数据库架构设计
数据库架构分类
介绍
介绍常见的 四种 数据库架构设计模型: 单库架构、分组架构、分片架构和分组分片架构 ,以及每种架构的 使用场景、存在的问题和对应的解决方案 。
一、数据模型
我们以 “ 用户中心 ” 数据库作为 数据模型 ,讲解数据库架构设计的方法。
用户中心是一个 常见业务,主要提供用户注册、登录、查询以及修改等服务,其核心元数据 :
User(uid, uname, passwd, sex, age,nickname, …)。
uid 为用户的ID,主键。
uname, passwd, sex, age, nickname 为用户的属性。
二、单库架构
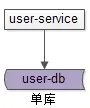
通常在 业务初期 ,数据库无需特别的设计, 单库单表就能满足业务需求 ,这也是 最常见的数据库架构 。
user-service:用户中心服务,为调用者提供 RPC 接口或者 Restful API。
user-db:使用一个库进行数据存储,提供数据库读写服务。
三、分组架构
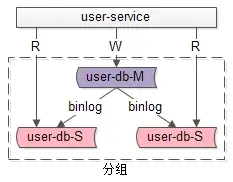
1. 什么是分组架构
分组架构是最常见的 一主多从,主从同步,读写分离 的数据库架构。
user-service:用户中心服务。
user-db-M(master):主库,提供数据库写服务。
user-db-S(slave):从库,提供数据库读服务。
主库和从库构成的数据库集群称为“组”。
2. 分组架构有什么特点
同一个组里的数据库集群:
主从之间通过 binlog 进行数据同步。
多个范例数据库结构完全相同。
多个范例存储的数据完全相同, 本质上是将数据进行复制 。
3. 分组架构解决什么问题
大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈 。如果希望:
线性提升数据库读性能。
通过消除读写锁冲突提升数据库写性能。
通过冗余从库实现数据的“读高可用”。
此时可以使用分组架构。但是, 在分组架构中,数据库的主库依然是写单点 。
总之, 分组架构是为了解决 “读写并发量高” 的问题,而实施的架构设计。
四、分片架构
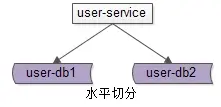
1. 什么是分片架构
分片架构是 水平切分(sharding) 数据库架构。
user-service:用户中心服务。
user-db1:水平切分成2份中的第一份。
user-db2:水平切分成2份中的第二份。
分片后,多个数据库范例也会构成一个数据库集群 。
2. 水平切分,应该分库还是分表
强烈建议分库,而不是分表 ,因为:
分表依然共用一个数据库文件,仍然有磁盘 IO 的竞争。
分库能够将数据迁移到不同数据库范例,甚至数据库服务器,扩展性更好。
3. 水平切分,用什么算法
常见的水平切分算法 有 “范围法” 和 “哈希法” :
范围法
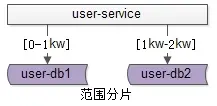
以用户中心的业务主键 uid 为 划分依据 , 将数据水平切分到两个数据库范例上去 :
user-db1:存储0到1千万的 uid 数据。
user-db2:存储0到2千万的 uid 数据。
