推理器类型:
(1)ImageClassificationInferencer:对给定图像进行图像分类。
(2)ImageRetrievalInferencer:从给定图像集上的给定图像执行图像到图像检索。
(3)ImageCaptionInferencer:在给定图像上生成标题
(4)VisualQuestionAnsweringInferencer:根据给定的图片回答问题。
(5)VisualGroundingInferencer:从给定图像的描述中找到一个对象。
(6)TextToImageRetrievalInferencer:根据给定图像集的给定描述执行文本到图像检索。
(7)ImageToTextRetrievalInferencer:从给定图像对一系列文本执行图像到文本检索。
(8)NLVRInferencer:对给定的图像对和文本执行自然语言视觉推理。
(9)FeatureExtractor:通过视觉主干从图像文件中提取特征。
列出可用型号
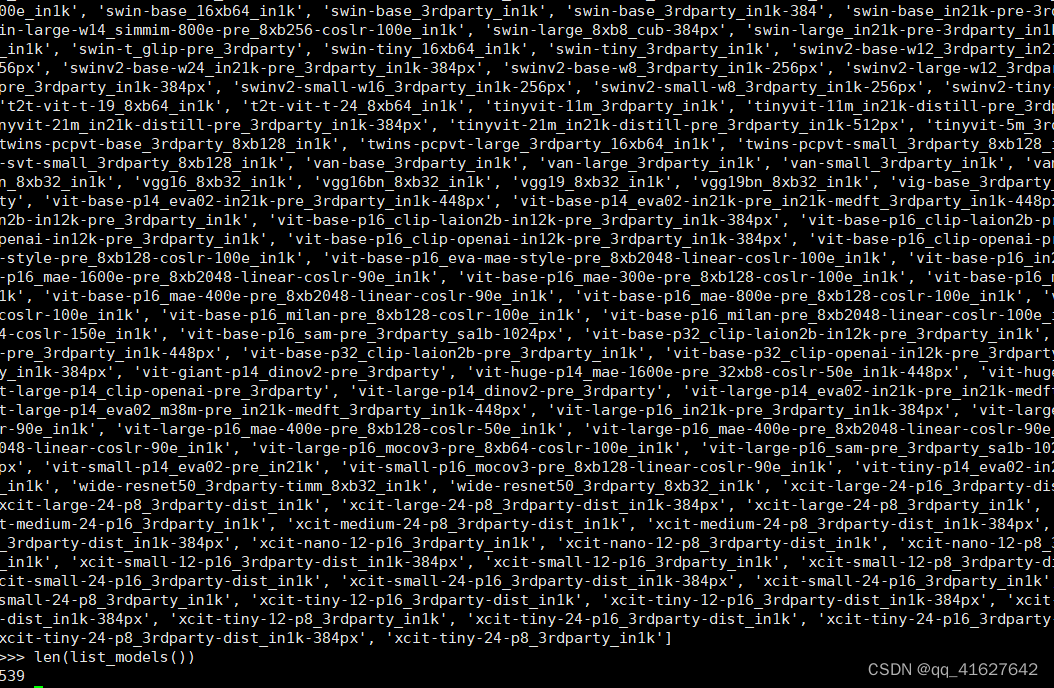
列出 MMPreTrain 中的所有模型。
from mmpretrain import list_models
list_models()#目前共有539个模型
可用型号搜索
list_models支持Unix文件名模式匹配,可以使用*** * **来匹配任何字符。
from mmpretrain import list_models
list_models("*convnext-b*21k")

获取相应任务的可用模型
您可以使用list_models推理器的方法来获取相应任务的可用模型。
1、Get a model
you can use get_model get the model.
from mmpretrain import get_model
model = get_model("convnext-base_in21k-pre_3rdparty_in1k")
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained=True)
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained="your_local_checkpoint_path")
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", head=dict(num_classes=10))
model_headless = get_model("resnet18_8xb32_in1k", head=None, neck=None, backbone=dict(out_indices=(1, 2, 3)))
获得的模型是常用的 PyTorch 模块
import torch
from mmpretrain import get_model
model = get_model('convnext-base_in21k-pre_3rdparty_in1k', pretrained=True)
x = torch.rand((1, 3, 224, 224))
y = model(x)
print(type(y), y.shape)
2、ImageClassificationInferencer:对给定图像进行图像分类任务可用模型
from mmpretrain import ImageClassificationInferencer
ImageClassificationInferencer.list_models()

