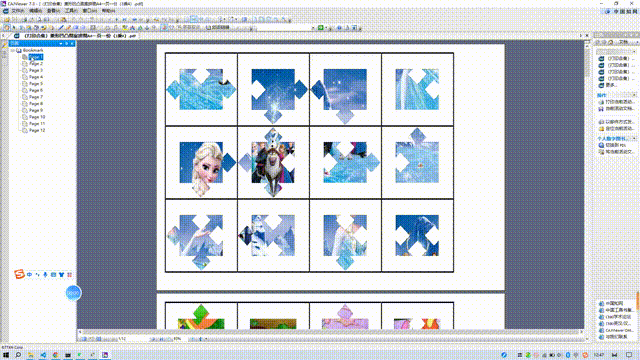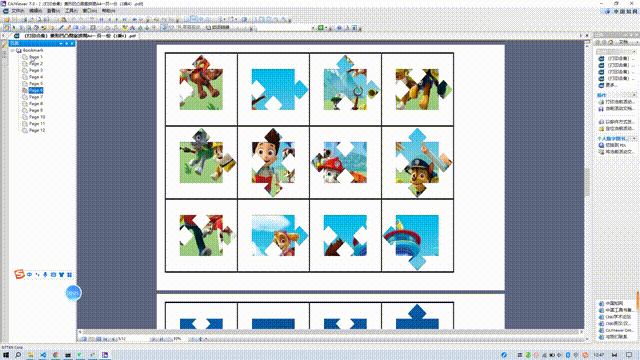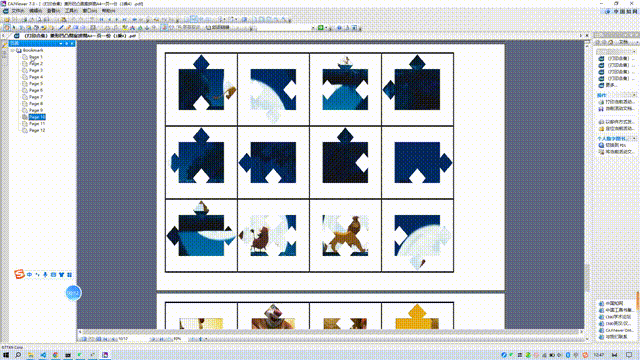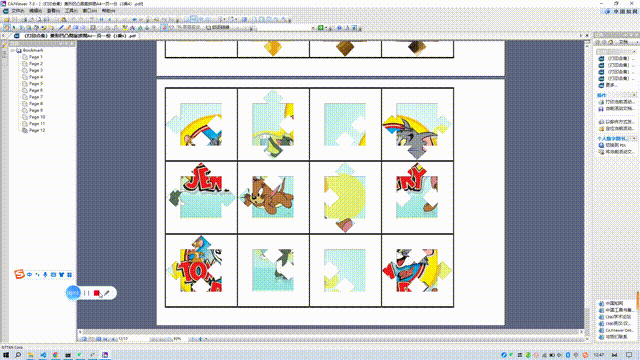
作品展示:

 背景需求
背景需求
我尝试将拼图的“圆形凹凸角”变成"正方形凹凸角”,没有成功,但做出了“菱形凹凸角”。
实用性思考:
1、这种菱形凹凸角与正方形结构近似,裁剪难度中等(比圆角容易剪)
2、但是它同样要对细节进行精剪,不适合集体教学(操作时间长)。
3、但可以适当打印几份,放在个别化美工区里做分层差异的学具。
'''
目的:3*4彩色拼图(有菱形凹凸)
作者:阿夏
时间:2023年7月25日 15:43
'''
import os
# yangshi=float(input('输入造型数字:凹凸基础0.5(链边太细);凹凸最适宜0.56;纯方块:7\n'))
# pic_width=int(input('请输入底边像素(1024)\n'))# 长度 把MB图片缩小一点,生成的拼图块格式也小一点1024
# pic_height=int(input('请输入侧边像素(768)\n'))# 宽度768
Number=12
# int(input('多少块3*4(12块)\n'))# 宽度768
# pic_puzzle_longnum=int(input('请输入侧边的积木块数量(3)\n'))# 积木块数量4*6=12块 中的4 768
# pic_puzzle_shortnum=int(input('请输入底边的积木块数量(4)\n'))# 积木块数量4*6=12块 中的6 1024
# pic_puzzle_side_long=float(input('请输入word里面积木块图片的长度\n'))# 小拼图块的长度 1.5正方形
# pic_puzzle_side_short=float(input('请输入word里面积木块图片的宽度\n'))# 小拼图块的宽度 1.5正方形
# fenlan=int(input('请输入word里面分栏数量\n'))# 1.5 4*6时 6列
'''
A4短边 最多4格,1.7
3格 2.3
2格 3.6
拼贴后的作品只有A4一半大小
项目1:横版照片
造型:0.56凹凸,7方形
样式:4:3
像素:1024*768
格子:4*6=24块
积木块长宽:1.7*1.7
分栏:6
项目2:横版照片 16宫格照片
样式:1:1
像素:1024*1024
格子:4*4
积木块长宽:1.7*1.7
分栏:5
项目3:横版照片 9宫格照片
样式:1:1
像素:1024*1024
格子:3*3
积木块长宽:2.3*2.3
分栏:3
(比4*6图片小)
项目4:横版照片 4宫格照片
样式:1:1
像素:1024*1024
格子:2*2
积木块长宽:3.6*3.6
分栏:2
(比4*6图片小)
2张A4打印纸
成品a4一半
项目1:横版照片
造型:0.56凹凸,7方形
样式:4:3
像素:1024*768
格子:4*6=24块
积木块长宽:2.3*2.3
分栏:4
'''
# pic=['jpg','png','tif']
# for i in pic:
# # print(i)
# geshi.append(i)
# print(geshi)
# bmp,jpg,png,tif,gif,pcx,tga,exif,fpx,svg,psd,
# cdr,pcd,dxf,ufo,eps,ai,raw,WMF,webp,avif,apng 等。”
#
print('----------第1步:读取总图(大图)所在的位置:-----------')
pathz=[]
prz="C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\凸起图案拼图\\总图"
# 过滤:只保留png结尾的图片
imgs1z=os.listdir(prz)
for img1z in imgs1z:
if img1z.endswith(".jpg"):
pathz.append(prz+'\\'+img1z)
# 所有总图片(原图)的路径
print(pathz)
print(len(pathz))# 一共几张图片(2张测试)
# print(imgs1z)
print('------第2步,调整照片大小(把照片缩小格式(4:3横版、3:4竖版、1:1九宫格)这里是1024*768-------')
# 先缩小图片格式,这样导出的拼图块们的容量小一点(适合打印版本A4)
# 不用第一部分,每张拼图块图片很大,4MB照片拆分24张,每张1MB(适合电子白板教学,高清图片)
# '''作者:幸福清风https://blog.csdn.net/xun527/article/details/117085712'''
from PIL import Image
import os.path
import glob
def convertjpg(jpgfile,outdir,width=1024,height=768): #横版本 把 16-266KB的照片转换成540*405像素,照片大小16*43KB,拆分后正好4*6一页
# def convertjpg(jpgfile,outdir,width=405,height=540): #竖版照片 把 16-266KB的照片转换成540*405像素,照片大小16*43KB,拆分后正好4*6一页
# 400*300宽高像素 15-24K
# 520*390宽高像素 29-30K
# 1024,height=768 哪怕只有45K,也是格子很大
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
