AutoPrompt (EMNLP2020)
Shin T, Razeghi Y, Logan IV R L, et al. Autoprompt: Eliciting knowledge from language models with automatically generated prompts[J]. arXiv preprint arXiv:2010.15980, 2020.
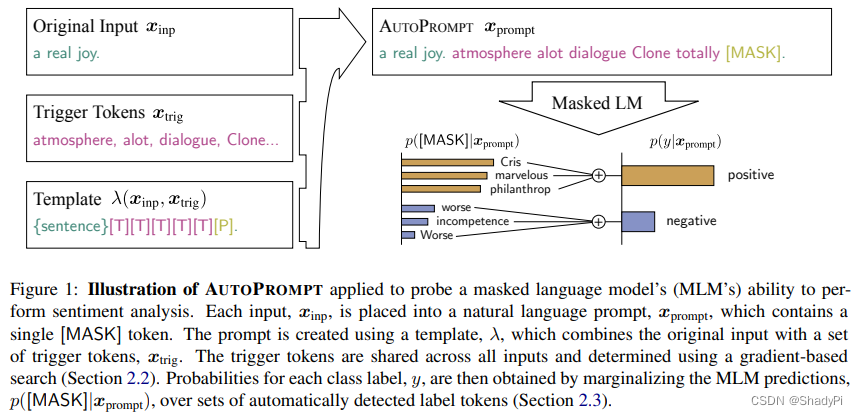
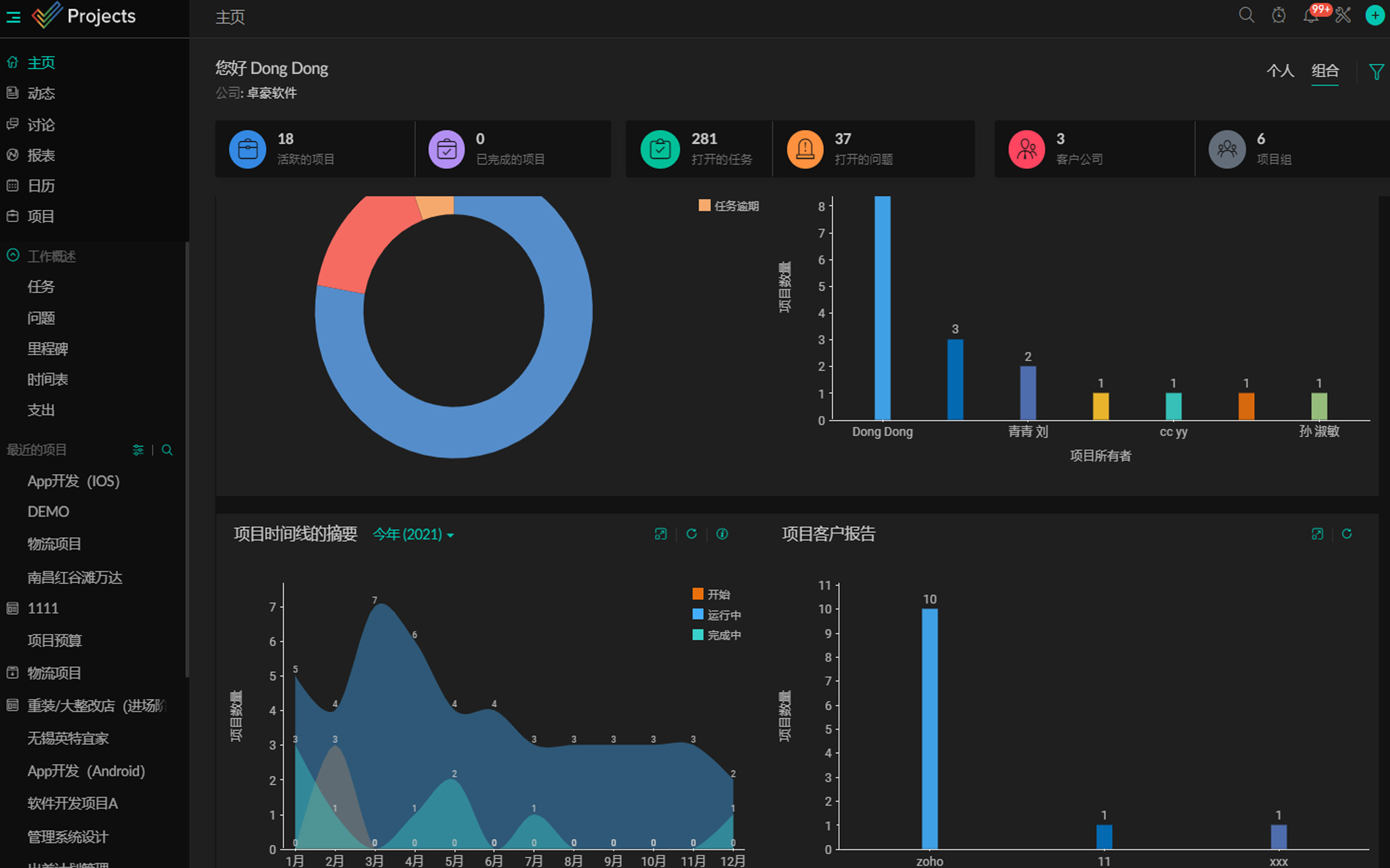
基本架构,original input + trigger tokens, 放入到预先设计好的模板里,作为完整的prompt给到大模型,要求是让大模型补全[MASK]中的内容。
主要的prompt search工作就是在trigger tokens的选择上,在同一个任务中,添加的trigger tokens都是一致的。
LM的输出好坏由
p
(
y
∣
x
p
r
o
m
p
t
)
p(y|x_{prompt})
p(y∣xprompt)打分,分越高表明prompt越好。在选择trigger tokens的过程中,首先将所有trigger tokens都设置为[MASK],然后迭代优化尝试提高
p
p
p。具体的做法是计算将某个trigger token替换为新token
w
w
w之后
p
p
p会提高多少,作者给出的估计方式是
w
i
n
T
∇
log
p
(
y
∣
x
p
r
o
m
p
t
)
w_{in}^T\nabla\log p(y|x_{prompt})
winT∇logp(y∣xprompt)
应该是基于类似泰勒展开的计算,
f
(
x
)
=
f
(
x
0
)
+
(
x
−
x
0
)
f
′
(
x
0
)
f(x)=f(x_0)+(x-x_0)f'(x_0)
