首先回答HashMap的底层原理?
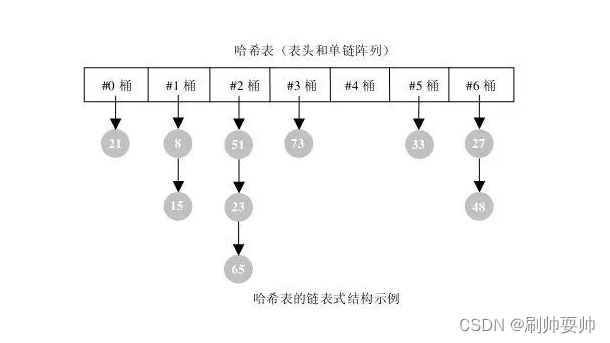
HashMap是数组+链表组成。数字组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。要将key 存储到(put)HashMap中,key类型实现必须计算hashcode方法,默认这个方法是对象的地址。接着还必须要覆盖对应的equals方法。如果对于插入的操作的来说,那么对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部。对于查找的来说话,就需要遍历 链表,然后key的equals方法去逐一对比查找。但是对应的key可以为空。所以,HashMap对应的链表越少,性能才越好。
如何解决冲突?
1:链式寻址法,这是一种常见的方法,简单理解就是把存在Hash冲突的key,以单向链表来进行存储。
2:开放定址法也称线性探测法,就是从发生冲突的那个位置开始,按照一定次序从Hash表找到一个空闲位置然后把发生冲突的元素存入到这个位置,而在java中,ThreadLocal就用到了线性探测法来解决Hash冲突
3、再Hash法,就是通过某个Hash函数计算的key,存在冲突的时候,再用另外一个Hash函数对这个可以进行Hash,一直运算,直到不再产生冲突为止,这种方式会增加计算的一个时间,性能上呢会有一些影响
HashMap在JDK1.8版本中是通过链式寻址法以及红黑树来解决Hash冲突的问题,其中红黑树是为了优化Hash表的链表过长导致时间复杂度增加的问题,当链表长度大于等于8并且Hash表的容量大于64的时候,再向链表添加元素,就会触发链表向红黑树的一个转化。(红黑树 是一种自平衡的二叉搜索树)
hashCode方法的作用:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当
集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理
位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如
果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相
同就散列其它的地址。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
HashTable的底层原理?
hashtable是通过数组与链表来储存数据,但是它与hashmap不同的是它的key不能为空同时其为线程安全的。虽然hashmap是线程安全的不过其保证线程安全的手段低效,它只是简单的对每个方法加上synchronized(悲观锁)相当于就是对底层的数组加上一把大锁。这种方式出现锁冲突的概率非常大,因为不管是读还是写都需要去竞争同一把锁所以其效率低下。
再次回答CurrentHashMap的底层原理?
ConcurrentHashMap与HashMap等的区别 ?
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。