引言
闲聊对话系统也很多别名
- 聊天机器人
- Chatbot
- Social Chatbot
- Chit-chat bot
- Conversational AI
- 开放领域对话系统
实现方法
现在闲聊对话系统一般有两种主要的实现方法
- 检索式对话系统
- 生成式对话系统
可以任务闲聊对话系统也是一个函数 y = f ( x ) y=f(x) y=f(x),给定用户输入 x x x,生成系统回复 y y y,那么闲聊对话系统本质是去构建这样一个函数 f f f。
其中用户输入
x
x
x也称为post、input、message、query等;
系统回复
y
y
y一般称为response。
检索式对话系统大体实现方法如下图:

首先它要维护一个对话库,其中包含一些message和response对,即问答对。当新的用户输入进来后,目的是找到和用户输入最相近的一个问答对。然后返回该问答对中的回答(response)。
在具体实现时,为了提升效果会有一些细节,比如会实现两个阶段的pipeline,即粗筛+ 精排。粗筛阶段通过类似字符串匹配的方式缩小要查询的问答对,精排阶段利用更精细的排序模型对缩小的问答对进行更好的排序。最后选择排序结果较好的返回给用户。
粗筛阶段一般比较简单,比如可以用ES来实现,其基于BM25算法来检索。所以大家重点关注精排模型。
检索式对话系统的优点是可控,缺点也是可控。成也萧何败萧何。可控的意义是确保系统不会返回一些非法的信息,缺点是不够创新,来来回回就那几句。
而生成式对话模型就可以解决这个问题。

生成式对话模型尝试建模 p ( y ∣ x ) p(y|x) p(y∣x),常用的模型是seq2seq模型。它的优点是可能生成训练集中没有的语句,缺点是生成结果不可控,很难确保生成的句子是安全合法的。要保证生成的输出符合社会主义核心价值观。
下面我们详细介绍它们的技术演化过程。
检索式对话系统
主要分为两大类,一方面是仅考虑单轮对话,另一方面考虑多轮对话。
单轮检索(单轮回复选择):
- 框架1:基于句子嵌入匹配
- 框架2:基于message-response交互匹配
- 扩展:基于外部知识匹配
多轮检索(上下文-回复匹配/多轮回复选择) - 框架1: 嵌入->匹配
- 框架2:表征->匹配->聚集
单轮回复选择
即只根据用户的一句话去候选库中选择回复。

比如上面这样的场景,假设经过了粗筛后得到上面6种回复,然后模型需要找到与用户post最相关的response。
模型可能会对每个候选回复进行打分,定义一个阈值,低于阈值的我们认为是无效的回复,高于阈值的认为是有效的回复,然后从中选择得分最高的作为response。
那具体如何做这种匹配呢?最简单的方法是使用句子嵌入来做。

首先计算query和response的句嵌入向量,然后基于某个函数来计算这两个句嵌入向量的相似度。即用特征提取函数提取特征,用匹配函数计算相似度。
那么什么样的模型可以作为特征提取器,或者说特征提取函数呢,我们之前了解的CNN、RNN或BERT都可以。它们都可以得到句子向量表示。
那么匹配函数怎么实现?任何可以计算两个向量之间距离的函数(模型)都可以。比如余弦相似度,或用一个全连接网络(首先拼接两个句向量)。
那么下面来看下具体如何实现这个特征提取函器 g g g。

- 首先对于输入,即token序列中的每个token映射成一个词嵌入,不管是基于字符还是基于单词的方式。
- 然后基于某种方法得到句子级嵌入,可以是(元素级)最大/均值池化、经过卷积之后再最大池化、喂给RNN得到最后一个隐藏状态等。
那么匹配函数
f
f
f如何实现。

