ICASSP (International Conference on Acoustics, Speech and Signal Processing) 即国际声学、语音与信号处理会议,是IEEE主办的全世界最大、最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。
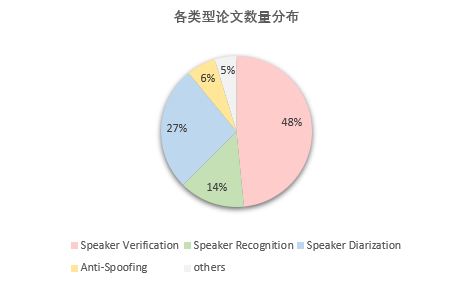
今年入选 ICASSP 2023 的论文中,说话人识别(声纹识别)方向约有64篇,初步划分为Speaker Verification(31篇)、Speaker Recognition(9篇)、Speaker Diarization(17篇)、Anti-Spoofing(4篇)、others(3篇)五种类型。
本文是 ICASSP 2023说话人识别方向论文合集系列第一期,整理了Speaker Verification(前15篇)部分的论文简述,论文来自国内研究团队——清华大学、武汉大学、上海交通大学、香港中文大学、香港理工大学、西北工业大学、天津大学、山东大学、腾讯、美团、OPPO,以及微软等美国、加拿大、法国、日本、韩国、新加坡的国外研究团队。
01 Speaker verification
1.Adaptive Large Margin Fine-Tuning For Robust Speaker Verification
标题:用于鲁棒说话人验证的自适应大幅度微调
作者:Leying Zhang, Zhengyang Chen, Yanmin Qian
单位:MoE Key Lab of Artificial Intelligence, AI Institute
X-LANCE Lab, Department of Computer Science and Engineering
Shanghai Jiao Tong University, Shanghai, China
链接:https://ieeexplore.ieee.org/document/10094744
摘要:大幅度微调(LMFT)是提高说话人验证系统性能的有效策略,广泛应用于说话人验证挑战系统中。由于损失函数中的较大余量可能会使训练任务过于困难,因此人们通常在LMFT中使用较长的训练片段来缓解这一问题。然而,LMFT模型可能与真实场景验证存在持续时间不匹配,其中验证语音可能非常短。在我们的实验中,我们还发现LMFT在短时间和其他验证场景中失败。为了解决这个问题,我们提出了基于持续时间和相似性的自适应大幅度微调(ALMFT)策略。为了验证其有效性,我们构建了基于VoxCeleb1的固定、可变长度和非对称验证试验。实验结果表明,ALMFT算法是非常有效和稳健的,不仅实现了与官方VoxCeleb中的LMFT相当的改进,同时也克服了短时和非对称场景下的性能下降问题。
Large margin fine-tuning (LMFT) is an effective strategy to improve the speaker verification system’s performance and is widely used in speaker verification challenge systems. Because the large margin in the loss function could make the training task too difficult, people usually use longer training segments to alleviate this problem in LMFT. However, the LMFT model could have a duration mismatch with the real scenario verification, where the verification speech may be very short. In our experiments, we also find that LMFT fails in short duration and other verification scenarios. To solve this problem, we propose the duration-based and similarity-based adaptive large margin fine-tuning (ALMFT) strategy. To verify its effectiveness, we constructed fixed, variable length, and asymmetric verification trials based on VoxCeleb1. Experimental results demonstrate that ALMFT algorithms are very effective and robust, which not only achieve comparable improvement with LMFT in official VoxCeleb evaluation trials but also overcome performance degradation problems in short-duration and asymmetric scenarios respectively.
