系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
本文目录
- 系列文章目录
- 一、DataLoader是什么?
- 二、使用步骤
- 1.相关参数
- 2.引入库
- 3.创建数据(使用CIFAR10为例)
- 4.创建DataLoader实例
- 5.在Tensorboard中显示即完整代码如下
一、DataLoader是什么?
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),如果把Dataset比作一副扑克牌,则DataLoader就是每次手中处理的某一批扑克牌,然后每一批取多少张,总共能取多少批,用不用打乱顺序等,都可以在创建DataLoader时从参数自行设定。
二、使用步骤
1.相关参数
class DataLoader(Generic[T_co]):
r"""
Data loader. Combines a dataset and a sampler, and provides an iterable over
the given dataset.
The :class:`~torch.utils.data.DataLoader` supports both map-style and
iterable-style datasets with single- or multi-process loading, customizing
loading order and optional automatic batching (collation) and memory pinning.
See :py:mod:`torch.utils.data` documentation page for more details.
Args:
dataset (Dataset): dataset from which to load the data.
batch_size (int, optional): how many samples per batch to load
(default: ``1``).
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: ``False``).
sampler (Sampler or Iterable, optional): defines the strategy to draw
samples from the dataset. Can be any ``Iterable`` with ``__len__``
implemented. If specified, :attr:`shuffle` must not be specified.
batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, but
returns a batch of indices at a time. Mutually exclusive with
:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,
and :attr:`drop_last`.
num_workers (int, optional): how many subprocesses to use for data
loading. ``0`` means that the data will be loaded in the main process.
(default: ``0``)
collate_fn (Callable, optional): merges a list of samples to form a
mini-batch of Tensor(s). Used when using batched loading from a
map-style dataset.
pin_memory (bool, optional): If ``True``, the data loader will copy Tensors
into device/CUDA pinned memory before returning them. If your data elements
are a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,
see the example below.
drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,
if the dataset size is not divisible by the batch size. If ``False`` and
the size of dataset is not divisible by the batch size, then the last batch
will be smaller. (default: ``False``)
timeout (numeric, optional): if positive, the timeout value for collecting a batch
from workers. Should always be non-negative. (default: ``0``)
worker_init_fn (Callable, optional): If not ``None``, this will be called on each
worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as
input, after seeding and before data loading. (default: ``None``)
generator (torch.Generator, optional): If not ``None``, this RNG will be used
by RandomSampler to generate random indexes and multiprocessing to generate
`base_seed` for workers. (default: ``None``)
prefetch_factor (int, optional, keyword-only arg): Number of batches loaded
in advance by each worker. ``2`` means there will be a total of
2 * num_workers batches prefetched across all workers. (default value depends
on the set value for num_workers. If value of num_workers=0 default is ``None``.
Otherwise if value of num_workers>0 default is ``2``).
persistent_workers (bool, optional): If ``True``, the data loader will not shutdown
the worker processes after a dataset has been consumed once. This allows to
maintain the workers `Dataset` instances alive. (default: ``False``)
pin_memory_device (str, optional): the data loader will copy Tensors
into device pinned memory before returning them if pin_memory is set to true.