1、通过inference_model进行任务推理
from mmpretrain import list_models, inference_model
list_models('resnet50', task='Image Classification')#给定任务和骨干网络预训练模型
inference_model('resnet50_8xb32_in1k', '/media/lhy/mmpretrain/demo/bird.JPEG', show=True)#给定预训练模型和图像的路径

2、通过ImageClassificationInferencer进行任务推理
该inference_model API仅用于演示,不能保留模型实例或对多个样本进行推理。您可以使用推理器进行多次调用。
1. 使用MMPreTrain中的预训练模型对图像进行推理。
from mmpretrain import list_models, ImageClassificationInferencer
image = '/media/lhy/mmpretrain/demo/bird.JPEG'
inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
# Note that the inferencer output is a list of result even if the input is a single sample.
result = inferencer(image)[0]
print(result['pred_class'])
print(result['pred_score'])
print(result['pred_label'])
# You can also use is for multiple images.
image_list = ['demo/demo.JPEG', 'demo/bird.JPEG'] * 16
results = inferencer(image_list, batch_size=8)
print(len(results))
print(results[1]['pred_class'])
2. 使用配置文件和检查点来推断GPU上的多个图像,并将可视化结果保存在文件夹中。
from mmpretrain import ImageClassificationInferencer
inferencer = ImageClassificationInferencer(model='configs/resnet/resnet50_8xb32_in1k.py',
pretrained='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',device='cuda')
inferencer(['demo/dog.jpg', 'demo/bird.JPEG'], show_dir="./visualize/")
visualize_kwargs: set = {
'resize', 'rescale_factor', 'draw_score', 'show', 'show_dir',
'wait_time'
}
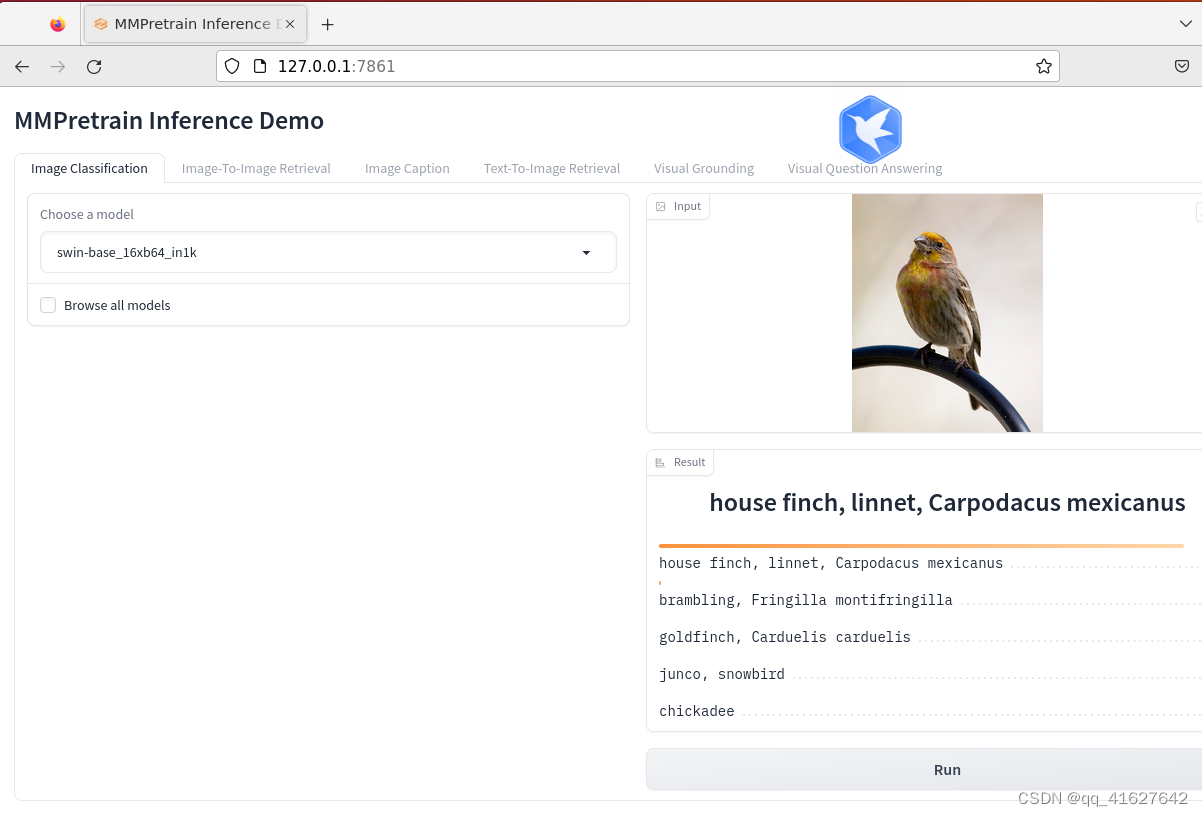
3、gradio 演示进行任务推理
3、ImageRetrievalInferencer:从给定图像集上的给定图像执行图像到图像检索
from mmpretrain import ImageRetrievalInferencer
ImageRetrievalInferencer.list_models()

