目录
普通构造
构造函数基础
显示调用与隐式调用
explicit关键字
初始化列表
拷贝构造
拷贝构造的写法
深拷贝和浅拷贝
拷贝构造的调用时机
返回值优化
析构函数
析构函数基础
析构函数的作用
注意事项
如果无法调用构造函数,那么就无法实例化出对象
如果无法调用析构函数,就无法成功释放对象
编译器会提供默认的构造和析构
类内构造与析构的调用顺序
全缺省构造与无参构造的二义性
普通构造
在C++中,构造函数是一种特殊的成员函数,用于在创建对象时进行初始化操作。构造函数的名称与类的名称相同,没有返回类型,并且可以有多个重载版本。当创建一个新的对象时,构造函数会自动调用,确保对象在创建后处于有效的初始状态。构造函数也可以进行重载,允许在同一个类中定义多个构造函数,只要符合重载的条件即可。
构造函数基础
要点概要
- 函数名与类名相同。
- 无返回值。
- 可以有参数。
- 可以给变量设初始值。
- 构造函数可以重载。
- 可以设缺省值。
- 默认会自动调用。
写法示例
#include <iostream>
using namespace std;
class MyClass
{
public:
// 默认构造函数
MyClass()
{
cout << "Default constructor called." << endl;
}
// 参数化构造函数
MyClass(int x, int y)
{
cout << "Parameterized constructor called with x=" << x << " and y=" << y << endl;
}
};
int main()
{
// 使用默认构造函数创建对象
MyClass obj1; // 输出: Default constructor called.
// 使用参数化构造函数创建对象
MyClass obj2(10, 20); // 输出: Parameterized constructor called with x=10 and y=20.
// 使用拷贝构造函数创建对象
MyClass obj3 = obj2; // 输出: Copy constructor called.
return 0;
}
显示调用与隐式调用
函数的调用可以分为两种方式:显示调用和隐式调用。
显示调用是指在代码中明确指定调用某个函数。这种调用方式是最常见的,我们在代码中使用函数名和参数列表来直接调用函数。隐式调用是指在特定情况下,编译器自动帮助我们调用函数,而无需在代码中显式地写出函数调用语句。这种情况通常出现在运算符重载、类型转换和构造函数等特殊情况下。
同理,构造函数的调用也分显示调用和隐式调用。
显示调用构造函数(Explicit Constructor Call)
显示调用构造函数是指在代码中直接使用构造函数来创建对象。这种方式使用类名和参数列表来明确调用构造函数,从而创建对象。具体写法如下:
隐式调用构造函数(Implicit Constructor Call)
隐式调用构造函数是指在特定情况下,编译器自动帮助我们调用构造函数来创建对象,而无需在代码中显式地写出构造函数调用语句。其中单参构造或只有一个参数没设缺省值的要特别注意,单参构造函数的隐式转换是指当类的构造函数只有一个参数时,该参数的类型可以隐式地转换为类类型,从而创建类的对象。
代码示例如下:
/* 无参构造、有参构造和拷贝构造都加了explicit限制 */
// 显示调用↓
CallTest c1;
CallTest c2(7.3, 'B');
CallTest c3(c2);
// c4的匿名对象这里是没问题的,但赋值的时候是隐式调用,触动了拷贝构造的explicit
CallTest c4 = CallTest(c1); //error
// pc是指针,不涉及拷贝构造,只有右边的普通构造
CallTest* pc = new CallTest();
// c5的右边也是没问题的,还是拷贝构造的explicit给限制了
CallTest c5 = static_cast<CallTest>(17); //error
// 隐式调用↓
//CallTest cc02 = { 17 }; //单参构造 - error1
//CallTest cc01 = 17; //单参构造 - error2
//CallTest cc1 = { 9, 'Z' };
//CallTest cc2 = c2;explicit关键字