在上述中共有15个参数,我们常用的有如下5个参数
dataset (Dataset)– 表示要读取的数据集
batch_size (python:int, optional)– 表示每次从数据集中取多少个数据
shuffle (bool, optional)–表示是否为乱序取出
num_workers (python:int, optional)– 表示是否多进程读取数据(默认为0);
drop_last (bool, optional)– 表示当样本数不能被batchsize整除时(即总数据集/batch_size 不能除尽,有余数时),最后一批数据(余数)是否舍弃(default:
False)
pin_memory(bool, optional)- 如果为True会将数据放置到GPU上去(默认为false)
2.引入库
from torch.utils.data import DataLoader
3.创建数据(使用CIFAR10为例)
创建CIFAR10的测试集
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
4.创建DataLoader实例
# 创建DataLoader实例
test_loader = DataLoader(
dataset=test_set, # 引入数据集
batch_size=4, # 每次取4个数据
shuffle=True, # 打乱顺序
num_workers=0, # 非多进程
drop_last=False # 最后数据(余数)不舍弃
)
几点解释
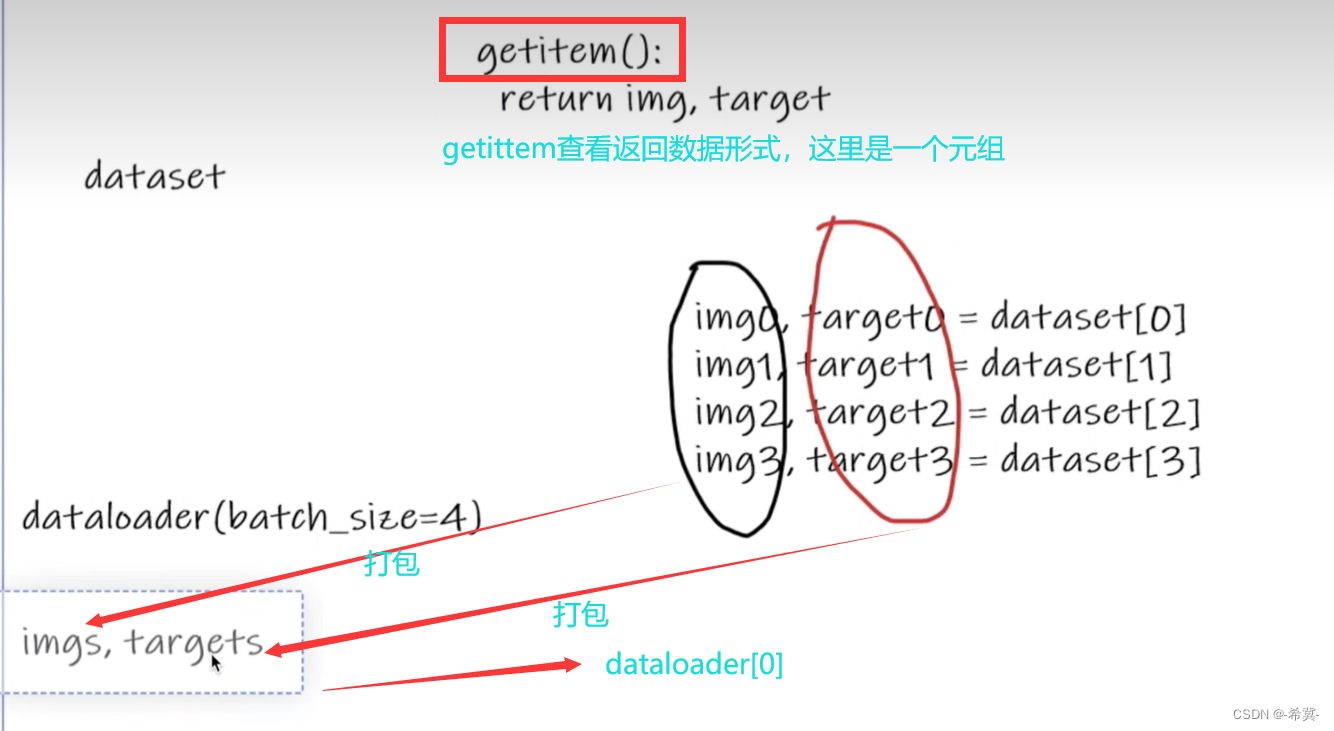
以此次一批数据为4为例
一个批次dataloader[0]就是
img0,target0 = dateset[0] . . . img3,target3 = dateset[3]
总共4个数据
故,
dataloader会将上面的img0……img3进行打包成imgs
