运行代码要求:
代码运行环境要求:Keras版本>=2.4.0,python版本>=3.6.0
本次实验主要是在两种不同工况数据下,进行带有复合故障的诊断实验,没有复合故障的诊断实验。
实验结果证明,针对具有复合故障的数据集,需要 研发特定的算法,才能更好区分复合故障数据集。
1.东南大学采集数据平台

数据
该数据集包含2个子数据集,包括轴承数据和齿轮数据,这两个子数据集都是在传动系动力学模拟器(DDS)上获取的。(第一个文件夹是轴承数据,第二个文件夹是齿轮数据,本次是针对齿轮数据进行故障诊断)

本实验主要是利用轴承数据(第一个文件夹的数据)进行故障诊断,轴承具体数据
有两种工况,转速-负载配置设置为20-0和30-2。
每种工况下有:ball(滚动体故障)、comb(复合故障,即包含滚动体、外圈、内圈故障),health(健康)、inner(内圈故障)、outer(外圈故障)
code_20.py是只使用20_0工况下ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集诊断。没有使用复合故障数据集
code_20_0.py是使用20_0工况下ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)、comb(复合故障,即包含滚动体、外圈、内圈故障)诊断
code_30.py是只使用30_2工况下ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集诊断。没有使用复合故障数据集
code_30_2.py是使用30_2工况下ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)、comb(复合故障,即包含滚动体、外圈、内圈故障)诊断
模型

首先在20-0工况数据集下实验
2.1.使用ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集。没有使用复合故障数据集
每类故障有1000个样本(一共4000个样本),训练集与测试集比例是9:1(训练集:3600个样本,测试集:400个样本)
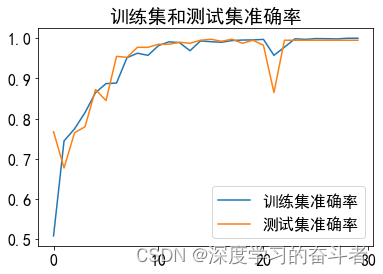

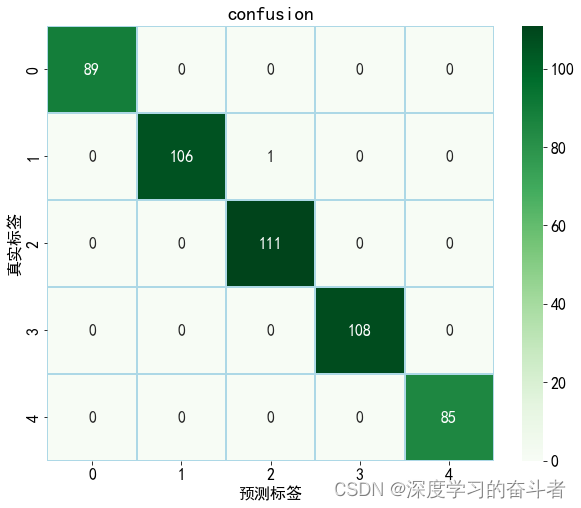
测试集的混淆矩阵(以样本个数呈现)

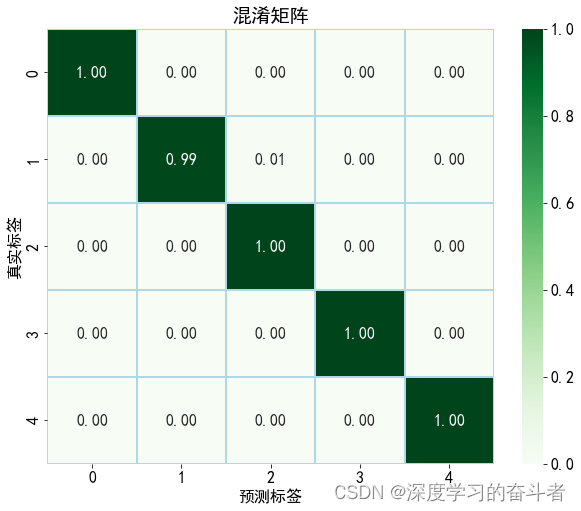
测试集的混淆矩阵(以准确率数呈现)