if not os.path.exists(outdir):
os.mkdir(outdir)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
except Exception as e:
print(e)
print('------第3步,读取大图的位置,生成凹凸平涂------')
# '''多照片()'''
# 读取路径下的一个文件
for w in range(len(pathz)): # 0-2
# # 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\小图{}'.format(w+1)) # 1-2
path = '{}'.format(pathz[w])
print(path)
# r"C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\1.jpg"# 来源
# # 读取路径下的一个文件
# path = r"C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\1.jpg"# 来源
# for jpgfile in glob.glob(path):
# convertjpg(jpgfile,r"C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\小图")# 去向
# '''# 全部照片'''
# path = r"C:\Users\Administrator\Desktop\凸起图案拼图\原图\*.{}".format(geshi)
# for jpgfile in glob.glob(path):
# convertjpg(jpgfile,r"C:\Users\Administrator\Desktop\凸起图案拼图\照片调整")
print('------以下部分 生成带凹凸拼图-------')
'''https://blog.csdn.net/zbbzb/article/details/120127932 作者:zbbzb'''
# import os
# from PIL import Image
# # 分隔成n*m个方块
# # 分割几行几列, 二维数组保存
# def SplitImages(img_path, row, col):
# path_name = os.path.dirname(img_path)
# img = Image.open(img_path).convert("RGBA")
# imgSize = img.size
# splitW = int(imgSize[0]/col)
# splitL = int(imgSize[1]/row)
# pimg = img.load()
# imbList = []
# for i in range(row):
# rowList = []
# l = (i + 1) * splitL
# for j in range(col):
# w = (j + 1) * splitW
# imb = Image.new('RGBA', (splitW, splitL),(255,255,255,0))
# pimb = imb.load()
# for k in range(j * splitW, w):
# for z in range(i * splitL, l):
# pimb[k - splitW * j, z - i * splitL] = pimg[k,z]
# dirPath = path_name + "/" + str(i*10 + j) + ".png"
# # imb.save(dirPath)
# rowList.append(imb)
# imbList.append(rowList)
# return imbList
# 最终版:随机凹凸, 考虑圆心偏移
import os
from PIL import Image
import random
# 分割几行几列, 二维数组保存
def SplitImages(img_path, row, col):
path_name = os.path.dirname(img_path)
img = Image.open(img_path).convert("RGBA")
imgSize = img.size
splitW = int(imgSize[0]/col)
splitL = int(imgSize[1]/row)
pimg = img.load()
imbList = []
for i in range(row):
rowList = []
l = (i + 1) * splitL
for j in range(col):
w = (j + 1) * splitW
imb = Image.new('RGBA', (splitW, splitL),(255,255,255,0))
pimb = imb.load()
for k in range(j * splitW, w):
for z in range(i * splitL, l):
pimb[k - splitW * j, z - i * splitL] = pimg[k,z]
dirPath = path_name + "/" + str(i*10 + j) + ".png"