哈希法
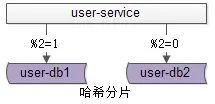
以用户中心的业务主键 uid 为 划分依据 , 将数据水平切分到两个数据库范例上去 :
user-db1:存储 uid 取模为1的 uid 数据。
user-db2:存储 uid 取模为0的 uid 数据。
这两种方法在互联网都有使用,其中 哈希法使用较为广泛 。
4. 分片架构有什么特点
同一个分片里的数据库集群:
多个范例之间本身不直接产生联系, 不像主从间有 binlog 同步 。
多个范例的数据库结构完全相同。
多个范例存储的数据之间没有交集, 所有范例的数据并集构成全局数据 。
5. 分片架构解决什么问题
大部分互联网 业务的数据量很大 , 单库 容量容易 成为瓶颈 ,此时 通过分片可以 :
线性提升数据库写性能。
线性提升数据库读性能。
降低单库数据容量。
总之, 分片架构是为了解决 “数据量大” 的问题,而实施的架构设计。
五、分组+分片架构
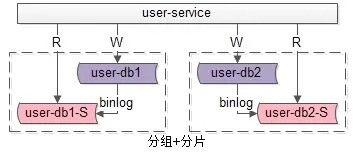
如果业务读写并发量很高,数据量也很大,通常需要实施分组+分片的数据库架构 :
通过分片来降低单库的数据量,线性提升数据库的写性能。
通过分组来线性提升数据库的读性能,保证读库的高可用。
六、数据库垂直切分
除了水平切分, 垂直切分也是一类常见的数据库架构设计 ,垂直切分 一般和业务结合比较紧密。
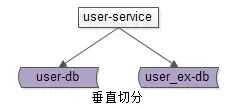
以 用户中心 为例,可以这么 进行垂直切分 :
User(uid, uname, passwd, sex, age, …)
User_EX(uid, intro, sign, …)
垂直切分开的表,主键都是 uid。
登录名,密码,性别,年龄等属性放在一个垂直表(库)里。
自我介绍,个人签名等属性放在另一个垂直表(库)里。
1. 如何进行垂直切分
根据业务情况对数据进行垂直切分时,一般 要考虑属性的“长度”和“访问频度”两个因素 :
长度较短,访问频率较高的放在一起。
长度较长,访问频度较低的放在一起。
这是因为,数据库会以行(row)为单位,将数据加载到内存。在内存容量有限的情况下,长度短且访问频度高的属性,内存可以加载更多的数据,命中率提高,磁盘IO减少,数据库的读性能得到提升。
2. 垂直切分有什么特点
垂直切分 和水平切有相似的地方,又不太相同 :
多个范例之间也不直接产生联系,即 没有 binlog 同步 。
多个范例 数据库结构都不相同 。
多个范例存储的数据之间 至少有一列交集,一般来说是业务主键,所有范例间数据并集构成全局数据 。
3. 垂直切分解决什么问题
垂直切分即 可以降低单库的数据量,还可以降低磁盘IO从而提升吞吐量,但它与业务结合比较紧密,并不是所有业务都能够进行垂直切分的。
数据库架构设计
介绍
数据库架构设计是 针对海量数据的数据库,通过数据结构、存储形式和部署方式等方面的规划和设计,以解决数据库服务的高并发、高可用、一致性、可扩展以及性能优化等问题。
一、可用性设计
可用性是 指在某个考察时间,系统能够正常运行的概率或时间占有率的期望值。 通常, 我们都要求某个系统具备“高可用性” 。
