kubernetes安装问题记录
- 【1】未配置 host 文件警告
- 1.1 原因
- 1.2 解决方案
- 【2】swap 未禁用警告
- 2.1 产生原因
- 2.2 解决方式
- 【3】containerd 进程禁用了 cri 模块插件
- 3.1 原因
- 3.2 解决方法
- 问题1-3的完整错误日志
- 【4】因错误中断再次 kubeadm init 报错
- 4.1 原因
- 4.2 解决方案
- 【5】iptables 不存在
- 5.1 原因
- 5.2 解决方案
- 【6】kubelet 运行错误
- 6.1.1 原因
- 6.1.2 解决containerd自启的问题
- 6.2.1 原因
- 6.2.2 解决 registry.k8s.io/pause:3.6镜像无法从远端拉取
- 【7】worker 节点 cni 模块未初始化
- 7.1 原因
- 7.2 解决方式
- 【8】kubelet 提示 flannel 为初始化
- 8.1 原因
- 8.2 解决方式
- 【9】flannel pod 状态一直是 CrashLoopBackOff
- 9.1 排查过程
- 9.2 原因
- 9.3 解决方案
【1】未配置 host 文件警告
[WARNING Hostname]: hostname "master" could not be reached
1.1 原因
节点没有在 host 文件中配置IP和主机映射
如下图所示

1.2 解决方案
修改所有节点的 host 文件,增加集群全部节点 host 信息
[root@worker01 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.101.150 master
192.168.101.151 worker01
192.168.101.152 worker02
【2】swap 未禁用警告
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
2.1 产生原因
swap未关闭
2.2 解决方式
关闭swap并且修改fstab文件
# 临时禁用 swap 分区
swapoff -a
# 永久禁用 swap 分区
vi /etc/fstab
# 注释掉下面的设置
# /dev/mapper/centos-swap swap ,将这一行注释掉
# 之后需要重启服务器生效
【3】containerd 进程禁用了 cri 模块插件
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E0726 21:49:09.213675 18427 remote_runtime.go:616] "Status from runtime service failed" err="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory\""