可以看到,匹配函数需要两个句子向量作为输入,计算这两个句子之间的匹配分数。
可以通过
- 余弦相似度(Cosine)。
- σ ( q T ⋅ W ⋅ r ) \sigma(q^T\cdot W\cdot r) σ(qT⋅W⋅r),这里 q q q是query的向量, r r r是response的向量,中间引入了一个线性变换矩阵 W W W,最后得到一个标量(输入到sigmoid函数)表示得分,称为Bilinear。可以看到这和一种Attention计算方法很类似。
- MLP方式:拼接这两个输入向量,喂给一个多层感知机,让多层感知机只有一个输出。
- Neural Tensor 网络,类似MLP,但更加复杂一点。
下面介绍几个使用上面提到的方式的模型。

来自论文Convolutional Neural Network Architectures for Matching Natural Language Sentences
它用CNN作为特征提取函数,用MLP作为匹配函数。比较简单,我们再看复杂一点的。

来自论文Improved Representation Learning for Question Answer Matching
把LSMT+Attention+Pooling作为模型中的
g
g
g,即特征提取函数。
首先分别用两个BI-LSTM提取query和候选response中每个词的表示,然后比如把query中每个词的表示做池化,利用这个结果去response中每个词的表示上做Attention,即使query和response相互交互,得到更丰富的语句表示。最后计算这两个语句表示向量的余弦距离。
上面这些做法的不足在于,提取特征的时候没有让query和response有足够多的交互,下面是一个解决方法:

主要目的在于试图提取出query和response的混合特征。首先分别得到query和response中每个token的词向量,然后使用交互函数
f
f
f来综合query和response的词向量,进行充分交互(计算相似度)得到一个交互表示矩阵,该矩阵中有query中每个token和response每个token交互的得分。接着通过一个汇聚函数
g
g
g进行压缩得到一个交互向量(卷积/池化操作)。最后通过匹配函数
h
h
h得到匹配得分。
这种套路我们称为框架2,即基于message-response交互匹配。这种方式的好处是query和response会有一个充分的交互机会,期望得到更好的表示。
具体如何选择 f , g , h f,g,h f,g,h呢?比较有空间的只是 f f f和 g g g函数。

主要做法可以分为两类,分别是基于相似度矩阵的做法(similarity matrix-based)和基于注意力的做法(attention-based)。前者是我们上面介绍过的方法;后者的交互变成了一系列的注意力操作,对于q(query)和r(response),把r中的每个token作为注意力计算中的query,与q(作为注意力中的key和value)去计算注意力得分,并加权和得到r中同等数量的向量,然后依次喂给RNN得到定长的表示向量。
可以看到还是用到了RNN,并行度不好。其实整个可以用transformer替换,可以对比下效果。

来自论文Text Matching as Image Recognition
这篇论文是首次提出将文本匹配看成是图片识别思想,即叫query和response的相似度表示成相似度矩阵,然后进行卷积操作,最后计算匹配得分。
我们介绍了两个框架,那它们有什么优缺点呢?
从效果来看:Message response interaction 大于
从效率来看:Sentence embedding 大于 Message response interaction
但在实践中一般先保证效率,如果效率保证的情况下,尽量用效果好的。毕竟用户提了一个问题后期望2-3秒内有响应,而不是等10多秒。
多轮回复选择

比如上图的场景中,考虑上下文"Our English lessons are free"和"What lesson?"等就不行,因为前文中机器人说了在上海有一个drum class,显然是与drum有关且知道是什么课程的。而回复"Yes, please bring your drum"显然机器人是知道了对话历史信息。这种情况下属于多轮回复选择。
但考虑对话上下文有一些挑战
- 层次化的数据结构
- 每句话由一些token组成,每段话由句子组成
- 信息冗余
- 对话过程中很可能出现对于回复选择没用的句子
- 逻辑自洽
- 回复选择中的语句顺序很重要
- token和句子间存在长期依赖
- 需要合适的回复
这些解决方法也可以分为两种framework。
我们先来看第一种framework。

这种框架,或者说这种套路的做法是把对话历史拼成一个长的(输入)序列(context embedding),得到context vector,然后当成单轮回复选择用response vector去进行交互匹配。
这类方法下如何得到context embeding、以及如何生成context vector就很重要。
下面我们来看几个例子。

