有时候我们是攻击方,发送被网站或微信屏蔽的敏感图像,分享瓜时剔除可能暴露的个人信息,在平台分享其他平台的购物记录
有时候我们是防守方,判断他人给的图有没有造假嫌疑,判断是不是网图盗图
调研了图像造假的判别方案,在cv领域,这不是一个热门的研究方向(时间点2023.07),以下方法也只能通过pipeline的方法筛选出一部分有问题的影像,而不能实现高召回。但随着AIGC的发展,这一领域有望得到更高关注。
造假方法
下图分别是 拼接(splicing),复制移动 (copy-move) 和擦除填充 (removal)3种造假方法下的真实图像、被篡改的图像、篡改mask。
其他攻击方法:
马赛克、压缩、涂抹(抹色、马赛克)、剪裁、截图、缩放、摄屏、高斯等模糊、社交工具传输。。。

基于图像属性的篡改辨别方法
基于Exif
-
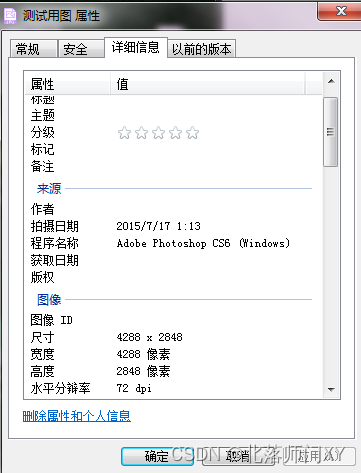
图片属性中包含Photoshop
from PIL import Image, ExifTags
for k,v in ExifTags.TAGS.items():
print(k,v)
im = Image.open('1.jpg')
print(im._getexif())
print 输出如下
...
297 PageNumber
301 TransferFunction
305 Software
306 DateTime
315 Artist
...
{305: 'Adobe Photoshop CS6 (Windows)', 274: 1, 306: '2015:07:27 23:14:35', 296: 2, 34665: 164, 282: (720000, 10000), 283: (720000, 10000), 40961: 1, 40962: 4288, 40963: 2848}
# 305代表Software,这里可以查询到测试图片是PS输出的在生产数据上实验了一下,24.6万生产数据,查获3张有ps软件痕迹,但肉眼无法辨别修改了何处
-
以文本形式打开后包含Adobe、Photoshop
分析图像的元数据
8BIMRoll 8BIM? mfri 8BIM ?nhttp://ns.adobe.com/xap/1.0/ <?xpacket begin="锘? id="W5M0MpCehiHzreSzNTczkc9d"?> <x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27 "> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <rdf:Description rdf:about="" xmlns:xmp="http://ns.adobe.com/xap/1.0/" xmlns:photoshop="http://ns.adobe.com/photoshop/1.0/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xmpMM="http://ns.adobe.com/xap/1.0/mm/" xmlns:stEvt="http://ns.adobe.com/xap/1.0/sType/ResourceEvent#" xmlns:stRef="http://ns.adobe.com/xap/1.0/sType/ResourceRef#" xmp:CreatorTool="Adobe Photoshop CS6 (Windows)" xmp:CreateDate="2015-07-17T01:13:20+08:00" xmp:MetadataDate="2015-07-27T23:14:35+08:00" xmp:ModifyDate="2015-07-27T23:14:35+08:00" photoshop:ColorMode="3" photoshop:ICCProfile="sRGB IEC61966-2.1" dc:format="image/jpeg" xmpMM:InstanceID="xmp.iid:30F8DD307234E511B70284B06955DBF7" xmpMM:DocumentID="xmp.did:9D133752D32BE51198FE9C8FB23C9B23" xmpMM:OriginalDocumentID="xmp.did:45BE21CCDC2BE51198FE9C8FB23C9B23"> <photoshop:DocumentAncestors> <rdf:Bag> <rdf:li>254F3628FF464B1FDE38249322C255F7</rdf:li> <rdf:li>C7552FC0D2A6B529F0D230FBB690F91D</rdf:li> <rdf:li>DDDB579B9673E92F5C2E344218B20707</rdf:li> </rdf:Bag> </photoshop:DocumentAncestors> <xmpMM:History> <rdf:Seq> <rdf:li