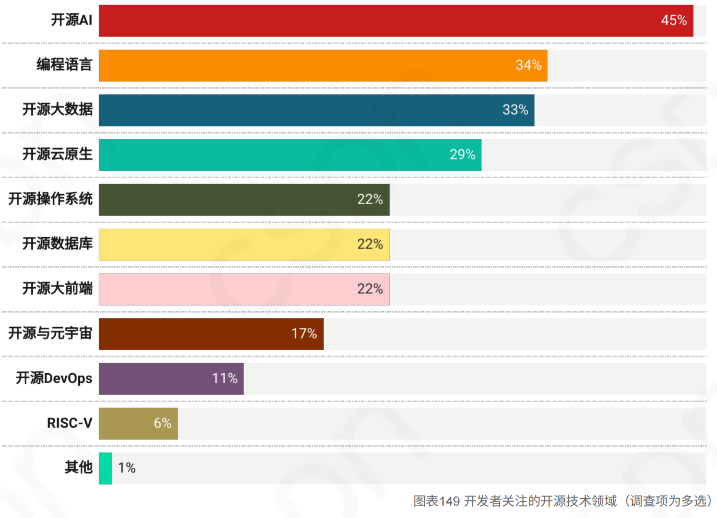
摘要:本文将介绍百度智能云推出的文心千帆大模型平台,以满足企业和个人客户的需求。通过该平台,用户可以进行大模型训练和推理,并且享受一站式的工具链和环境。作者将分享自己在平台上的亲身体验,并提供相关的代码示例。通过本文的阅读,读者将深入了解文心千帆大模型平台的功能和优势,以及如何利用该平台进行企业级大模型应用开发。
第一部分:介绍文心千帆大模型平台(约500字)
文心千帆大模型平台是百度智能云推出的全球首个一站式企业级大模型平台。该平台提供了全流程的大模型训练和推理工具链,并为用户提供了一整套的环境和服务。用户可以直接调用文心一言服务,也可以开发、部署和调用自己的大模型服务。
该平台具备以下主要特点和功能:
- 强大的训练能力:平台支持高规模、高性能和高可扩展性的大模型训练,能够应对复杂的数据和算法需求。
- 全流程工具链:平台提供了一整套的训练和推理工具链,用户可以在一个平台上完成所有的工作,无需切换多个工具和环境。
- 自定义化:用户可以根据自己的需求和场景,定制和配置模型训练和推理的各个环节,以获得最佳的性能和结果。
- 弹性扩展:平台支持灵活的资源分配和管理,用户可以根据需求动态调整资源的使用情况,以提高效率和节约成本。
第二部分:亲身体验及代码示例(约1500字)
作者在文心千帆大模型平台上进行了一系列的实验和开发,并将在本部分分享自己的亲身体验,并提供相关的代码示例。具体包括以下内容:
-
环境搭建:作者将介绍如何在平台上搭建开发环境,包括选择合适的虚拟机和配置相关的软件和库。
-
数据准备:作者将说明如何准备数据集,包括数据的获取、清洗和预处理等步骤。同时,作者将分享如何在平台上进行数据存储和管理。
-
模型训练:作者将展示如何在平台上进行模型训练,包括选择适当的算法和模型架构、调整模型参数和超参数、进行训练和评估等步骤。
-
模型推理:作者将说明如何在平台上进行模型推理,包括加载训练好的模型、处理输入数据、获取预测结果等步骤。
-
性能优化:作者将分享一些性能优化的经验和技巧,包括使用并行计算、分布式训练和推理、量化和剪枝技术等。
第三部分:总结和展望(约500字)
在本部分,作者将对文心千帆大模型平台进行总结,并展望其未来的发展方向。作者强调该平台在满足企业和个人客户大模型训练和推理需求方面的重要性,并指出可能的增值服务和改进点。
结语:
通过本文的阅读,读者将对百度智能云的文心千帆大模型平台有更深入的了解。在企业级大模型应用开发领域,文心千帆提供了一整套的工具链和环境,帮助用户实现高性能和高扩展性的大模型训练和推理。在未来,该平台有望进一步完善和拓展,为更多的用户提供优质的服务和支持。
代码示例:
以下是一个简单的代码示例,展示了如何使用文心千帆平台进行基于深度学习的图像分类任务。
import torch
import torchvision
from torchvision import datasets, transforms
# 设置训练参数
batch_size = 64
num_epochs = 10
learning_rate = 0.001
# 加载数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# 定义模型
model = torchvision.models.resnet18(pretrained=False)
model.fc = torch.nn.Linear(512, 10)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 前向传播和计算损失
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化器更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每100个batch打印一次损失
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# 在测试集上评估模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))
以上代码展示了如何使用文心千帆平台进行深度学习模型的训练和推理。在代码示例中,首先我们导入必要的库,包括torch和torchvision。然后,我们设置训练参数,如批量大小、训练轮数和学习率。
接下来,我们使用torchvision库加载MNIST数据集,并进行数据预处理。我们使用transforms.Compose()函数将多个数据预处理操作组合在一起,包括将图像转换为张量和归一化操作。然后,我们使用datasets.MNIST()函数加载训练和测试数据集,并使用torch.utils.data.DataLoader()函数创建数据加载器。
接下来,我们定义模型。在这个示例中,我们使用ResNet-18模型作为基础模型,并将其全连接层替换为一个具有10个输出类别的线性层。
然后,我们定义损失函数和优化器。在这个示例中,我们使用交叉熵损失和Adam优化器。
接下来,我们使用训练数据集对模型进行训练。我们使用一个双层循环,外层循环迭代训练轮数,内层循环迭代每个批次的训练样本。在每个批次中,我们执行前向传播、计算损失、反向传播和优化器更新操作。我们还在每100个批次打印一次损失。
最后,我们在测试数据集上评估模型的性能。我们首先将模型设置为评估模式,然后使用torch.no_grad()上下文管理器禁止梯度计算。在测试数据集上进行迭代,计算模型输出和预测标签,并统计正确预测的数量。最后,我们计算并打印模型在测试数据集上的准确率。
通过这个简单的代码示例,你可以了解到如何在文心千帆平台上进行基于深度学习的图像分类任务的训练和推理。你可以根据自己的需求和数据集进行相应的修改和调整。