类的构造函数前加explicit关键字表示显示声明。它主要用于修饰类的构造函数,防止编译器进行隐式类型转换,特别是单参数构造函数,以增强类型安全性。默认情况下,C++允许在特定情况下进行隐式类型转换,这种行为可能导致不直观的结果和潜在的错误,因为程序员可能无意中使用了不期望的转换。
通过在构造函数声明中添加explicit关键字,可以明确指示该构造函数不应该用于隐式类型转换。这样一来,在使用这个类的对象时,就只能使用显式构造方式,从而避免了隐式转换引发的潜在问题。以下是关于explicit关键字的一些其它要点:
1. explicit关键字的用法很简单,直接在构造函数前面加上一个explicit就可以了
explicit ClassName(parameters...);2. explicit修饰的构造函数为显示调用的意思,表明不能进行隐式类型转换。其中这个隐式转换包括构造的隐式调用和类型的隐式转换两种含义。代码示例如下:
// 显式地创建对象 ClassName obj(parameter); // 显式类型转换 ClassName obj = static_cast<ClassName>(parameter); // 隐式地创建对象 ClassName obj = { parameter }; // 隐式地类型转换 ClassName obj = parameter;3. 这里说的隐式转换指的是对象之间的隐式转换,形参上发生的隐式转换对其没有影响。
初始化列表
在 C++ 中,初始化列表是一种用于初始化类成员变量的特殊语法。它允许在构造函数体执行之前对成员变量进行初始化,以提高代码的效率和性能。
通常,在类的构造函数中,成员变量的初始化是通过构造函数的初始化列表完成的,而不是在构造函数体内部赋值。这样做的好处是,初始化列表可以直接调用成员变量的构造函数来初始化它们,而不需要再调用默认构造函数然后在构造函数体内部赋值。这样可以避免不必要的构造函数调用和对象赋值,从而提高了代码的执行效率。
使用初始化列表的语法示例如下:
class MyClass
{
private:
int num1;
double num2;
char ch;
public:
// 构造函数的初始化列表位于构造函数的冒号后面
MyClass(int n, double d, char c) : num1(n), num2(d), ch(c)
{
// 构造函数体,可以进行其他操作
}
// 其他成员函数等等...
};
注意事项:
- 每个成员变量在初始化列表中只能出现一。(因为初始化操作只会进行一次)
- 类中的引用成员变量、const成员变量、自定义类型成员(且该类没有默认构造函数时)必须放在初始化列表位置进行初始化。
- 对于类的自定义类型成员,即使没有在初始化列表中显式地初始化这些成员变量,它们都会先调用自己的构造函数进行初始化,接着再执行构造函数体内的代码。
- 初始化列表按照成员的声明顺序初始化,与其在初始化列表中的先后顺序无关。
- 建议初始化操作最好通过初始化列表完成,因为使用初始化列表可以直接在构造函数中对成员变量进行初始化,而不需要先调用默认构造函数然后在构造函数体内部赋值。这样可以避免不必要的构造函数调用和对象赋值,提高代码的执行效率和性能。
- 普通的构造函数对变量进行初始化时,是先定义,再赋值。而初始化列表,是先声明,在调用构造函数时定义并初始化。
- 当没用初始化列表时,构造函数体内的其实是赋值操作,并不是严格意义上的初始化。
拷贝构造
拷贝构造的写法
在C++中,拷贝构造函数(Copy Constructor)是一种特殊的构造函数,用于创建一个对象的副本。当使用一个对象去初始化另一个对象时,或者将对象作为函数参数按值传递时,拷贝构造函数就会被调用。要注意,拷贝构造的参数是固定的常量类引用。
语法示例如下:
class MyClass
{
public:
// 拷贝构造函数
MyClass(const MyClass& other)
{
// 拷贝构造的函数体
}
// 其他成员和函数
};
其中,拷贝构造也可以用初始化列表,像这样:
CallTest(const CallTest& other) : _num(other._num), _ch(other._ch)
{
cout << "copy CallTest" << endl;
}下面是一些常见的疑惑点及其解释:
- 为什么拷贝构造的参数要设置成引用?
