深入篇【C++】【容器适配器】: (stack)&& (queue)&& (priority_queue)模拟实现(详细剖析底层实现原理)
- Ⅰ.容器适配器
- Ⅱ.认识deque
- Ⅲ.stack模拟实现
- Ⅳ.queue模拟实现
- Ⅴ.priority_queue模拟实现
- 1.priority_queue()
- 2.push()
- 3.pop()
- 4.仿函数
- 5.完整代码
Ⅰ.容器适配器
适配器是一种设计模式,该模式就是将一个类的接口转化成客户想要的另外一个接口。
简单来说就是对其他容器进行封装,利用这些容器的接口来实现想要的功能,然后再封装成一个接口供别人使用。容器适配器的本质就是复用。
比如stack和queue底层就是对其他容器进行了包装。STL中stack和queue底层默认使用的容器是deque。deque是什么,下面会介绍,这里我们先了解deque是一种类似vector和list的数据结构。
Ⅱ.认识deque
这里对deque不做深入的探究,只是介绍deque的功能和为什么可以作为栈和队列底层的默认容器。
我们首先要理解vector和list的各自特点:
vector:
1.利用下标随机访问。
2.存在扩容,大量移动数据问题。
3.存在中间头部删除插入数据,效率低下问题。
list:
1.任意位置插入删除都很方便。
2.不存在扩容释放问题。
3.不支持下标访问。
4.底层不是连续的空间,空间使用效率低。
deque是一个双向队列,头部和尾部都可以进行操作。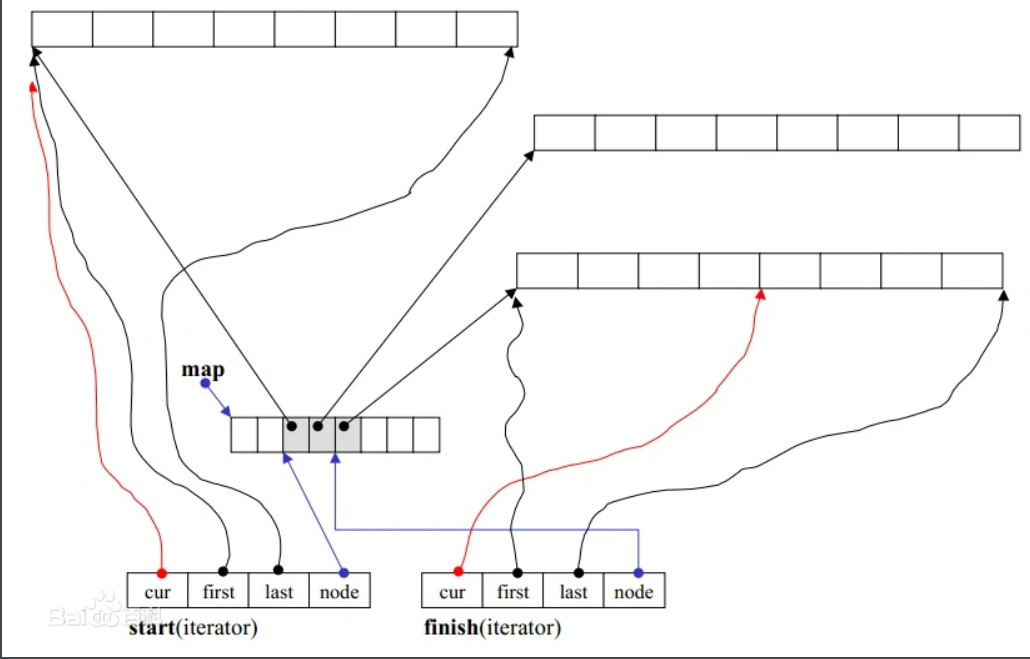
我们只要理解它和vector和list之间的区别就可以理解为什么要是有它作为底层的默认容器了。
1.deque相比vector:
优点:可以极大的缓解扩容问题和头插和头删问题。
缺点:下标访问不够极致,效率相比降低。
2.deque相比list
优点:可以支持下标访问。因为空间变得连续,cpu高速缓存效率变高。
缺点:头插头删尾删尾插效率都可以,只是中间插入和删除效率不行。
3.为什么要使用deque:
①deque很适合高频的头插头删,尾插尾删。而stack和queue就是只能对一端进行操作,所以很适合适配stack和queue的默认容器
②相比vector,不需要扩容,不存在头插头删挪动数据问题。
③相比list,不需要不断的空间释放空间,cpu缓存高。
但是要注意deque不适合高频的中间插入和删除,也不适合高频的随机访问。
如果要高频的中间插入删除,则使用list,如果需要高频的随机访问和排序最好使用vector。
deque可以看成是vector和list的结合体,具备vector和list不具备的优点。deque看似很牛,其实在现实中并不怎么使用。适合作为stack和queue底层的容器使用。
Ⅲ.stack模拟实现
stack的底层容器可以是任何标准的容器类模板或者一些其他特性的容器类,这些容器应该支持一下这些操作:{先进后出}
empty():判断是否为空。
push_back():尾插一个元素。
pop_back():尾删一个元素。
back():获取尾部元素。
因为stack不需要遍历,所以就没有通过迭代器。
通过数据结构中的stack我们知道,stack用数组和链表都可以实现的,那么在这里是如何实现的呢?