f(x)=f(x0)+(x−x0)f′(x0),展开后与
x
x
x有关的项就是
x
f
′
(
x
0
)
xf'(x_0)
xf′(x0),与这里所用的近似估计形式相似,但不清楚为什么要log。
总而言之,有了这个估计以后可以通过这个估计选出Top k个使该估计变大的候选token,选出来以后直接换进去算出新的 p p p,取最高的放进去。
除了优化prompt的这个问题之外,AutoPrompt还提出了一些算法来评估MLM在分类问题上的性能。例如二元情感分类 (positive/negative),但模型在预测[MASK]的时候给出的概率分布会包含(marvelous/worse)这样本质差不多但表达不同的结果。作者提出的解决方法思想是用Transformer的encoder计算出原文本中[MASK] token的contextualized embedding(带上下文信息的embedding),之后在词库中找到跟该contextualized embedding相似度最高的k个词作为正确答案的近似替代,如果LM预测的[MASK]是这里面的词汇,也算作正确答案。作者训练了一个逻辑分类器来做相似度评判工作。
对于非分类问题,例如Fact Retrieval和Relation Extraction,作者并没有做类似的“宽容性”调整。
可能的问题:同一个任务下的prompt都是一样的,应该可以根据input做出调整;这里使用的MLM输出的是对[MASK]预测的概率分布,而且还需要这个模型的梯度,然而在调用API的时候实际上是不能获得的。
BBT & BBTv2 (EMNLP2022)
Sun T, He Z, Qian H, et al. BBTv2: towards a gradient-free future with large language models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3916-3930.
