总觉得忍一忍就会好起来。真笨,人家不就是觉得你会忍一忍,所以才这样对你吗?当我们凶狠地对待这个世界的时候,才会发现这个世界,突然变得温文尔雅了。——余华《在细雨中呼喊》
🎯作者主页: 追光者♂🔥
🌸个人简介:
💖[1] 计算机专业硕士研究生💖
🌟[2] 2022年度博客之星人工智能领域TOP4🌟
🏅[3] 阿里云社区特邀专家博主🏅
🏆[4] CSDN-人工智能领域优质创作者🏆
📝[5] 预期2023年10月份 · 准CSDN博客专家📝
- 无限进步,一起追光!!!
🍎感谢大家 点赞👍 收藏⭐ 留言📝!!!
附:
- 1.Python内置函数系统学习(1)——数据转换与计算 (详细语法参考+参数说明+应用场景示例) 对象—>>字符串、字符—>>ASACII码 综合应用
- 2.Python内置函数系统学习(2)——数据转换与计算 (详细语法参考+参数说明+应用场景示例), max()在列表、元组、字典中的综合应用 | 编程实现当前内存使用情况的监控
- 3.Python内置函数系统学习(3)——数据转换与计算 (详细语法参考+参数说明+具体示例) 详解min()函数在列表、元组、字典的综合应用 | lambda 很牛哦!你怎么看!?
- 4.【Python从入门到人工智能】16个必会的Python内置函数(4)——数据转换与计算 (详细语法参考+参数说明+具体示例) | 求和、四舍五入、幂运算的综合应用
- 5.【Python从入门到人工智能】14个必会的Python内置函数(5)——输入输出 (详细语法参考+参数说明+应用场景示例)| 你知道计算机八大学报么?| 附:知识图谱&区块链技术
- 6.【Python从入门到人工智能】14个必会的Python内置函数(6)——打印输出 (详细语法参考+参数说明+具体示例) | 详解Python中的打印输出!附综合案例!
🌿这是Python内置函数的第7篇文章。本篇首先分享Python打印输出的综合应用场景及其相关知识并给出实现代码,具体包含中英文多列对齐输出(zip函数的应用)以及通过print的多行打印模拟实现一个应用程序的主要应用界面、通过while循环和width实现分行输出国际列车的站名。然后初步分享了Python中格式化处理的一些知识,如格式转换、生成数据编号、格式化十进制整数、格式化浮点数、格式化百分数/科学记数法/金额等。注意,这不仅是Python基础,也是人工智能/机器学习基础知识哦!让我们一起来学习吧!祝大家学习顺利!
👀目录
- 🧩一、打印输出 & 综合应用场景
- 🔍1.1 场景二:中英文多列对齐输出
- 🔍1.2 场景三:实现程序主界面
- 🔍1.3 场景四:分行输出K3国际列车的站名(含问题记录和解决)
- 🧩二、格式化处理
- 🔍2.1 语法参考 & 参数说明
- 🔍2.2 示例
- 🎈2.2.1 格式转换
- 🎈2.2.2 生成数据编号
- 🎈2.2.3 格式化十进制整数
- 🎈2.2.4 格式化浮点数
- 🎈2.2.5 格式化百分数
- 🎈2.2.6 格式化科学记数法
- 🎈2.2.7 格式化金额
- 🎈2.2.8 补充:快速理解
🧩一、打印输出 & 综合应用场景
此前曾分享了打印输出函数print的综合应用场景一以及其较为高级的语法结构。本篇先继续分享print的剩余几个示例的综合应用场景。
🔍1.1 场景二:中英文多列对齐输出
中英文多列对齐输出 德国、法国、英国2018年汽车销量数据。读取多个列表的数据,对数据输出时,如果进行格式化处理,输出不对齐,影响输出效果。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/16/0016 10:37
gem = [["大众", 643518], ["奔驰", 319163], ["宝马", 265051], ["福特", 252323], ["雪铁龙", 227967], ["奥迪", 255300]]
