文章目录
- 前言
- 运行效果截图
- 导入必要的模块和库
- 定义常量和变量
- 获取所有英雄的名称
- 遍历每个英雄
- 遍历每个英雄的皮肤
- 完整代码
- 结束语

前言
英雄联盟是一款备受喜爱的团队对战游戏,游戏中每位英雄都有各种精美的皮肤供玩家选择。本文将介绍一个使用Python编写的英雄联盟皮肤下载器,可以快速获取所有英雄的皮肤图片,让您更方便地欣赏和收藏这些皮肤。
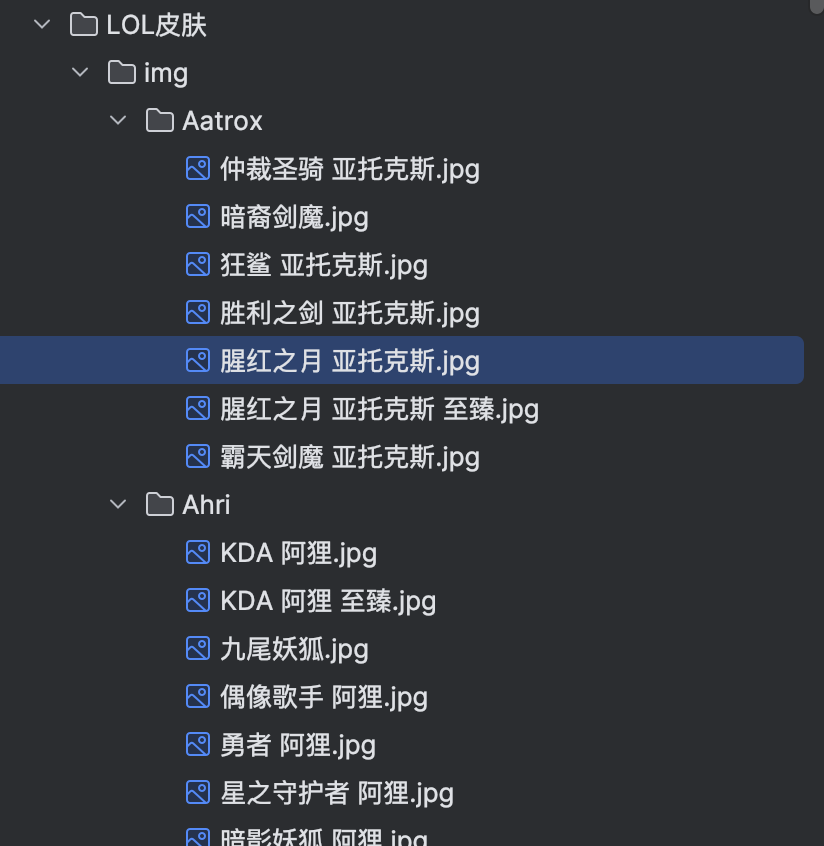
运行效果截图
导入必要的模块和库

import requests # pip install requests
import re
from time import sleep
import os
定义常量和变量

all_hero_url ='https://lol.qq.com/biz/hero/champion.js'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
all_hero_url:英雄URL地址headers:请求头,用于模拟浏览器发送请求
获取所有英雄的名称

all_hero_js_resp = requests.get(all_hero_url,headers = headers)
all_hero_name = re.findall(r'"\d+?":"(\w+?)"',all_hero_js_resp.text)
- 发送GET请求,获取英雄信息的JavaScript文件
- 通过正则表达式提取所有英雄的名称,并存储在
all_hero_name列表中
遍历每个英雄