拷贝构造函数的参数设置成引用是为了避免无限递归调用和提高性能。
使用引用的一个必要之处在于:如果拷贝构造函数的参数不是引用,而是按值传递,那么在调用拷贝构造函数时会创建一个形参的副本。为了创建这个形参的副本,又需要调用拷贝构造函数,于是又会进入新的拷贝构造函数,而新的拷贝构造又会因为值传递而调用拷贝构造,从而无限递归调用拷贝构造函数。这样会导致无限递归,直到内存耗尽或栈溢出。如果是按值传递,那么在调用拷贝构造函数时,又要调用拷贝构造函数,形成了无限循环。
为了避免这种无限递归的情况,拷贝构造函数的参数通常设置为引用,引用参数不会创建副本,它直接引用传递的对象。这样,当拷贝构造函数被调用时,它只是引用了传递的对象,而不会创建新的副本,从而避免了无限递归调用。
使用引用作为参数还有一个额外的好处:它可以避免不必要的复制。如果使用按值传递的方式,会触发对象的复制,涉及到复制构造函数的调用和内存复制,这会使得传参成本增加。而使用引用传递,只是传递对象的引用,不会触发复制,因此性能会更好。
- 为什么拷贝构造的参数要设置成const的呢
原因有如下几点:
- 防止意外修改:使用`const`关键字可以确保在拷贝构造函数中不会意外地修改传递的对象的状态。如果不使用const,在拷贝过程中意外地修改传递的对象可能会导致错误和不一致的行为。
- 允许传递临时对象:常量引用允许拷贝构造函数的参数接受临时对象,而非常量引用则不可以。因为非常量引用的初始值必须为左值,而这就使得非常量引用无法接收临时变量这类的右值。所以使用常量引用,会提高代码的灵活性和可读性。
- 保持一致性:使用const引用作为拷贝构造函数的参数与其他成员函数使用常量引用的做法保持一致,这是良好的编程实践。
深拷贝和浅拷贝
深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是与拷贝操作相关的概念,通常涉及对象的复制和资源管理。
浅拷贝(Shallow Copy)
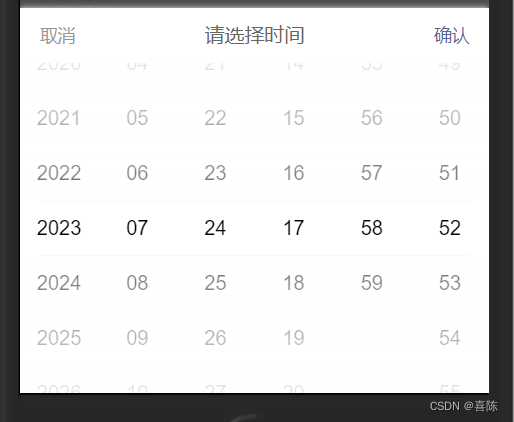
浅拷贝是指在进行对象复制时,只复制对象本身,而不复制对象所指向的资源。这意味着新创建的对象和原始对象共享同一个资源。因此,当一个对象修改资源时,另一个对象也会受到影响,可能导致“双重释放”问题。其中,编译器自动生成的默认拷贝构造就是浅拷贝。
代码示例如下:
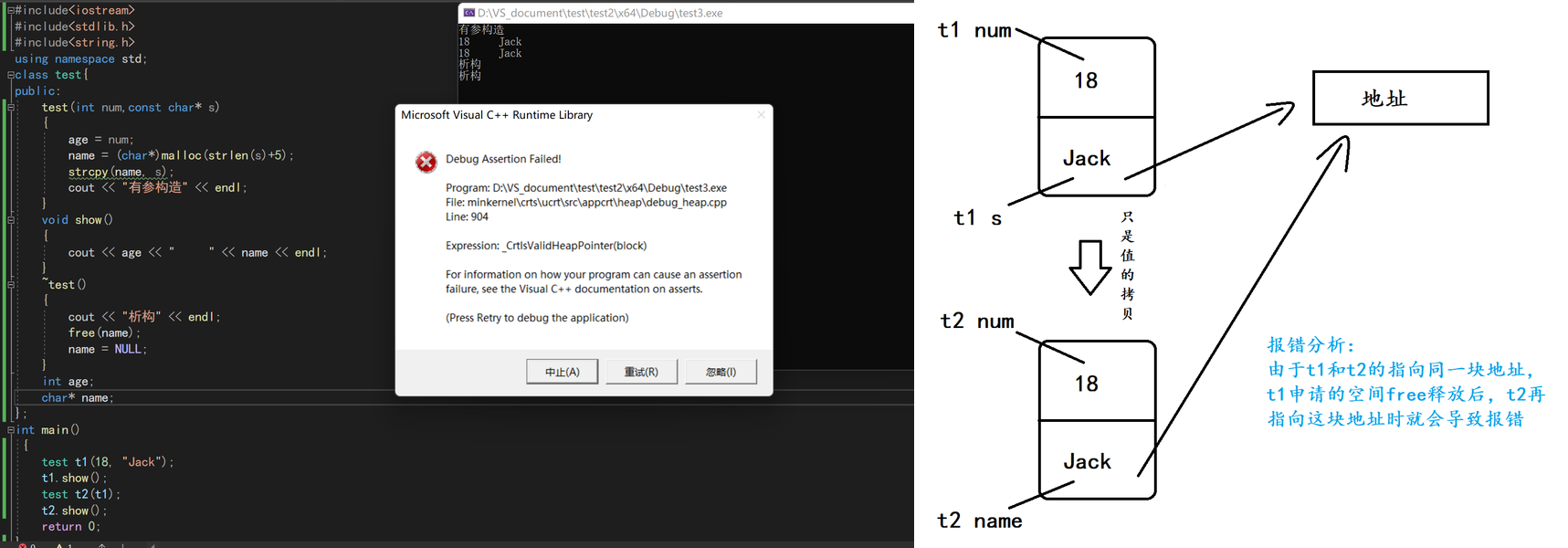
深拷贝(Deep Copy)
深拷贝是指在进行对象复制时,不仅复制对象本身,还复制对象所指向的动态分配的资源(例如堆内存、文件等)。这样,在新创建的对象和原始对象之间,每个对象都有其自己独立的资源副本。因此,对一个对象的修改不会影响到另一个对象的资源。代码示例如下:
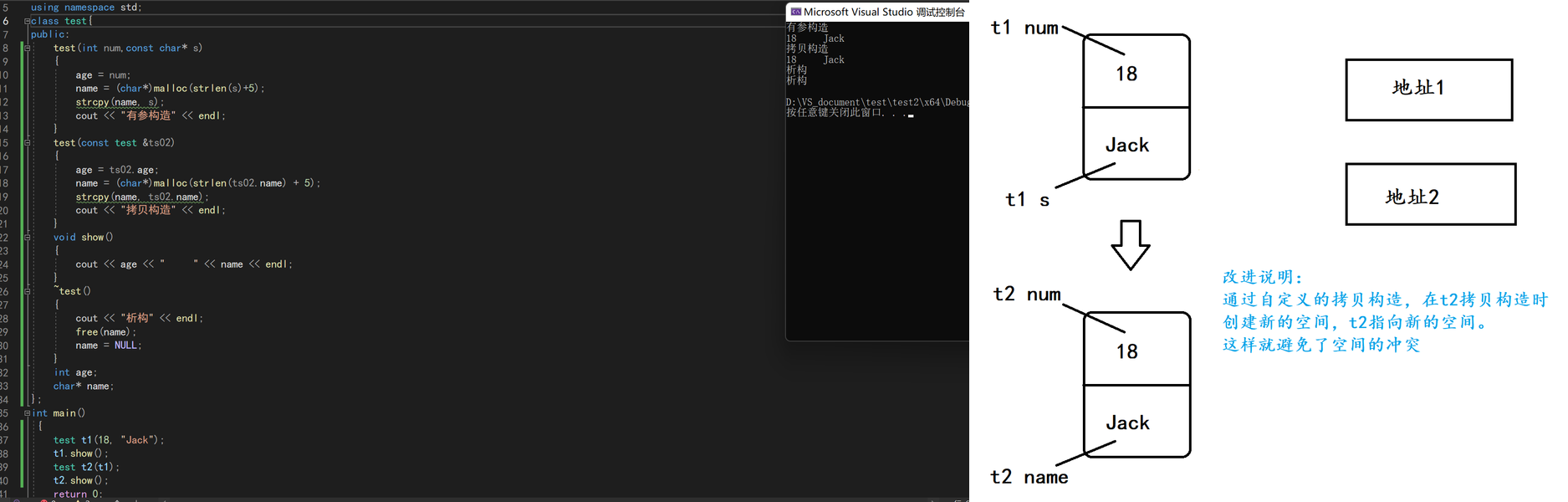
在使用自定义类时,特别是包含动态分配的资源(例如指针)时,需要谨慎选择使用深拷贝或浅拷贝。通常情况下,最好还是使用深拷贝,以避免资源管理的问题。