stEvt:action="created" stEvt:instanceID="xmp.iid:45BE21CCDC2BE51198FE9C8FB23C9B23" stEvt:when="2015-07-17T01:13:20+08:00" stEvt:softwareAgent="Adobe Photoshop CS6 (Windows)"/> <rdf:li stEvt:action="saved" stEvt:instanceID="xmp.iid:2FF8DD307234E511B70284B06955DBF7" stEvt:when="2015-07-27T23:14:35+08:00" stEvt:softwareAgent="Adobe Photoshop CS6 (Windows)" stEvt:changed="/"/> <rdf:li stEvt:action="converted" stEvt:parameters="from application/vnd.adobe.photoshop to image/jpeg"/> <rdf:li stEvt:action="derived" stEvt:parameters="converted from application/vnd.adobe.photoshop to image/jpeg"/> <rdf:li stEvt:action="saved" stEvt:instanceID="xmp.iid:30F8DD307234E511B70284B06955DBF7" stEvt:when="2015-07-27T23:14:35+08:00" stEvt:softwareAgent="Adobe Photoshop CS6 (Windows)" stEvt:changed="/"/> </rdf:Seq> </xmpMM:History> <xmpMM:DerivedFrom stRef:instanceID="xmp.iid:2FF8DD307234E511B70284B06955DBF7" stRef:documentID="xmp.did:9D133752D32BE51198FE9C8FB23C9B23" stRef:originalDocumentID="xmp.did:45BE21CCDC2BE51198FE9C8FB23C9B23"/> </rdf:Description> </rdf:RDF> </x:xmpmeta> -
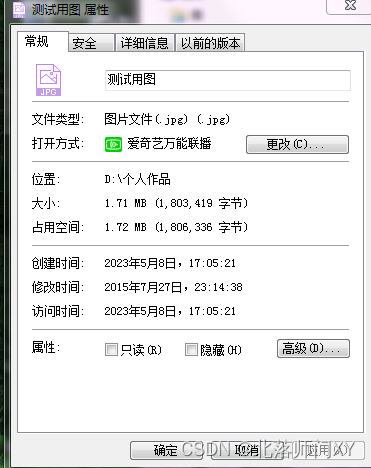
创建时间与访问时间不一致
注:重命名、复制也可能导致时间不一致
-
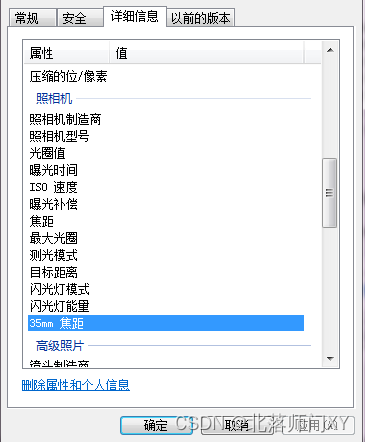
没有照相机的信息
正常的图片和ps后的图片对比如下

-
同个人的图片有多个不同的尺寸
理论上是同个人用同一设备拍摄的,各图像之间具有相似性。某些场景中是有手机下载电子文件或手机截屏,这种需要另外判断。
基于图像内容的其他篡改辨别方法
透视
多个人眼的高光应一致
阴影、光源、光线角度
相机的噪点分布
物体边缘的细腻程度
RGB颜色值的变化关系
手工设计的图像内在特征统计
错误级别分析/误差分析 (Error Level Analysis,ELA)
背景介绍:
图像有损压缩:
cv2.imwrite(new_im_path,img, [cv2.IMWRITE_JPEG_QUALITY, quality]) # 第三个参数不传默认quality=95,已经通过hashlib验证,获取了相同的摘要
图片有损格式包括JPEG2000,JBIG,JPEG格式等。“有损文件格式不能保证颜色保持不变。对于JPEG,保存需要指定质量级别。质量级别会调整压缩量(较低的质量会创建较小的文件),但是会通过删除一些颜色信息进行压缩。使用JPEG,保存图片会使颜色略有变化。重新保存的文件在视觉上可能看起来与源图片相同,但是确切的像素值将有所不同。对于有损图片格式,第一次保存图像会导致大量的色彩损失。但是,加载图片,然后再次以相同的有损格式对其进行编码,将导致较少的其他颜色下降。ELA结果突出显示了图像在重新保存期间最容易出现颜色劣化的区域。”
