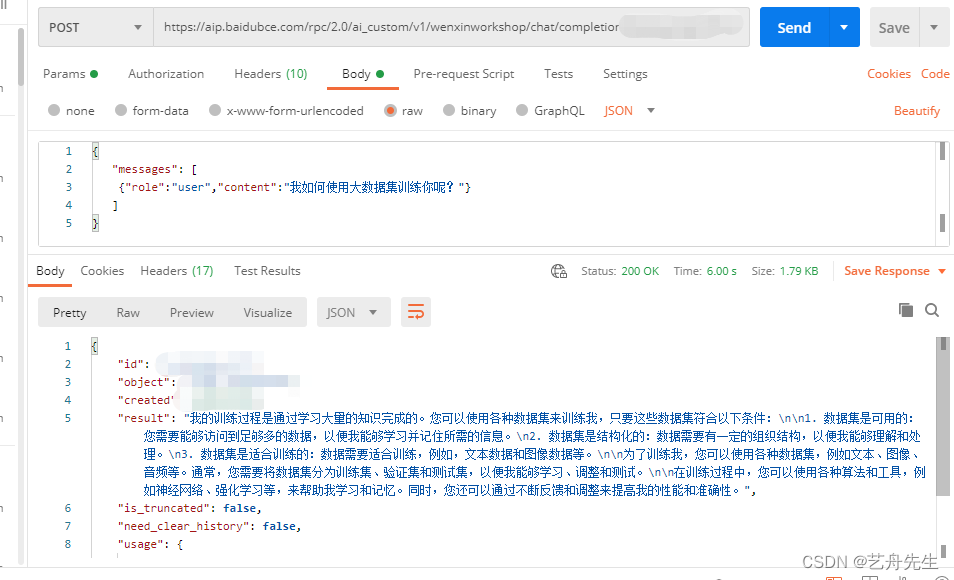
目录
什么是字符乱码
字符乱码是什么原因
怎么解决字符乱码的问题
示例代码
什么是字符乱码
字符乱码是指在文本或字符编码中出现无法正确显示或解析的字符。当使用不同的字符编码格式读取或显示文本时,如果编码格式不匹配或不正确,就会导致字符乱码问题。常见的情况包括显示为一连串乱码字符、显示为方框或问号等无法识别的符号。

字符乱码是什么原因
1. 错误的字符编码:当使用不正确的字符编码格式来解析文本时,会导致乱码。常见的字符编码包括UTF-8、GBK、ISO-8859等。如果文本使用的字符编码与解析时指定的编码不一致,就会导致乱码问题。
2. 编码格式不支持:某些特殊字符或特定语言的字符可能不被某些字符编码格式支持,导致无法正确显示。如果文本包含无法被当前字符编码所表示的字符,就会导致乱码问题。
3. 文件传输问题:在文件传输过程中,如果未正确处理字符编码转换或文件格式转换,可能会导致乱码。例如,当将以一种字符编码格式保存的文件转移到另一种字符编码格式的系统中时,如果没有进行正确的编码转换,就会导致乱码。
4. 文本编辑器设置问题:某些文本编辑器默认使用特定的字符编码格式,如果该设置与文本实际的编码不一致,就会导致乱码。此外,一些编辑器可能在保存文件时自动更改字符编码格式,导致乱码出现。
5. 数据库字符集问题:在数据库中存储的字符数据可能使用不同的字符编码格式,如果在读取或写入数据时没有正确指定字符编码,就会导致乱码。
怎么解决字符乱码的问题
1. 确认字符编码格式:确定文本的正确字符编码格式,如UTF-8、GBK等。如果不确定编码格式,可以尝试不同的编码来查看乱码是否得到解决。
2. 设置字符编码:在读取或解析文本时,确保使用正确的字符编码格式进行处理。这可以通过设置文件编码、数据库字符集或编程语言中的字符编码参数来实现。
3. 文本编辑器设置:在文本编辑器中,确保设置正确的字符编码格式。可以查看编辑器的选项或首选项,寻找与字符编码相关的设置,并将其设置为与文本实际编码一致。
4. 编码转换工具:使用专门的编码转换工具将文本从一种编码格式转换为另一种编码格式。这可以确保文本能够正确地被解析和显示。
5. 检查文件传输:如果乱码问题在文件传输过程中发生,确保在传输过程中正确处理字符编码转换或文件格式转换。可以使用二进制模式传输文件,以确保不会进行任何编码转换。
6. 更新软件:如果字符乱码问题出现在特定软件中,尝试更新软件版本或应用程序补丁,以修复可能存在的字符编码处理问题。
7. 调整字符集配置:对于数据库或服务器设置,确保将字符集配置为与文本实际编码一致的设置。
如果上述方法仍无法解决字符乱码问题,可能需要进一步调查和分析特定情况的原因,并针对性地解决。在处理字符乱码问题时,重要的是明确文本的正确编码和使用正确的编码处理方法。
示例代码
下面是一个使用Python解决字符乱码问题的示例代码:
import codecs
# 读取文本文件并指定字符编码解析
def read_file(file_path, encoding):
with codecs.open(file_path, 'r', encoding=encoding) as f:
content = f.read()
return content
# 写入文本文件并指定字符编码保存
def write_file(file_path, content, encoding):
with codecs.open(file_path, 'w', encoding=encoding) as f:
f.write(content)
# 示例使用:读取文本文件,指定编码为UTF-8,然后将内容保存为GBK编码格式的文件
input_file = 'input.txt'
output_file = 'output.txt'
input_encoding = 'UTF-8'
output_encoding = 'GBK'
# 读取文本文件
content = read_file(input_file, input_encoding)
print('原始内容:', content)
# 写入文本文件
write_file(output_file, content, output_encoding)
print('转换完成!')在上述示例中,使用了`codecs`模块,它提供了对文本文件进行读写时指定字符编码的功能。通过在读取和写入文件时指定了正确的字符编码,可以解决部分字符乱码问题。根据实际需求,可以调整示例代码中的文件路径和字符编码设置来适应具体的乱码问题和解决方案。