拷贝构造的调用时机
拷贝构造的调用时机大致可以概括为下面这几种:
类的拷贝初始化、赋值操作、传值传参、函数返回值。
类的拷贝初始化
这种是最常用也是最容易想到的一种。例如:
MyClass cls(other); //显示调用拷贝构造我们平时就经常使用这种方法进行初始化。
赋值操作
赋值时是隐式地调用了我们的拷贝构造。例如:
MyClass cls;
cls = { val }; //隐式地调用拷贝构造
// 或者下面这种也是隐式调用拷贝构造
MyClass cls = { val };这种赋值操作也是我们经常用到的。
传值传参
当一个函数设置了当前类的非引用参数,那么进行传值传参时,并不是直接将原对象传进去,而是将原对象的值拷贝给一个临时变量,这时就设计到了拷贝构造。(也就是函数传参的本质)例如设有类AnotherClass如下:
class MyClass {
public:
MyClass() {
std::cout << "Default Constructor" << std::endl;
}
MyClass(const MyClass& other) {
std::cout << "Copy Constructor" << std::endl;
}
};
class AnotherClass {
public:
AnotherClass(MyClass obj) : myObject(obj) {}
private:
MyClass myObject;
};那么当我们如下调用时
MyClass obj1; // 调用默认构造函数
AnotherClass obj2(obj1); // 调用拷贝构造函数,会调用2次就会输出如下结果:
Default Constructor
Copy Constructor
Copy Constructor那么解释一下,当对
AnotherClass(MyClass obj) : myObject(obj) {}传参时,将原对象的值拷贝给obj这个临时变量时会调用一次拷贝构造。而 myObject(obj) 时又会显示的调用一次拷贝构造以完成初始化。
函数返回值
函数返回值的原理和函数传参的类似,因为函数在返回时并不是直接返回,而是将返回值拷贝给一个临时变量,然后函数栈帧销毁,将这个临时变量返回到函数调用处。而这个过程中,将最终的返回值拷贝给临时变量的时候也是触发了拷贝构造。
MyClass someFunction() {
MyClass obj;
return obj; // 调用拷贝构造函数
}
但是当我们真正去试的时候发现并没有真正的调用构造函数,这是因为C++进行了返回值优化,至于什么是返回值优化,我们下面就会讲到。
接下来让我们总结一下,其实调用拷贝构造的时机,从本质上讲就是我们很容易看到的显示调用拷贝构造和我们不容易看到的调用拷贝构造。而显示调用很容易发觉就不说了。不容易察觉的拷贝构造大体就是赋值操时会隐式的调用拷贝构造,借助临时变量时会发生拷贝时会调用拷贝构造。
返回值优化