通过使用模板,来实例化出不同类的stack,所以我们需要两个模板参数,一个是用来控制stack的数据类型,一个用来控制stack的实现类型。
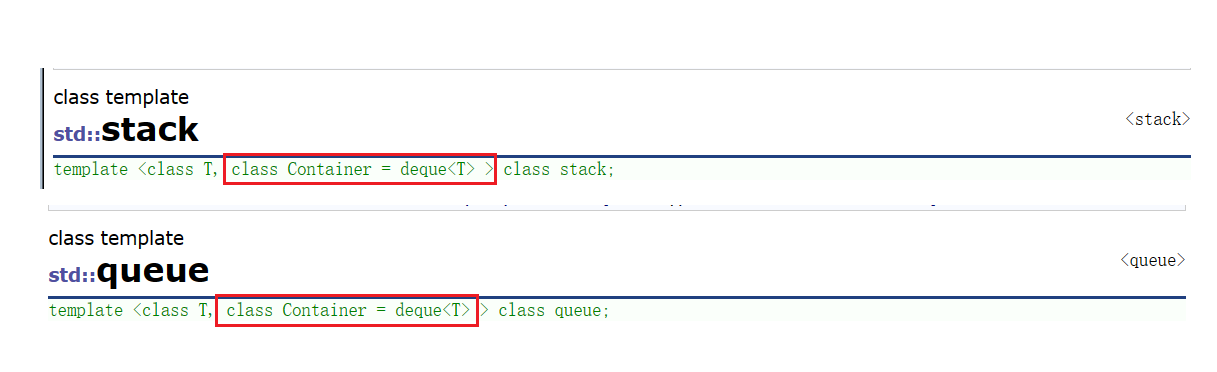
template<class T,class container>
T会根据使用的数据实例化不同的数据类型。
container会根据使用的容器来实例化出对应的容器类型。
namespace tao
{
//template<class T, class container=vector<T>>
//template<class T, class container=list<T>>
template<class T, class container=deque<T>>
//container容量适配器可以是vector可以是list可以是deque,这里给模板参数使用缺省值,默认使用deque作为底层容器。
class stack
{
public:
void push(const T& val)//入栈
{
_con.push_back(val);
}
void pop()//出栈
{
_con.pop_back();
}
T& top()//获取栈顶元素
{
return _con.back();
}
size_t size()//获取栈的大小
{
return _con.size();
}
bool empty()//判断栈是否为空
{
return _con.empty();
}
private:
//对容器进行封装,来实现自己想要的接口
container _con;
//通过模板参数,定义一个容器,这个容器要支持上面所说的操作。
};
}
| stack接口 | 功能 |
|---|---|
| push | 数据入栈 |
| pop | 数据出栈 |
| top | 获取栈顶元素 |
| empty | 判断栈是否为空 |
| size | 获取栈的大小 |
测试:
void test1()
{
stack<int, vector<int>> s;
//用数组vector构成的栈
s.push(1);
s.push(2);
s.push(3);
s.push(4);
while (!s.empty())
{
cout << s.top() << " ";
s.pop();
}
cout << endl;
//用链表list构成的栈
stack<int, list<int>> l;
l.push(1);
l.push(2);
l.push(3);
l.push(4);
l.push(5);
while (!l.empty())
{
cout << l.top() << " ";
l.pop();
}
cout << endl;
stack<int> s;//不指定容器类型,则默认使用缺省参数deque
//默认用deque构成的栈
s.push(1);
s.push(2);
s.push(3);
s.push(4);
while (!s.empty())
{
cout << s.top() << " ";
s.pop();
}
cout << endl;
Ⅳ.queue模拟实现
queue的底层容器可以是任何标准的容器类模板或者一些其他特性的容器类,这些容器应该支持一下这些操作:{先进先出}
empty():判断是否为空
push_back():尾插一个元素,入队列。
pop_front():头删一个元素,出队列。
front():获取队头数据
namespace tao
{
template<class T,class container=deque<T>>
//默认使用deque作为底层容器
class queue
{
public:
void push(const T& val)//入队列
{
_con.push_back(val);
}
void pop()//出队列
{
_con.pop_front();
}
T& top()//获取队头数据
{
return _con.front();
}
size_t size()//获取队列大小
{
return _con.size();
}
