我很喜欢关于社交媒体和数据库的创作主意。所以,让我们以一个新的方向来探索:看看Twitch.tv或任何具有即时通讯功能的平台。如果你刚开始接触数据库,可以阅读之前的那篇文章:社交媒体中的“点赞”“喜欢”是如何存储在数据库中的?。
那篇文章记录了我对数据库范式的探索。在过去的几周中,我一直在进行一场名为“ScyllaDB的开发者视角:构建应用程序”的演讲。我的目标是构建一个简单的应用程序,使用一个数据库来处理每秒1k/3k的操作。在这篇文章中,我将分享我所学到的知识。通过阅读本文,初学者开发者应该知道如何使用一个很酷的数据库构建一个消耗大量IOPS的应用程序。
项目:Twitch Sentinel
我决定开始一个涉及大数据导入的Twitch项目,我们称之为Twitch Sentinel。
这个想法很简单:收集来自Twitch.tv上尽可能多频道的所有消息,存储这些数据,并从中获取一些指标。
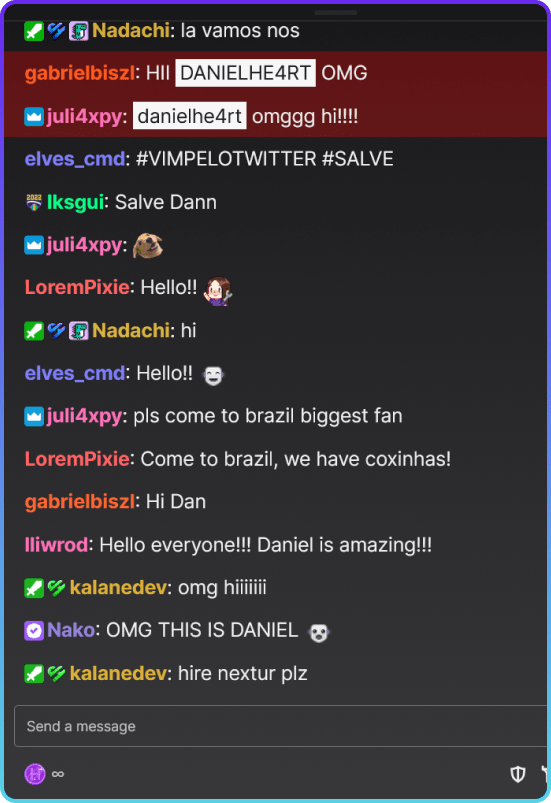
我的Twitch聊天屏幕截图。你能想象每秒存储超过1,000条消息吗?这听起来像是一个很酷的挑战。以下是你可以为你的研究生成的一些指标:
- 特定主播每天收到多少条聊天消息。
- 用户每天发送多少条消息。
- 基于消息推断主播或用户在线的最可能的时间段。
- 每小时消息峰值等等。
但你可能会问:“如果Twitch已经提供了分析面板,为什么我还要创建这个呢?”答案是:毫无用处的概念验证(PoCs),它们会教会你一些新东西!你以前创建过分析仪表板吗?使用过真正快速的数据库吗?思考过新的建模方式吗?如果没有,让我教你我对这个主题的了解!