来自论文 The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems ,作者们收集了Ubuntu论坛中的相关技术问题多轮对话。
同时提出了一个基准模型,用LSTM最后一个隐藏状态作为候选response的向量表示response vector。通过拼接所有对话历史中的句子成一个很长的句子,然后也把这个长句子喂给一个LSTM,也用这个LSTM最后一个时间步的隐藏状态当成整个长句子的向量表示,即context embedding/context vector。最后用Bilinear模型匹配这两个向量。
这篇工作重点是数据集,而不是这个模型,数据集产生的影响远比这个模型要大。

来自论文 Multi-view Response Selection for Human-Computer Conversation
使用了一个层次化的循环神经网络,第一层是词级别的GRU(RNN),把对话历史中的每个句子的所有词向量拼接起来,当成一个输入序列喂给RNN,在RNN得到的输出上做了卷积操作,分别得到对话历史中句子的表示;然后把这些句子的表示向量拼接起来,当成一个输入喂给另一个句子级别的GRU,用最后时间步的隐藏状态当成句子粒度的整个对话历史的表示向量。同时用词级别RNN的最后一个时间步的隐藏状态当成词粒度的对话历史的表示向量。
对于response,也分别用词级别和句子级别的RNN来做。然后分别融合对话历史和response不同级别的表示向量,去做Bilinear匹配。
但现在有了预训练语言模型,我们可以把对话历史拼接成一个长的序列,喂给BERT来得到对话历史的表示向量。
下面我们来看framework 2。

套路2认为套路1的方法有明显的缺点,即response仅仅适合context vector做了交互,在套路1中对对话历史提取出一个表示向量,对response提取出一个表示向量,然后直接做匹配。那么缺点就是在计算对话历史的表示向量时,没有考虑候选的response。
而套路2让候选的response和对话历史中的每句话都产生交互,得到一个交互后的表现向量。融合交互后的结果去计算匹配分数。
我们来看下这个套路对应的哪些出色的模型。

来自论文 Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots ⭐
对于包含
n
n
n句话的对话历史,想计算一个response
r
r
r和它们的匹配分数。
首先把每句话中的词映射成词向量,然后把每个句话的词向量都喂给一个GRU得到每个词更好的词向量表示。接下来做了一个叫做Utterance-Response匹配的事情,实现了我们介绍套路2中的
f
f
f函数。
如何实现的呢?其实我们也见过。就是用response中每个token对应的词向量和对话历史语句中每个token的词向量计算相似分数,得到 n n n个相似矩阵。然后对这 n n n个相似矩阵做卷积,得到 n n n个新的表示向量。这么做的目的就是得到了融合response的对话历史语句表示。
同时作者也设计出来一个multi view。把GRU输入的词向量之间也计算出一个相似矩阵,称为Word Pairs。GRU输出的向量计算出来的称为Segment Pairs。
然后分别进行卷积和池化操作得到 n n n个表示向量。此时用另外一个GRU得到新的表示向量,来计算匹配分数。
这篇文章的思路启发影响了后面的很多人。
基于预训练语言模型
随着BERT的出现,我们如何应用它到检索式对话系统中呢。有一个影响力很大的19年的工作:

来自论文 ConveRT: Efficient and Accurate Conversational Representations from Transformers ⭐
这篇工作提出了两套模型,分别应用于单轮和多轮场景下的对话回复选择。上图是单轮场景下的。
它是一个以效率为优先的双塔模型,计算用户的query和候选的response之间的相似度得分。
具体地,把query和response都喂给共享参数的Transformer,然后用两个不共享参数的前馈网络分别得到query和response的表示向量,最后将它们进行点积。
双塔模型的优点在于可以预先计算出所有response的表示向量并缓存下来,然后来了新的query之后,只需要计算query的表示向量。