2、通过ImageRetrievalInferencer进行任务推理
from mmpretrain import list_models,ImageRetrievalInferencer
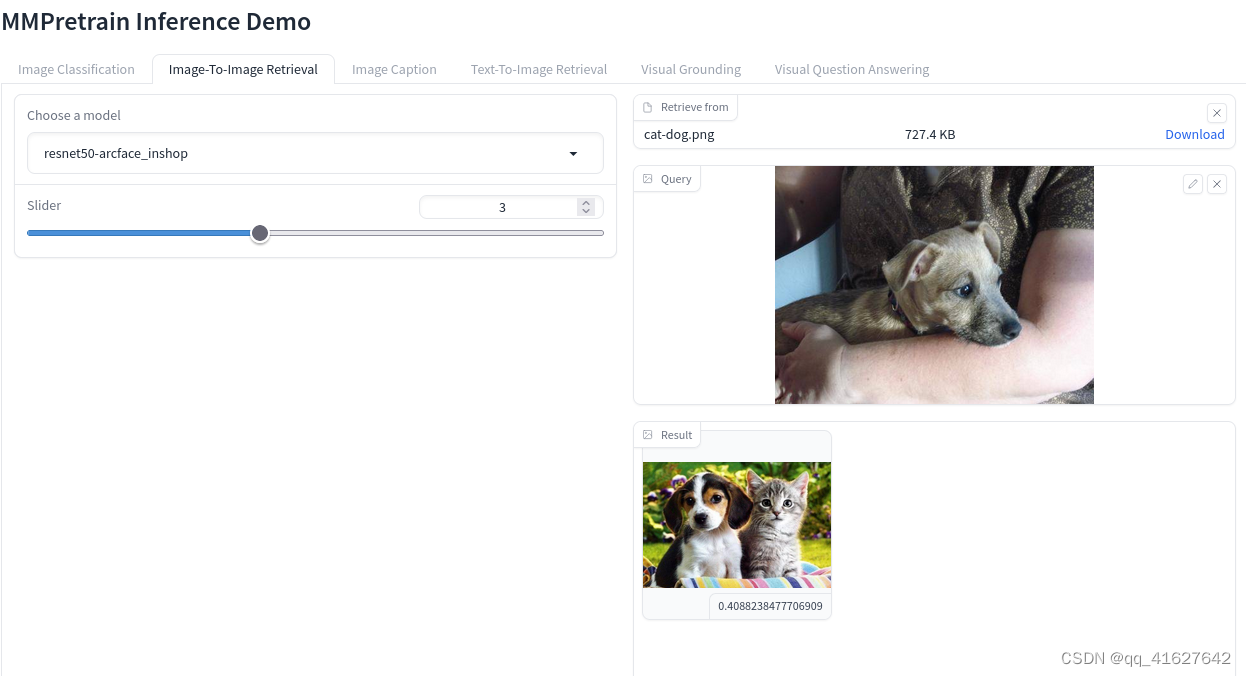
inferencer = ImageRetrievalInferencer('resnet50-arcface_inshop',prototype=['/media/lhy/mmpretrain/demo/demo.JPEG', '/media/lhy/mmpretrain/demo/dog.jpg'],prototype_cache='img_retri.pth')
#prototype检索的图像列表
inferencer('/media/lhy/mmpretrain/demo/cat-dog.png', topk=2)[0][1]
{'match_score': tensor(0.4088, device='cuda:0'),
'sample_idx': 3,
'sample': {'img_path': './demo/dog.jpg'}}
""" # noqa: E501
visualize_kwargs: set = {
'draw_score', 'resize', 'show_dir', 'show', 'wait_time', 'topk'
}
postprocess_kwargs: set = {'topk'}
4、ImageCaptionInferencer(在给定图像上生成标题)任务可用模型
from mmpretrain import ImageCaptionInferencer
ImageCaptionInferencer.list_models()
['blip-base_3rdparty_caption',
'blip2-opt2.7b_3rdparty-zeroshot_caption',
'flamingo_3rdparty-zeroshot_caption',
'llava-7b-v1_caption',
'minigpt-4_vicuna-7b_caption',
'ofa-base_3rdparty-finetuned_caption',
'otter-9b_3rdparty_caption']
1、通过inference_model进行任务推理
from mmpretrain import list_models, inference_model
list_models(task='Image Caption') #给定任务和骨干网络预训练模型
inference_model('ofa-base_3rdparty-finetuned_caption', '/media/lhy/mmpretrain/demo/cat-dog.png', show=True)