所谓 “高可用性”(High Availability) 是指系统经过专门的设计, 从而减少停工时间,保持其服务的高度可用。
数据库的高可用, 通常采用的解决方式为:复制+冗余。
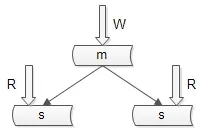
1. 保证 “读” 高可用的方法
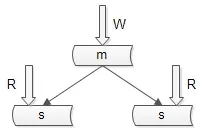
数据库主从复制,冗余数据。如图所示:
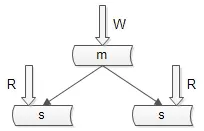
主库用于写数据,从库用于读数据 。在 一主多从 的数据库架构中, 多份从库数据保证了读数据高可用 。
数据库主从复制 可能带来的问题:主从数据不一致。
2. 保证 “写” 高可用的方法
双主模式,即复制主库,冗余数据。如图所示:
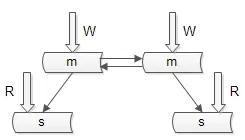
很多公司 采用单主模式,这是无法保证数据库写的高可用性。
数据库双主模式 可能带来的问题:双主同步 key 冲突,引起数据不一致。
解决方案:
a)方案一:由数据库或者业务层保证 key 在两个主库上不冲突。
b)方案二:“双主” 当 “主从” 用,不做读写分离,当主库挂掉时,启用从库。如图下图:
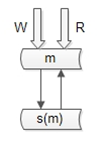
优点:读写都到主,解决了一致性问题;“双主”当“主从”用,解决了可用性问题
带来的问题:读性能如何扩充?解决方案见下文
二、读性能设计:如何扩展读性能
1. 建立索引
建立太多的索引,会带来以下问题 :
a)降低了写性能。
b)索引占用内存多了,内存存放的数据就会减少,数据命中率降低,IO次数随之增加。
对于索引过多的问题,有以下 解决方案 :
不同的库可以建立不同索引。
主库只提供写,不建立索引。
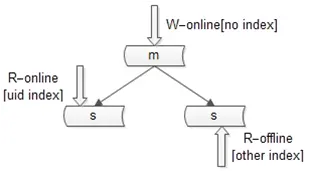
online 从库只提供 online 读,建立 online 读索引。
offline 从库只提供 offline 读,建立 offline 读索引。
2. 增加从库
增加从库 会引发主从不一致问题,从库越多,主从时延越长,不一致问题越严重 。这种方案很常见,但我们在生产环境中没有采用。
3. 增加缓存
传统缓存的使用方案 :
a)发生写请求时,先淘汰缓存,再写数据库。
b)发生读请求时,先读缓存,hit则返回,miss则读数据库并将数据入缓存(此时可能旧数据入缓存)。
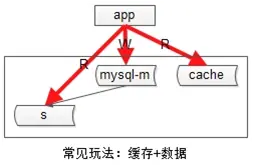
增加缓存 会带来的两个问题 :
a)数据复制会引发一致性问题,由于主从延时的存在,可能引发缓存与数据库数据不一致。
b)业务层要关注缓存,无法屏蔽“主+从+缓存”的复杂性。
我们缓存的使用方案:服务+数据+缓存。
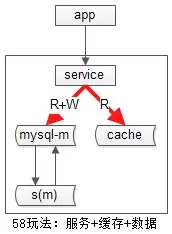
这种方案带来的好处:
a)引入服务层屏蔽“数据库+缓存”
b)不做读写分离,读写都到主的模式,不会引发不一致
三、一致性设计
1. 主从不一致的解决方案
a)方案一:引入中间件
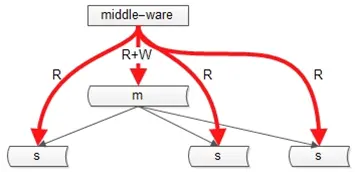