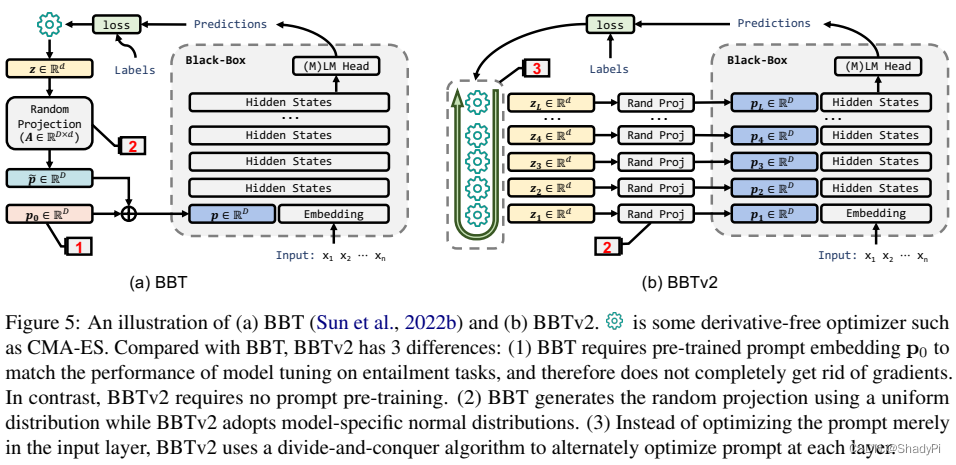
比较有意思的点在于使用了不基于梯度的优化器CMA-ES,因为LLM的反向传播基本不可用或者会耗费大量资源;同时在直接优化输入的continuous prompt很难的情况下,把prompt的embedding拆成
p
=
A
z
,
p
∈
R
D
,
A
∈
R
D
∗
d
,
z
∈
R
d
p=Az,p\in R^D,A\in R^{D*d}, z\in R^d
p=Az,p∈RD,A∈RD∗d,z∈Rd,其中
A
A
A为随机生成(BBTv2又有所改进)并且固定不变的,训练过程中只优化
z
z
z,这样就降低了训练难度。
问题:作为continuous prompt,直接将“乱码”作为prompt,解释性低,人类无法理解,对于不同的模型prompt不一样;BBTv2要求能参与LLM向前传播的过程,在实际调用API时无法实现。
GrIPS(EACL2023)
Prasad A, Hase P, Zhou X, et al. Grips: Gradient-free, edit-based instruction search for prompting large language models[J]. arXiv preprint arXiv:2203.07281, 2022.
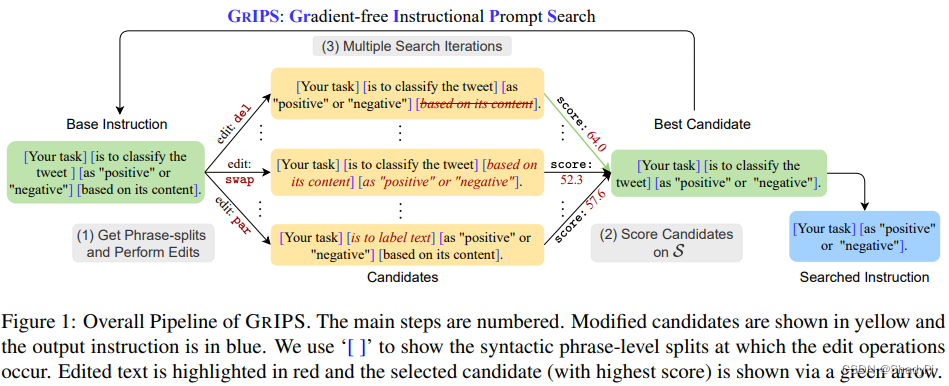
这个prompt搜索算法比较朴素,有四种操作(图中没给出添加操作),删去、调换、重述和添加,且添加只能添加之前被删掉的。采用贪心策略,每次做完这四种操作以后在一个小的验证集
S
S
S中比较出最好的改动,保留该改动然后进行下一次迭代。
实验部分没有跟其他工作比较,只跟人工方法以及带样例的prompt比较了一下,且本工作主打的是Instruction Prompt,因而模型还采用了Instruction特化的LLM,着眼于Instruction对performance的影响。
可能的问题:算法偏简单,同时没有跟其他工作比,在解释性方面倒是讲了很多故事。
HyperPrompt (ICML2022)
He Y, Zheng S, Tay Y, et al. Hyperprompt: Prompt-based task-conditioning of transformers[C]//International Conference on Machine Learning. PMLR, 2022: 8678-8690.