返回值优化(Return Value Optimization,RVO)是一种编译器优化技术,它允许编译器在某些情况下避免对临时对象进行拷贝构造或移动构造,直接将函数的返回值放在目标对象的位置,从而节省了额外的拷贝开销,提高程序的性能和效率。
当函数返回一个对象时,它会直接在接收这个返回值的地方创建对象,而不是先在临时对象中创建再拷贝到目标对象中。这样的优化避免了额外的拷贝构造步骤,提高了程序的性能和效率。接下来我们看两个示例。
- 示例1:
#include <iostream>
class MyClass
{
public:
MyClass()
{
std::cout << "Default Constructor" << std::endl;
}
MyClass(const MyClass& other) {
std::cout << "Copy Constructor" << std::endl;
}
};
MyClass someFunction()
{
MyClass obj;
return obj;
}
int main()
{
MyClass x = someFunction();
return 0;
}
分析:
首先,MyClass x = someFunction(); 这一行代码会调用 someFunction() 函数。
然后,在 someFunction() 函数中,先创建一个 MyClass 类型的局部对象 obj,这时会调用 MyClass 的无参构造。
接着,在 return obj; 这一行代码中,obj 对象将从 someFunction() 函数中返回。由于编译器的返回值优化,所以它会直接在 x 对象的位置构造 obj 对象,而不是在临时对象中构造。所以我们不会看到任何拷贝构造函数的输出,即不会调用构造哈数。也就是说编译器直接在 x 的位置构造 obj 对象,从而避免了繁杂的拷贝构造调用。
所以,最终的输出结果为:
Default Constructor
- 示例2:
#include <iostream>
using namespace std;
class myType
{
public:
myType()
{
cout << "my type empty" << endl;
}
myType(int val)
{
cout << "my type one" << endl;
}
myType(const myType& other)
{
cout << "my copy !" << endl;
}
};
int main()
{
myType t1;
myType t2 = myType(t1);
myType* pt = new myType;
return 0;
}分析:
首先,创建t1的时候调用无参构造,这个没有问题。
接着,对于t2的来说,理论上讲,括号右边会调用一次拷贝构造创建一个新的匿名对象,而赋值操作又会调用隐式的拷贝,也就是说理论上讲会调用两次拷贝构造。但实际上由于返回值优化的原因,实际上只会调用一次拷贝构造。