# imb.save(dirPath)
rowList.append(imb)
imbList.append(rowList)
return imbList
def Resize(img, rizeW, rizel, pastePoint=None):
if pastePoint is None:
pastePoint = [0, 0]
new_im = Image.new('RGBA', [rizeW, rizel],(255,255,255,0))
new_im.paste(img, pastePoint)
return new_im
def SplitCircle(imbList, imgPath):
path_name = os.path.dirname(imgPath)
img = Image.open(imgPath).convert("RGBA")
imgSize = img.size
col = len(imbList[0])
row = len(imbList)
if col == 1 and row == 1:
return
splitW = int(imgSize[0]/col)
splitL = int(imgSize[1]/row)
minV = min(splitW, splitL)
r_d = int(minV / 4) # 要计算 两个不能比 l 长 并且加上 offset 也不能超过 l
r_offset = int(minV / 8)
pSplitW = splitW + (r_d + r_offset) * 2
pSplitL = splitL + (r_d + r_offset) * 2
pimg = img.load()
# 存(row - 1) * (col - 1) 个中心点
pointList = []
for i in range(row):
colPointList = []
for j in range(col):
colPoint = []
rowPoint = []
if j != col - 1:
colPoint = [splitW * (j + 1), int(splitL/2) + i * splitL]
if i != row - 1:
rowPoint = [int(splitW / 2) + j * splitW, splitL * (i + 1)]
colPointList.append({'colPoint': colPoint, 'rowPoint': rowPoint})
imbList[i][j] = Resize(imbList[i][j], pSplitW, pSplitL, [r_d + r_offset, r_d + r_offset])
dirPath = path_name + "/" + str(i*10 + j) + ".png"
# imbList[i][j].save(dirPath)
pointList.append(colPointList)
for i in range(row):
for j in range(col):
imbImg = imbList[i][j]
new_img = imbImg
# 圆心靠左 靠右, 默认靠右
lrandNum = random.randint(0, 999999)
drandNum = random.randint(0, 999999)
lrRight = True
drRight = True
if lrandNum < 500000:
lrRight = False
if drandNum < 500000:
drRight = False
new_img_imb = new_img.load()
if j != col - 1:
if lrRight :
new_next_img = imbList[i][j + 1]
new_next_img_imb = new_next_img.load()
# 左右
for k in range((j + 1) * splitW, (j + 1) * splitW + r_d + r_offset):
for z in range(i * splitL, (i + 1) * splitL):
r_w = pointList[i][j]['colPoint'][0] + r_offset
r_l = pointList[i][j]['colPoint'][1]
r = ((pow(abs(k - r_w),1)+pow(abs(z - r_l),1)))*2
# 凹凸圆球的直径,作者原设置0.5,感觉三个凹型的拼图连接地方太细了,幼儿容易剪断,所以这里改成0.55
# 测试结果:0.3不规则矩形块(图形类似俄罗斯方块)
# 0.7 方块,四周 有很小的圆点(不连接) 内部有很小空心圆点(适合电子版)
# 0.6 方块,四周 有很大的圆点(不连接) 内部有很小空心圆点(适合电子版)
if r/2 < r_d:
new_img_imb[k - j * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = pimg[k, z]
new_next_img_imb[k - (j + 1) * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = (255,255,255,0)
imbList[i][j + 1] = new_next_img
else:
new_next_img = imbList[i][j + 1]