JPEG压缩和8*8的关系:
JPEG压缩图像的第一步,是将图像分解成一个个8×8的小图像,之后再分别对这些小图像进行变换量化编码。
[Week2.3]JPEG采用8×8分块处理 – 肥叉烧 feichashao.com
JPEG不是按像素点来存储图片的,而是通过波的叠加。
JPEG的算法的核心就是通过在图片的频率空间(frequency domain)减少不重要信息(特别是高频信息)来实现的。
同一张图,同样的宽度和高度,如何分辨图片质量? - 知乎
ELA:
ELA是一种针对JPEG压缩图像的分析方法,对无损的PNG、图片色彩减少到256色以下(转换为GIF图)、已经多次压缩后的图 等不是很适用。通过检测特定压缩比率重新绘制图片后造成的误差分布, ELA分析的是压缩的变化,原始图片整个图像应处于大致相同的压缩级别。对纯色显示的是黑色,纹理及边缘是亮色,分析ELA中亮度与其周围因素不和谐的部分,推断图像篡改处。
JPEG算法在8x8像素网格上运行。每个8x8正方形均独立压缩。如果图像完全未修改,则所有8x8正方形都应具有相似的潜在错误。如果对图像进行了修改,则修改所触及的每个8x8正方形应比图像其余部分具有更高的潜在错误。
链接示例中,首先获取了原始数码照片的ela值,重新保存后获取的ela值更低(更暗),此时ela都较低,此时,复制了书籍并加恐龙,获得的ela值在编辑处偏高(偏亮)。ela值反映的是高频信息量。
图片防伪ELA检测--png与jpeg_python ela检测_最小森林的博客-CSDN博客
ELA--学习笔记_ela错误级别分析_Wsyoneself的博客-CSDN博客
GitHub - qumuase/ELA: ELA 全称:Error Level Analysis ,汉译为“错误级别分析”或者叫“误差分析”。通过检测特定压缩比率重新绘制图像后造成的误差分布,可用于识别JPEG图像的压缩。
ELA的缺陷也很明显,它只能作为一种分析工具,还是有很多方法可以绕开,比如:多次压缩;将低质量的部分copy到高质量图片中,ela分析就是暗色;PNG等非压缩文件。。。在《图片防伪ELA检测--png与jpeg》最后也有对这部分的分析
下例将原图和压缩到90质量的图像计算差异,显示ELA图像
代码来源:ELA图像处理-图像篡改_ela 图像处理_herr_kun的博客-CSDN博客
from PIL import Image,ImageChops,ImageEnhance
from matplotlib.pyplot importplt
filename='1.jpg'
resaved_filename = filename.replace('.jpg','_90.jpg')
# 使用 PIL 模块进行处理
im = Image.open(filename).convert('RGB')
im.save(resaved_filename, 'JPEG', quality=90)
# 以固定的质量进行保存,quality=100表示完全和原图像一样,这里以90质量压缩
resaved_im = Image.open(resaved_filename)
ela_im = ImageChops.difference(im, resaved_im) #PIL.Image.Image对象,RGB图像
# 逐像素获得两张图像像素点差值的绝对值
extrema = ela_im.getextrema() # ((0,16),(0,10),(0,14))
# 分别获得三个通道的最大最小值,返回三个tuple
max_diff = max([ex[1] for ex in extrema]) # 15
if max_diff == 0:
max_diff = 1
scale = 255.0 / max_diff # 计算变亮尺度,拉到255
# 将图像进行变亮操作,变亮的程度由scale决定
ela_im = ImageEnhance.Brightness(ela_im).enhance(scale)
plt.imshow(ela_im)
plt.show()
上面的代码和《A Picture’s Worth 》的核心代码一致,以下链接标题为《Fake Image Detection with ELA and CNN》,cnn是用keras写的,内容是将图像通过ELA进行convert_to_ela_image,再通过CNN进行二分类model.add(Dense(2, activation = "softmax"))
