面试官:我看你简历上写了MySQL,对MySQL InnoDB引擎的索引了解吗?
候选者:嗯啊,使用索引可以加快查询速度,其实上就是将无序的数据变成有序(有序就能加快检索速度)
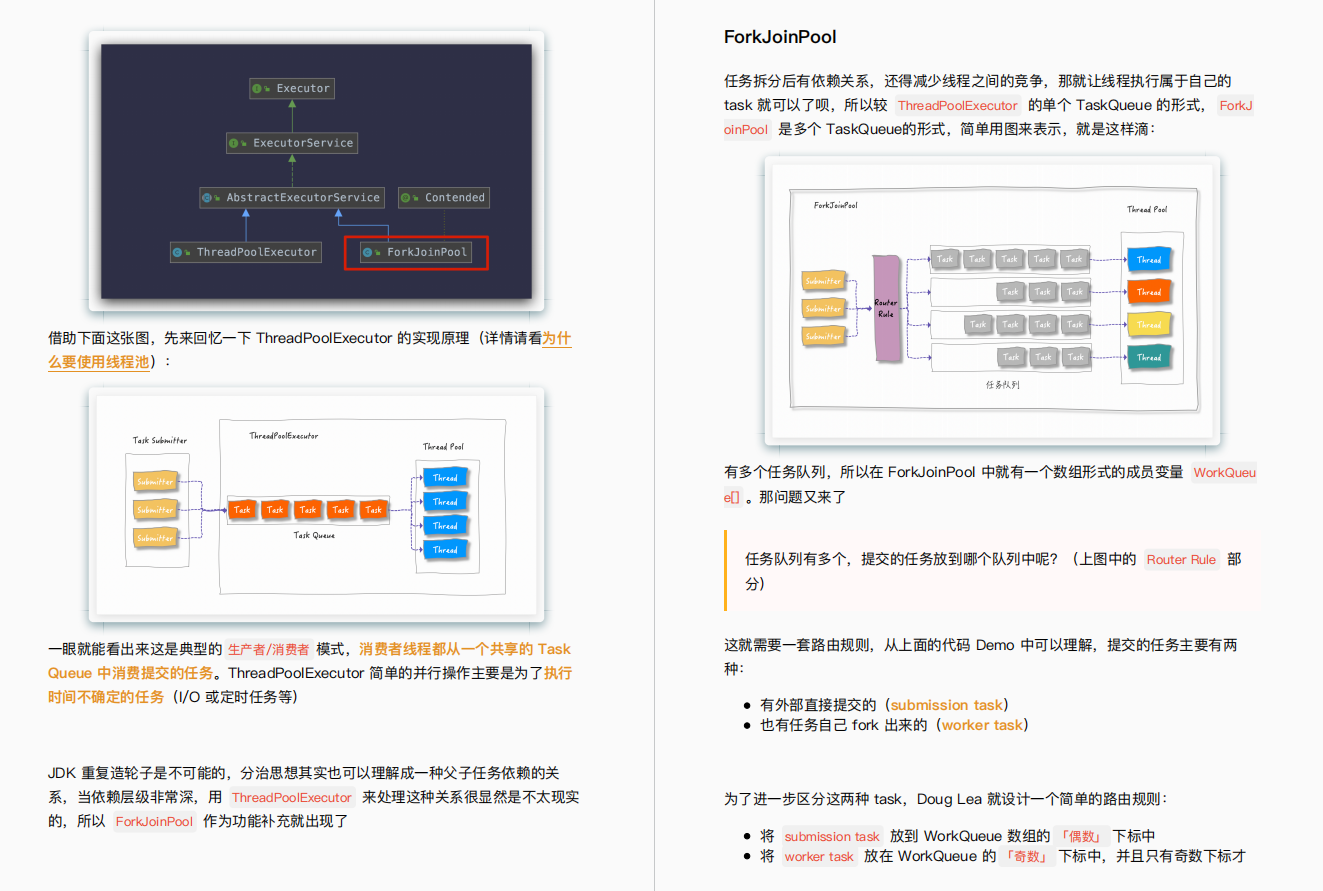
候选者:在InnoDB引擎中,索引的底层数据结构是B+树
面试官:那为什么不使用红黑树或者B树呢?
候选者:MySQL的数据是存储在硬盘的,在查询时一般是不能「一次性」把全部数据加载到内存中
候选者:红黑树是「二叉查找树」的变种,一个Node节点只能存储一个Key和一个Value
候选者:B和B+树跟红黑树不一样,它们算是「多路搜索树」,相较于「二叉搜索树」而言,一个Node节点可以存储的信息会更多,「多路搜索树」的高度会比「二叉搜索树」更低。
候选者:了解了区别之后,其实就很容易发现,在数据不能一次加载至内存的场景下,数据需要被检索出来,选择B或B+树的理由就很充分了(一个Node节点存储信息更多(相较于二叉搜索树),树的高度更低,树的高度影响检索的速度)
候选者:B+树相对于B树而言,它又有两种特性。
候选者:一、B+树非叶子节点不存储数据,在相同的数据量下,B+树更加矮壮。(这个应该不用多解释了,数据都存储在叶子节点上,非叶子节点的存储能存储更多的索引,所以整棵树就更加矮壮)
候选者:二、B+树叶子节点之间组成一个链表,方便于遍历查询(遍历操作在MySQL中比较常见)