fra = [["雪铁龙", 698985], ["雷诺", 547704], ["大众", 259268], ["福特", 82633], ["宝马", 84931], ["奔驰", 73254]]
eng = [["福特", 254082], ["大众", 203150], ["雪铁龙", 177298], ["奔驰", 172238], ["宝马", 172048], ["奥迪", 143739]]
for item1, item2, item3 in zip(gem, fra, eng):
print(item1[0], item1[1], " ", item2[0], item2[1], " ", item3[0], item3[1])
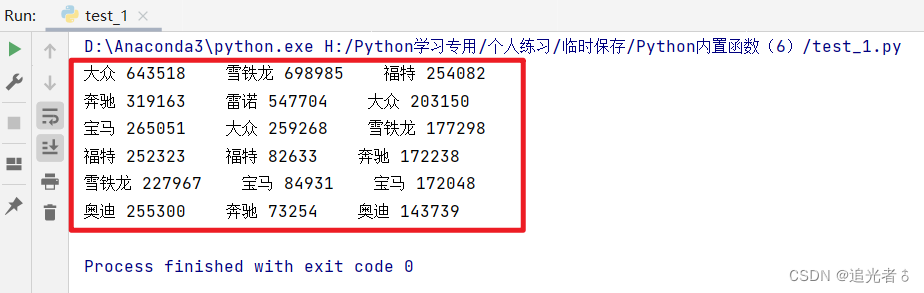
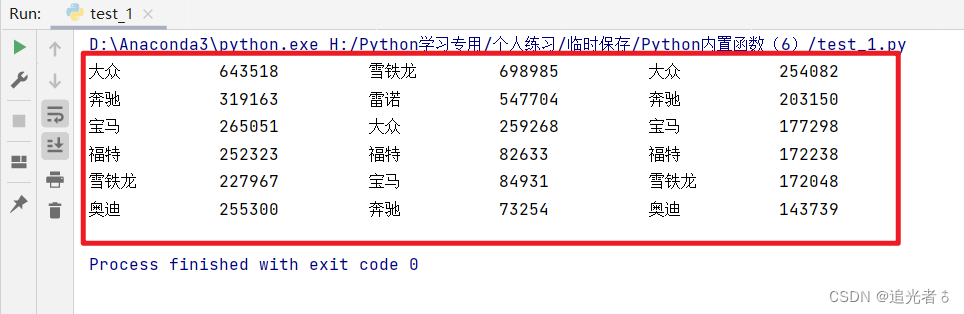
如果数据中包含中文,则输出的列数据无法排列整齐。使用 对齐函数ljust() 对数据进行居左对齐显示,也无法对齐数据。因为中文占据的字符长度与英文不同,此时可以使用制表符 ’\t’ 来进行对齐输出。代码如下:
依然是针对上述的 gem,fra,eng 嵌套列表:
for item1,item2,item3 in zip(gem,fra,eng):
item11 = item1[0].ljust(8)
item12 = str(item1[1]).ljust(8)
item21 = item2[0].ljust(8)
item22 = str(item2[1]).ljust(8)
item31 = item1[0].ljust(8)
item32 = str(item3[1]).ljust(8)
print(item11 +"\t",item12+"\t"," ",item21+"\t",item22+"\t"," ",item31+"\t",item32)
数据对齐结果 输出如下:
🔍1.2 场景三:实现程序主界面
利用print函数,可以输出程序界面,代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/16/0016 10:45
# 实现程序主界面
print("""\033[1;35m
****************************************************************
企业编码生成系统
****************************************************************
1.生成6位数字防伪编码 (213563型)
2.生成9位系列产品数字防伪编码(879-335439型)
3.生成25位混合产品序列号(B2R12-N7TE8-9IET2-FE35O-DW2K4型)
4.生成含数据分析功能的防伪编码(5A61M0583D2)
5.半智能防伪码自动生成(按指定样式数量自动生成)
6.企业粉丝防伪码抽奖
0.退出系统
================================================================
说明:通过数字键选择菜单
================================================================
\033[0m""")
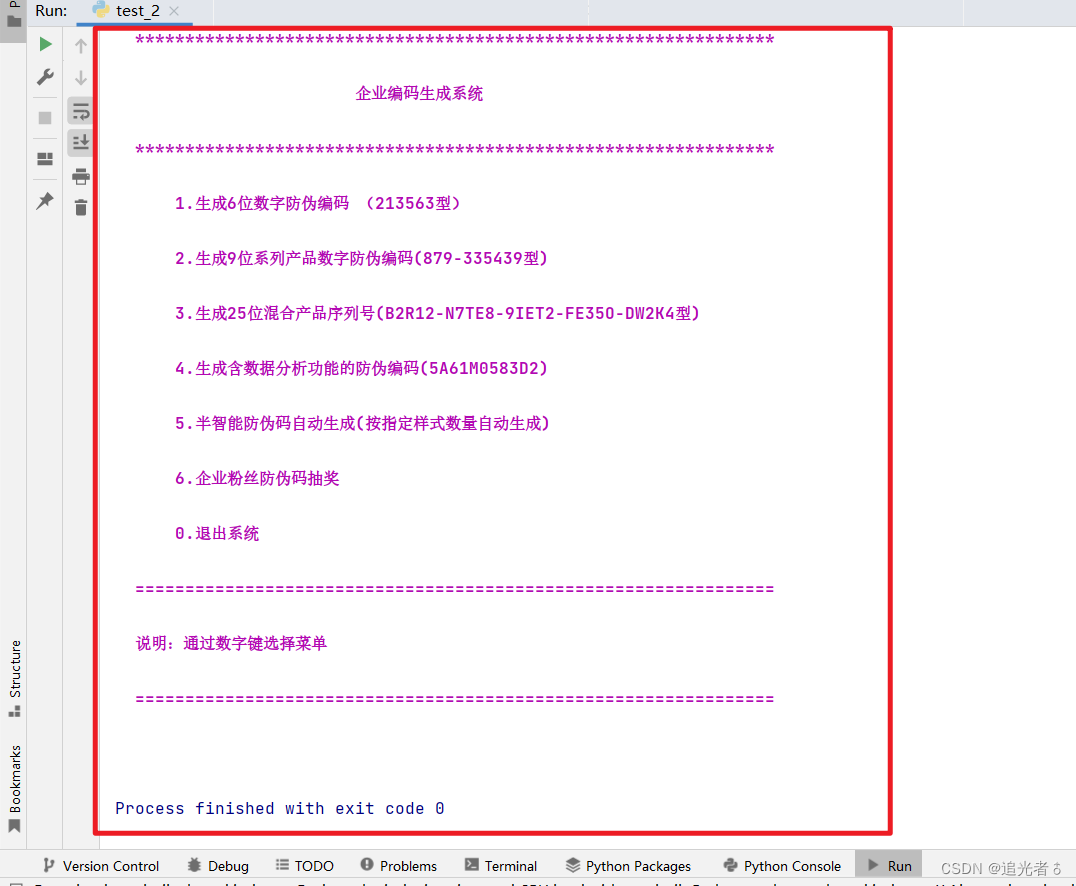
执行以后,我们可以得到如下的“程序主界面”输出结果:
🔍1.3 场景四:分行输出K3国际列车的站名(含问题记录和解决)
