文件内容
导包配置
import json
from pyspark import SparkContext, SparkConf
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
os.environ["HADOOP_HOME"] = "D:/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set("spark.default.parallelism", "1") # 写入一个分区
sc = SparkContext(conf=conf)
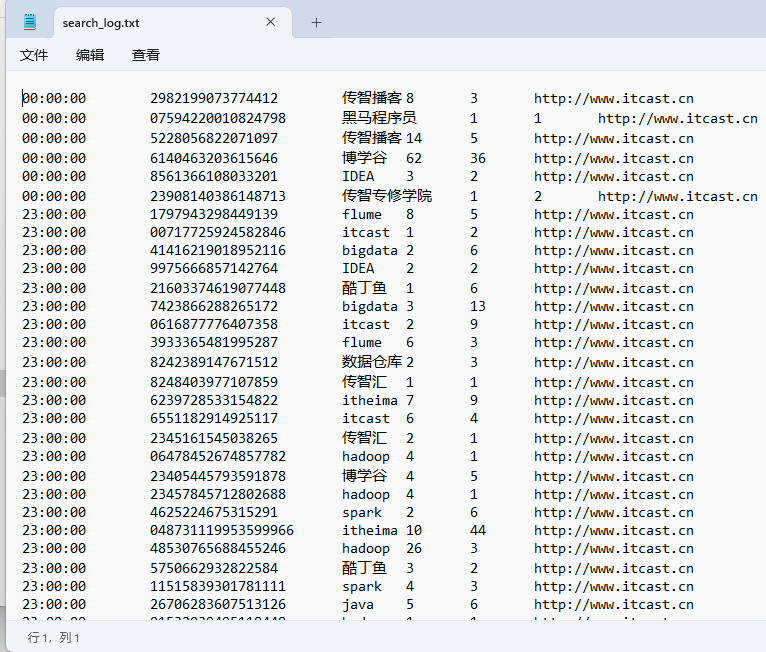
文件准备
rdd = sc.textFile("D:/search_log.txt")
print(rdd.collect())
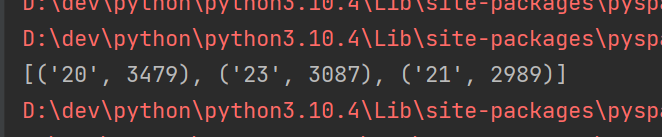
TODO 热门搜索时间段TOP3
"""
取出时间转换为小时
转为(小时,1)二元元组
reduceByKey算子聚合
sorted排序
take前三(返回list,无需collect)
"""
rdd_1 = rdd.map(lambda x: x.split("\t")). \
map(lambda x: x[0][:2]). \
map(lambda x: (x, 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
print(rdd_1)
TODO 热门搜索TOP3
"""
取出搜索词
(word,1)二元元组
聚合
TOP3
"""
rdd_2 = rdd.map(lambda x: (x.split("\t")[2], 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(3)
print(rdd_2)

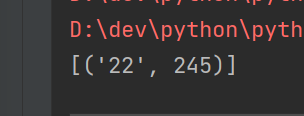
TODO 统计关键字什么时段搜索最多
"""
filter过滤,保留关键字
(时段,1)二元元组
聚合
排序
取TOP1
"""
rdd_3 = rdd.map(lambda x: x.split('\t')). \
filter(lambda x: x[2] == "黑马程序员"). \
map(lambda x: (x[0][:2], 1)). \
reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(1)
print(rdd_3)
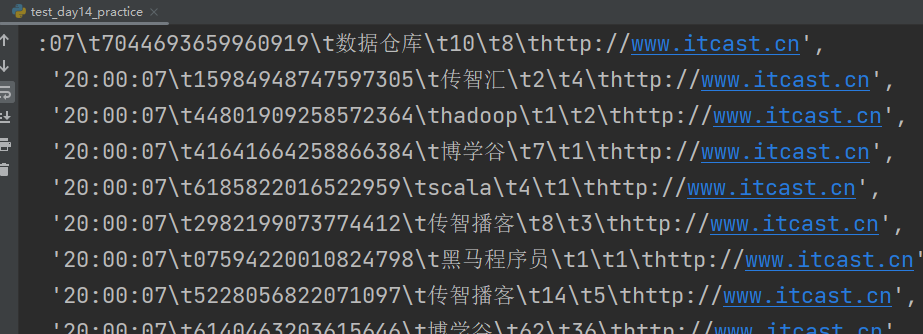
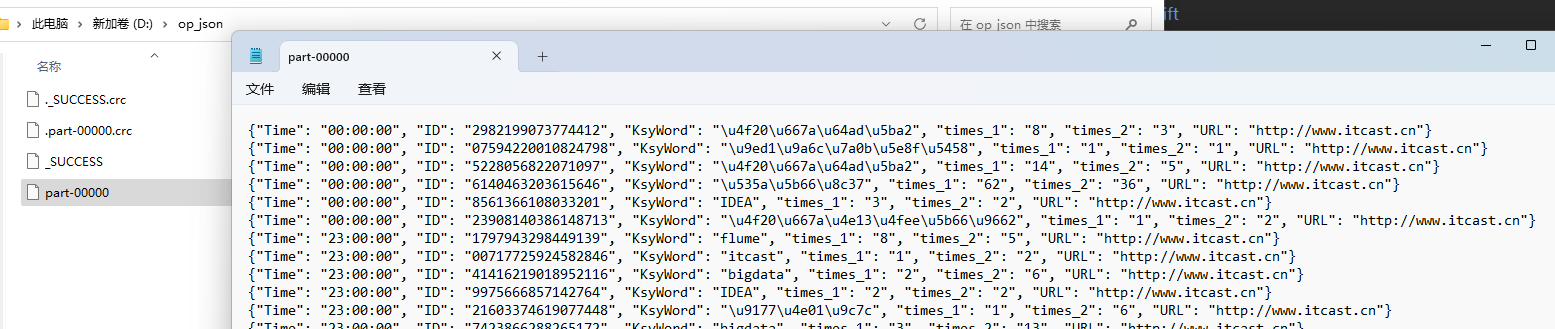
TODO 将数据转为JSON,写会文件
"""
存入字典
转为JSON
saveAsTextFile写入文件,写入一个分区:conf.set("spark.default.parallelism", "1")
"""
rdd.map(lambda x: x.split("\t")). \
map(lambda x: {"Time": x[0], "ID": x[1], "KsyWord": x[2], "times_1": x[3], "times_2": x[4], "URL": x[5]}). \
map(lambda x: json.dumps(x)). \
saveAsTextFile("D:/op_json")
断开链接
sc.stop()