new_next_img_imb = new_next_img.load()
# 左右
for k in range((j + 1) * splitW - r_d - r_offset, (j + 1) * splitW):
for z in range(i * splitL, (i + 1) * splitL):
r_w = pointList[i][j]['colPoint'][0] - r_offset
r_l = pointList[i][j]['colPoint'][1]
r = ((pow(abs(k - r_w),1)+pow(abs(z - r_l),1)))*2
if r/2 < r_d:
new_next_img_imb[k - (j + 1) * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = pimg[k, z]
new_img_imb[k - j * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = (255,255,255,0)
imbList[i][j + 1] = new_next_img
if i!= row - 1:
if drRight:
new_down_img = imbList[i + 1][j]
new_down_img_imb = new_down_img.load()
# 上下
for k in range(j * splitW, (j + 1) * splitW):
for z in range((i + 1) * splitL, (i + 1) * splitL + r_d + r_offset):
r_w = pointList[i][j]['rowPoint'][0]
r_l = pointList[i][j]['rowPoint'][1] + r_offset
r = ((pow(abs(k - r_w),1)+pow(abs(z - r_l),1)))*2
if r/2 < r_d:
new_img_imb[k - j * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = pimg[k, z]
new_down_img_imb[k - j * splitW + r_d + r_offset, z - (i + 1) * splitL + r_d + r_offset] = (255,255,255,0)
imbList[i + 1][j] = new_down_img
else:
new_down_img = imbList[i + 1][j]
new_down_img_imb = new_down_img.load()
# 上下
for k in range(j * splitW, (j + 1) * splitW):
for z in range((i + 1) * splitL - r_d - r_offset, (i + 1) * splitL):
r_w = pointList[i][j]['rowPoint'][0]
r_l = pointList[i][j]['rowPoint'][1] - r_offset
r = ((pow(abs(k - r_w),1)+pow(abs(z - r_l),1)))*2
if r/2 < r_d:
new_down_img_imb[k - j * splitW + r_d + r_offset, z - (i + 1) * splitL + r_d + r_offset] = pimg[k, z]
new_img_imb[k - j * splitW + r_d + r_offset, z - i * splitL + r_d + r_offset] = (255,255,255,0)
imbList[i + 1][j] = new_down_img
imbList[i][j] = new_img
# n=[]
# for i in range (0,row*col):
# n.append(i)
# print(n)
print('----把每张图片的12份小图放入一个文件夹小图(每张大图生成一个文件夹)----')
for i in range(0,row): # 3
for j in range(0,col): # 4
n=3*4
dirPath = r"C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图" + "/小图{}/{}.png".format(w+1,'%02d'%(i*4 + j) )
# 在路径下的“拼图”文件夹下
#
imbList[i][j].save(dirPath)
if __name__ == '__main__':
# dirPath =r"C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/小图/"
SplitCircle(SplitImages(pathz[w], 3,4), pathz[w])
# SplitCircle(SplitImages(pathz[w], pic_puzzle_longnum, pic_puzzle_shortnum) , pathz[w])
# 横版高4长6
# 第一个数字是高度4张图片 第二个数字是宽度3张
# '''
# 71.8KB的图片4*6 24张3*8摆放在word 上下左右 1 1 1 1
print('-----第4步:拼图块导入docx打印-----')
