数据集资源
https://download.csdn.net/download/qq_42864343/88110620?spm=1001.2014.3001.5503
https://download.csdn.net/download/qq_42864343/88110686?spm=1001.2014.3001.5501
创建数据集目录
在YOLOv5根目录下创建mydata文件夹(名字可以自定义),目录结构如下,将之前labelImg标注好的xml文件和图片放到对应目录下
mydata
…images # 存放图片
…xml # 存放图片对应的xml文件
…dataSet #之后会在Main文件夹内自动生成train.txt,val.txt,test.txt和trainval.txt四个文件,存放训练集、验证集、测试集图片的名字(无后缀.jpg)
示例如下:
mydata文件夹下内容如下:
使用脚本划分训练集、验证集、测试集
dataSet 文件夹下面存放训练集、验证集、测试集的划分,通过脚本生成,在项目的根目录创建一个split_train_val.py文件,代码内容如下:
# coding:utf-8
import os
import random
import argparse
#通过argparse模块创建一个参数解析器。该参数解析器可以接收用户输入的命令行参数,用于指定xml文件的路径和输出txt文件的路径。
parser = argparse.ArgumentParser()
# 指定xml文件的路径
parser.add_argument('--xml_path', default='mydata/xml', type=str, help='input xml label path')
# 设置输出txt文件的路径
parser.add_argument('--txt_path', default='mydata/dataSet', type=str, help='output txt label path')
opt = parser.parse_args()
# 训练集与验证集 占全体数据的比例
trainval_percent = 1.0
# 训练集 占训练集与验证集总体 的比例
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
# 获取到xml文件的数量
total_xml = os.listdir(xmlfilepath)
#判断txtsavepath是否存在,若不存在,则创建该路径。
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
# 统计xml文件的个数,即Image标签的个数
num = len(total_xml)
list_index = range(num)
# tv (训练集和测试集的个数) = 数据总数 * 训练集和数据集占全体数据的比例
tv = int(num * trainval_percent)
# 训练集的个数
tr = int(tv * train_percent)
# 按数量随机得到取训练集和测试集的索引
trainval = random.sample(list_index, tv)
# 打乱训练集
train = random.sample(trainval, tr)
# 创建存放所有图片数据路径的文件
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
# 创建存放所有测试图片数据的路径的文件
file_test = open(txtsavepath + '/test.txt', 'w')
# 创建存放所有训练图片数据的路径的文件
file_train = open(txtsavepath + '/train.txt', 'w')
# 创建存放所有测试图片数据的路径的文件
file_val = open(txtsavepath + '/val.txt', 'w')
# 遍历list_index列表,将文件名按照划分规则写入相应的txt文件中
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行如上代码,成功划分数据集
使用脚本将训练集,测试集,验证集生成label标签
即将每个xml标注提取bbox信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。格式如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['smoke'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('mydata/xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('mydata/label/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('mydata/label/'):
os.makedirs('mydata/label/')
image_ids = open('mydata/dataSet/%s.txt' % (image_set)).read().strip().split()
list_file = open('mydata/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/mydata/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
这段代码是一个用于将XML格式的图像注释信息转换为YOLO格式的标签的脚本。主要包括以下几个步骤:
- 导入相关模块和库。
- 定义训练集、测试集和验证集的名称(在这里只有训练集)。
- 定义所需的物体类别(这里只有一个类别,即’smoke’)。
- 定义一个函数convert,用于将图像的边界框坐标转换为YOLO格式的相对坐标。
- 定义一个函数convert_annotation,用于将单个图像的注释信息转换为YOLO格式的标签。
- 获取当前工作路径,并打印输出。
- 针对每个数据集(训练集、测试集和验证集),创建保存标签的目录。
- 依次处理每个图像,将图像路径写入列表文件,并调用convert_annotation函数将图像的注释信息转换为YOLO格式的标签。
- 关闭列表文件。
在mydata中创建配置文件
命名为:smoke.yaml
# 图片路径
train: mydata/train.txt
val: mydata/val.txt
test: mydata/test.txt
# numbers of classes 我这个数据集只标注了香烟,所以类别为1
nc: 1
# class names
names: ['smoke']
下载yolov5的权重
链接:https://pan.baidu.com/s/1vlTmjNofB5kD3BOaSy4SnA
提取码:gr8v
在根目录创建weights文件夹
把下载好的权重放进去