bool empty()//判断队列是否为空
{
return _con.empty();
}
private:
container _con;//底层封装_con这个容器,利用_con的各个接口来实现自己想要的接口。
};
}
| queue接口 | 功能 |
|---|---|
| push | 数据入队列 |
| pop | 数据出队列 |
| top | 获取队头数据 |
| empty | 判断队列是否为空 |
| size | 获取队列的大小 |
测试:
void test3()
{
queue<int, list<int>> q;
//底层使用list构建的队列
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.top() << " ";
q.pop();
}
cout << endl;
queue<int> q1;
//默认使用deque作为底层容器
q1.push(1);
q1.push(2);
q1.push(3);
q1.push(4);
while (!q1.empty())
{
cout << q1.top() << " ";
q1.pop();
}
cout << endl;
}
Ⅴ.priority_queue模拟实现
priority_queue称为优先级队列,与stack和queue类似也是容器适配器,底层是用vector容器封装实现的,不过与stack和queue不同的是,priority_queue不是简单的对容器进行封装,还使用了算法来配合容器接口来实现,其底层本质是一个二叉树的堆,使用vector来构建,再加上堆的算法,将这个线性表构建成堆的结构。所以如果需要堆的地方,就可以考虑使用priority_queue。
还有注意默认情况下,建立的堆结构是大堆。这里说明下,优先级队列的创建大堆和小堆的方式是是通过使用不同的伪函数来实现的。什么是伪函数下面会进行介绍。
我们想一想堆有什么接口呢?
| priority_queue接口 | 功能 |
|---|---|
| priority_queue | 构造对象 |
| push | 数据入堆,尾插一个元素 |
| pop | 数据出堆,头部删除一个元素 |
| top | 获取堆顶数据 |
| empty | 判断堆是否为空 |
| size | 获取堆的大小 |
1.priority_queue()
将一个数组构建成堆,那么如何调整呢?这个过程就是建堆过程。利用向下调整算法进行建堆。
而向下调整算法使用的前提是左右子树都是堆结构才可使用。所以我们实现的方法是:
【从最后一个叶子结点的父亲开始向下调整】
①向下调整,顾名思义应当传的是父亲结点。
②首先我们要记录孩子结点的位置。
③默认child是左右孩子中较大的那一个,要与右孩子比较一下看是否右孩子大。
④用较大的孩子与父亲比较,如果孩子大于父亲,则要进行交换(建大堆),否则就停止调整。
⑤交换完后,还要持续的往下调整,利用迭代思想,将父亲位置挪动儿子位置,那么儿子就变成父亲了。再重新记录新孩子的位置。这样持续的往下找,直到孩子的下标超过了数组范围。
void Adjustdown(int parent)
{
//首先找到左右孩子中较大的那一个
int child = parent * 2 + 1;
//默认左孩子是小的
if (child + 1 < _con.size() && _con[child] <con[child + 1])
{
++child;
}
while (child<_con.size())
{
//比较父节点和孩子结点
if ( _con[parent] < _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
优先级队列实例化出的对象本身就是一个堆,所以我们需要在它的构造函数里就将建堆工作做好。不像前面的stack和queue我们不需要写构造函数的,因为自定义成员变量,初始化时,会调用默认构造函数或者它自己的构造函数。
而这里构造函数需要构造出一个堆,需要我们自己手动操作了。

我们注意到优先级队列的构造函数可以使用迭代器来初始化。
所以我们也就可以定义一个迭代器模板参数。