中间件将key上的写路由到主,在一定时间范围内(主从同步完成的经验时间),该key上的读也路由到主库。
b)方案二:读写都到主
我们采用的方案, 不做读写分离,数据不会不一致。
2. 数据库与缓存不一致的解决方案
两次淘汰法:
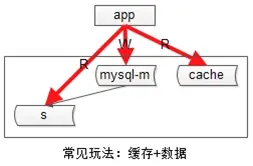
异常的读写时序,或导致旧数据入缓存,一次淘汰不够,要进行二次淘汰。
a)发生写请求时,先淘汰缓存,再写数据库,额外增加一个timer,一定时间(主从同步完成的经验时间)后再次淘汰。
b)发生读请求时,先读缓存,hit则返回,miss则读数据库并将数据入缓存(此时可能旧数据入缓存,但会被二次淘汰淘汰掉,最终不会引发不一致)。
四、扩展性设计
https://blog.58heshihu.com/index.php/archives/258/
或者
https://www.cnblogs.com/wintersun/p/4638176.html
数据库水平切分策略
分库寻址
当数据库的数据量很大时,就需要对库或表进行水平切分 。最常见的水平切分方式, 共有四种策略 :
索引表法
缓存映射法
计算法
基因法
一、数据模型
我们以 “用户中心” 数据库作为数据模型,讲解数据库的水平切分策略。
用户中心是一个常见业务,主要提供用户注册、登录、查询以及修改等服务,其核心元数据:
User(uid, uname, passwd, sex, age,nickname, …)。
uid 为用户的ID,主键。
uname, passwd, sex, age, nickname 为用户的属性。
用户中心是几乎每一个公司必备的基础服务,用户注册、登录、信息查询与修改都离不开用户中心。
二、数据库水平切分方案
当数据量越来越大时,需要多用户中心进行水平切分 。 最常见 的水平切分方式, 按照 uid 取模分库 :
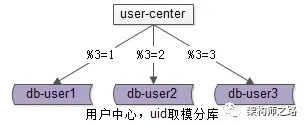
通过 uid 取模, 将数据分布到多个数据库实例上去,提高服务实例个数,降低单库数据量,以达到扩容的目的。
水平切分之后 :
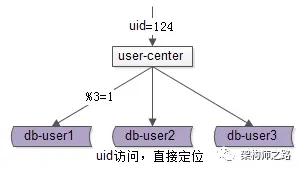
uid 属性 上的查询可以 直接路由到库 ,如上图,假设访问 uid=124 的数据,取模后能够直接定位db-user1。
大多数场景下,我们都不会通过 uid 进行的登录,而是使用 uname 登录。那么 对于 uname 上的查询 ,就不能这么幸运了:
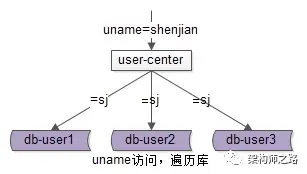
uname 上的查询,如上图,假设访问 uname=codebaoku 的数据, 由于不知道数据落在哪个库上,往往需要遍历所有库(扫全库法),当分库数量多起来,性能会显著降低 。
用 uid 分库,如何高效实现 uname 上的查询 ,是本文将要讨论的问题。
三、数据库水平切分查询策略
1)方案一:索引表法
思路: uid 能直接定位到库,uname 不能直接定位到库,如果通过 uname 能查询到 uid,问题解决。
解决方案 :
(1)建立一个索引表记录 uname 到 uid 的映射关系;
(2)用 uname 来访问时,先通过索引表查询到 uid,再定位相应的库;
(3) 索引表属性较少,可以容纳非常多数据,一般不需要分库;
(4) 如果数据量过大,可以通过 uname 来分库;
潜在不足:多一次数据库查询,性能下降一倍。
2)方案二:缓存映射法
思路: 访问索引表性能较低,把映射关系放在缓存里性能更佳。
解决方案 :
(1)uname 查询先到 cache 中查询 uid,再根据 uid 定位数据库;
(2)假设 cache miss,采用扫全库法获取 uname 对应的 uid,放入 cache;
(3)uname 到 uid 的映射关系不会变化, 映射关系一旦放入缓存,不会更改,无需淘汰,缓存命中率超高;
(4) 如果数据量过大,可以通过 name 进行 cache 水平切分;
潜在不足:多一次cache查询。
3)方案三:计算法,uname 生成 uid
思路: 不进行远程查询,由 uname 直接得到 uid。
解决方案 :
(1)在用户注册时,设计函数 uname 生成 uid,uid=f(uname),按 uid 分库插入数据;
(2)用 uname 来访问时,先通过函数计算出 uid,即 uid=f(uname)再来一遍,由 uid 路由到对应库;
潜在不足:该函数设计需要非常讲究技巧,有 uid 生成冲突风险。
4)方案四:基因法,uname 基因融入 uid
思路: 不能用uname生成uid,可以从uname抽取“基因”,融入uid中。
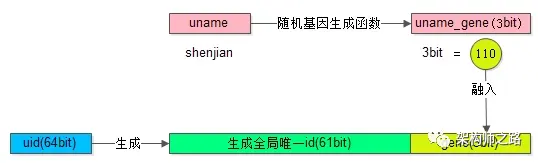
假设分 8 库,采用 uid%8 路由 ,潜台词是, uid 的最后 3 个 bit 决定这条数据落在哪个库上,这 3 个 bit 就是所谓的“基因”。
解决方案 :
(1)在用户注册时,设计函数 uname 生成 3bit 基因,uname_gene=f(uname),如上图粉色部分;
(2)同时,生成 61bit 的全局唯一 id,作为用户的标识,如上图绿色部分;
(3)接着把 3bit 的 uname_gene 也作为 uid 的一部分,如上图屎黄色部分;
(4)生成 64bit 的 uid,由 id 和 uname_gene 拼装而成,并按照 uid 分库插入数据;
(5)用 uname 来访问时,先通过函数由 uname 再次复原 3bit 基因,uname_gene=f(uname),通过 uname_gene%8 直接定位到库。
MySQL分库分表设计
1. 为什么要分库分表
物理服务机的CPU、内存、存储设备、连接数等资源有限 ,某个时段 大量连接同时执行操作 ,会导致数据库在处理上遇到 性能瓶颈 。
为了解决这个问题,行业先驱门充分发扬了 分而治之 的思想,对大库表进行分割, 然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。
数据库分库分表有 两种实现方式:垂直拆分 和 水平拆分 。
2. 垂直拆分(Scale Up 纵向扩展)
垂直拆分分为 垂直分库和垂直分表 ,主要 按功能模块拆分,以解决 各个库或者各个表之间的 资源竞争 。
比如分为订单库、商品库、用户库…这种方式,多个数据库之间的表结构是不同的。
2.1 垂直分库
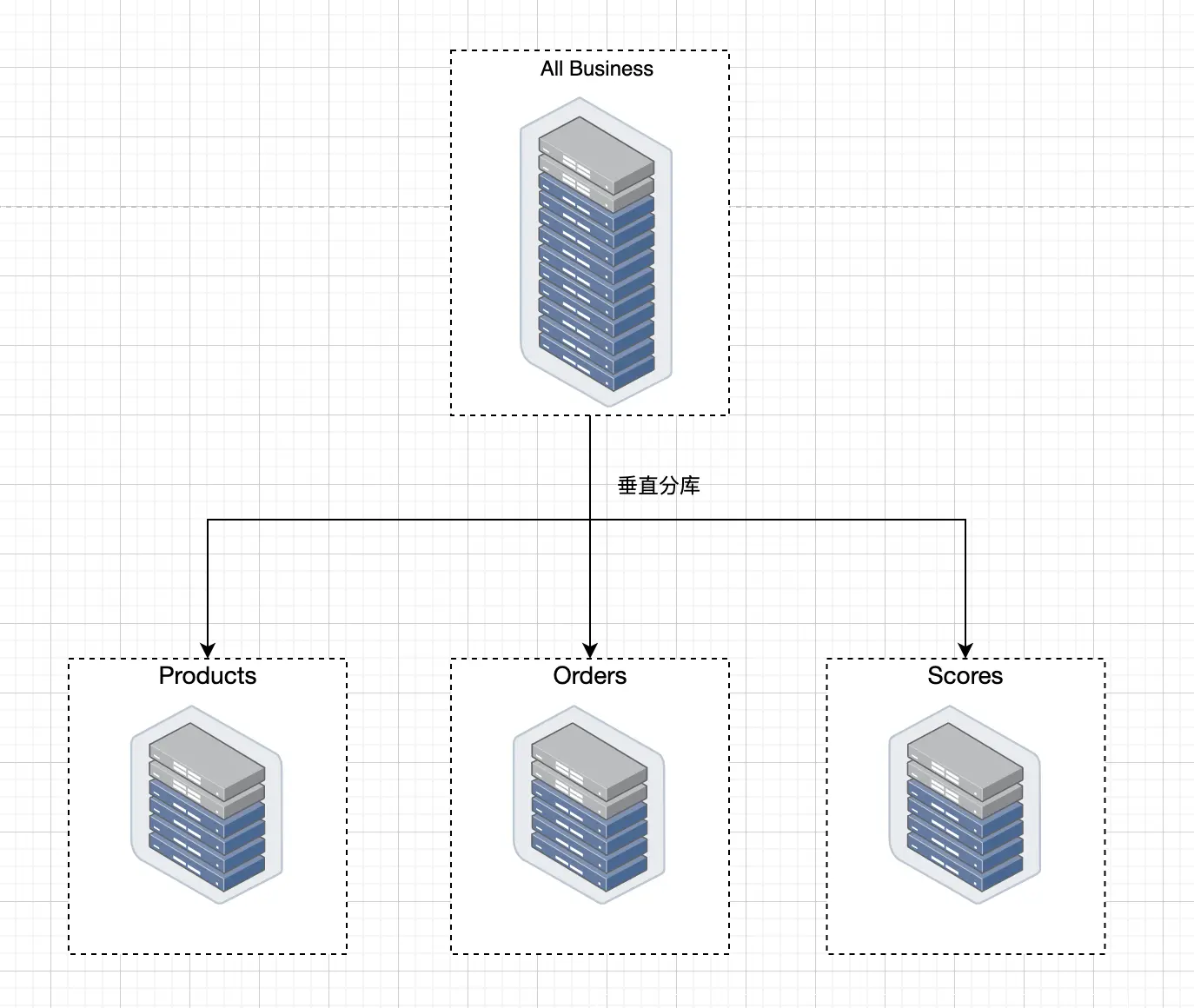
垂直分库其实 是一种简单的逻辑分割 。比如我们的 数据库中有商品表Products、还有对订单表Orders,还有积分表Scores。
接下来我们就可以创建三个数据库,一个数据库存放商品,一个数据库存放订单,一个数据库存放积分。
垂直分库有一个优点,就是能够根据业务场景进行孵化 ,比如某一单一场景只用到某2-3张表,基本上应用和数据库可以拆分出来做成相应的服务。
拆分方式如下图所示:
2.2 垂直分表
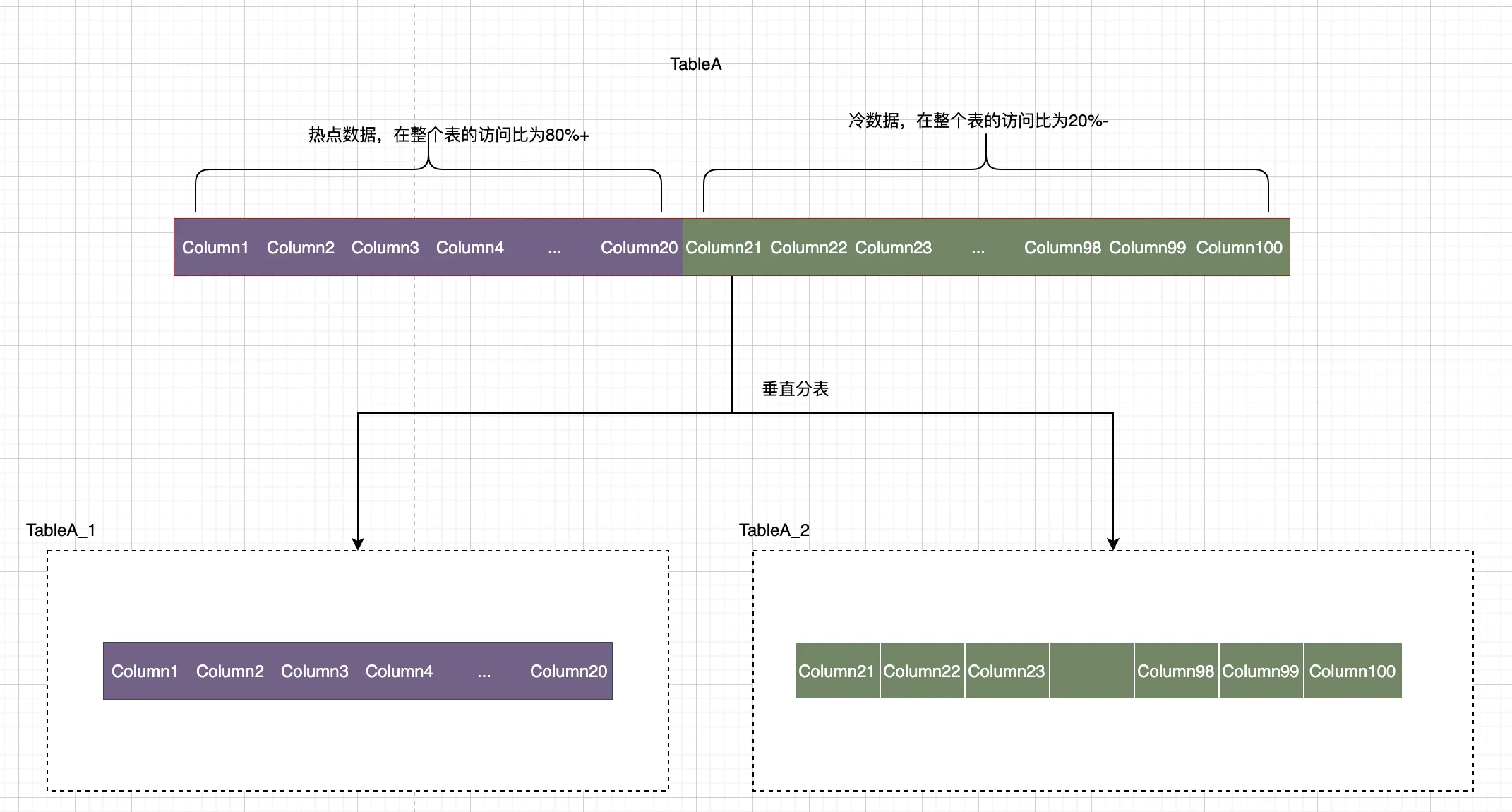
垂直分表,比较 适用于那种字段比较多的表 ,假设我们一张表有100个字段,我们分析了一下当前业务执行的SQL语句,有20个字段是经常使用的,而另外80个字段使用比较少。
这样我们就可以把20个字段放在主表里面,我们再创建一个辅助表,存放另外80个字段。
当然主表和辅助表都是有主键的,他们通过主键进行关联合并,就可以组合成100个字段的表。
拆分方式如下图所示:
除了这种访问频率的冷热拆分之外,还可以按照字段类型结构来拆分,比如大文本字段单独放在一个表中,与基础字段隔离,提高基础字段的访问效率。
也可以将字段按照功能用途来拆分,比如采购的物料表可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直拆分。
垂直拆分的优点 :
跟随业务进行分割,类似微服务的分治理念,方便解耦之后的管理及扩展。
高并发的场景下,垂直拆分使用多台服务器的 CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限制也得到了提升,能实现冷热数据的分离。
垂直拆分的缺点 :
部分业务表无法 join,应用层需要很大的改造,只能通过聚合的方式来实现,增加了开发的难度。
单表数据量膨胀的问题依然没有得到有效的解决,分布式事务也是一个难题。
3. 水平拆分(Scale Out 横向扩展)
水平拆分又 分为库内分表和分库分表,来解决单表中数据量增长出现的压力,这些数据库中的表结构完全相同。
3.1 库内分表
先说说库内分表。假设 当我们的 Orders 表达到了 5000万 行记录的时候,非常影响数据库的读写效率 ,怎么办呢? 我们 可以考虑按照订单编号的 order_id 进行 rang分区 ,就是把订单编号在 1-1000万 的放在order1表中,将编号在 1000万-2000万 的放在 order2 中,以此类推,每个表中存放 1000万 行数据。
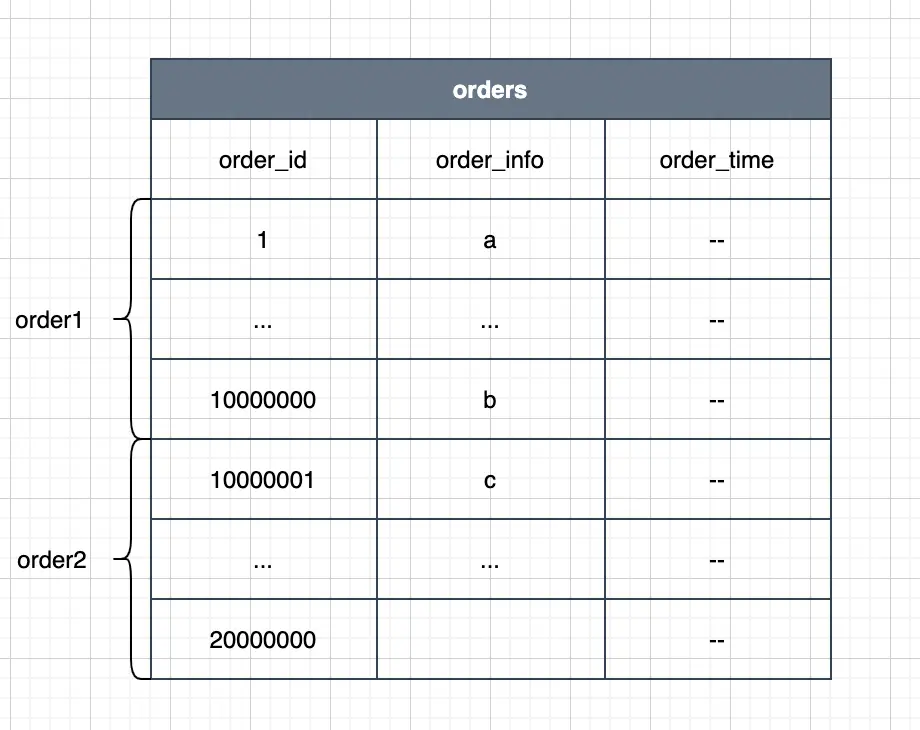
关于水平分表的时机 ,业内的标准不是很统一, 阿里的Java 开发手册的标准是当单表行数超过 500万行或者单表容量超过 2 GB时, 才推荐进行分库分表。 百度的则是1000 W行的进行分表 ,这个是百度的DBA经过测试推算出的结果。
但是这边忽略了单表的字段数和字段类型,如果字段数很多,超过50列,对性能影响也是不小的,我们曾经有个业务,表字段是随着业务的增长而自动扩增的,到了后期,字段越来越多,查询性能也越来越慢。
所以个人觉得不必拘泥于500W 还是1000W,开发人员在使用过程中, 如果压测发现因为数据基数变大而导致执行效率慢下来,就可以开始考虑分表了。
3.2 库内分表的实现策略
目前在 MySql 中支持四种表分区的方式 ,分别为 HASH、RANGE、LIST及KEY ,当然在其它的类型数据库中,分区的实现方式略有不同,但是分区的思想原理是相同,具体如下:
3.2.1 HASH(哈希)
HASH 分区 主要用来确保数据在预先确定数目的分区中平均分布 ,而在 RANGE 和 LIST 分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中,而在HASH 分区中,MySQL 自动完成这些工作,
你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。 示例如下:
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY HASH(YEAR(createtime))
PARTITIONS 10;
上面的例子,使用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里共分为 10 个分区。
建表语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式,它可以是字段类型为 MySQL 整型的一列的名字,也可以是返回非负数的表达式。
另外,可能需要在后面再添加一个“PARTITIONS num”子句,其中 num 是一个非负的整数,它表示表将要被分割成分区的数量。
3.2.2 RANGE(范围)
基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠 ,使用 VALUES LESS THAN 操作符来进行定义。示例如下:
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE(gwcode) (
PARTITION P0 VALUES LESS THAN(101) ,
PARTITION P1 VALUES LESS THAN(201) ,
PARTITION P2 VALUES LESS THAN(301) ,
PARTITION P3 VALUES LESS THAN MAXVALUE
);
上面的示例,使用了范围RANGE函数对岗位编号进行分区,共分为4个分区,
岗位编号为 1~100 的对应在分区P0中,101~200 的编号在分区P1中,依次类推即可。那么类别编号大于 300,可以使用MAXVALUE来将大于 300 的数据统一存放在分区 P3中即可。
3.2.3 LIST(预定义列表)
类似于按 RANGE 分区,区别在于 LIST 分区 是基于列值匹配一个离散值集合中的某个值来进行选择分区的。 LIST 分区 通过使用“PARTITION BY LIST(expr)”来实现 ,其中 “expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式 ,
然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表 。 示例如下:
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY LIST(`gwcode`) (
PARTITION P0 VALUES IN (46,77,89) ,
PARTITION P1 VALUES IN (106,125,177) ,
PARTITION P2 VALUES IN (205,219,289) ,
PARTITION P3 VALUES IN (302,317,458,509,610)
);
上面的例子,使用了列表匹配LIST函数对员工岗位编号进行分区,共分为4个分区,编号为46,77,89的对应在分区P0中,106,125,177类别在分区P1中,依次类推即可。
不同于RANGE的是,LIST分区的数据必须匹配列表中的岗位编号才能进行分区,所以这种方式只是适合比较区间值确定并少量的情况。
3.2.4 KEY(键值)
类似于按HASH分区,区别在于 KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。 示例如下:
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY KEY(gwcode)
PARTITIONS 10;
注意: 此种分区算法目前使用的比较少 ,使用服务器提供的哈希函数有不确定性,对于后期数据统计、整理存在会更复杂,所以我们 更倾向于使用由我们定义表达式的 Has h,大家知道其存在和怎么使用即可。
3.2.5 Composite(复合模式)
Composite 是上面几种模式的组合使用,比如你在 Range的基础上,再进行 Hash 哈希分区。
3.3 分库分表
库内分表解决了单表数据量过大的瓶颈问题,但使用还是同一主机的CPU、IO、内存,另外单库的连接数也有限制,并不能完全的降低系统的压力 。 此时,我们就要考虑另外一种技术叫 分库分表 。分库分表 在库内分表的基础上,将分的表挪动到不同的主机和数据库上。可以充分的使用其他主机的CPU、内存和IO资源 。 拆分方式进一步演进到下面:

4. 分库分表存在的问题
4.1 事务问题
在执行分库分表之后, 由于数据存储到了不同的库上,数据库事务管理出现了困难 。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
4.2 跨库跨表的join问题
在执行了分库分表之后, 难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上 ,这时, 表的关联操作将受到限制 ,我们无法 join 位于不同分库的表,也无法 join 分表粒度不同的表,结果 原本一次查询能够完成的业务,可能需要多次查询才能完成。
4.3 额外的数据管理负担和数据运算压力
额外的数据管理负担 ,最显而易见的就是 数据的定位问题和数据的增删改查的重复执行问题 ,这些都可以通过应用程序解决,但必然 引起额外的逻辑运算 ,例如,对于一个记录用户成绩的用户数据表 userTable,业务要求查出成绩最好的 100 位,在进行分表之前,
只需一个 order by 语句就可以搞定,但是在进行分表之后,将需要 n 个 order by 语句,分别查出每一个分表的前 100 名用户数据,然后再对这些数据进行合并计算,才能得出结果。