time="2023-07-26T21:49:09+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory\""
, error: exit status 1
3.1 原因
containerd 默认 cri 模块禁用了
3.2 解决方法
先看进程是否启动
ps aux | grep docker | grep -v grep
在查看文件配置
cat /etc/containerd/config.toml
内容如下:
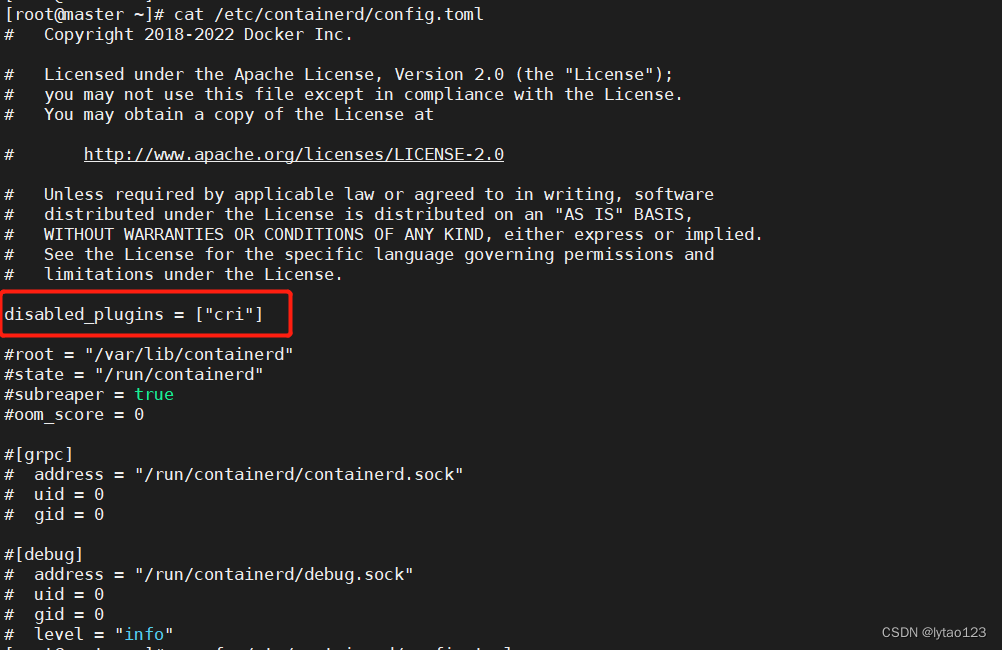
发现 cri 模块禁用了
# 删除该文件
rm -f /etc/containerd/config.toml
# 重启 containerd
systemctl restart containerd
# 查看 containerd 状态
systemctl status containerd.service
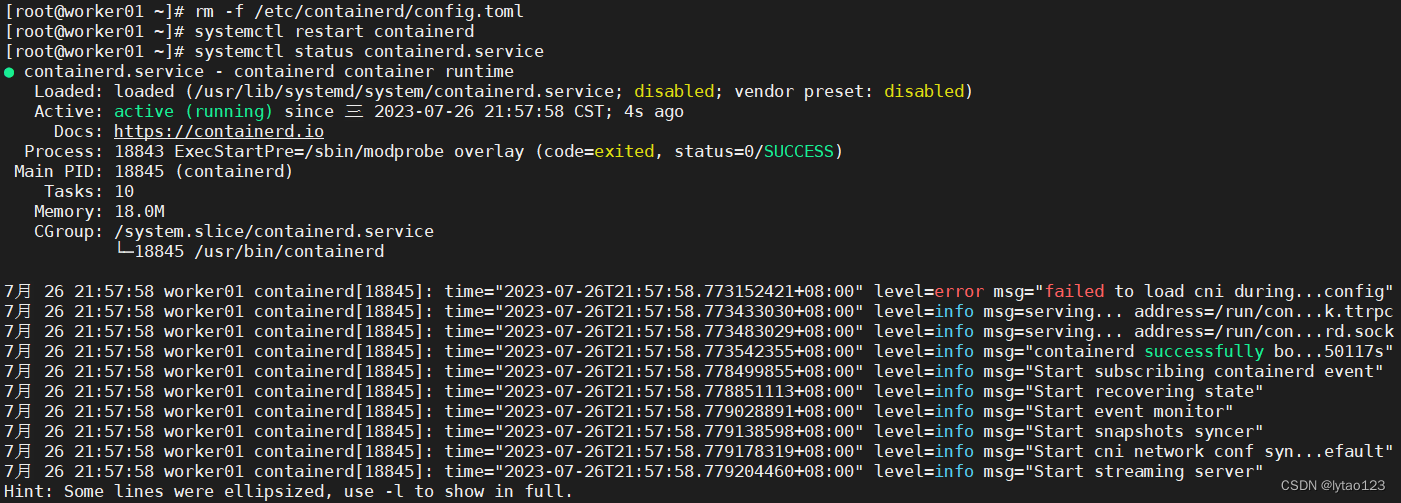
问题1-3的完整错误日志
[root@master ~]# kubeadm init \
> --kubernetes-version 1.24.16 \
> --apiserver-advertise-address=192.168.101.150 \
> --service-cidr=10.96.0.0/16 \
> --pod-network-cidr=10.244.0.0/16 \
> --image-repository registry.aliyuncs.com/google_containers
[init] Using Kubernetes version: v1.24.16
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
[WARNING Hostname]: hostname "master" could not be reached
[WARNING Hostname]: hostname "master": lookup master on 192.168.101.2:53: no such host
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-07-26T21:14:10+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
【4】因错误中断再次 kubeadm init 报错
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist
[ERROR Port-10250]: Port 10250 is in use
4.1 原因
当第一次执行 kubeadm init 后,因为错误而中断,则可能产生上述问题
4.2 解决方案
执行
kubeadm reset
【5】iptables 不存在
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist
5.1 原因
kubeadm reset 命令执行后删除了
5.2 解决方案
modprobe br_netfilter
cat <<EOF> kubernetes.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
【6】kubelet 运行错误
运行 kubeadm init 后报错如下:
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
执行 systemctl status kubelet 查询 kubelet 状态时已运行,查看 kubelet 日志 journalctl -xefu kubelet 有如下报错:
Error: failed to run Kubelet: unable to determine runtime API version: rpc error: code = Unavailable
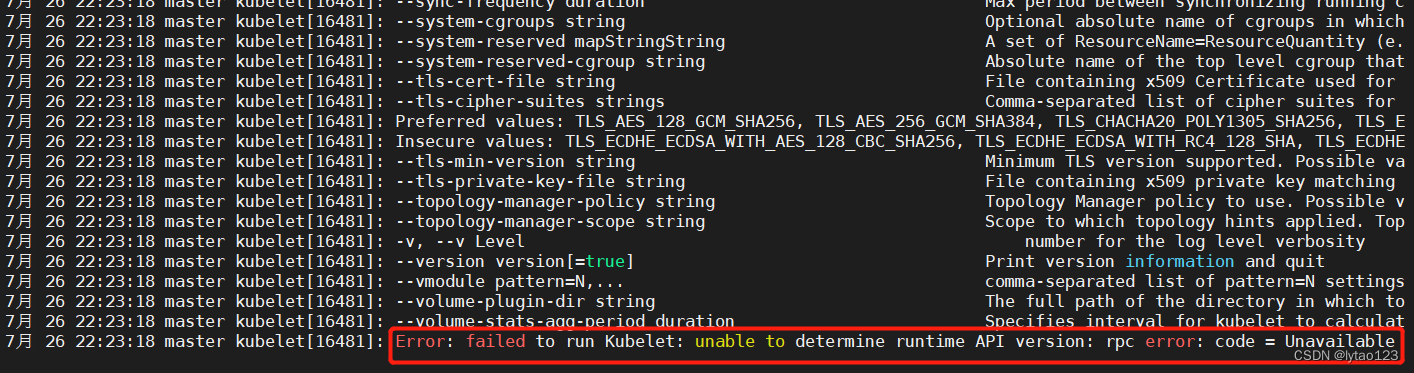
检查 containerd 进程状态 systemctl status containerd
6.1.1 原因
发现 containerd 没有自动启动,因为之前重启了一次,所以导致它没有自启
6.1.2 解决containerd自启的问题
运行 systemctl enable containerd && systemctl start containerd && systemctl status containerd 自启加启动查看状态
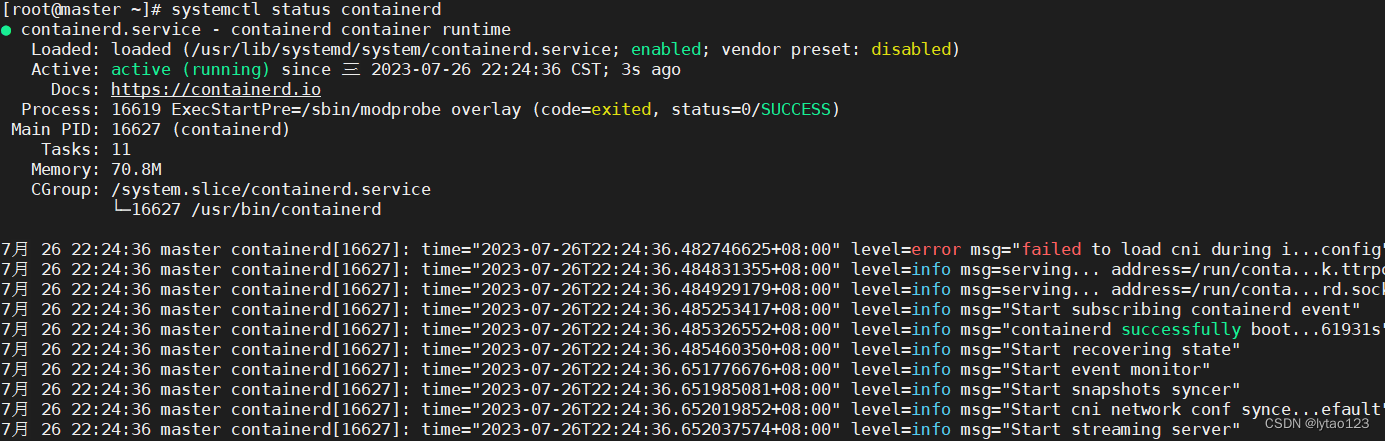
再次查看 kubelet 日志 journalctl -xefu kubelet
Error getting node" err="node \"master\" not found
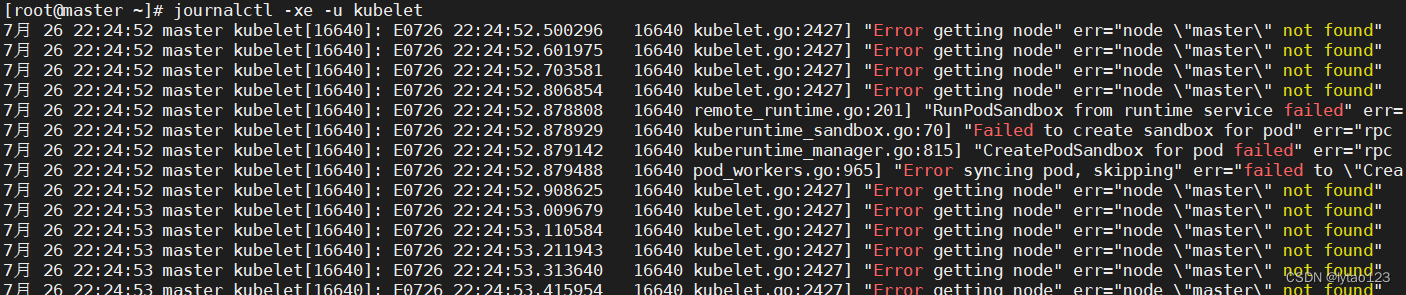
此外还有报错信息如下:
7月 26 23:04:21 master kubelet[16683]: E0726 23:04:21.149924 16683 remote_runtime.go:201] "RunPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to get sandbox image \"registry.k8s.io/pause:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 108.177.97.82:443: connect: connection refused"
7月 26 23:04:21 master kubelet[16683]: E0726 23:04:21.150026 16683 kuberuntime_sandbox.go:70] "Failed to create sandbox for pod" err="rpc error: code = Unknown desc = failed to get sandbox image \"registry.k8s.io/pause:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 108.177.97.82:443: connect: connection refused" pod="kube-system/kube-controller-manager-master"
7月 26 23:04:21 master kubelet[16683]: E0726 23:04:21.150087 16683 kuberuntime_manager.go:815] "CreatePodSandbox for pod failed" err="rpc error: code = Unknown desc = failed to get sandbox image \"registry.k8s.io/pause:3.6\": failed to pull image \"registry.k8s.io/pause:3.6\": failed to pull and unpack image \"registry.k8s.io/pause:3.6\": failed to resolve reference \"registry.k8s.io/pause:3.6\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\": dial tcp 108.177.97.82:443: connect: connection refused" pod="kube-system/kube-controller-manager-master"
7月 26 23:04:21 master kubelet[16683]: E0726 23:04:21.150205 16683 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"CreatePodSandbox\" for \"kube-controller-manager-master_kube-system(2a015198157cc6fdcbb6d8f80c34c6b5)\" with CreatePodSandboxError: \"Failed to create sandbox for pod \\\"kube-controller-manager-master_kube-system(2a015198157cc6fdcbb6d8f80c34c6b5)\\\": rpc error: code = Unknown desc = failed to get sandbox image \\\"registry.k8s.io/pause:3.6\\\": failed to pull image \\\"registry.k8s.io/pause:3.6\\\": failed to pull and unpack image \\\"registry.k8s.io/pause:3.6\\\": failed to resolve reference \\\"registry.k8s.io/pause:3.6\\\": failed to do request: Head \\\"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6\\\": dial tcp 108.177.97.82:443: connect: connection refused\"" pod="kube-system/kube-controller-manager-master" podUID=2a015198157cc6fdcbb6d8f80c34c6b5
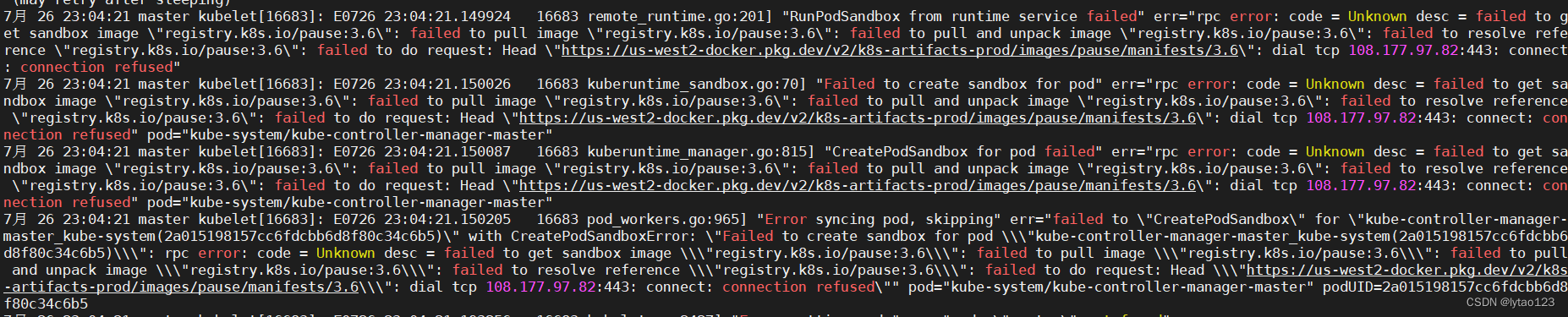
原因是 registry.k8s.io/pause:3.6 镜像无法从远端拉取
6.2.1 原因
网络问题,无法拉取镜像
6.2.2 解决 registry.k8s.io/pause:3.6镜像无法从远端拉取
修改镜像地址为阿里的,注意每个安装有 kubelet 的节点都需要修改
# 生成 config.toml 文件,我在解决第3个问题的时候删除了
containerd config default > /etc/containerd/config.toml
# 按照官网CRI部分修改如下两个配置
vim /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri"]
# sandbox_image = "registry.k8s.io/pause:3.6"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
…
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
# 重启
systemctl restart containerd
# 修改crictl.yaml的CRI
cat <<EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