//构造函数--用迭代区间来构造函数
//这个迭代器可以写成模板
template<class InputIterator>
priority_queue(InputIterator begin,InputIterator last)
{
//第一首先将数据插入进去
while (begin != last)
{
_con.push_back(*begin);
++begin;
}
//第二需要建堆,默认建的是大堆--利用向下调整算法建堆
//从最后一个叶子结点的父亲开始向下调整,然后依次往前走,直到走到堆顶。
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown(i);
}
2.push()
当我们先要插入一个元素进入数组里,直接尾插利用所给的容器接口尾插到数组里。
但尾插完,要注意这个堆结构是否被破坏,如果被破坏了,需要进行调整。那么如何调整呢?我们实现的方法是:
【向上调整算法】
①顺着插入位置的双亲往上调整即可,不需要管另一侧的树,因为插入一个元素后,只会影响左子树,或者右子树的结构。
②向上调整,顾名思义,传的应该是孩子结点位置。
③首先要记录父亲位置。
④找左右孩子中比较大的孩子与父亲比较。
⑤如果孩子大于父亲则进行交换(大堆),否则停止调整。
⑥交换完后,还要持续向上调整,将孩子位置挪动父亲位置上,这样孩子就变成父亲了,再重新记录新的父亲位置。直到父亲的位置到达堆顶位置。
void Adjustup(int child)//向上调整只要一直顺着双亲向上调整即可
{
//首先确定父节点位置
int parent = (child - 1) / 2;
while (child>0)
{
//然后比较父节点与这个结点的大小--默认大堆
if (_con[parent] < _con[child]))
{
//不需要管另一个子结点(如何有的话,因为child之前都是堆,满足堆的性质,比如大堆,那么子结点一定小于父节点的)
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
void push(const T& val)
{
//首先将元素尾插到数组里
_con.push_back(val);
//使用向上调整算法,调整堆
Adjustup(_con.size()-1);
}
3.pop()
当我们需要删除一个元素时,该如何删除呢?堆的删除只有头删这个接口,那堆顶的删除该如何删除呢?还是需要使用到向下调整算法
①首先交换堆顶数据和堆尾数据
②删除堆尾数据。
③利用向下调整算法从堆顶进行调整。
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
//里面封装着容器,直接用容器删除最后一个数据
_con.pop_back();
Adjustdown(0);
}
其他的比如获取堆顶元素,堆的大小,堆是否为空就简单多了。
T& top()
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
4.仿函数
什么是仿函数呢?仿函数就是一个类的对象可以像函数一个使用。如何达到这样的效果呢?就是在类里重载()运算符,这样对象调用这个运算符重载函数时,看起来就像在调用函数。比如下面两个仿函数。
template<class T>
class Less
{
public:
bool operator()( T& x, T& y)//重载()运算符 其实本质也是一种泛型, 对控制比较的泛型
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()( T& x, T& y)//重载() 也是一种泛型, 对控制比较的泛型
{
return x > y;
}
};
实例化出对象后,对象调用这个仿函数,看起来就像直接在调用less这个函数。
//仿函数--->类对象可以像函数一样使用本质就是类里重载了运算符()
tao::Less<int> less;
int x = 1;
int y = 2;
cout << less(x, y) << endl;;
那仿函数有什么用呢.