for n in all_hero_name:
sleep(1)
hero_info_js_url =f'https://lol.qq.com/biz/hero/{n}.js'
hero_info_js_resp = requests.get(hero_info_js_url,headers=headers)
hero_info_js = hero_info_js_resp.text
hero_ids = re.findall(r'"id":"(\d+?)"',hero_info_js)
hero_names = re.findall(r'"name":"(.+?)".+?"chrom',hero_info_js)
- 遍历所有英雄的名称
- 构造每个英雄的详细信息JavaScript文件URL
- 发送GET请求,获取英雄详细信息的JavaScript文件
- 通过正则表达式提取英雄ID和皮肤名称,并分别存储在
hero_ids和hero_names列表中
遍历每个英雄的皮肤
for id,name in zip(hero_ids,hero_names):
img_url =f'https://game.gtimg.cn/images/lol/act/img/skin/big{id}.jpg'
# 发送请求
img_resp = requests.get(img_url,headers=headers)
name = name.encode().decode('unicode_escape')
name = name.replace('/','')
name = name.replace('\\','')
print(f'正在下载{n}的:{name}皮肤')
if not os.path.exists(f'./img/{n}'):
os.mkdir(f'./img/{n}')
with open(f'./img/{n}/{name}.jpg','wb') as f:
f.write(img_resp.content)
sleep(1)
- 遍历每个皮肤的ID和名称
- 构造每个皮肤的图片URL
- 发送GET请求,获取皮肤图片内容
- 对皮肤名称进行一些处理(编码转换、去除特殊字符)
- 打印下载信息
- 检查是否存在对应英雄的文件夹,如果不存在则创建
- 将皮肤图片保存到文件夹中
- 等待一秒,继续下载下一个皮肤
完整代码
import requests # 导入requests模块,用于发送HTTP请求
import re # 导入re模块,用于正则表达式匹配
from time import sleep # 导入sleep函数,用于休眠
# 定义常量和变量
all_hero_url ='https://lol.qq.com/biz/hero/champion.js' # 所有英雄URL地址
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
} # 请求头,用于模拟浏览器发送请求
# 获取所有英雄的名称
all_hero_js_resp = requests.get(all_hero_url,headers = headers) # 发送GET请求,获取英雄信息的JavaScript文件
all_hero_name = re.findall(r'"\d+?":"(\w+?)"',all_hero_js_resp.text) # 通过正则表达式提取所有英雄的名称,并存储在all_hero_name列表中
# 遍历每个英雄
for n in all_hero_name:
sleep(1) # 休眠1秒,避免请求频率过高被服务器拦截
hero_info_js_url =f'https://lol.qq.com/biz/hero/{n}.js' # 构造每个英雄的详细信息JavaScript文件URL
hero_info_js_resp = requests.get(hero_info_js_url,headers=headers) # 发送GET请求,获取英雄详细信息的JavaScript文件
hero_info_js = hero_info_js_resp.text # 获取JavaScript文件的内容
hero_ids = re.findall(r'"id":"(\d+?)"',hero_info_js) # 通过正则表达式提取英雄ID,并存储在hero_ids列表中
hero_names = re.findall(r'"name":"(.+?)".+?"chrom',hero_info_js) # 通过正则表达式提取皮肤名称,并存储在hero_names列表中
# 遍历每个英雄的皮肤
for id,name in zip(hero_ids,hero_names):
img_url =f'https://game.gtimg.cn/images/lol/act/img/skin/big{id}.jpg' # 构造每个皮肤的图片URL
img_resp = requests.get(img_url,headers=headers) # 发送GET请求,获取皮肤图片内容
name = name.encode().decode('unicode_escape') # 对皮肤名称进行编码转换,解决中文字符显示问题
name = name.replace('/','') # 去除名称中的斜杠字符
name = name.replace('\\','') # 去除名称中的反斜杠字符
print(f'正在下载{n}的:{name}皮肤')
if not os.path.exists(f'./img/{n}'):
os.mkdir(f'./img/{n}') # 检查是否存在对应英雄的文件夹,如果不存在则创建
with open(f'./img/{n}/{name}.jpg','wb') as f: # 将皮肤图片保存到文件夹中
f.write(img_resp.content)
sleep(1) # 休眠1秒,避免请求频率过高被服务器拦截
- 第1行:导入requests模块,用于发送HTTP请求。
- 第2行:导入re模块,用于正则表达式匹配。
- 第3行:从time模块中导入sleep函数,用于程序休眠。
- 第6行:定义常量
all_hero_url,表示所有英雄URL地址。 - 第7行:定义headers字典,包含用户代理信息,用于模拟浏览器发送请求。
- 第10行:发送GET请求获取英雄信息的JavaScript文件,并将响应结果赋值给
all_hero_js_resp。 - 第11行:使用正则表达式提取所有英雄的名称,并存储在
all_hero_name列表中。 - 第15行:使用for循环遍历每个英雄的名称。
- 第16行:休眠1秒,以避免请求频率过高被服务器拦截。
- 第17行:构造每个英雄的详细信息JavaScript文件URL。
- 第18行:发送GET请求获取英雄详细信息的JavaScript文件,并将响应结果赋值给
hero_info_js_resp。 - 第19行:获取JavaScript文件的内容。
- 第20行:使用正则表达式提取英雄ID,并存储在
hero_ids列表中。 - 第21行:使用正则表达式提取皮肤名称,并存储在
hero_names列表中。 - 第25行:使用for循环遍历每个英雄的皮肤。
- 第26行:构造每个皮肤的图片URL。
- 第27行:发送GET请求获取皮肤图片内容,并将响应结果赋值给
img_resp。 - 第28行:对皮肤名称进行编码转换,解决中文字符显示问题。
- 第29行:去除名称中的斜杠字符。
- 第30行:去除名称中的反斜杠字符。
- 第31行:打印下载信息。
- 第32-34行:检查是否存在对应英雄的文件夹,如果不存在则创建。
- 第35行:将皮肤图片保存到对应的文件夹中。
- 第36行:休眠1秒,以避免请求频率过高被服务器拦截。
代码使用Python的requests模块发送HTTP请求,使用re模块进行正则表达式匹配。通过解析游戏官网的数据接口,获取英雄和皮肤信息,并保存为本地文件。其中,sleep函数用于控制请求间隔,避免频繁请求导致被服务器拦截。代码还涉及文件和文件夹的操作,如创建文件夹、保存图片文件等。整体上,这段代码是一个简单的网络爬虫,用于批量下载英雄联盟的皮肤图片。
结束语
英雄联盟皮肤下载器是一个简单而实用的工具,让您能够快速获取所有英雄的皮肤图片。通过运行代码,您可以轻松地收集和保存英雄联盟中所有英雄的各种精美皮肤,无需手动下载。这个工具不仅适用于英雄联盟的玩家,也可以作为收藏者的便利工具,帮助您更好地欣赏和管理这些精美的皮肤设计。希望本文介绍的英雄联盟皮肤下载器对您有所帮助,让您在游戏中尽情享受每位英雄的独特魅力。