https://github.com/agusgun/FakeImageDetector/blob/master/fake-image-detection.ipynb
copy-move的增强方案
Python-opencv: 自动制作copymove数据集_opencv制作数据集_shancx的博客-CSDN博客
水印(防守)与去水印(篡改攻击)
背景介绍:
阿里内网秒杀月饼,写脚本误秒杀124盒月饼,自首后2h内4人被解雇。后续发现另有一个P8秒杀了9盒被解雇。内网截图者也被解雇。

揭秘阿里巴巴抢月饼事情的全过程 - 简书https://www.zhihu.com/question/50677827?sort=created揭秘阿里巴巴抢月饼事情的全过程 - 简书
添加水印-名字和工号作为Logo的可见水印
例如我司,有可见的彩色水印,截图一次颜色加强一次,满一定次数就要走签报
添加水印-用接近底色的色彩作为不可见水印
下例中,淘宝后台在“访问和支付曲线”页面用接近白色的颜色显示商家的二维码。在PS中查看色阶的较高列即可查看对应色彩。



在我司实验了一下,在邮箱页面截取一张547*90的纯白色图片,值确实都是255,未发现高透明度的水印。
import cv2
im_path = 'back.png'
img = cv2.imread(im_path)
for i in img:
for j in i:
if (j !=255).any(): # j=np.array([255,255,255]),所以这里是False
print('异常色', j)“月饼事件”里阿里巴巴内网肉眼不可见的水印的原理原来是这样的-逍遥峡谷 “月饼事件”里阿里巴巴内网肉眼不可见的水印的原理原来是这样的-逍遥峡谷
“月饼事件”里阿里巴巴内网肉眼不可见的水印的原理原来是这样的-逍遥峡谷
添加水印-工号二进制
用./组成二进制作为隐形工号,较隐蔽。也可以在背景中加几个像素点
也可以对每个字的颜色进行编码
添加水印-频域手段在图片上增加数字盲水印(数字水印)
阿里巴巴公司根据截图查到泄露信息的具体员工的技术是什么? - 知乎
摘取其中一部分介绍,链接里还有各种攻击实验,值得一看。
水印可分为空域方法和频域方法,频域方法简单来说就是通过傅里叶变换等方法转化到频域空间,添加水印信息,这里可以选择频段,再转回空域,水印相当于是加了一层噪声。
空域:
我们日常所见的图像就是空域。空域添加数字水印的方法是在空间域直接对图像操作(之所以说的这么绕,是因为不仅仅原图是空域,原图的差分等等也是空域),比如将水印直接叠加在图像上。
频域:
我们常说一个音有多高,这个音高是指频率;同样,图像灰度变化强烈的情况,也可以视为图像的频率。频域添加数字水印的方法,是指通过某种变换手段(傅里叶变换,离散余弦变换,小波变换等)将图像变换到频域(小波域),在频域对图像添加水印,再通过逆变换,将图像转换为空间域。相对于空域手段,频域手段隐匿性更强,抗攻击性更高。
攻击
所谓对水印的攻击,是指破坏水印,包括涂抹,剪切,放缩,旋转,压缩,加噪,滤波等。数字盲水印不仅仅要敏捷性高(不被人抓到),也要防御性强(抗打)。数字盲水印的隐匿性和鲁棒性是互斥的。越抗攻击的水印越会影响图像的显示。
添加水印-其他锁定截图者方法
手机端截图监听,获得截图的时间、界面
基于评论数、热度等随时间变化的数据,确定大致时间段,筛选对应的访问账号
段落间距
排版
————————————————————————
去水印-摄屏
公认防数字水印比较强的方法是拍摄电子屏幕,可利用摩尔纹等引入噪声掩盖数字盲水印,但也有针对这方面的研究,并不是万全之策。比如工号二进制,调调对比度还是可能锁定。
去水印-数转模转数
拍摄-打印-复印-拍摄-压缩
去水印-网页端去审查元素CSS
去掉background-image
去水印-二值化
基于深度学习的篡改辨别方法
分类:按照是否篡改或具体篡改类型
检测:
分割:
软件或网页的篡改辨别方法
合合信息PS检测
检测证件、票据、单据、商业文档(比如合同、档案、报告等)的图像是否被PS篡改过。识别出图像中的擦除、拼接、复制移动的痕迹。以判断图片是否被篡改,还能定位修改区域,以热力图形式展示图片的PS区域篡改置信度
TextIn - 在线免费体验中心 - PS检测
JPEGsnoop
关注DQT 和 EXIF 判断。免费开源网页,开源c++代码。检测结果为4个等级:Class 1 表明可以确定照片被修改过,Class 2 表明照片极可能被修改过,Class 3 表明照片极可能是原图,Class 4 表明 JPEGsnoop 无法匹配到原图特征,所以不能准确判断。