2、通过ImageCaptionInferencer进行任务推理
from mmpretrain import ImageCaptionInferencer
inferencer = ImageCaptionInferencer('blip-base_3rdparty_caption')
inferencer('/media/lhy/mmpretrain/demo/cat-dog.png')[0]
{'pred_caption': 'a puppy and a cat sitting on a blanket'}
5、VisualGroundingInferencer:从给定图像的描述中找到一个对象任务可用模型
from mmpretrain import VisualGroundingInferencer
VisualGroundingInferencer.list_models()
[‘blip-base_8xb16_refcoco’, ‘ofa-base_3rdparty-finetuned_refcoco’]

1、通过inference_model进行任务推理
from mmpretrain import list_models, inference_model
list_models(task='Visual Grounding') #给定任务和骨干网络预训练模型
inference_model('ofa-base_3rdparty-finetuned_refcoco', '/media/lhy/mmpretrain/demo/cat-dog.png', 'cat', show=True)
2、通过ImageCaptionInferencer进行任务推理
from mmpretrain import VisualGroundingInferencer
inferencer = VisualGroundingInferencer('ofa-base_3rdparty_refcocinferencer('/media/lhy/mmpretrain/demo/cat-dog.png', 'dog')[0]
{'pred_bboxes': tensor([[ 36.6000, 29.6000, 355.8000, 395.2000]])}
""" # noqa: E501
6、TextToImageRetrievalInferencer:(根据给定图像集的给定描述执行文本到图像检索)任务可用模型
from mmpretrain import TextToImageRetrievalInferencer
TextToImageRetrievalInferencer.list_models()
['blip-base_3rdparty_retrieval', 'blip2_3rdparty_retrieval']

1、通过TextToImageRetrievalInferencer进行任务推理
from mmpretrain import TextToImageRetrievalInferencer
inferencer = TextToImageRetrievalInferencer('blip-base_3rdparty_retrieval',prototype='/media/lhy/mmpretrain/demo/',prototype_cache='t2i_retri.pth')
inferencer('A cat and a dog.')[0]
{'match_score': tensor(0.3855, device='cuda:0'),
'sample_idx': 1,
'sample': {'img_path': './demo/cat-dog.png'}}

7、ImageToTextRetrievalInferencer(从给定图像对一系列文本执行图像到文本检索)
from mmpretrain import ImageToTextRetrievalInferencer
ImageToTextRetrievalInferencer.list_models()