做出明智的决策
当你开始一个新项目时,你应该知道代码的每一部分和你用来实现项目的工具都将直接影响项目的未来。同时,你选择的数据库也直接影响整个应用程序的性能。现在我们将检查与数据库的快速性和一致性相关的一些属性。
ACID缩写
如果你对数据建模感兴趣,你可能已经听说过ACID。如果没有,ACID是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)的缩写。这些缩写的每个部分构成了关系数据库中的事务。事务是一个单一的操作,告诉你的数据库如果ACID中的任何一个概念失败,你的查询将不会成功。让我们更深入地探讨一下:
- 原子性: 事务中的每个部分都是唯一的,如果其中任何一个部分失败,它将失败并回滚到该数据的原始状态。
- 一致性: 只有在符合特定模型的正确数据形式下,才能接受你的数据,这基于表建模、触发器、约束等。
- 隔离性: 所有事务都是独立的,并不会干扰正在运行的事务。
- 持久性: 如果事务完成,数据将持久保存,即使系统在此之后发生故障。
正如你所见,ACID为所有数据提供了一个有趣的安全保障,但这需要进行一些权衡:维护成本高,因为对于每个事务,你将会锁定(隔离)你的数据。它需要许多节点。如果你的目标是通过更高的吞吐量加快速度,ACID将阻碍你的计划,因为所有这些操作都需要成功。你甚至不能考虑灵活的模式,即“文档”,因为这将违反一致性属性。那么怎么办呢?我们只是用JSON或TXT作为我们的数据库吗?嗯,这并不是件坏事,但让我们用非关系数据库(即NoSQL)来实现。
BASE缩写
当我们转向NoSQL数据库时,可能最重要的事情就是要知道:有不同的范式,每个范式都擅长特定的领域。但在大多数NoSQL数据库范式之间存在一个共同点,即BASE属性。这个缩写代表:基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistency)。现在事情变得有趣了,因为这些属性允许你在数据上进行“较少的验证”,因为你从开发人员的角度保证了数据的完整性。但在谈论这个之前,让我们来了解一下它们的意义:
- 基本可用: 你可以随时读取/写入数据库中的数据,但这并不意味着这些数据是最新的。
- 软状态: 你可以根据需要灵活地调整模式,这成为开发人员的任务,而不是数据库管理员的任务。
- 最终一致性: 所有的数据将在多个数据中心之间同步,直到达到所需的一致性级别。
看起来,BASE属性给我们提供了一个数据库,可以接收任何类型的数据,并尊重数据建模。它始终可用于查询,并且对于高数据插入来说是一个不错的选择。但也有权衡的方面:如果你需要强一致性的数据,可能不是最佳选择。复杂性较高,因为数据库建模被委托给了开发人员。如果你需要在集群中同步节点,数据冲突可能会是一个问题。现在我们对数据库可能具有的一些属性有了更多了解,所以现在是根据我们的项目来做决策的时候了。
做出明智的决策
ACID vs BASE?谁赢了?这取决于项目的类型!通常情况下,你可以在一个项目中使用多个数据库,所以这不是一个问题。但如果你只能选择一个,要明智地选择。明确一下:当你需要具备数据一致性、事务处理,而性能不是关键考虑因素时,应选择ACID。当你对IOPS有更高的需求并且对数据建模有把握时,应选择BASE。对于我们的项目,我们将从Twitch.tv接收大量的消息。我们需要快速存储和处理所有这些消息。因此,当然我们要放弃ACID的“安全保护”,转而采用BASE的“明智处理”xD考虑到这一点,我决定使用CQL和ScyllaDB,因为它可以处理我们每秒接收数百万条消息的想法,并且同时具备一致性和ACID的支持。如果Discord使用ScyllaDB来存储消息,为什么我们不能在Twitch上使用呢?
将我们的想法建模成查询
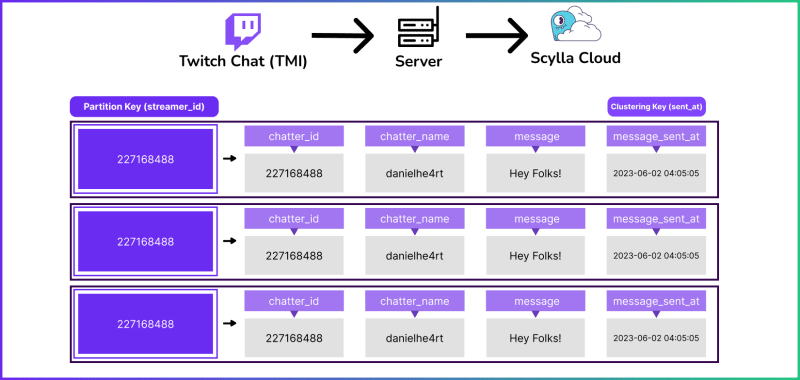 当你使用ScyllaDB时,你的主要关注点应该是你想要运行哪个查询。考虑到这一点,我们需要:
当你使用ScyllaDB时,你的主要关注点应该是你想要运行哪个查询。考虑到这一点,我们需要:
- 存储消息并在必要时进行读取。
- 经常从流列表中进行存储和读取。
- 统计特定流中聊天用户发送的所有消息。
因此,我们的数据建模应该如下所示: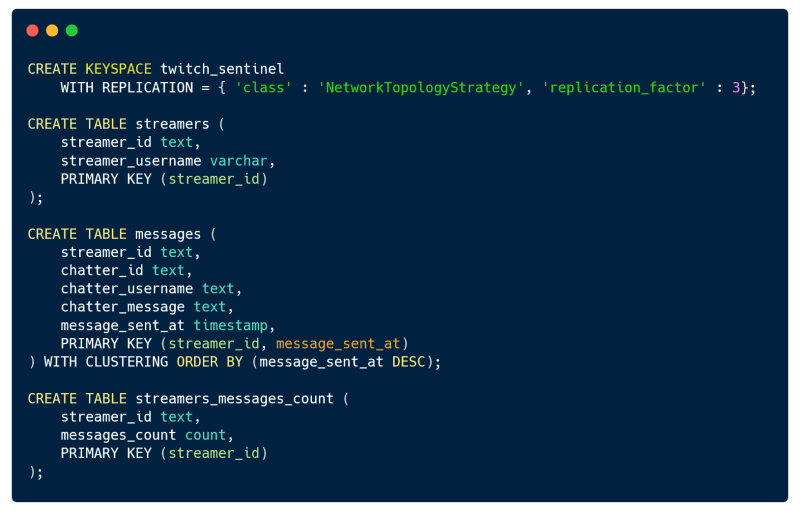 没什么大不了的,这应该很简单。我们需要尽可能快的吞吐量,复杂的查询不能让我们获得这样的性能。以下是我们可以使用从此模型中检索的数据运行的一些查询:
没什么大不了的,这应该很简单。我们需要尽可能快的吞吐量,复杂的查询不能让我们获得这样的性能。以下是我们可以使用从此模型中检索的数据运行的一些查询:
每个用户的消息数量(前5名)
SELECT
chatter_id,
chatter_username,
count(*) AS msg_count
FROM
dev_sentinel.messages
GROUP BY
chatter_id,
chatter_username
ORDER BY
msg_count DESC
LIMIT 5
每个流媒体主播的唯一用户数量
SELECT
streamer_id,
COUNT(DISTINCT chatter_id) AS unique_chatters
FROM
dev_sentinel.messages
GROUP BY
streamer_id
ORDER BY
unique_chatters DESC
给定用户的最早和最近的消息
SELECT
min(sent_at) AS earliest_msg,
max(sent_at) AS latest_msg
FROM
dev_sentinel.messages
WHERE
chatter_username = 'danielhe4rt'
Twitch作为我们的载荷!
好的,现在我们已经对数据库的概念进行了建模,现在我们需要“真实世界”的载荷。我不知道你是否喜欢那些只是为了展示一个毫无意义的巨大数字而模拟所有数据的教程…我个人不喜欢,这也是为什么我想带给你一些真实的内容供你探索。在Twitch的直播平台上,他们有一堆可以与主播聊天互动的API。最著名的是称为’TMI’(Twitch消息接口)的客户端,它可以直接连接到任何你想要的Twitch主播聊天室。这里有一个客户端列表供你参考:
- tmi.js - 适用于NodeJS的接口
- tmi.php - 适用于PHP的接口(可以轻松集成到Laravel中)
- pytmi - 适用于Python的接口
- twitch-irc-rs - 适用于Rust的接口
无论如何,所有这些客户端的思路都是相同的:你需要选择一个频道并连接到它。代码如下所示:
$client = new Client(new ClientOptions([
'connection' => [
'secure' => true,
'reconnect' => true,
'rejoin' => true,
],
'channels' => ['danielhe4rt']
]));
$client->on(MessageEvent::class, function (MessageEvent $e) {
print "{$e->tags['display-name']}: {$e->message}";
});
$client->connect();
每个Twitch负载都有一个名为"tags"的数组,它带有与该特定消息相关的JSON数据:
{
"badge-info": {
"subscriber": "58"
},
"badges": {
"broadcaster": "1",
"subscriber": "3036",
"partner": "1"
},
"client-nonce": "3e00905ed814fb4d846e8b9ba6a9c1da",
"color": "#8A2BE2",
"display-name": "danielhe4rt",
"emotes": null,
"first-msg": false,
"flags": null,
"id": "b40513ae-efed-472b-9863-db34cf0baa98",
"mod": false,
"returning-chatter": false,
"room-id": "227168488",
"subscriber": true,
"tmi-sent-ts": "1686770892358",
"turbo": false,
"user-id": "227168488",
"user-type": null,
"emotes-raw": null,
"badge-info-raw": "subscriber/58",
"badges-raw": "broadcaster/1,subscriber/3036,partner/1",
"username": "danielhe4rt",
"message-type": "chat"
}
在这个负载中,我们只需要以下信息:
- room-id:与特定广播频道相关的标识符。
- user-id:与发送消息的用户相关的标识符。
- tmi-sent-at:消息的时间戳。
在消息接口中,您还将收到一条包含消息的字符串。这是一个简单的项目,但是,试着从中抽象出更多的想法并让我知道!我很乐意帮助您创建更大的项目!
