redis的持久化方式有2种,rdb,即通过快照的方式将全量数据以二进制记录在磁盘中,aof,仅追加文件,将增量的写命令追加在aof文件中。在恢复的时候,rdb要更快,但是会丢失一部分数据。aof丢失数据极少,但是恢复数据很慢。redis默认使用rdb进行持久化。
下面结合配置文件对2种方式进行讲解。
RDB
redis默认的持久化方式就是rdb。可以手动通过命令触发,如save,前台阻塞去rdb持久化;bgsave,后台rdb持久化(其实就是另起一个线程去做持久化)
################################ SNAPSHOTTING ################################
# Save the DB to disk.
#
# save <seconds> <changes> [<seconds> <changes> ...]
#
# Redis will save the DB if the given number of seconds elapsed and it
# surpassed the given number of write operations against the DB.
#
# Snapshotting can be completely disabled with a single empty string argument
# as in following example:
#
# save ""
#
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 change was performed
# * After 300 seconds (5 minutes) if at least 100 changes were performed
# * After 60 seconds if at least 10000 changes were performed
#
# You can set these explicitly by uncommenting the following line.
#
# save 3600 1 300 100 60 10000
如果不想开启rdb,可以使用save ""来关闭rdb。
默认的,rdb会开启# save 3600 1 300 100 60 10000 的频率,意思为,3600秒(1小时)有1次写命令,进行rdb备份;或者300秒(5分钟)有100次写命令,进行rdb备份;或者60秒(1分钟)有10000次写命令,进行rdb备份。判断顺次进行,满足任意一个,都会开启rdb。
如果想修改,按照这个格式自己修改就可以。
# The filename where to dump the DB
dbfilename dump.rdb
其实就是命名一下rdb备份文件,默认命名为dump.rdb。这个文件只会有一个,如果备份了新的,旧的就会被删除。
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /var/lib/redis/6379
指定备份文件的路径,aof的文件也会放在这个路径下。
AOF
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check https://redis.io/topics/persistence for more information.
翻译如下:
默认情况下,Redis将数据集异步转储到磁盘上。这种模式在许多应用程序中已经足够好了,但是Redis进程的问题或停电可能会导致几分钟的写丢失(取决于配置的保存点)。
#只追加文件是另一种持久性模式,提供了更好的持久性。例如,使用默认的数据同步策略(见后面的配置文件),Redis可以在一个戏剧性的事件中只丢失一秒钟的写,比如服务器停电,或者如果Redis进程本身发生了错误,只丢失一次写,但操作系统仍然正常运行。
可以同时启用AOF和RDB持久性而不会出现问题。如果在启动时启用AOF, Redis将加载AOF,这是具有更好的持久性保证的文件。
由rdb的备份机制可知,默认的备份机制为,1小时1次写命令 | 5分钟100次写命令 | 1分钟10000次写命令。这样的触发机制,不管写命令是多是少,如果遇到停电等问题,丢失的数据相对来说都会比较多。如果你不想丢失这么多的数据,就需要开启aof。如果rdb和aof同时开启,aof和rdb都会备份,但是恢复时会使用aof。
# The fsync() call tells the Operating System to actually write data on disk
# instead of waiting for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
#
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
这部分配置的是aof触发追加的时机,或者说策略。在讲策略之前,需要先了解fsync和内核。
如果没有调用fsync,内核会等待更多的数据,直到在buffer缓冲区满了之后向磁盘进行IO。
fsync是一个底层的函数,redis通过调用这个fsync函数,可以使内核不必等待buffer满而直接去向disk磁盘进行IO。
而aof的追加策略有3种,
always是说每次写命令,都直接调fsync,向磁盘中的文件里追加。
no不是不追加,而是不调用fsync,会在内核满了以后由内核向磁盘文件中IO追加。
everysec比较折中,每一秒会固定调用一次fsync,此外如果一秒中内核的buffer满了多次,内核也会多次向磁盘进行IO。