这个工具除了输出4个等级外,还有exif、quality(基于DQT表计算)、DQT表(Define Quantization Table ,量化表)等信息,具体请查看下面的链接
https://jingyan.baidu.com/article/37bce2be53f88f1002f3a212.html
https://github.com/ImpulseAdventure/JPEGsnoop
Forensically
功能 “Error Level Analysis”、 “Clone Detection ”、“JPEG Analysis”可以查看图像质量、“”
https://29a.ch/photo-forensics/

FotoForensics
http://fotoforensics.com/
MagicEXIF 图像校验器
关注图像的原始性及完整性,进行5级校验,


天池大赛
2021 伪造图像的对抗攻击
伪造图像的对抗攻击,从天池大赛说起_OpenCV中文网公众号的博客-CSDN博客
https://tianchi.aliyun.com/competition/entrance/531812/customize232
安全AI挑战者计划第五期:TOP8伪造图像对抗攻击_天池技术圈-阿里云天池
方案:
【长期赛】安全AI挑战者计划第五期:伪造图像的对抗攻击_学习赛_相关的问题_天池大赛-阿里云天池
比赛介绍
针对营业执照等10类证书文档类图像进行P图攻击,限定5个篡改区域、篡改面积、篡改前后文字数量一致、不可裁减、分辨率一致。
分成攻击和防守2个赛道,攻击赛道先开始,需要选手提供高质量的P图骗过阿里方的4个经典检测模型,包括1个白盒模型—Error Level Analysis (ELA)和另外3个未知的黑盒模型。
赛道1(攻击),任务是通过对原始图像的特定候选区域进行伪造篡改(P图),做到视觉无伪造痕迹,并且让我们提供的图像取证模型无法识别篡改。最后的得分是所提交20张图像的4个得分的总和,每张图像分数为120分,总分2400分。
赛道2——检测比赛,查找篡改区域。篡改图像可能包括如splicing(拼接)、copy-move、object removal(删除)等任意操作,部分进行后处理(JPEG压缩、重采样、裁剪边缘等)。长期赛训练数据为2005张,测试数据为4000张图像,线上得分是选手提交的4000张mask的F1和IOU两个得分的总和,每张图像分数为2分,总分8000分。正式比赛时是1000张2000分。
最后赛道1最高2079/2400分,赛道2最高1512/2000分
“参赛者从10个类别中各任意选择2张进行伪造篡改,最终需要提交20张篡改图像即可。给定参赛者的数据时,同一张图像额外给定一张标定篡改位置信息的图像。篡改操作不限定(如splicing、copy-move、object removal等任意操作),允许进行后处理(如高斯模糊,JPEG压缩等)。并且不需要考虑图像的元数据。
本次比赛的检测模型有两个黑盒模型和一个ELA模型
参赛选手在每个提供的图像上都可以对选择图像的候选5个区域进行伪造篡改。其中对P图的方式和后处理方式没有任何限制,但是会要求篡改痕迹尽量肉眼不可见。
选手得分由四部分构成:未检出篡改的比例、候选区域内篡改像素比例、候选区域外像素变化的比例、篡改区域背景一致性。
在进行评估时,需要使用原始图像减去修改后的图像,得到修改量,然后分别计算候选区域外未修改得分和区域内的修改得分,同时计算篡改区域背景一致性得分,图像在4个检测模型的检测得分。
候选区域外像素变化越小,得分越高;候选区域内,改动的差异越大,的得分越高;篡改区域背景一致性越高,的得分越高;候选区域内修改内容越难被检测,得分越高。
”
赛道2 rank1
赛道2 rank1分享——你知道PS有几种解法吗_天池技术圈-阿里云天池
当成分割来做,找了4个方法获得概率图,原图+4个概率图获得5个特征空间的表示,训练5个分割模型,用交集的方式融合mask。因为作者的模型假阳较高,像素被每个模型击中才认为是篡改过。利用ELA, DCT, MantraNet和Noiseprint四种算法分别提取每个数据的篡改概率图,再对原图和每一个概率图都训练一个BiseNet分割模型,然后融合5个分割模型的结果。
选手自研的autops:
基于赛道1的图片生成赛道2的图片,做数据扩充。方案是文本检测模型,对检测到的文本行remove或remove后缩放还原回去。
马赛克检测:
(GitHub - summer4an/mosaic_detector: mosaic detector in picture.)