让它发挥作用!
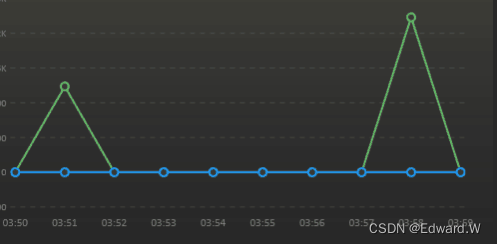
正如我在本文开头所说,我在这个项目中的目标是构建一个高度可扩展的应用程序,使用一个非常酷的数据库来处理我们的需求,即每秒接收大量的负载。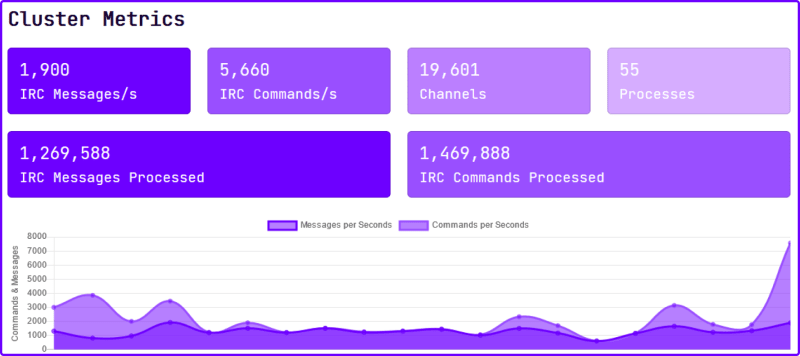 因此,我们连接了 Twitch.tv 上约 20,000 个最受欢迎的聊天室,并获得了平均每秒 1,700 至 2,000 条消息。这意味着我们每小时平均收到 6 百万条消息。您有没有编写过处理如此高数据摄取的代码?在应用程序接收并将所有这些数据发布到 ScyllaDB 的同时,这里是一个 T3-Micro 集群(AWS 上最便宜的实例)的统计信息。
因此,我们连接了 Twitch.tv 上约 20,000 个最受欢迎的聊天室,并获得了平均每秒 1,700 至 2,000 条消息。这意味着我们每小时平均收到 6 百万条消息。您有没有编写过处理如此高数据摄取的代码?在应用程序接收并将所有这些数据发布到 ScyllaDB 的同时,这里是一个 T3-Micro 集群(AWS 上最便宜的实例)的统计信息。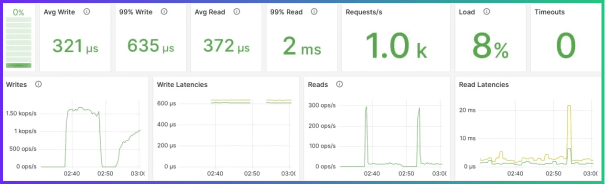 它以毫秒级的 P99 延迟处理每秒 1,000 个请求,就像轻而易举一样。而对于每秒 1,000 个请求,这台轻量级机器的负载仅为 8%,因此如果您愿意,您可以做得更快。大部分情况下,这取决于有多少流媒体主播连接到您的机器人,以及观众每秒发送多少条消息。
它以毫秒级的 P99 延迟处理每秒 1,000 个请求,就像轻而易举一样。而对于每秒 1,000 个请求,这台轻量级机器的负载仅为 8%,因此如果您愿意,您可以做得更快。大部分情况下,这取决于有多少流媒体主播连接到您的机器人,以及观众每秒发送多少条消息。
最后的考虑
这个项目让我深刻认识到选择适合特定任务的正确工具是多么重要。在这种情况下,数据库必须是您在考虑更高规模时会使用的工具。请记住,在一个项目中使用多个数据库是完全可以的。每个数据库都可以解决开发环境中的一般或特定问题。如果有时间,请始终进行适当的研究和尽可能多的工具的 PoC(概念验证)!
更多技术干货请关注公号“云原生数据库”
squids.cn,目前可体验全网zui低价云数据库RDS,免费的数据库迁移工具DBMotion、备份工具、SQL开发工具等