论文标题:
ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels
论文链接:
https://www.xueshufan.com/publication/3042807565
代码链接:
https://github.com/angus924/rocket
发表年份:2020
摘要
大多数时间序列分类方法都具有很高的计算复杂度,即使对于较小的数据集也需要大量的训练时间,而对于较大的数据集则难以处理。此外,许多现有的方法专注于单一类型的特征,如形状或频率。基于卷积神经网络在时间序列分类方面的近期成功,我们展示了使用随机卷积核的简单线性分类器以现有方法的一小部分计算开销实现了最先进的精确度。使用这种方法,可以在
<
,
2
,
h
b
o
x
h
<,2,hbox {h}
<,2,hboxh
的UCR存档中的所有85个’ bake off '数据集上训练和测试分类器,并且可以在大约1小时内对超过100万个时间序列的大型数据集训练分类器。
介绍
与典型卷积神经网络中使用的学习卷积核相比,我们表明,生成大量随机卷积核是有效的,这些随机卷积核结合起来捕获与时间序列分类相关的特征(尽管单独地,单个随机卷积核可能只能非常近似地捕获给定时间序列中的相关特征)。
方法
Rocket使用大量随机卷积核转换时间序列,即具有随机长度、权重、偏差、膨胀和填充的核。利用变换后的特征训练线性分类器。Rocket和逻辑回归的组合实际上形成了一个具有随机核权的单层卷积神经网络,其中转换的特征形成了训练过的softmax层的输入。然而,在实践中,除了最大的数据集,我们使用的是岭回归分类器,它具有快速交叉验证正则化超参数(而不是其他超参数)的优点。
尽管如此,由于使用随机梯度下降训练的逻辑回归对于非常大的数据集更具有可伸缩性,当训练示例的数量远远大于特征的数量时,我们使用逻辑回归。rocket与典型卷积神经网络中使用的卷积层以及之前使用时间序列卷积核(包括随机核)的工作有四个区别:
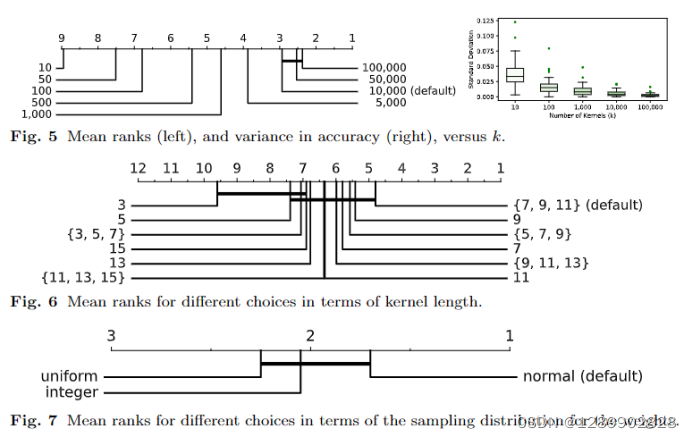
1.rocket使用了大量的核。由于只有一个“层”的核,并且不学习核的权值,计算卷积的计算成本很低,并且可以用相对较少的计算成本使用非常多的核。
2.rocket使用大量不同的核。与典型的卷积网络(通常是一组内核共享相同的大小、扩张和填充)不同,每个Rocket的核具有随机的长度、扩张和填充,以及随机的权重和偏差。
3.特别是,Rocket利用了核的dialtion的关键功能。与卷积神经网络中典型的dilation使用相反,在卷积神经网络中,膨胀随深度呈指数增长(e.g.,Yu and Koltun 2016;Bai et al. 2018;Franceschiet al. 2019),我们对每个核膨胀系数随机采样,产生各种各样的核,捕捉不同频率和尺度下的模式,这对方法的性能至关重要。
4.除了使用结果特征映射的最大值(广义地说,类似于全局最大池),Rocket还使用了一个额外的新特征:正数值的比例。这使得分类器能够衡量给定模式在时间序列中的流行程度。这是Rocket结构对其卓越的准确性最关键的单一元素。
实验
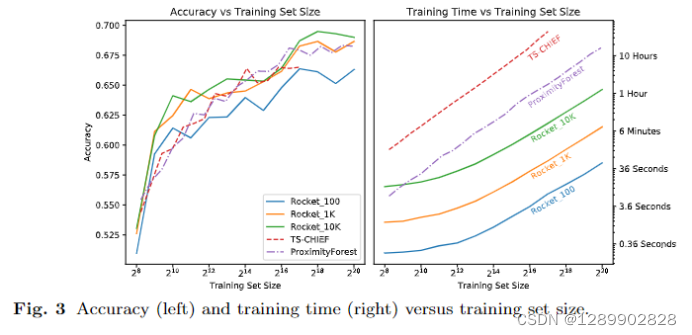
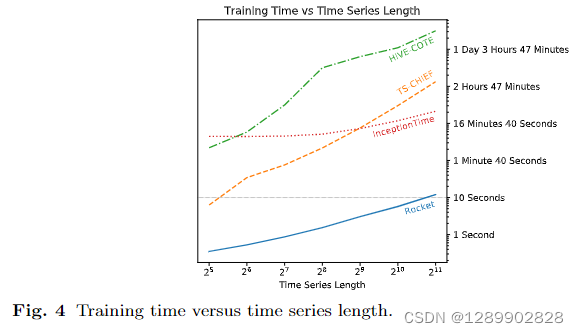
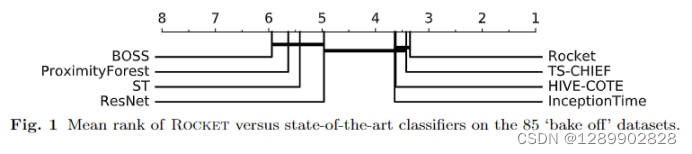
速度有数量级上的提升。
总结
Rocket关键使用了正数值的比例(ppv)来总结特征图的输出,允许分类器在给定的时间序列中对模式的流行程度进行加权。据我们所知,ppv以前从未以这种方式使用过。我们发现,这比传统最大池化操作中应用的简单最大值要有效得多。可以相信ppv对其他数据类型(如图像)也同样有效。



![[附源码]计算机毕业设计基于SpringBt的演唱会购票系统论文2022Springboot程序](https://img-blog.csdnimg.cn/8a5ef33fbddb477ebbea397c9fa327c9.png)

![[附源码]Python计算机毕业设计SSM基于框架的旅游订票系统(程序+LW)](https://img-blog.csdnimg.cn/4bd710d325f3419282fffdd21cdfb466.png)