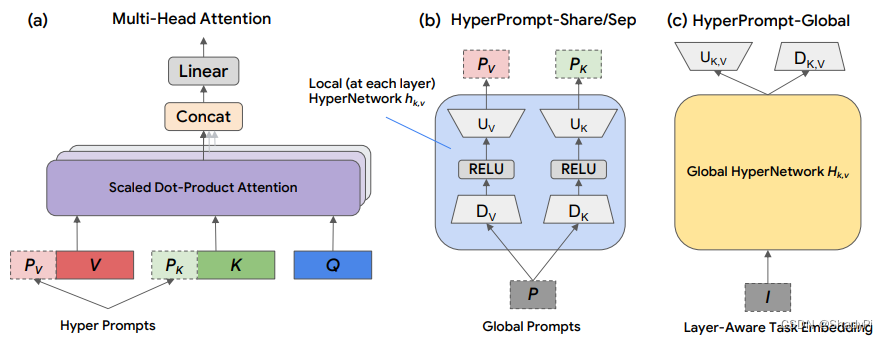
基于当时最强的Transformer T5做的prompt,推理时在QKV中的V和K上加上自己的prompt
P
V
,
P
K
P_V,P_K
PV,PK,因为这个参数量很多,所以在此基础之上建立了一个上层网络,如(b),这个网络可以生成
P
V
,
P
K
P_V,P_K
PV,PK。global prompt
P
P
P,通过(b)中所示的HyperNetwork生成Transformer要用的
P
V
,
P
K
P_V,P_K
PV,PK,其中
P
P
P是根据任务不同而不同的,且是可训练的。
而HyperNetwork又分为两种——Share和Sep,Share是所有任务共用一套参数 U V , U K , D V , D K U_V,U_K,D_V,D_K UV,UK,DV,DK,而Sep则是每种任务单独训练一个。
Google还觉得不够,于是又在上层建立了一个网络,Global Network,用来生成HyperNetwork中的参数。该网络的输入是 I I I,叫做Layer-Aware Task Embedding,是task embedding和layer embedding一起通过一个两层MLP生成的。
也就是说完整的工作流程如下:
(1)task embedding和layer embedding一起通过一个两层MLP生成Layer-Aware Task Embedding
I
I
I;
(2)
I
I
I通过GlobalNetwork生成
U
K
,
V
,
D
K
,
V
U_{K,V},D_{K,V}
UK,V,DK,V
(3)在HyperNetwork中,由Global Prompt
P
P
P生成Value和Key的Prompt
P
V
,
K
P_{V,K}
PV,K
(4)最后
P
V
,
K
P_{V,K}
PV,K参与Transformer的向前传播,提高模型的performance
作者自己说这样的好处在于在不同的子任务上共享知识,同时减少参数量。
看实验的效果是挺好的,而且可以处理多任务。但同样需要介入模型向前传播的过程,而且感觉训练会是一个难题。。。
Efficient Prompt Retrieval(NAACL2022)
Rubin O, Herzig J, Berant J. Learning to retrieve prompts for in-context learning[J]. arXiv preprint arXiv:2112.08633, 2021.
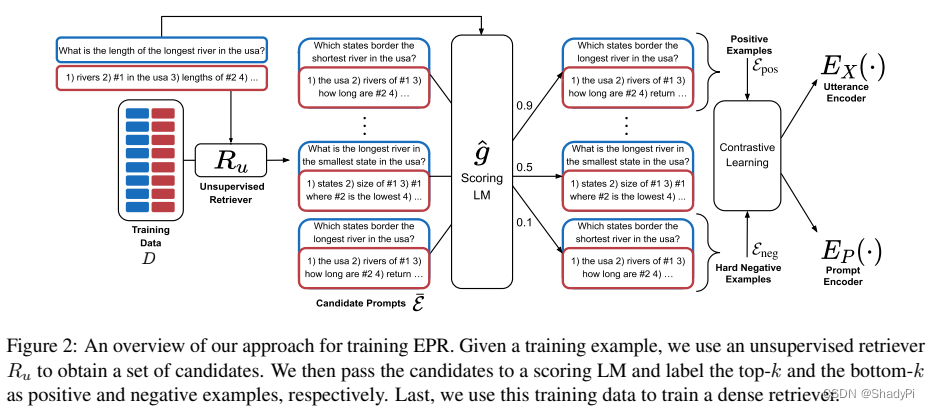
这篇工作主要做的是一个prompt retriever,主要关注的问题是选取合适的样例来作为prompt提供给LLM,也就是样例选取。
该工作首先需要一个 unsupervised prompt retriever ,即上图中的 R u R_u Ru,用来对所有样例进行一次初筛,得到candidate prompts ε ‾ \overline{\varepsilon} ε。再将这个候选集拿给打分用语言模型 g ^ \hat{g} g^进行打分,打分依据是对于数据对 ( x , y ) (x,y) (x,y)输入一个样例 e l ∈ ε ‾ , x e_l\in \overline\varepsilon, x el∈ε,x,LM输出 y y y的概率,即 s ( e l ‾ ) = Prob g ^ ( e l ‾ , x ) s(\overline{e_l})=\text{Prob}_{\hat{g}}(\overline{e_l},x) s(el)=Probg^(el,x)。将所有candidate按分数从高到低排序,top-k为正样本,bottom-k为负样本,依据这里得到的样本通过对比学习学习两个encoder, E X , E P E_ X,E_P EX,EP, E X E_X EX用于编码原始输入 x x x,而 E P E_P EP用于编码样例,一个输入输出对 e l ‾ \overline{e_l} el。对比学习的目的就是让编码后能区分出正负样本且正负样本之间的差距尽可能大。
试验结果表明,无论 g ^ , g \hat{g},g g^,g是不是同一个模型,EPR相较之前提出的一些 prompt retriever 都有性能上的提升。在之前unsupervised工作的基础上加上supervised引导,达到了更好的效果。
RLPrompt(EMNLP2022)
Deng M, Wang J, Hsieh C P, et al. Rlprompt: Optimizing discrete text prompts with reinforcement learning[J]. arXiv preprint arXiv:2205.12548, 2022.