# When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync no". In practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no
在我们执行rdb的bgsave或者aof的bgrewriteaof时,是另外起一个线程进行IO的。而代码片段里讲,即使是这样,也会阻塞接受命令的主线程。即使现在的版本已经到7了还没有解决这个问题,所以暂时的办法就是你可以选择在后台备份rdb文件或者重写aof文件时,暂停备份。在最坏的情况下,最长有可能丢失30s的备份。
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
在介绍这2个参数之前,我们需要先介绍一下aof文件的重写。aof文件在过大时,会进行重写。在后台重写的命令为bgrewriteaof(另外开一个线程,但是会阻塞主线程对aof文件的fsync),前台重写
在4版本之前,仅会将抵消掉的命令在重写后清除。
在4以后到7之前,重写时会将全量数据转为rdb的格式(但要注意存储在aof文件中),有新的写命令追加进来后,仍然以aof格式存储在同一个aof文件中。仍然为aof格式,一同存储在aof文件中。
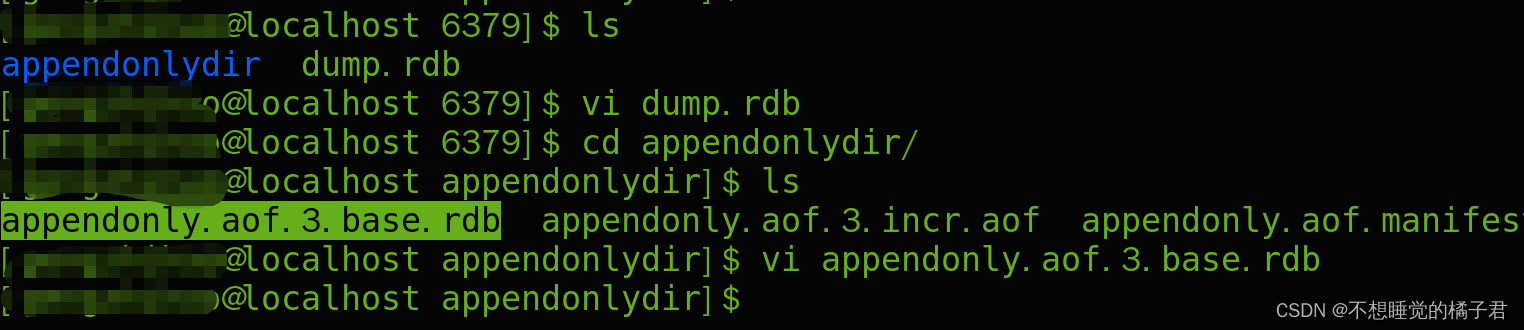
而7开始,aof文件一共分为3个,appendonly.aof.3.base.rdb appendonly.aof.3.incr.aof appendonly.aof.manifest,
appendonly.aof.1.incr.aof文件,存储的是重写后的增量部分的写命令,为aof格式。
appendonly.aof.1.base.rdb文件,存储的是重写时的全量数据,转为rdb格式存在这个文件中。
上述2个文件,每次重写,数字部分的版本号都会+1.
appendonly.aof.manifest文件存储了关于另外2个文件的信息。
这样,aof在恢复时,先通过vase.rdb快速恢复大部分数据,再通过aof文件恢复重写后的增量数据,兼顾了快和全。
aof文件的重写,可以通过bgrewriteaof命令手动触发重写,也可以配置策略,当aof文件超过多大时自动重写。
好,知道了aof的重写以后,可以去介绍这2个参数了。redis每次重写以后,都会记录重写后的aof文件(在7版本aof文件重写默认为rdb格式)的大小,配置文件的注释中称其为base size,而新的aof文件的大小称其为current size。
当current size超过了base size指定百分比时,就会触发重写。如auto-aof-rewrite-percentage为100%时,一个200M的aof文件重写后,会和之前存量的rdb文件里的数据合并为一个rdb文件,假设合并后的新的rdb文件为500M,那么base size为500M,新的aof文件如果超过了500M*100%,那么就会触发重写。
# Redis can create append-only base files in either RDB or AOF formats. Using
# the RDB format is always faster and more efficient, and disabling it is only
# supported for backward compatibility purposes.
aof-use-rdb-preamble yes
上面说过,7版本的aof文件重写后默认为rdb文件,在这里可以选择no,重写后为aof文件。默认为yes rdb文件。
上面,通过结合配置文件,讲了一下rdb和aof,下面简单的看一下2个文件实际长什么样吧。
rdb
rdb的文件默认叫dump.rdb,和aof文件所在目录appendonlydir同级。dump.rdb中可见
REDIS0010ú redis-ver^F7.0.12ú
redis-bitsÀ@ú^Ectime Ádú^Hused-memÂ^X^[^M^@ú^Haof-baseÀ^@ÿOx!Íܧ¤µ
~
~
~
~
aof
base文件里面存储的重写时的全量数据,默认以rdb格式存储,更快。也可以指定为aof格式存储。
appendonly.aof.3.base.rdb
REDIS0010ú redis-ver^F7.0.12ú
redis-bitsÀ@ú^EctimeÂø<94>¿dú^Hused-memÂ0W^O^@ú^Haof-baseÀ^Aÿo{Ag+/ÿ7
~
~
~
重写后的增量数据,在incr.aof文件中存储。aof如何存储命令的呢,以下面作为示例。
刚进入redis-cli时,默认为0号库,也就是select 0. 2表示这个命令由2个部分(字符串)组成,$6表示下面的字符串有6个字符,即SELECT;$1表示下面的字符串有1个字符,即0.
再遇到下面的3,表示一个命令开始,由3个部分组成。同理,可知命令为set k1 v1。
appendonly.aof.3.incr.aof
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$2
v1
*3
$3
set
$2
k1
$2
v2
*3
$3
set
$2
k2
$2
v2
*3
appendonly.aof.manifest
file appendonly.aof.3.base.rdb seq 3 type b
file appendonly.aof.3.incr.aof seq 3 type i
~
~
~
~
~
~
~
~