多轮场景如上图所示,变成了一个三塔模型,从左到右,分别对应用户当前输入input
x
x
x、候选response
y
y
y、对话历史 input
z
z
z。
这篇工作把对话历史中的最后一句话当成用户当前的输入,把除了最后一句话的其他(有限的)语句当成对话历史。
这样做的好处是体现出了对话历史中的最后一句话的重要性。
得到这三个输入后,喂给Transformer模型,分别得到这三个输入的向量表示,然后让input
x
x
x和input
z
z
z分别与候选response表示
y
y
y计算点积得到匹配得分,同时也对input
x
x
x和input
z
z
z计算了均值,得到
h
x
,
z
h_{x,z}
hx,z,用它和
h
y
h_y
hy计算点积作为最终的匹配得分。
这篇工作取得了当时检索式对话系统的一个SOTA成果。
基于生成式的闲聊对话系统
通常为了生成句子,我们都要建模句子的语言模型
p
(
y
∣
x
)
p(y|x)
p(y∣x),像GPT3这种自回归语言模型取得了非常好的结果。
重点是如何去建模seq2seq模型中的概率分解式。

首先如何建模输入序列
x
x
x的表示,最简单的做法是喂给RNN用最后一个隐藏状态表示这个输入序列;更复杂一点的有对整个RNN时间步的输出做了一个平均或基于注意力的加权平均。

更复杂的就是维护了不同级别的表示,比如有词级别和语句级别的。我们在上面也见过。
但这些做法随着预训练语言模型的出现,都落伍了。
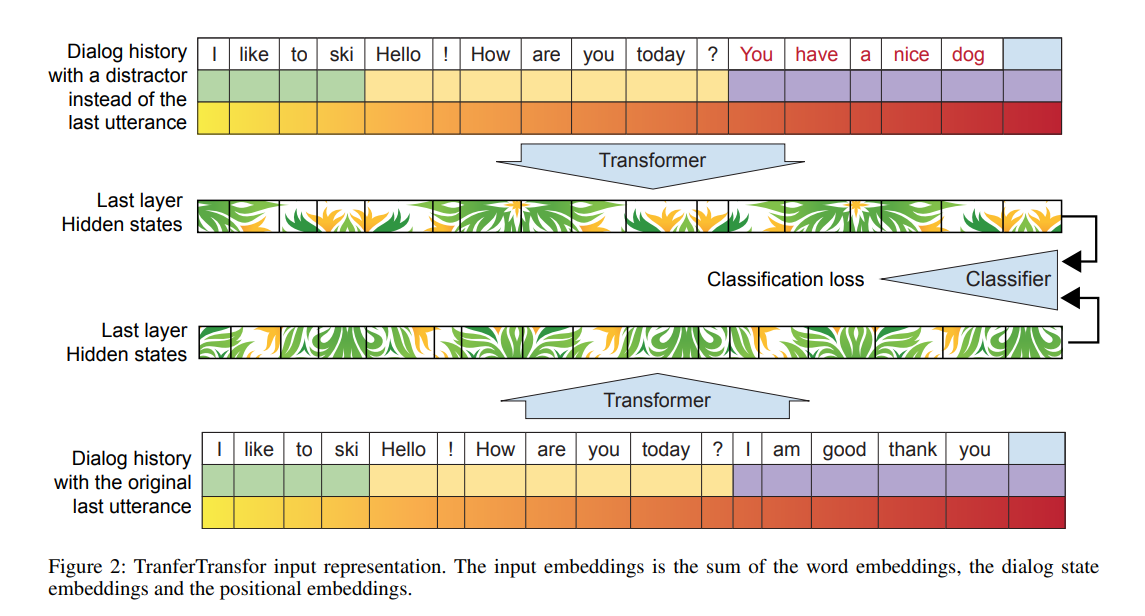
来自论文 TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents ⭐
这篇工作的作者是第一个把预训练语言模型用到对话生成中的,后续几乎类似的工作都follow了作者的做法。
其实想法很简单,把对话生成模型看成语言模型,把所有的对话历史拼接成一个长序列,然后让预训练语言模型去预测句子的下一个token。
参考
- 贪心学院课程
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
- Improved Representation Learning for Question Answer Matching
- Text Matching as Image Recognition
- The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems ⭐
- Multi-view Response Selection for Human-Computer Conversation
- Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots ⭐
- ConveRT: Efficient and Accurate Conversational Representations from Transformers ⭐
- TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents ⭐