2.2.使用ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集,comb(复合故障,即包含滚动体、外圈、内圈故障)。
每类故障有1000个样本(一共5000个样本),训练集与测试集比例是9:1(训练集:4500个样本,测试集:500个样本)
从结果可以看出,CNN对带有复合故障的数据集诊断准确率不高,需要区分复合故障与单独故障的特定算法, 才能提高准确率


测试集的混淆矩阵(以样本个数呈现)

测试集的混淆矩阵(以准确率数呈现)
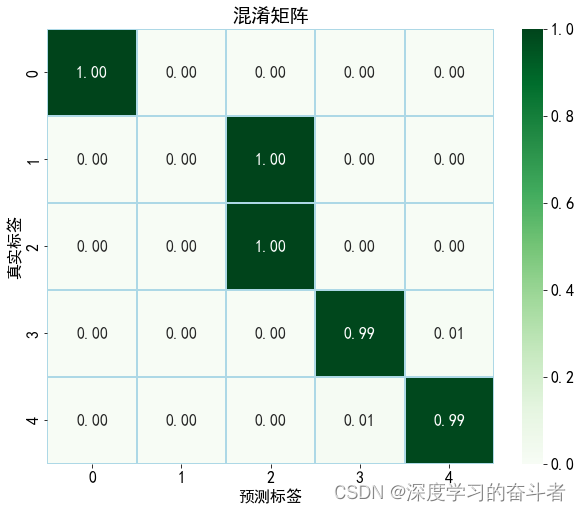
3.在30-2工况数据集下实验
3.1.使用ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集。没有使用复合故障数据集
每类故障有1000个样本(一共4000个样本),训练集与测试集比例是9:1(训练集:3600个样本,测试集:400个样本)
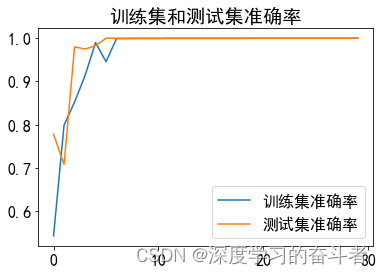

测试集的混淆矩阵(以样本个数呈现)
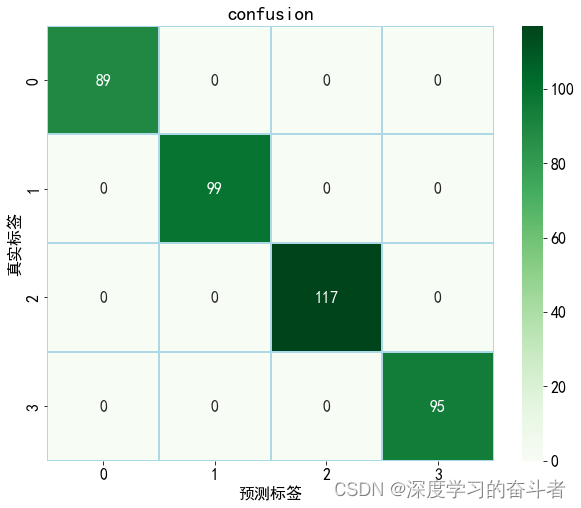
测试集的混淆矩阵(以准确率数呈现)

3.2.
使用ball(滚动体故障)、health(健康)、inner(内圈故障)、outer(外圈故障)数据集,comb(复合故障,即包含滚动体、外圈、内圈故障)。
每类故障有1000个样本(一共5000个样本),训练集与测试集比例是9:1(训练集:4500个样本,测试集:500个样本)
从结果可以看出,CNN对带有复合故障的数据集诊断准确率虽然不低,但是准确率不稳定。
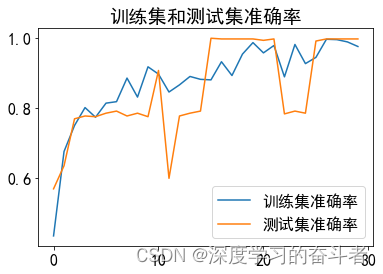

测试集的混淆矩阵(以样本个数呈现)
测试集的混淆矩阵(以准确率数呈现)
本次项目所有代码和数据放在了压缩包
import pandas as pd
import pandas as pd
import numpy as np
from keras.utils import np_utils
from sklearn import preprocessing
import tensorflow as tf
from matplotlib import pyplot as plt
#压缩包:https://mbd.pub/o/bread/ZJyTlp9y