target0……target3进行打包成target
如下小土堆的图所示
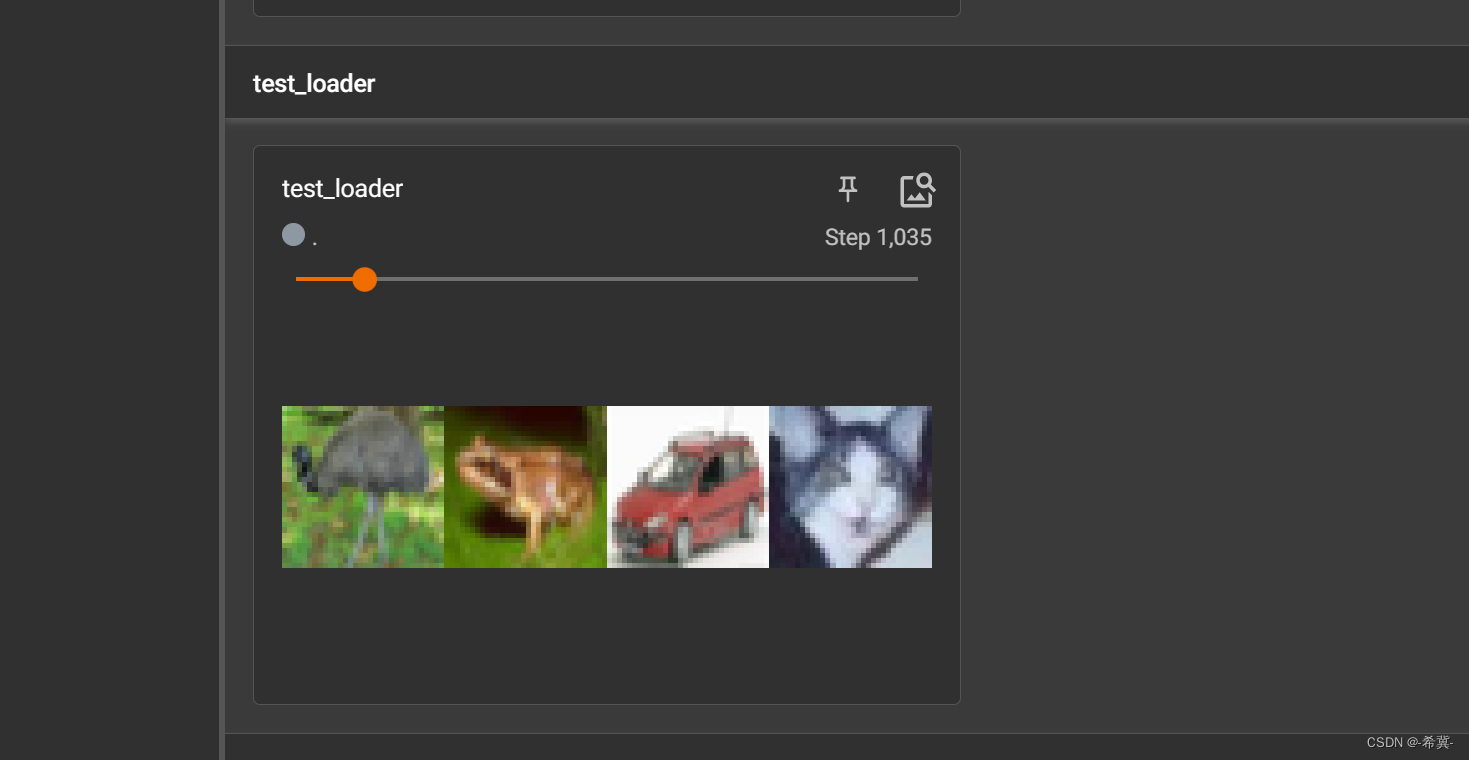
5.在Tensorboard中显示即完整代码如下
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试集
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 创建test_loader实例
test_loader = DataLoader(
dataset=test_set, # 引入数据集
batch_size=4, # 每次取4个数据
shuffle=True, # 打乱顺序
num_workers=0, # 非多进程
drop_last=False # 最后数据(余数)不舍弃
)
img,index = test_set[0]
print(img.shape) # 查看图片大小 torch.Size([3, 32, 32]) C h w,即三通道 32*32
print(index) # 查看图片标签
# 遍历test_loader
for data in test_loader:
img,target = data
print(img.shape) # 查看图片信息torch.Size([4, 3, 32, 32])表示一次4张图片,图片为3通道RGB,大小为32*32
print(target) # tensor([4, 9, 8, 8])表示4张图片的target
# 在tensorboard 中显示
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
img, target = data
writer.add_images("test_loader",img,step)
step = step+1
writer.close()