print('----------4-1:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\零时Word')
print('---提取小图片路径------------')
path=[]
for r in range(len(pathz)):
pr="C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\凸起图案拼图\\小图{}".format(r+1)
# 过滤:只保留png结尾的图片
imgs1=os.listdir(pr)
for img1 in imgs1:
if img1.endswith(".png"):
path.append(pr+'\\'+img1)
# 所有图片的路径
print(path)
print(len(path))
# 216条路径(18张*12图)
# print(imgs1)
print('----------第3步:随机抽取9张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,len(pathz)): #28/2 0-14
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\长方形模板.docx')
# # 制作列表
# 从左边图列表和右边图列表中抽取图片(12张图片,可能5个向左、7个向右边)
# 24条里面0和12条是一组,2个里面随机抽1一个,1和13是一组,2个里面随机抽一个…… 抽出12个图片后
r=[]
c=[]
r.append(path[nn*12:nn*12+12]) # 左侧第一份,
# r.append(path[nn*24:nn*24+24]) # 连续12张图片、2份字母插入同一份A4
# print(r)
# 再打乱顺序读取12个
for a in r:
for b in a:
c.append(b)
print(c)
figures=random.sample(c[0:12],Number) # 前9张不重复打乱
# figures2=random.sample(c[4:8],Number) # 后9张不重复打乱
# figures3=random.sample(c[12:18],Number) # 后6张不重复打乱
# figures4=random.sample(c[18:24],Number) # 后6张不重复打乱
# 9+9张不重复打乱图片合并
# figures=figures1+figures2
# figures=figures1+figures2+figures3+figures4
print(figures)
# # 每2个学号一组的列表 m名字里面的前两个数字(学号)
# name2=name[nn*2:nn*2+2]
# print(name2)
# for z in range(2): # 5行组合循环2次 每页两张表
# 单元格位置3*3格
bg=[]
# 前1+3+1行不要写入 从4动
for x in range(0,3): # 3行 索引1行2行3行
for y in range(0,4): # 3列 索引0列1列2列
ww='{}{}'.format(x,y)
bg.append(ww)
print(bg)
table = doc.tables[0]
for t in range(len(bg)): # 02
pp=int(bg[t][0:1])
qq=int(bg[t][1:2])
# print(p)
k=figures[t]
print(pp,qq,k)
# 写入图片
run=doc.tables[0].cell(pp,qq).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(k),width=Cm(6.05),height=Cm(6.05))
# 单元格宽度6.15 6.15
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
# # 姓氏描画文字
# title=[]
# for t in range(4):
# title.append(name2[z][0])
# print(title)
# wz=[]
# # 前1+3+1行不要写入 从4动
# for x1 in range(0,3): # 3行 索引1行2行3行
# for y1 in range(0,4): # 3列 索引0列1列2列
# ww='{}{}'.format(x1,y1)
# wz.append(ww)
# print(wz)
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\凸起图案拼图\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/(打印合集)菱形凹凸图案拼图A4一页一份(3乘4).pdf")
file_merger.close()
# doc.Close()
# # # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/零时Word') #递归删除文件夹,即:删除非空文件夹
for i in range(len(pathz)):
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/凸起图案拼图/小图{}'.format(i+1)) #递归删除文件夹,即:删除非空文件夹
视频gif作品展示: