1. 识别非小计行
1.1. 结果集

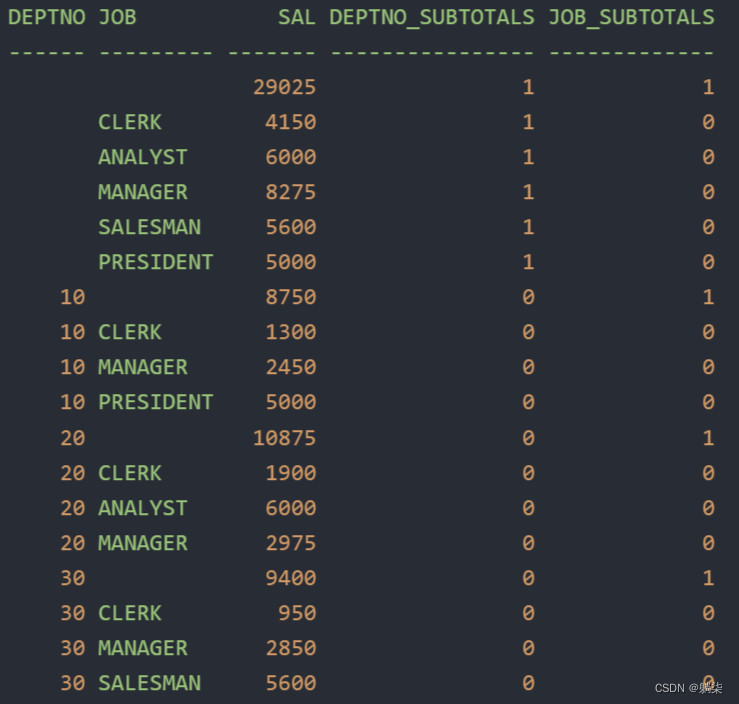
1.2. DB2
1.3. Oracle
1.4. 超级聚合(supera ggregate)值
1.4.1. sql
select deptno, job, sum(sal) sal,
grouping(deptno) deptno_subtotals,
grouping(job) job_subtotals
from emp
group by cube(deptno,job)1.5. SQL Server
1.5.1. sql
select deptno, job, sum(sal) sal,
grouping(deptno) deptno_subtotals,
grouping(job) job_subtotals
from emp
group by deptno,job with cube2. 使用CASE表达式标记行数据
2.1. 结果集

2.2. sql
select ename,
case when job = 'CLERK'
then 1 else 0
end as is_clerk,
case when job = 'SALESMAN'
then 1 else 0
end as is_sales,
case when job = 'MANAGER'
then 1 else 0
end as is_mgr,
case when job = 'ANALYST'
then 1 else 0
end as is_analyst,
case when job = 'PRESIDENT'
then 1 else 0
end as is_prez
from emp
order by 2,3,4,5,63. 创建稀疏矩阵
3.1. 结果集

3.2. sql
select case deptno when 10 then ename end as d10,
case deptno when 20 then ename end as d20,
case deptno when 30 then ename end as d30,
case job when 'CLERK' then ename end as clerks,
case job when 'MANAGER' then ename end as mgrs,
case job when 'PRESIDENT' then ename end as prez,
case job when 'ANALYST' then ename end as anals,
case job when 'SALESMAN' then ename end as sales
from emp3.3. sql
select max(case deptno when 10 then ename end) d10,
max(case deptno when 20 then ename end) d20,
max(case deptno when 30 then ename end) d30,
max(case job when 'CLERK' then ename end) clerks,
max(case job when 'MANAGER' then ename end) mgrs,
max(case job when 'PRESIDENT' then ename end) prez,
max(case job when 'ANALYST' then ename end) anals,
max(case job when 'SALESMAN' then ename end) sales
from (
select deptno, job, ename,
row_number()over(partition by deptno order by empno) rn
from emp
) x
group by rn3.3.1. 删除一些Null行,以便让整个报表显得“紧密”一些
4. 按照时间单位分组
4.1. 结果集
4.1.1. sql
select trx_id,
trx_date,
trx_cnt
from trx_log
TRX_ID TRX_DATE TRX_CNT
------ -------------------- ----------
1 28-JUL-2005 19:03:07 44
2 28-JUL-2005 19:03:08 18
3 28-JUL-2005 19:03:09 23
4 28-JUL-2005 19:03:10 29
5 28-JUL-2005 19:03:11 27
6 28-JUL-2005 19:03:12 45
7 28-JUL-2005 19:03:13 45
8 28-JUL-2005 19:03:14 32
9 28-JUL-2005 19:03:15 41
10 28-JUL-2005 19:03:16 15
11 28-JUL-2005 19:03:17 24
12 28-JUL-2005 19:03:18 47
13 28-JUL-2005 19:03:19 37
14 28-JUL-2005 19:03:20 48
15 28-JUL-2005 19:03:21 46
16 28-JUL-2005 19:03:22 44
17 28-JUL-2005 19:03:23 36
18 28-JUL-2005 19:03:24 41
19 28-JUL-2005 19:03:25 33
20 28-JUL-2005 19:03:26 194.1.2. 结果集
GRP TRX_START TRX_END TOTAL
--- -------------------- -------------------- ----------
1 28-JUL-2005 19:03:07 28-JUL-2005 19:03:11 141
2 28-JUL-2005 19:03:12 28-JUL-2005 19:03:16 178
3 28-JUL-2005 19:03:17 28-JUL-2005 19:03:21 202
4 28-JUL-2005 19:03:22 28-JUL-2005 19:03:26 1734.2. sql
select ceil(trx_id/5.0) as grp,
min(trx_date) as trx_start,
max(trx_date) as trx_end,
sum(trx_cnt) as total
from trx_log
group by ceil(trx_id/5.0)5. 多维度聚合运算
5.1. 结果集

5.2. DB2
5.3. Oracle
5.4. SQL Server
5.5. 窗口函数COUNT OVER
5.5.1. sql
select ename,
deptno,
count(*)over(partition by deptno) deptno_cnt,
job,
count(*)over(partition by job) job_cnt,
count(*)over() total
from emp5.6. PostgreSQL
5.7. MySQL
5.8. 使用标量子查询
5.8.1. sql
select e.ename,
e.deptno,
(select count(*) from emp d
where d.deptno = e.deptno) as deptno_cnt,
job,
(select count(*) from emp d
where d.job = e.job) as job_cnt,
(select count(*) from emp) as total
from emp e6. 动态区间聚合运算
6.1. 入职最早的员工的HIREDATE作为起始点,每隔90天计算一次工资合计值
6.1.1. 结果集
HIREDATE SAL SPENDING_PATTERN
----------- ------- ----------------
17-DEC-1980 800 800
20-FEB-1981 1600 2400
22-FEB-1981 1250 3650
02-APR-1981 2975 5825
01-MAY-1981 2850 8675
09-JUN-1981 2450 8275
08-SEP-1981 1500 1500
28-SEP-1981 1250 2750
17-NOV-1981 5000 7750
03-DEC-1981 950 11700
03-DEC-1981 3000 11700
23-JAN-1982 1300 10250
09-DEC-1982 3000 3000
12-JAN-1983 1100 41006.2. DB2
6.3. Oracle
6.4. 窗口函数SUM OVER
6.4.1. sql
select hiredat,
sal,
sum(sal)over(order by days(hiredate)
range between 90 preceding
and current row) spending_pattern
from emp e6.4.2. sql
select hiredate,
sal,
sum(sal)over(order by hiredate
range between 90 preceding
and current row) spending_pattern
from emp e6.4.2.1. Oracle的窗口函数支持DATE类型排序
6.5. PostgreSQL
6.6. MySQL
6.7. SQL Server
6.8. 使用标量子查询
6.8.1. sql
select e.hiredate,
e.sal,
(select sum(sal) from emp d
where d.hiredate between e.hiredate-90
and e.hiredate) as spending_pattern
from emp e
order by 17. 变换带有小计的结果集
7.1. 结果集


7.2. DB2
7.3. Oracle
7.4. 使用GROUP BY的ROLLUP扩展
7.4.1. sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
cast(grouping(deptno) as char(1))||
cast(grouping(mgr) as char(1)) flag
from emp
where mgr is not null
group by rollup(deptno,mgr)
) x
group by mgr7.5. SQL Server
7.5.1. sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
cast(grouping(deptno) as char(1))+
cast(grouping(mgr) as char(1)) flag
from emp
where mgr is not null
group by deptno,mgr with rollup
) x
group by mgr