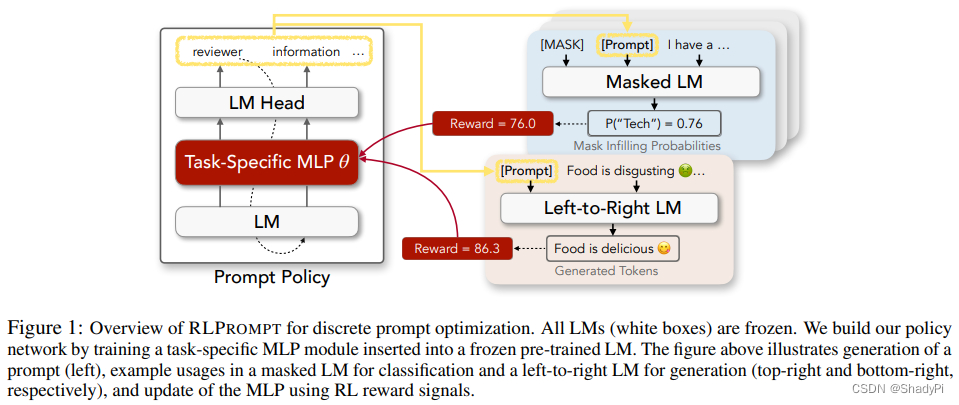
一篇把提出prompt转化为强化学习的工作,算是比较新颖的视角。
本工作使用Soft Q Learning(SQL)作为强化学习算法,Policy network由一个加入了MLP的LM实现,其中LM的部分是frozen的,仅MLP的参数可训练。算法流程是在模板[Input][Prompt][MASK]形式下,向[Prompt]中逐个加入单词,加入后进行测试,获得reward,以此迭代。在本篇工作中,Prompt的长度一般是2个或者5个单词。
在强化学习中,reward的设置是至关重要的,作者设计了两个技术来优化reward,分别是Input-Specific z-Score Reward和Piecewise Reward。其中,Input-Specific z-Score Reward指对于某个Input
x
x
x,其prompt
z
z
z的最终Reward还需要进行一个类似归一化的处理,即
z
−
s
c
o
r
e
(
z
,
x
)
=
R
x
(
z
)
−
mean
z
′
∈
Z
(
x
)
R
x
(
z
′
)
std
z
′
∈
Z
(
x
)
R
x
(
z
′
)
z-score(z,x)=\frac{R_x(z)-\text{mean}_{z'\in Z(x)}R_x(z')}{\text{std}_{z'\in Z(x)}R_x(z')}
z−score(z,x)=stdz′∈Z(x)Rx(z′)Rx(z)−meanz′∈Z(x)Rx(z′)
其中,
Z
(
x
)
Z(x)
Z(x)是为
i
n
p
u
t
input
input生成的一系列prompt
z
z
z的集合,这个归一化即是综合考虑该输入难度做出的归一化,有些输入很简单就能达到高性能,有些则较难,该归一化的作用是平衡不同输入的reward。(但看最后的示例,应该是每个数据集训练出不同的prompt,而没有做到每个输入都有不同的prompt。可能是在policy network中采了不同的样吧,由于没有看代码,这个部分我比较存疑)。
另外一个技术Piecewise Reward主要用于让模型不要极端的只增大一个类的可能性(如果直接按照预测到正确类的概率的话会导致这种情况),作者使用了hinge loss技术。即将重点放在正确类与其他错误类的区别,Gap,上,Gap的定义为
G
a
p
z
(
c
)
=
P
z
(
c
)
−
max
c
′
≠
c
P
z
(
c
′
)
Gap_z(c)=P_z(c)-\max_{c'\neq c}P_z(c')
Gapz(c)=Pz(c)−c′=cmaxPz(c′)
即正确类的概率-非正确类概率中最大的预测概率。
实验得到的效果自然是不错的,不过RLPrompt中也提到了其他工作,比如上文中的AutoPrompt、BBT、GrIPS,不过主要是在few-shot的setting下比较的,所以这些其他工作的表现跟原生论文里有所不同。以及虽然在开头部分标榜自己具有zero-shot能力,但好像并没有给出实验?