我的预训练使用yolov5m,修改该文件的类别个数
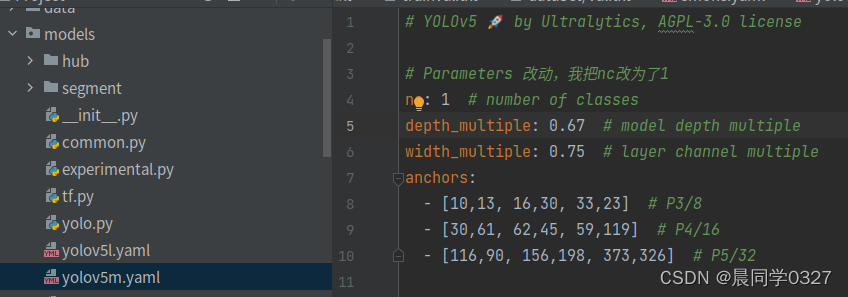
打开pycharm的terminal,运行如下命令
python train.py --data mydata/smoke.yaml --cfg models/yolov5m.yaml --weights weights/yolov5m.pt --epochs 100 --batch-size 16
报错
Failed to initialize: Bad git executable.
The git executable must be specified in one of the following ways:
- be included in your $PATH
- be set via $GIT_PYTHON_GIT_EXECUTABLE
- explicitly set via git.refresh()
All git commands will error until this is rectified.
This initial warning can be silenced or aggravated in the future by setting the
$GIT_PYTHON_REFRESH environment variable. Use one of the following values:
- quiet|q|silence|s|none|n|0: for no warning or exception
- warn|w|warning|1: for a printed warning
- error|e|raise|r|2: for a raised exception
Example:
export GIT_PYTHON_REFRESH=quiet
#出错原因:git环境变量设置问题
#简便解决办法:在train.py的导入包的上方增加以下代码
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
再次运行
python train.py --data mydata/smoke.yaml --cfg models/yolov5m.yaml --weights weights/yolov5m.pt --epochs 100 --batch-size 16
成功开始训练
模型测试
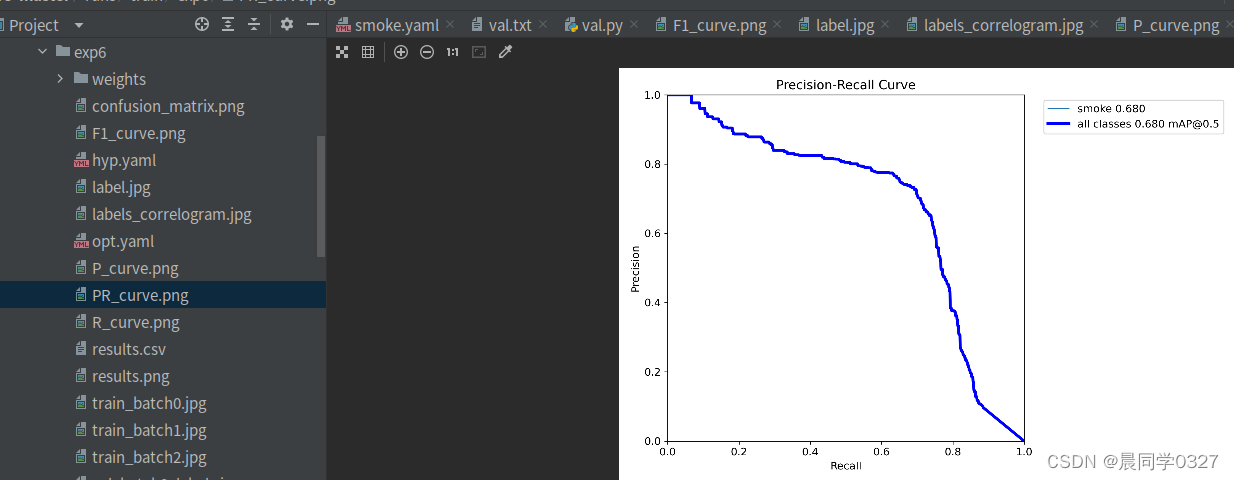
新版的yolov5在训练结束后自动进行了测试:
 测试结果在 runs/train/exp6中:
测试结果在 runs/train/exp6中:
打开准确率和召回率图片,结果如下:
使用训练好的模型进行检测
使用图片进行测试
在项目根目录创建 inference文件,在里面创建 images和output文件
python detect.py --weights runs/train/exp6/weights/best.pt --data mydata/smoke.yaml --source inference/images/ --project inference/output/ --device 0
运行报错:

解决方法:
https://blog.csdn.net/qq_42864343/article/details/131962108?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22131962108%22%2C%22source%22%3A%22qq_42864343%22%7D&ydreferer=aHR0cHM6Ly9tcC5jc2RuLm5ldC9tcF9ibG9nL2NyZWF0aW9uL3N1Y2Nlc3MvMTMxOTYyMTA4
运行结果:

使用视频进行测试
创建video文件夹,把视频放进去
python detect.py --weights runs/train/exp6/weights/best.pt --data mydata/smoke.yaml --source inference/video/ --project inference/output/ --device 0 --view_img true
运行完成后,直接保存了,没有展示出来。
在项目根目录创建python文件,让视频结果展示出来,内容如下:
import cv2
video = cv2.VideoCapture("./inference/output/exp4/video-test.mp4")
if video.isOpened():
# video.read() 一帧一帧地读取
# open 得到的是一个布尔值,就是 True 或者 False
# frame 得到当前这一帧的图像
open, frame = video.read()
else:
open = False
while open:
ret, frame = video.read()
# 如果读到的帧数不为空,那么就继续读取,如果为空,就退出
if frame is None:
break
if ret == True:
# 设置窗口为可调整
cv2.namedWindow('video', flags=cv2.WINDOW_NORMAL)
# 在这个可调整的窗口显示图片
cv2.imshow("video", frame)
# 这里使用 waitKey 可以控制视频的播放速度,数值越小,播放速度越快
# 这里等于 27 也即是说按下 ESC 键即可退出该窗口
if cv2.waitKey(200) & 0xFF == 27:
break
video.release()
cv2.destroyAllWindows()
运行该代码,检测结果:

展示视频检测结果
使用远程摄像头测试
python detect.py --weights runs/train/exp6/weights/best.pt --data mydata/smoke.yaml --source rtsp://账户:密码@ip/Streaming/Channels/1 --device 0 --project inference/output/
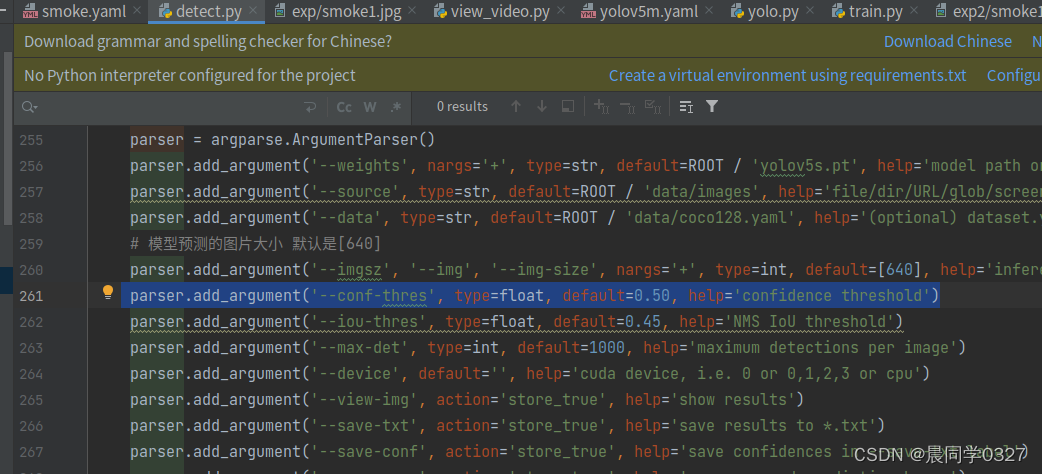
如果出现误检,可以把detect.py中的阈值调高

detect.py中原本的置信度阈值为0.25,发现出现了误检,因此把置信度阈值调为0.50
参考文献:
YOLOv5训练自己的数据集(超详细)
https://blog.csdn.net/qq_40716944/article/details/118188085
YOLOV5训练自己的数据集(踩坑经验之谈)https://blog.csdn.net/a_cheng_/article/details/111401500
yolov5 报错解决记录
https://blog.csdn.net/Sickas/article/details/129459630