2.Backdoor Attack Against Automatic Speaker Verification Models in Federated Learning
标题:针对联合学习中自动说话人验证模型的后门攻击
作者:Dan Meng1, Xue Wang2,Jun Wang1
单位:1 OPPO Research Institure;2 Wuhan University
链接:https://ieeexplore.ieee.org/document/10094675
摘要:说话人验证已被广泛并成功地应用于许多关键任务领域的用户识别。与其他经典机器学习任务类似,说话人验证的训练性能在很大程度上依赖于数据的数量和多样性。因此,在训练过程中需要包括第三方数据(例如来自公共数据集基准,互联网或其他合作公司的数据)。这就提出了两个主要问题:如何在确保数据安全和隐私的同时使用多方数据?采用委托第三方数据是否会威胁到说话人验证模型的安全性?在本文中,我们首先证明了联合学习(FL)为训练说话人验证模型提供了一种替代方法,而无需从多方一起收集数据。然后,我们验证了在更宽松的威胁假设下执行后门攻击的可能性,即毒害部分说话人而不是所有说话人。具体而言,我们首次研究了FL中说话人验证模型的安全性。在FL的训练过程中,充分利用FL的优势,设计了两阶段训练策略。此外,我们提出了全局谱聚类(GSC)方法,以缓解攻击者只能到达并毒害自己的数据所造成的触发器泛化不足的问题。我们还采用了个性化联合聚合(PFAgg)来避免其他方的建模污染,增强了FL中后门攻击的不可见性。在TIMIT数据集上的实验结果表明,我们提出的框架不仅可以获得令人满意的攻击结果,而且具有可接受的错误率。
Speaker verification has been widely and successfully adopted in many mission-critical fields for user identification. Similar to other classical machine learning tasks, the training performance of speaker verification relies heavily on the number and diversity of data. Therefore third-party data (e.g. data from public dataset benchmarks, the Internet or other cooperating companies) need to be included during the training process. This raises two major questions: How to use multiparty data while ensuring data security and privacy? Whether adopting entrusted third-party data can threaten the security of the speaker verification model? In this paper, we first demonstrate that federated learning (FL) provides an alternative way for training the speaker verification model without collecting data from multi-parties together. We then validate that it is possible to perform backdoor attack under a looser threat assumption, namely poisoning partial speakers instead of all of the speakers. Specifically, we study the security of speaker verification models in FL for the first time. During the training process of FL, we make full use of the advantages of FL, and design a two stage training strategy. Besides, we propose Global Spectral Cluster (GSC) method to alleviate insufficient trigger generalization problem, which cased by the constrain that the attacker can only reach and poison its own data. We also adopt Personalized Federated Aggregation (PFAgg) to avoid modeling pollution in other parties, enhancing the invisibility of backdoor attack in FL. Experimental results on the TIMIT dataset show that our proposed framework can not only achieve satisfying attack results, but also have an acceptable error rate.
3.Can Spoofing Countermeasure And Speaker Verification Systems Be Jointly Optimised?
标题:欺骗对抗和说话人验证系统能否联合优化?
作者:Wanying Ge, Hemlata Tak, Massimiliano Todisco and Nicholas Evans
单位:EURECOM, Sophia Antipolis, France
链接:https://ieeexplore.ieee.org/document/10095068
摘要:欺骗对抗(CM)和自动说话人验证(ASV)子系统可以与后端分类器一起使用,作为欺骗感知说话人验证(SASV)任务的解决方案。这两个子系统通常被独立训练以解决不同的任务。虽然我们之前的工作展示了联合优化的潜力,但它也显示了对说话人过度拟合的趋势以及缺乏子系统互补性。仅使用从新说话人收集的少量辅助数据,我们证明了联合优化降低了单独的CM和ASV子系统的性能,但它仍然提高了互补性,从而提供了优越的SASV性能。使用标准的SASV评估数据和协议,联合优化相对于在同类训练条件下使用固定的、独立优化的子系统获得的性能减少了27%的相同错误率。
Spoofing countermeasure (CM) and automatic speaker verification (ASV) sub-systems can be used in tandem with a backend classifier as a solution to the spoofing aware speaker verification (SASV) task. The two sub-systems are typically trained independently to solve different tasks. While our previous work demonstrated the potential of joint optimisation, it also showed a tendency to over-fit to speakers and a lack of sub-system complementarity. Using only a modest quantity of auxiliary data collected from new speakers, we show that joint optimisation degrades the performance of separate CM and ASV sub-systems, but that it nonetheless improves complementarity, thereby delivering superior SASV performance. Using standard SASV evaluation data and protocols, joint optimisation reduces the equal error rate by 27% relative to performance obtained using fixed, independently-optimised subsystems under like-for-like training conditions.
4.Convolution-Based Channel-Frequency Attention for Text-Independent Speaker Verification
标题:基于卷积的独立文本说话人信道频率关注验证
作者:Jingyu Li, Yusheng Tian, Tan Lee
单位:Department of Electronic Engineering, The Chinese University of Hong Kong, Hong Kong
链接:https://ieeexplore.ieee.org/document/10095415
摘要:深度卷积神经网络(CNN)已被应用于说话人嵌入提取,在说话人验证方面取得了显著成功。引入注意机制可以有效地提高模型的性能。本文提出了一种高效的基于二维卷积的注意力模块C2D-Att。轻量级卷积层的注意力计算涉及到卷积通道和频率之间的相互作用。这只需要少量的参数。产生细粒度的注意权重来表示特定于信道和频率的信息。对输入特征进行加权,提高说话人建模的表示能力。C2D-Att集成到ResNet的修改版本中,用于说话人嵌入提取。实验在VoxCeleb数据集上进行。结果表明,C2DAtt在生成判别注意图方面是有效的,并且优于其他注意方法。该模型在不同尺度的模型尺寸下均表现出良好的鲁棒性,取得了较好的效果。
Deep convolutional neural networks (CNNs) have been applied to extracting speaker embeddings with significant success in speaker verification. Incorporating the attention mechanism has shown to be effective in improving the model performance. This paper presents an efficient two-dimensional convolution-based attention module, namely C2D-Att. The interaction between the convolution channel and frequency is involved in the attention calculation by lightweight convolution layers. This requires only a small number of parameters. Fine-grained attention weights are produced to represent channel and frequency-specific information. The weights are imposed on the input features to improve the representation ability for speaker modeling. The C2D-Att is integrated into a modified version of ResNet for speaker embedding extraction. Experiments are conducted on VoxCeleb datasets. The results show that C2DAtt is effective in generating discriminative attention maps and outperforms other attention methods. The proposed model shows robust performance with different scales of model size and achieves state-of-the-art results.
5. Covariance Regularization for Probabilistic Linear Discriminant Analysis
标题:概率线性判别分析的协方差正则化
作者:Zhiyuan Peng1,2, Mingjie Shao3, Xuanji He2, Xu Li4, Tan Lee1, Ke Ding2, Guanglu Wan2
单位:1Department of Electronic Engineering, The Chinese University of Hong Kong
2Meituan
3School of Information Science and Engineering, Shandong University, China
4ARC Lab, Tencent PCG
链接:https://ieeexplore.ieee.org/document/10094608
摘要:概率线性判别分析(PLDA)通常用于说话人验证系统中对说话人嵌入的相似度进行评分。近年来的研究通过对角化PLDA的协方差来提高其在域匹配条件下的性能。我们怀疑这种残酷的修剪方法可能会消除其建模说话人嵌入维度相关性的能力,导致域自适应性能不足。本文探讨了两种可选的协方差正则化方法,即插值PLDA和稀疏PLDA来解决这一问题。插值后的PLDA结合余弦评分的先验知识对PLDA的协方差进行插值。稀疏PLDA引入了稀疏性惩罚来更新协方差。实验结果表明,两种方法在域自适应下都明显优于对角正则化。此外,在训练稀疏PLDA进行域适应时,可以显著减少域内数据。
Probabilistic linear discriminant analysis (PLDA) is commonly used in speaker verification systems to score the similarity of speaker embeddings. Recent studies improved the performance of PLDA in domain-matched conditions by diagonalizing its covariance. We suspect such a brutal pruning approach could eliminate its capacity in modeling dimension correlation of speaker embeddings, leading to inadequate performance with domain adaptation. This paper explores two alternative covariance regularization approaches, namely, interpolated PLDA and sparse PLDA, to tackle the problem. The interpolated PLDA incorporates the prior knowledge from cosine scoring to interpolate the covariance of PLDA. The sparse PLDA introduces a sparsity penalty to update the covariance. Experimental results demonstrate that both approaches outperform diagonal regularization noticeably with domain adaptation. In addition, in-domain data can be significantly reduced when training sparse PLDA for domain adaptation.
6.Cross-Modal Audio-Visual Co-Learning for Text-Independent Speaker Verification
标题:文本独立说话人验证的跨模态视听协同学习
作者:Meng Liu1,2, Kong Aik Lee2,3, Longbiao Wang1, Hanyi Zhang1, Chang Zeng4, Jianwu Dang1
单位:1Tianjin Key Laboratory of Cognitive Computing and Application,College of Intelligence and Computing, Tianjin University, Tianjin, China
2Institute for Infocomm Research, A⋆STAR, Singapore
3Singapore Institute of Technology, Singapore
4National Institute of Informatics, Tokyo, Japan
链接:https://ieeexplore.ieee.org/document/10095883
摘要:视觉言语(即唇部运动)与听觉言语高度相关,这是由于言语产生过程中的共现性和同步性。本文研究了这种相关性,并提出了一种跨模态语音共同学习范式。我们的跨模态共同学习方法的主要动机是在利用另一模态的知识的帮助下对一模态建模。具体来说,引入了两个基于视听伪连体结构的跨模态助推器来学习模态转换的相关性。在每个助推器内部,提出了一个最大特征映射嵌入式Transformer变体,用于模态对齐和增强特征生成。这个网络可以从零开始学习,也可以与预先训练好的模型一起学习。在测试场景下的实验结果表明,我们提出的方法比基线单峰和融合系统的平均相对性能分别提高了60%和20%。
Visual speech (i.e., lip motion) is highly related to auditory speech due to the co-occurrence and synchronization in speech production. This paper investigates this correlation and proposes a crossmodal speech co-learning paradigm. The primary motivation of our cross-modal co-learning method is modeling one modality aided by exploiting knowledge from another modality. Specifically, two cross-modal boosters are introduced based on an audio-visual pseudo-siamese structure to learn the modality-transformed correlation. Inside each booster, a max-feature-map embedded Transformer variant is proposed for modality alignment and enhanced
feature generation. The network is co-learned both from scratch and with pretrained models. Experimental results on the test scenarios demonstrate that our proposed method achieves around 60% and 20% average relative performance improvement over baseline unimodal and fusion systems, respectively.
7. DASA: Difficulty-Aware Semantic Augmentation for Speaker Verification
标题:DASA:用于说话人验证的困难感知语义增强
作者:Yuanyuan Wang1, Yang Zhang1, Zhiyong Wu1,3, Zhihan Yang1, Tao Wei2, Kun Zou2, Helen Meng3
单位:1 Shenzhen International Graduate School, Tsinghua University, Shenzhen, China
2 Ping An Technology, Shenzhen, China
3 The Chinese University of Hong Kong, Hong Kong SAR, China
链接:https://ieeexplore.ieee.org/document/10095066
摘要:数据增强对深度神经网络模型的泛化能力和鲁棒性至关重要。现有的说话人验证增强方法对原始信号进行处理,耗时长,增强后的样本缺乏多样性。本文提出了一种新的困难感知语义增强(DASA)方法用于说话人验证,该方法可以在说话人嵌入空间中生成多样化的训练样本,而额外的计算成本可以忽略不计。首先,我们通过沿语义方向扰动从说话人协方差矩阵中获得的说话人嵌入来增强训练样本。其次,在训练过程中从稳健的说话人嵌入中估计出准确的协方差矩阵,因此我们引入了难度感知加性余量softmax (DAAM-Softmax)来获得最优的说话人嵌入。最后,我们假设增广样本的数量趋于无穷,并利用DASA导出了期望损失的封闭上界,从而达到了兼容和效率。大量的实验表明,该方法可以取得显著的性能改进。在CN-名人评价集上,最佳结果达到了相对降低14.6%的EER指标。
Data augmentation is vital to the generalization ability and robustness of deep neural networks (DNNs) models. Existing augmentation methods for speaker verification manipulate the raw signal, which are time-consuming and the augmented samples lack diversity. In this paper, we present a novel difficulty-aware semantic augmentation (DASA) approach for speaker verification, which can generate diversified training samples in speaker embedding space with negligible extra computing cost. Firstly, we augment training samples by perturbing speaker embeddings along semantic directions, which are obtained from speaker-wise covariance matrices. Secondly, accurate covariance matrices are estimated from robust speaker embeddings during training, so we introduce difficultyaware additive margin softmax (DAAM-Softmax) to obtain optimal speaker embeddings. Finally, we assume the number of augmented samples goes to infinity and derive a closed-form upper bound of the expected loss with DASA, which achieves compatibility and efficiency. Extensive experiments demonstrate the proposed approach can achieve a remarkable performance improvement. The best result achieves a 14.6% relative reduction in EER metric on CN-Celeb evaluation set.
8.Discriminative Speaker Representation Via Contrastive Learning with Class-Aware Attention in Angular Space
标题:角度空间中基于类注意对比学习的说话人辨别表征
作者:Zhe LI 1, Man-Wai MAK1, Helen Mei-Ling MENG2
单位:1Department of Electronic and Information Engineering, The Hong Kong Polytechnic University
2Department of Systems Engineering and Engineering Management, The Chinese University of Hong Kong
链接:https://ieeexplore.ieee.org/document/10096230
摘要:将对比学习应用于说话人验证(SV)的挑战在于,基于softmax的对比损失缺乏辨别力,而硬否定对很容易影响学习。为了克服第一个挑战,我们提出了一种对比学习SV框架,该框架在监督的对比损失中加入了一个附加的角度裕度,其中该裕度提高了说话人表征的辨别能力。对于第二个挑战,我们引入了一种类意识注意机制,通过该机制,硬负样本对监督对比损失的贡献较小。我们还采用了基于梯度的多目标优化来平衡分类和对比损失。在CN Celeb和Voxceleb1上的实验结果表明,这种新的学习目标可以使编码器找到一个嵌入空间,该嵌入空间在不同语言之间表现出很大的说话人区分能力。
The challenges in applying contrastive learning to speaker verification (SV) are that the softmax-based contrastive loss lacks discriminative power and that the hard negative pairs can easily influence learning. To overcome the first challenge, we propose a contrastive learning SV framework incorporating an additive angular margin into the supervised contrastive loss in which the margin improves the speaker representation’s discrimination ability. For the second challenge, we introduce a class-aware attention mechanism through which hard negative samples contribute less significantly to the supervised contrastive loss. We also employed gradient-based multi-objective optimization to balance the classification and contrastive loss. Experimental results on CN-Celeb and Voxceleb1 show that this new learning objective can cause the encoder to find an embedding space that exhibits great speaker discrimination across languages.
9. Distance-Based Weight Transfer for Fine-Tuning From Near-Field to Far-Field Speaker Verification
标题:基于距离的权重转移用于近场到远场说话人验证的微调
作者:Li Zhang1, Qing Wang1, Hongji Wang2, Yue Li1, Wei Rao2, Yannan Wang2, Lei Xie1
单位:1Audio, Speech and Language Processing Group (ASLP@NPU), School of Computer Science, Northwestern Polytechnical University (NPU), Xi’an, China
2Tencent Ethereal Audio Lab, Tencent Corporation, Shenzhen, China
链接:https://ieeexplore.ieee.org/document/10096790
摘要:标记远场语音的稀缺性是训练优秀远场说话人验证系统的制约因素。一般来说,通过少量远场语音对大规模近场语音预训练的模型进行微调,大大优于从头开始训练。然而,香草微调有两个局限性——灾难性遗忘和过度拟合。在本文中,我们提出了一种权重转移正则化(WTR)损失来约束预训练模型和微调模型之间的权重距离。在WTR损失的情况下,微调过程利用了先前从大范围近场语音中获得的判别能力,避免了灾难性遗忘。同时,基于PAC-Bayes泛化理论的分析表明,WTR损失使得微调模型具有更严格的泛化界,从而减轻了过拟合问题。此外,还探讨了三种不同的权值转移范数距离,即L1范数距离、L2范数距离和Max范数距离。我们评估了WTR损失在VoxCeleb(预训练)和FFSVC(微调)数据集上的有效性。实验结果表明,基于距离的权值转移微调策略明显优于传统微调和其他竞争性领域自适应方法。
The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. In general, fine-tuning the model pre-trained on large-scale nearfield speech through a small amount of far-field speech substantially outperforms training from scratch. However, the vanilla fine-tuning suffers from two limitations – catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization (WTR) loss to constrain the distance of the weights between the pre-trained model and the fine-tuned model. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech and avoids catastrophic forgetting. Meanwhile, the analysis based on the PAC-Bayes generalization theory indicates that the WTR loss makes the fine-tuned model have a tighter generalization bound, thus mitigating the overfitting problem. Moreover, three different norm distances for weight transfer are explored, which are L1-norm distance, L2-norm distance, and Max-norm distance. We evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained) and FFSVC (fine-tuned) datasets. Experimental results show that the distance-based weight transfer fine-tuning strategy significantly outperforms vanilla finetuning and other competitive domain adaptation methods.
10.Exploring Binary Classification Loss for Speaker Verification
标题:说话人验证中二元分类损失的探讨
作者:Bing Han, Zhengyang Chen, Yanmin Qian
单位:MoE Key Lab of Artificial Intelligence, AI Institute
X-LANCE Lab, Department of Computer Science and Engineering
Shanghai Jiao Tong University, Shanghai, China
链接:https://ieeexplore.ieee.org/document/10094954
摘要:闭集训练和开集测试之间的不匹配通常会导致说话人验证任务的性能显著下降。对于现有的损失函数,基于度量学习的目标强烈依赖于搜索有效对,这可能会阻碍进一步的改进。当在看不见的说话人上进行评估时,流行的多分类方法通常会出现退化。在这项工作中,我们介绍了SphereFace2框架,该框架使用几个二进制分类器以成对的方式训练说话人模型,而不是执行多分类。得益于这种学习范式,它可以有效地缓解训练和验证之间的差距。在Voxceleb上进行的实验表明,SphereFace2的性能优于其他现有的损失函数,尤其是在硬测试中。此外,大幅度微调策略被证明与之兼容,可以进一步改进。最后,SphereFace2还显示出其对类噪声标签的强大鲁棒性,这有可能应用于估计伪标签不准确的半监督训练场景。
The mismatch between close-set training and open-set testing usually leads to significant performance degradation for speaker verification task. For existing loss functions, metric learning-based objectives depend strongly on searching effective pairs which might hinder further improvements. And popular multi-classification methods are usually observed with degradation when evaluated on unseen speakers. In this work, we introduce SphereFace2 framework which uses several binary classifiers to train the speaker model in a pair-wise manner instead of performing multi-classification. Benefiting from this learning paradigm, it can efficiently alleviate the gap between training and evaluation. Experiments conducted on Voxceleb show that the SphereFace2 outperforms other existing loss functions, especially on hard trials. Besides, large margin fine-tuning strategy is proven to be compatible with it for further improvements. Finally, SphereFace2 also shows its strong robustness to class-wise noisy labels which has the potential to be applied in the semi-supervised training scenario with inaccurate estimated pseudo labels.
11.Hybrid Neural Network with Cross- and Self-Module Attention Pooling for Text-Independent Speaker Verification
标题:基于跨模块和自模块注意力池的混合神经网络用于文本无关说话人验证
作者:Jahangir Alam, Woo Hyun Kang, Abderrahim Fathan
单位:Computer Research Institute of Montreal (CRIM)
链接:https://ieeexplore.ieee.org/document/10096040
摘要:在基于深度学习的说话人验证中,说话人嵌入向量的提取起着重要的作用。在这篇论文中,我们提出了一种混合神经网络,采用交叉和自模块注意池机制来提取说话人鉴别话语水平嵌入。更具体地说,该系统将基于2D卷积神经网络(CNN)的特征提取模块与帧级网络级联,该网络由全时延神经网络(TDNN)网络和TDNN-长短期记忆(TDNNLSTM)混合网络并行组成。该系统还采用多层次的交叉和自模块注意池,通过捕获两个平行连接模块之间的互补性来聚合话语级上下文中的说话人信息。为了评估所提出的系统,我们在Voxceleb语料库上进行了一组实验,所提出的混合网络能够优于在相同数据集上训练的传统方法。
Extraction of a speaker embedding vector plays an important role in deep learning-based speaker verification. In this contribution, to extract speaker discriminant utterance level embeddings, we propose a hybrid neural network that employs both cross- and self-module attention pooling mechanisms. More specifically, the proposed system incorporates a 2D-Convolution Neural Network (CNN)-based feature extraction module in cascade with a frame-level network, which is composed of a fully Time Delay Neural Network (TDNN) network and a TDNN-Long Short Term Memory (TDNNLSTM) hybrid network in a parallel manner. The proposed system also employs a multi-level cross- and self-module attention pooling for aggregating the speaker information within an utterance-level context by capturing the complementarity between two parallelly connected modules. In order to evaluate the proposed system, we conduct a set of experiments on the Voxceleb corpus, and the proposed hybrid network is able to outperform the conventional approaches trained on the same dataset.
12.Improving Learning Objectives for Speaker Verification from the Perspective of Score Comparison
标题:从分数比较的角度完善说话人验证的学习目标
作者:Min Hyun Han, Sung Hwan Mun, Minchan Kim, Myeonghun Jeong, Sung Hwan Ahn, Nam Soo Kim
单位:Department of Electrical and Computer Engineering and INMC Seoul National University, Seoul, South Korea
链接:https://ieeexplore.ieee.org/document/10095828
摘要:深度说话人嵌入系统通常使用基于分类或端到端学习目标进行训练。流行的端到端方法利用深度度量学习,可以将其视为少量分类目标。本文探讨了传统学习目标在说话人验证中的局限性,提出了一种基于相似度分数的学习目标设计方法。该方法通过不受分类约束的分数比较来训练网络,更适合于验证任务。用流行的说话人嵌入网络进行的实验表明,使用所提出的损失对VoxCeleb数据集进行了改进。
Deep speaker embedding systems are usually trained with classification-based or end-to-end learning objectives. Popular end-to-end approaches utilize deep metric learning, which can be viewed as a few-shot classification objective. In this paper, we investigate the limit of conventional learning objectives in speaker verification and propose a new learning objective designed from the perspective of similarity scores. The proposed method trains a network by score comparison unbound from the classification, which is more suitable for verification tasks. Experiments conducted with popular speaker embedding networks demonstrate the improvements on the VoxCeleb dataset using the proposed loss.
13.Improving Transformer-Based Networks with Locality for Automatic Speaker Verification
标题:改进基于局部Transformer的说话人自动验证网络
作者:Mufan Sang1, Yong Zhao2, Gang Liu2, John H.L. Hansen1, Jian Wu2
单位:1The University of Texas at Dallas, TX, USA
2Microsoft Corporation, One Microsoft Way, Redmond, WA 98052, USA
链接:https://ieeexplore.ieee.org/document/10096333
摘要:近年来,基于Transformer的结构被用于语音嵌入提取。虽然Transformer使用自关注机制来有效地模拟token嵌入之间的全局交互,但它不足以捕获短的本地上下文,而这对于准确提取说话人信息至关重要。在本研究中,我们在两个方向上增强了变压器的局部性建模。首先,我们通过将深度卷积和通道关注引入到Conformer块中,提出了位置增强的Conformer (LE - Conformer)。其次,我们将最初提出的用于视觉任务的Swin Transformer应用到说话人嵌入网络中,提出了说话人Swin Transformer (SST)。我们在VoxCeleb数据集和大型微软内部多语言(MS-internal)数据集上评估了所提出的方法。提出的模型在VoxCeleb 1测试集上达到0.75%的EER,优于先前提出的基于Transformer的模型和基于CNN的模型,如ResNet34和ECAPA-TDNN。当在MS-internal数据集上训练时,所提出的模型取得了令人满意的结果,与Res2Net50模型相比,EER相对降低了14.6%。
Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing shortrange local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the enhanced locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer(SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
14.Incorporating Uncertainty from Speaker Embedding Estimation to Speaker Verification
标题:结合从说话人嵌入估计到说话人验证的不确定性
作者:Qiongqiong Wang, Kong Aik Lee, Tianchi Liu
单位:Institute for Infocomm Research (I2R), A⋆STAR, Singapore
链接:https://ieeexplore.ieee.org/document/10097019
摘要:在不同条件下记录的语音对其嵌入估计表现出不同程度的置信度,即不确定性,即使它们是使用相同的神经网络提取的。本文旨在将xi向量网络前端产生的不确定性估计与概率线性判别分析(PLDA)后端评分相结合,用于说话人验证。为了实现这一点,我们推导了一个后验协方差矩阵,它测量了从逐帧精度到嵌入空间的不确定性。我们提出了一个具有不确定性传播的PLDA评分的对数似然比函数。我们还提出用长度缩放技术取代长度归一化预处理技术,以在后端应用不确定性传播。在VoxCeleb-1、SITW测试集以及域不匹配的CNCeleb1-E测试集上的实验结果表明,所提出的技术可以将EER降低14.5% ~ 41.3%,将minDCF降低4.6% ~ 25.3%。
Speech utterances recorded under differing conditions exhibit varying degrees of confidence in their embedding estimates, i.e., uncertainty, even if they are extracted using the same neural network. This paper aims to incorporate the uncertainty estimate produced in the xi-vector network front-end with a probabilistic linear discriminant analysis (PLDA) back-end scoring for speaker verification. To achieve this we derive a posterior covariance matrix, which measures the uncertainty, from the frame-wise precisions to the embedding space. We propose a log-likelihood ratio function for the PLDA scoring with the uncertainty propagation. We also propose to replace the length normalization pre-processing technique with a length scaling technique for the application of uncertainty propagation in the back-end. Experimental results on the VoxCeleb-1, SITW test sets as well as a domain mismatched CNCeleb1-E set show the effectiveness of the proposed techniques with 14.5%–41.3% EER reductions and 4.6%–25.3% minDCF reductions.
15.JSV-VC: Jointly Trained Speaker Verification and Voice Conversion Models
标题:JSV-VC:联合训练说话人验证和语音转换模型
作者:Shogo Seki, Hirokazu Kameoka, Kou Tanaka, Takuhiro Kaneko
单位:NTT Communication Science Laboratories, NTT Corporation, Japan
链接:https://ieeexplore.ieee.org/document/10096901
摘要:本文提出了一种基于变分自编码器(VAE)的无平行语料库的任意源-目标说话人对的语音转换方法,即非并行任意到任意语音转换。一种典型的方法是使用从说话人验证(SV)模型获得的说话人嵌入作为VC模型的条件。然而,在VC和SV模型的朴素组合中,转换后的语音并不能保证反映目标说话人的特征。此外,说话人嵌入不是为VC问题设计的,导致转换性能不理想。为了解决这些问题,本文提出的方法JSV-VC同时训练VC和SV模型。对VC模型进行训练,使转换后的语音在SV模型中被验证为目标说话人,对SV模型进行训练,使其在VC模型前后输出一致的嵌入。实验评价表明,JSV -VC在定量和定性上都优于传统的任意对任意VC方法。
This paper proposes a variational autoencoder (VAE)-based method for voice conversion (VC) on arbitrary source-target speaker pairs without parallel corpora, i.e., non-parallel any-to-any VC. One typical approach is to use speaker embeddings obtained from a speaker verification (SV) model as the condition for a VC model. However, converted speech is not guaranteed to reflect a target speaker’s characteristics in a naive combination of VC and SV models. Moreover, speaker embeddings are not designed for VC problems, leading to suboptimal conversion performance. To address these issues, the proposed method, JSV-VC, trains both VC and SV models jointly. The VC model is trained so that converted speech is verified as the target speaker in the SV model, while the SV model is trained in order to output consistent embeddings before and after the VC model. The experimental evaluation reveals that JSV-VC outperforms conventional any-to-any VC methods quantitatively and qualitatively.