那仿函数有什么用呢优先级队列默认建的是大堆,那么大堆是如何建立的呢?我们是通过在构造建堆时,比较父节点和较大子节点的大小,进而控制大堆的。这样的写法是写死了,固定了,不能再修改了,如果我们像建立小堆,难道还要再拷贝一份,手动去改下符号吗?这未免太挫了吧。所以有的人就想出使用仿函数控制比较,进而控制大堆还是小堆,再增加一个模板参数用来传递仿函数,仿函数可以控制比较方式。这样就可以灵活的传递仿函数来控制创建大堆还是小堆。
所以我们可以用代码中用于比较的部分用仿函数来代替这样就可以灵活变化了。
5.完整代码
namespace tao
{
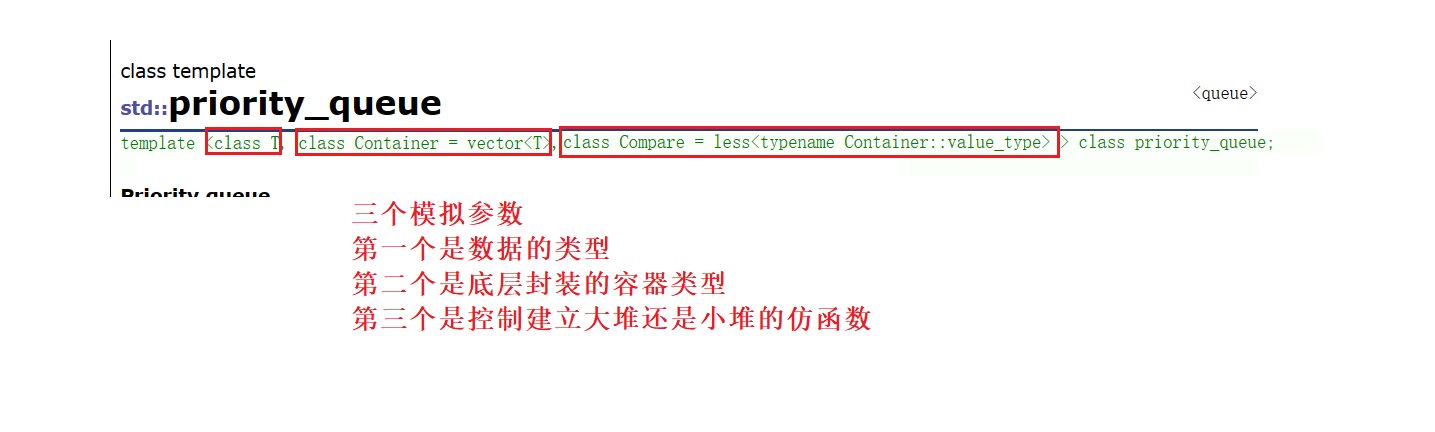
template<class T, class container=vector<T>,class compare=Less<T>>//通过第三个仿函数来控制比较,进而控制大堆还是小堆
//默认的那种方式是写死了,而这种方法通过仿函数
//通过模板参数来控制比较方式,比较类型又通过重载()
class priority_queue
{
private:
compare com;//比较泛型---灵活比较
void Adjustdown(int parent)
{
//首先找到左右孩子中较大的那一个
int child = parent * 2 + 1;
//默认左孩子是小的
if (child + 1 < _con.size() && com(_con[child] ,_con[child + 1]))
{
++child;
}
while (child<_con.size())
{
//比较父节点和孩子结点
if ( com(_con[parent] , _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Adjustup(int child)//向上调整只要一直顺着双亲向上调整即可
{
//首先确定父节点位置
int parent = (child - 1) / 2;
while (child>0)
{
//然后比较父节点与这个结点的大小--默认大堆
if (com(_con[parent] , _con[child]))
{
//不需要管另一个子结点(如何有的话,因为child之前都是堆,满足堆的性质,比如大堆,那么子结点一定小于父节点的)
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
public:
//构造函数--用迭代区间来构造函数
//这个迭代器可以写成模板
template<class InputIterator>
priority_queue(InputIterator begin,InputIterator last)
{
//第一首先将数据插入进去
while (begin != last)
{
_con.push_back(*begin);
++begin;
}
//第二需要建堆,默认建的是大堆--利用向下调整算法建堆
//从最后一个叶子结点的父亲开始向下调整
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown(i);
}
}
priority_queue()
{}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
//里面封装着容器,直接用容器删除最后一个数据
_con.pop_back();
Adjustdown(0);
}
void push(const T& val)
{
_con.push_back(val);
//使用向上调整算法,调整堆
Adjustup(_con.size()-1);
}
T& top()
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
container _con;
//容器适配器,封装了一个容器,但优先级队列不只是简单的容器封装还对容器里的数据进行了加工。插入尽量的数据还要利用算法进行调整
};
//仿函数/函数对象?
template<class T>
class Less
{
public:
bool operator()( T& x, T& y)//重载()运算符 其实本质也是一种泛型, 对控制比较的泛型
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()( T& x, T& y)//重载() 也是一种泛型, 对控制比较的泛型
{
return x > y;
}
};
测试:
void test1()
{
//第三个模板参数可以不给,因为默认是大堆
tao::priority_queue<int,vector<int>> pq;
//但写了也没事,如果想建立小堆,需要显式写出。
//priority_queue<int,vector<int>,less<int>> pq 默认是大堆
//priority_queue<int, vector<int>, greater<int>> pq;这样才是小堆
pq.push(1);
pq.push(2);
pq.push(3);
pq.push(4);
pq.push(5);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
}