1.回收站功能
为什么要检查
检查数据存活时间是否到达

单位分钟
web端界面删除不走回收站
mapreduce优化
记住
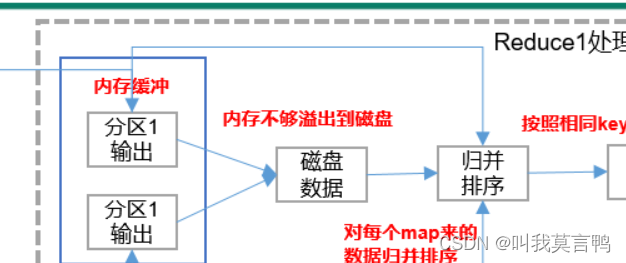
不写磁盘更优化

为什么conbiner可以解决数据倾斜
合并小数据块了
压缩解决不了 数据倾斜
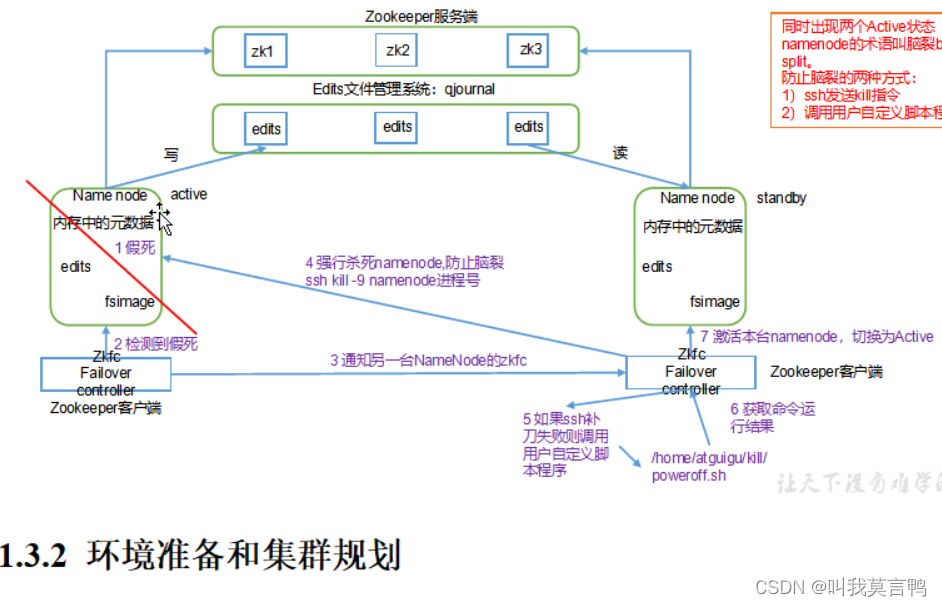
配置多个NN
1.哪个NN出去服务
一个NN Active 其他NN Standby
2.没有了2NN 谁去管理元数据
standby的机器,谁先拿到就谁干。
3.怎么保证实时同步的?
客户端请求后,ACTIVE向其他转发请求,在高可用集群中
监听
JournalNode 存修改日志

指定一个nn active

不能主动切换 隔离机制
杀死也不能指定

访问不通不敢切,防止假死。
上位之前先登录之前的NN kill -9
ZKFC 每台机器都有,用于和ZK交互,同时监控NN的健康状态,
启动时,先启动zk
生成永久节点hadoop/mycluster

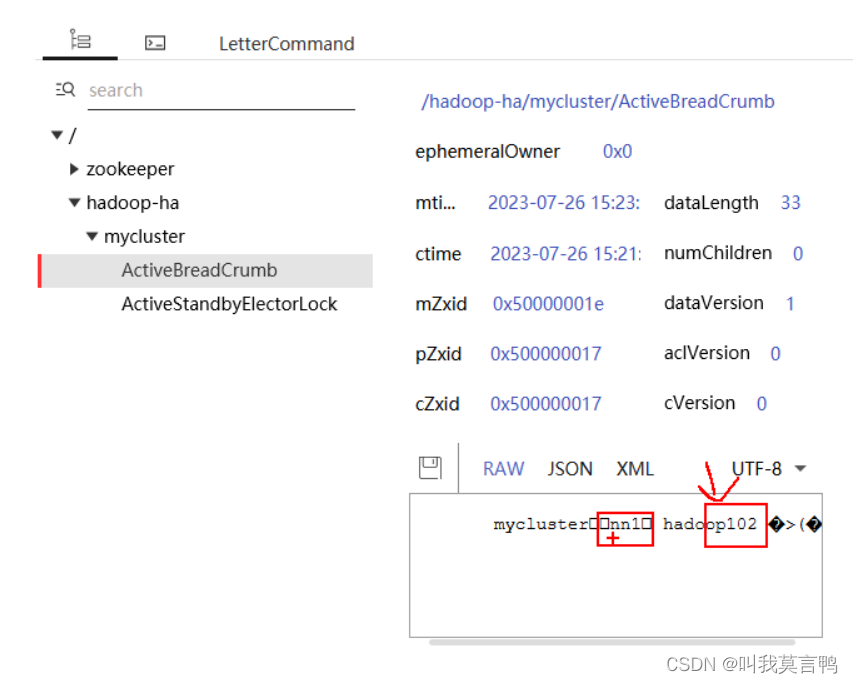
启动
判断是假死就杀死
不是假死就补刀kill
服务器断掉也无法实现高可用,但是他还是会不停的互相切换闲置服务器尝试

第一个是上一次成功的
第二次是当前的,
yarn会自动跳到active上 这个与nn不同
自动故障转移与hdfs相同
配置
1.core-site.xml
<configuration>
<!-- 把多个NameNode的地址组装成一个集群mycluster, -->
<!--可修改-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--可修改-->
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-3.3.4/data</value>
</property>
<!-- 指定zkfc要连接的zkServer地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop201:2181,hadoop202:2181,hadoop203:2181</value>
</property>
<!-- 启用nn故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
2.hdfs-site.xml
<configuration>
<!-- NameNode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode数据存储目录 -->
<!--占用的空间不多,主要是修改日志 edit-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<!-- 这个要和上面core对应>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<!--mycluster可替换成其他的名字-- >
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode的RPC通信地址 --> <!-- 留给后端的通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop104:8020</value>
</property>
<!-- NameNode的http通信地址 --> <!-- 留给web端的通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop104:9870</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 访问代理类:client用于确定哪个NameNode为Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/atguigu/.ssh/id_rsa</value>
</property>
<!-- 启用nn故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 启用resourcemanager ha -->
<!-- 声明两台resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定resourcemanager的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- ========== rm1的配置 ========== -->
<!-- 指定rm1的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<!-- 指定rm1的web端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop102:8088</value>
</property>
<!-- 指定rm1的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop102:8032</value>
</property>
<!-- 指定AM向rm1申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop102:8030</value>
</property>
<!-- 指定供NM连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop102:8031</value>
</property>
<!-- ========== rm2的配置 ========== -->
<!-- 指定rm2的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop103:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop103:8031</value>
</property>
<!-- ========== rm3的配置 ========== -->
<!-- 指定rm1的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>hadoop104</value>
</property>
<!-- 指定rm1的web端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>hadoop104:8088</value>
</property>
<!-- 指定rm1的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>hadoop104:8032</value>
</property>
<!-- 指定AM向rm1申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>hadoop104:8030</value>
</property>
<!-- 指定供NM连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>hadoop104:8031</value>
</property>
<!-- 指定zookeeper集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的状态信息存储在zookeeper集群 -->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>