EOF
最终启动完成
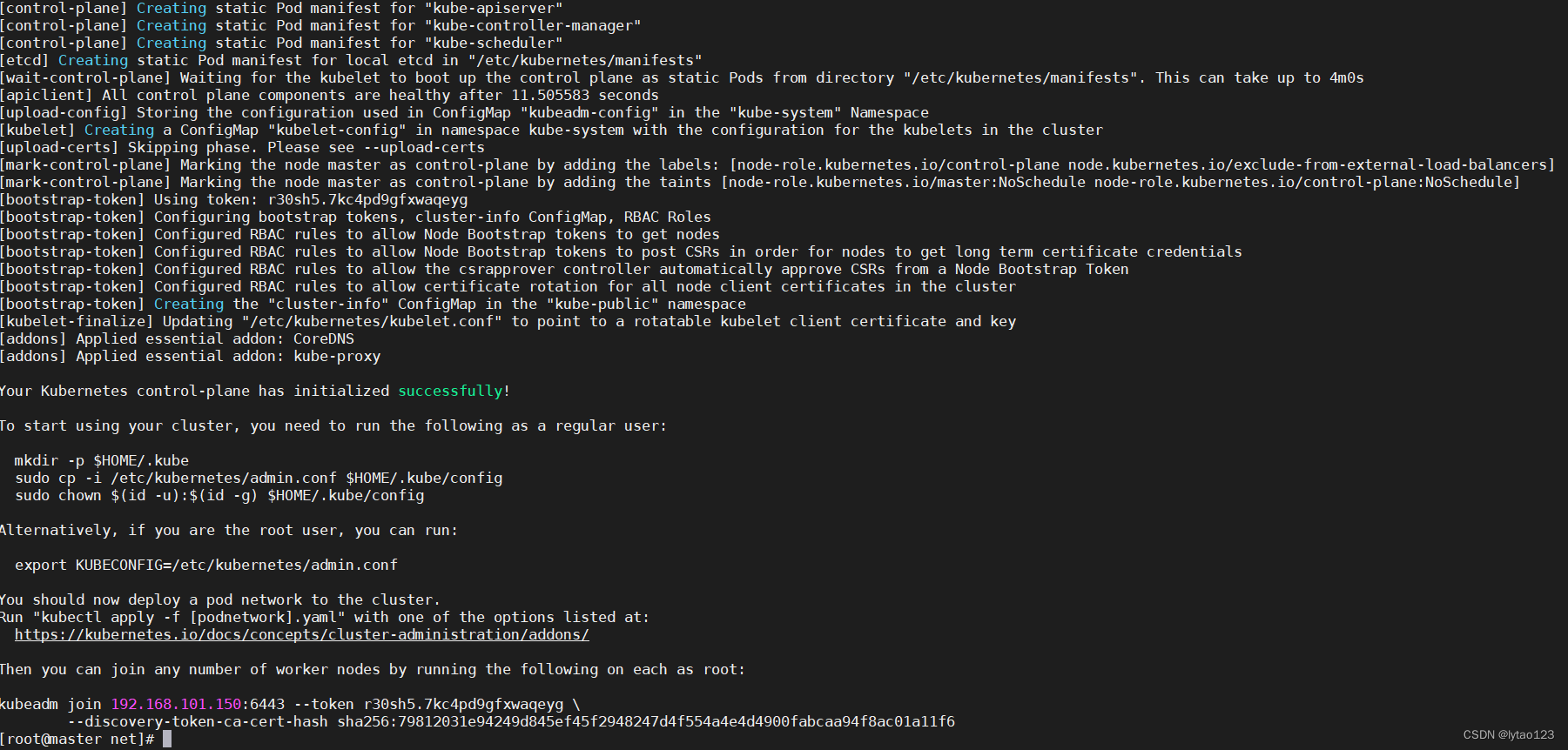
【7】worker 节点 cni 模块未初始化
"Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"
7.1 原因
暂时未知,中间我重启了多次 work节点
7.2 解决方式
重新安装 cni 模块
yum install -y kubernetes-cni
【8】kubelet 提示 flannel 为初始化
Warning FailedCreatePodSandBox 4m37s (x314 over 72m) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "673daa424ec000748c4f28539aeca738ff12923852f18829b06e8748fec00dea": plugin type="flannel" failed (add): open /run/flannel/subnet.env: no such file or directory
8.1 原因
/run/flannel/subnet.env 文件不存在
8.2 解决方式
vim /run/flannel/subnet.env
加入如下内容:
FLANNEL_NETWORK=10.200.0.0/16
FLANNEL_SUBNET=10.200.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
【9】flannel pod 状态一直是 CrashLoopBackOff
9.1 排查过程
查看 pod 日志
kubectl logs -f --tail 200 -n kube-flannel kube-flannel-ds-gj2xt
错误日志为:
Error registering network: failed to acquire lease: subnet "10.244.0.0/16" specified in the flannel net config doesn't contain "10.200.0.0/24" PodCIDR of the "master" node.
大概意思是 flannel.yml 中有默认的ip网段,与用户初始化时定义的网段有出入,导致 flannel 无法识别。需要改一下 flannel 文件的ip定义。
9.2 原因
部署的 flannel 中默认网段与用户初始化时定义的不一致导致
9.3 解决方案
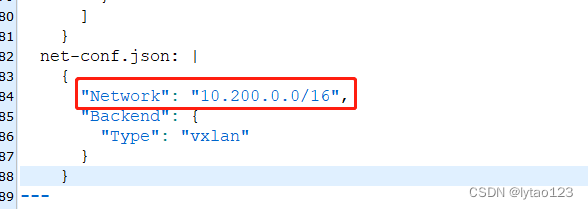
修改 flannel.yml 中默认网关与初始化时定义的网段一致
...
"Network": "10.200.0.0/16",
...