候选者:我稍微解释一下吧,你可以脑补下画面
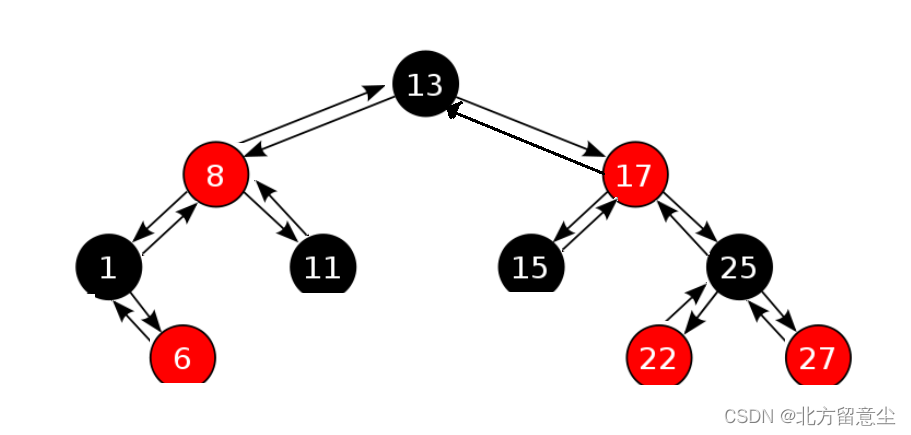
候选者:我们在MySQL InnoDB引擎下,每创建一个索引,相当于生成了一颗B+树。
候选者:如果该索引是「聚集(聚簇)索引」,那当前B+树的叶子节点存储着「主键和当前行的数据」
候选者:如果该索引是「非聚簇索引」,那当前B+树的叶子节点存储着「主键和当前索引列值」
候选者:比如写了一句sql:select * from user where id >=10,那只要定位到id为10的记录,然后在叶子节点之间通过遍历链表(叶子节点组成的链表),即可找到往后的记录了。
候选者:由于B树是会在非叶子节点也存储数据,要遍历的时候可能就得跨层检索,相对麻烦些。
候选者:基于树的层级以及业务使用场景的特性,所以MySQL选择了B+树作为索引的底层数据结构。
候选者:对于哈希结构,其实InnoDB引擎是「自适应」哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,我们是干预不了)
面试官:嗯…那我了解了,顺便想问下,你知道什么叫做回表吗?
候选者:所谓的回表其实就是,当我们使用索引查询数据时,检索出来的数据可能包含其他列,但走的索引树叶子节点只能查到当前列值以及主键ID,所以需要根据主键ID再去查一遍数据,得到SQL 所需的列
候选者:举个例子,我这边建了给订单号ID建了个索引,但我的SQL 是:select orderId,orderName from orderdetail where orderId = 123
候选者:SQL都订单ID索引,但在订单ID的索引树的叶子节点只有orderId和Id,而我们还想检索出orderName,所以MySQL 会拿到ID再去查出orderName给我们返回,这种操作就叫回表

候选者:想要避免回表,也可以使用覆盖索引(能使用就使用,因为避免了回表操作)。
候选者:所谓的覆盖索引,实际上就是你想要查出的列刚好在叶子节点上都存在,比如我建了orderId和orderName联合索引,刚好我需要查询也是orderId和orderName,这些数据都存在索引树的叶子节点上,就不需要回表操作了。
面试官:既然你也提到了联合索引,我想问下你了解最左匹配原则吗?
候选者:嗯,说明这个概念,还是举例子比较容易说明
候选者:如有索引 (a,b,c,d),查询条件 a=1 and b=2 and c>3 and d=4,则会在每个节点依次命中a、b、c,无法命中d
候选者:先匹配最左边的,索引只能用于查找key是否存在(相等),遇到范围查询 (>、<、between、like左匹配)等就不能进一步匹配了,后续退化为线性查找
候选者:这就是最左匹配原则

面试官:嗯嗯,我还想问下你们主键是怎么生成的?
候选者:主键就自增的
面试官:那假设我不用MySQL自增的主键,你觉得会有什么问题呢?
候选者:首先主键得保证它的唯一性和空间尽可能短吧,这两块是需要考虑的。
候选者:另外,由于索引的特性(有序),如果生成像uuid类似的主键,那插入的的性能是比自增的要差的
候选者:因为生成的uuid,在插入时有可能需要移动磁盘块(比如,块内的空间在当前时刻已经存储满了,但新生成的uuid需要插入已满的块内,就需要移动块的数据)
面试官:OK…

本文总结:
- 为什么B+树?数据无法一次load到内存,B+树是多路搜索树,只有叶子节点才存储数据,叶子节点之间链表进行关联。(树矮,易遍历)
- 什么是回表?非聚簇索引在叶子节点只存储列值以及主键ID,有条件下尽可能用覆盖索引避免回表操作,提高查询速度
- 什么是最左匹配原则?从最左边为起点开始连续匹配,遇到范围查询终止
- 主键非自增会有什么问题?插入效率下降,存在移动块的数据问题

![[附源码]Python计算机毕业设计SSM基于的小区物业管理系统(程序+LW)](https://img-blog.csdnimg.cn/1791d408ea6244e98367dc7f817f5881.png)