字段的值,即音频的地址。
resp = requests.get(audio_url, headers=headers)
这行代码发送一个GET请求去获取音频文件的内容。我们使用 requests.get() 方法发送GET请求,获取音频文件的内容,并将其保存到变量 resp 中。
print(f'正在保存{name}音频')
这行代码打印正在保存的音频名称。我们使用 print() 函数输出保存当前音频的名称。
with open(f'audio/{name}.mp3', 'wb') as f:
f.write(resp.content)
这行代码使用文件操作来保存音频文件。我们以二进制写入模式打开一个文件,根据音频名称创建对应的文件,并将音频文件的内容写入到文件中。
结束语
通过本文,我们学习了如何使用Python中的requests库来处理HTTP请求,并结合喜马拉雅平台的API接口完成了音频文件的下载和保存。当然,这只是一个简单的示例,实际应用中可能还涉及到其他更复杂的操作和处理方式。希望本文对你理解和使用requests库有所帮助,并能够在实际项目中发挥作用。