同源比对:
不同篡改图片来自同一张种子图片,相互比对确认修改点。分为1高度同源,同一张图上PS;2中度同源,有resize操作;3轻度同源,同一个物体的不同拍摄角度,用sift进行了对齐。
用于融合的N个概率图方案:
1.Mantranet
Mantranet是一个使用了385种篡改类型进行异常检测的自监督学习网络,其特色是将篡改定位问题当做一个局部异常点检测问题。
2.Noiseprint
每一个独立的设备对其所有照片上留有一个独特的模式,也就是光响应不均匀性(PRNU,Photo Response Non-Uniformity)。这是由于设备加工过程中的缺陷导致的。由于PRNU的唯一性和稳定性,其被用于设备指纹(device fingerprint),并被用于图片伪造检测任务中。
3.DCT
离散余弦变换(DCT for Discrete Cosine Transform)常用于数据的有损数据压缩,大名鼎鼎的图片格式JPEG就采用了DCT算法。利用DCT算法多次压缩之后出现的double quantization特性,可以分辨jpeg图片的篡改痕迹。
4.ELA
2022 真实场景篡改图像检测挑战赛
本赛事作为去年阿里安全挑战者计划第五期“伪造图像的对抗攻击”的赛道2的升级版,天池方提供了4k训练数据和4k测试数据。需对测试图像集里面的4000张图像进行篡改定位检测,赛道2 长期赛的测试数据也是4k张。这次比赛还关注了截屏图像。
评价依据为mask的F1值与IOU,3000张图,每张图像分数为2分,总分6000分,初赛最高分为3256/6000分
真实场景篡改图像检测挑战赛_算法大赛_赛题与数据_天池大赛-阿里云天池
复赛 rank1
方案(论坛里当前只看到了这一个):
真实场景篡改图像检测挑战赛方案展示(复赛第一)_天池技术圈-阿里云天池
可以从paddle下载数据集
【PaddleSeg】【天池大赛】真实场景篡改图像检测挑战赛线上2391分_ - 飞桨AI Studio
把它当成了一个分割问题,基于mmsegmentation,代码开源了。也是多模型融合的方案,而且没有用ELA这种传统鉴伪方法,而是用3个深度学习模型融合。作者还在正负样本平衡(特殊loss)、小目标(大尺度放大)、数据扩充(爬虫、伪标签、复用2021比赛数据)上做了努力,详见链接。
需要关注的是初赛第1是复赛第8,初赛第3是复赛第2,初赛第12是复赛第1。
“采用多种类型模型(CNN+Transformer)相融合的方式,提升不同表征形式对于不同特征的互补性。CNN 部分编码器采用目前 SOTA 的 ConvNeXt[3]模型,解码器采用金字塔结构UPerNet[4];Transformer部分编码器采用目前SOTA的Swin-Transformer[5]模型,解码器采用 UPerNet。同时为了增加解码器差异性,还额外增加了 SegFormer[6]模型。三模型结果融合,获取高置信度伪标签,多轮迭代优化,提升模型的识别性能。”
落地问题
PS篡改可分为通用型、文字型。通用型准确率会高一点,推测是因为目标较大,比如P个人。而文字型目标较小,难度更高。通用型通过率可以做到99%,召回率70~80%;文字型通过率80%情况下,召回率可能也只在70~80%。
如果只用exif来做,检出率1/10w极低,而且很难判断篡改点
推荐阅读:
“万物皆可修图”?合合信息“PS篡改检测”让反诈精确到“像素级” - 知乎
评论:“在身份证检测场景中,篡改检测准确率超99%”利用多尺度特征图检测明显ps过的位置
阿里巴巴公司根据截图查到泄露信息的具体员工的技术是什么? - 知乎
评论:介绍了很多添加盲水印的方法
有没有技术可以判断一张图片是否被PS过? - 知乎
评论:介绍了基于经验或其他传统方法的检测技术
检验图片有没有被 P 过_p过的图再截图能检测出来吗_Hern(宋兆恒)的博客-CSDN博客
评论:介绍了 JPEGsnoop 、Forensically