返回值优化大致过程是,t2直接在匿名对象myType(t1) 的位置调用了拷贝构造并创建对象,相当于间接地接替了匿名对象。
而至于pt,也是只会调用一次无参构造,但并不涉及返回值优化。因为pt是一个指针,new一个myType时,默认调用无参构造,然后pt指向new的myType的地址。
所以最终的输出结果为:
my type empty my copy ! my type empty
注意事项:
虽然返回值优化可以避免冗余的拷贝构造,但并不能有效地越过拷贝构造的explicit限制
具体原因如下:
在某些情况下,编译器可能会执行返回值优化,将临时对象直接构造在目标对象的位置上,从而避免了拷贝构造。然而,如果 explicit 限制存在,即使返回值优化可能将对象直接构造在目标对象的位置上,编译器仍然不允许在这种上下文中隐式地使用拷贝构造函数。简而言之,就是即使有返回值优化,在语法上也要避免隐式调用或隐式转换。
对于我们来说,应该将返回值优化视为编译器的优化行为,而不是依赖于该优化来实现特定的语义。因此,应该始终编写具有良好语义的代码,而不是依赖于返回值优化来避免拷贝构造或移动构造。即使没有返回值优化,良好的代码设计也会保证程序的性能和效率。
而且,尽管返回值优化是编译器的优化行为,但它通常不会改变代码的语义。编译器只是在不影响程序行为的前提下,尽可能地提高执行效率。因此,程序员可以专注于编写简洁、易读和语义清晰的代码,而不必过于担心返回值优化的细节。编译器会在适当的情况下自动应用这种优化。
析构函数
析构函数是一种特殊的成员函数,用于在对象的生命周期结束时执行一些清理工作和资源释放操作。C++中使用析构函数,让程序员可以在对象销毁时自动执行必要的清理操作,避免资源泄漏和内存溢出等问题。
析构函数基础
析构函数的命名规则:析构函数的名称是在类名前加上波浪号(~)。例如,如果类名是
MyClass,那么析构函数的名称应该是~MyClass。析构函数没有返回类型:与构造函数类似,析构函数也没有返回类型,包括
void。因为在对象销毁时,不需要返回任何值。自动调用:析构函数是自动调用的,当对象的生命周期结束时(超出其作用域,或者通过
delete关键字释放动态分配的对象),析构函数会被自动调用。默认析构函数:如果在类中没有定义析构函数,编译器会提供一个默认的析构函数。默认析构函数不执行任何特殊操作,但会调用成员对象的析构函数(如果有的话)。
一个类有且只有一个析构函数:与构造函数不同,一个类可以有多个构造函数,但一个类只能有一个析构函数。
析构函数不能重载:与构造函数不同,析构函数只能有一个。
析构函数没有参数:与构造函数不同,构造函数是固定的,不能有参数。
析构函数的作用
-
释放资源:析构函数主要用于释放对象所占用的资源,如动态分配的内存等。这样可以防止资源泄漏,保持程序的健壮性。
-
清理操作:除了资源释放,析构函数还可以执行一些清理操作,如保存数据、更新状态等。这些操作通常用于对象销毁前的准备工作。
为了更好地理解析构函数的作用,我们来看一个简单的示例代码:
#include <iostream>
class Resource {
private:
int* data;
public:
Resource() {
data = new int[100];
std::cout << "Resource created." << std::endl;
}
~Resource() {
delete[] data;
std::cout << "Resource destroyed." << std::endl;
}
};
class MyClass {
private:
Resource* res;
public:
MyClass() {
res = new Resource();
std::cout << "MyClass created." << std::endl;
}
~MyClass() {
delete res;
std::cout << "MyClass destroyed." << std::endl;
}
};
int main() {
{
MyClass obj; // 创建一个 MyClass 对象
} // obj 超出作用域,析构函数自动调用,释放相关资源
return 0;
}
运行上述代码,你会看到以下输出:
Resource created.
MyClass created.
Resource destroyed.
MyClass destroyed.
这个示例展示了析构函数在资源管理方面的作用,确保资源在对象生命周期结束时得到正确释放,避免内存泄漏。同时也演示了析构函数在清理操作方面的用法,可以在对象销毁前执行必要的清理工作。
注意事项
如果无法调用构造函数,那么就无法实例化出对象
构造函数是在对象创建时调用的特殊成员函数,用于初始化对象的状态和数据成员。在 C++ 中,当创建一个对象时(通过声明变量、动态分配内存或者容器中添加元素等方式),都会调用该类的构造函数来完成对象的初始化。
如果没有可用的构造函数(默认构造函数或带参数的构造函数),编译器会报错,因为无法确定对象应该如何进行初始化。换句话说,没有构造函数就无法准确地知道对象的初始状态和必要的准备工作,所以无法创建对象。
如果无法调用析构函数,就无法成功释放对象
在 C++ 中,如果无法调用析构函数,就无法正确地释放对象。析构函数是对象生命周期结束时自动调用的特殊成员函数,用于执行对象的清理工作、释放资源和销毁对象的成员。
当一个对象的生命周期结束时,例如超出作用域、delete 操作或容器销毁时,编译器会自动调用该对象的析构函数,以确保对象被正确清理。如果没有可调用的析构函数,对象所持有的资源也就无法释放,进而也就无法成功地释放对象。
编译器会提供默认的构造和析构
在上面我们知道编译器会自动调用构造和析构,而如果无法成功调用构造函数,我们就无法成功的实例化对象。那么此时就有人要问了,我们平常没有手动写构造函数的时候,实例化对象时,不也是可以正常创建出来吗。这是因为,如果当我们没有手动编写构造函数或析构函数的时候,编译器会给给我们默认生成对应的函数。严格意义上来说,编译器一般会为每个类生成6默认成员函数:
无参构造、拷贝构造、析构函数、=的重载函数、以及2个取地址运算符的重载。
所以可见,如果我们没写的话,对应的构造和析构编译器说会给我们自动生成的。
但要注意以下几点:
- 一旦我们手动实现了构造函数,那么编译器将不再为我们提供对应的默认构造函数。特别地,如果我们手动实现了无参构造或有参构造,那么编译器将不再为我们提供任何普通的构造函数,但还会为我们提供对应的拷贝构造(浅拷贝)。但如果我们手动实现了拷贝构造,那么编译器不但不再为我们提供对应的拷贝构造,而且也不再为我们提供任何普通的构造函数。
- C++中,默认生成的构造函数会自动调用自定义类型成员的构造函数,而对于内置类型的成员,编译器一般不会对其做处理,如果我们没有手动处理的话,一般是给随机值或是报错。其中,任何类型的指针也都是属于内置类型的。所以C++11支持内置类型的成员变量声明时可以给默认值来补坑。
- 相应的,编译器也会给我们提供默认的析构函数,但默认的构造函数也是不会对内置类型做处理,只会调用一些自定义类型成员对应的析构函数。
类内构造与析构的调用顺序
- 构造的调用顺序:先调用类内成员的构造,再调用类自身的构造
在 C++ 中,对象的构造过程确保了成员变量先于对象自身进行构造,这样可以保证成员变量在使用前得到正确的初始化。
当一个类的对象被创建时,首先会为对象分配内存空间。然后,会按照成员变量在类中的声明顺序调用它们的构造函数,确保它们在使用前得到正确的初始化。只有在所有成员变量构造完成后,才会调用对象自身的构造函数,执行对象级别的初始化操作。
这个构造顺序是由 C++ 编译器保证的,开发者无需手动干预。这种顺序确保了对象的成员变量在构造对象时处于合理的状态,使得对象在创建后可以正常工作。
- 析构的调用顺序:先调用类自身的析构,再调用类内成员的析构
当一个对象的生命周期结束时,它的析构函数被调用用于清理资源、释放内存或执行其他必要的清理操作。对象的析构函数在两个阶段进行调用:
对象自身的析构阶段:当一个对象的作用域结束或被显式删除时,会首先调用该对象自身的析构函数。这允许对象执行自身特有的清理操作,例如释放自身持有的资源。
类成员的析构阶段:在对象自身析构函数的执行过程中,会自动调用类成员的析构函数。这是因为对象的析构函数负责调用其所有成员对象的析构函数,确保这些成员对象也能得到正确的清理。
综上所述,析构函数的调用顺序是先调用类自身的析构函数,然后再调用类成员的析构函数。这个顺序确保了对象及其成员在销毁时都能得到适当的清理,帮助我们有效地管理资源和避免潜在的问题。
全缺省构造与无参构造的二义性
当在C++中同时定义了全缺省的构造函数和无参构造函数时,会出现构造函数的二义性问题。这是因为编译器在调用构造函数时无法确定应该使用哪个构造函数所导致。
构造函数的二义性是C++编译器无法解决的歧义情况,因为两个或多个构造函数都满足了调用的条件,这样编译器就无法确定应该调用哪一个构造函数。
所以,为了避免这种问题的出现,我们不要同时定义全缺省构造和无参构造。