如果字符串过长,希望多行显示,可以通过切片技术实现多行的输出,如下代码,设置width变量的值,即可实现对K3国际列车的站名多行输出。代码如下:
#coding=utf-8
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/16/0016 10:48
# 场景四:分行输出K3国际列车的站名
k3 = '北京、张家口南、集宁南、朱日和、二连、扎门乌德、赛音山达、乔伊尔、乌兰巴托、宗哈拉、达尔汗、苏赫巴托、多卓尔内、纳乌什基、吉达、乌兰乌德、斯柳江卡、伊尔库茨克、集马、尼日涅乌丁斯克、伊兰斯卡雅、克拉斯诺亚尔斯克、马林斯克、泰加、新西伯利亚、巴拉宾斯克、鄂木斯克、伊希姆、秋明、斯维尔德洛夫斯克、彼尔姆、巴列集诺、基洛夫、高尔基、弗拉基米尔、莫斯科'
width = 22 # 设置每行22个字的输出
# width = 30
len1 = 0
k3line = ""
while len(k3) > width:
k3line = k3[0:width]
k3 = k3[width:len(k3)]
print(k3line)
print(k3[0:len(k3)])
这是执行上述程序,设置每行22个字的输出 得到的结果:(顿号 也算)

注意:上面的程序,是在PyCharm中执行的。但是,执行时需要在程序的第一行 添加 #coding=utf-8 ,若不添加,则会报下述错误:SyntaxError: Non-UTF-8 code starting with '\xe5' in file H:\Python学习专用\个人练习\临时保存\Python内置函数(6)\test_3.py on line 7, but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details,

这是因为 Python的默认编码是ASCII码,如果文件中含有中文,应在文件开头加上一句:#coding=utf-8,
另外要注意,若coding和=之间有空格,如**#coding =utf-8**,会可能有错误提示:SyntaxError: Non-ASCII character '\xe7' in file , but no encoding declared; see http://www.python.org/peps/pep-0263.html for details (或者是依然报上述错误的提示)
那么同样的道理,设置每行30个字的输出,只需要 width = 30 即可:

🧩二、格式化处理
🔍2.1 语法参考 & 参数说明
语法参考:
format() 可以对数据进行格式化处理操作,语法如下:
format(value, format_spec)
format_spec为格式化解释。当参数format_spec为空时,等同于函数str(value)的方式。value为要转换的数据。format_spec可以设置非常复杂的格式转换参数,实现比较完备的数据格式处理模板。format_spec的编写方式如下形式:
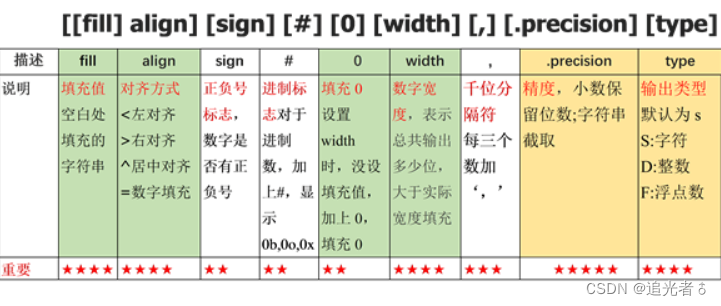
format_spec ::= [[fill]align][sign][#][0][width][,][.precision][type]
format_spec格式控制符可以分为文字对齐、填充值、标志设置、格式化、类型转换、千位符(数字分组)等主要应用。细化分类说明如下图所示。
format_spec 格式控制符细化分类:
主要参数说明:
fill(填充值):此处可以填写任何字符,通常与align、width一起使用,实现指定位数字符填充,通常格式、填充效果及位置分别如下两图所示。、
fill 填充格式:

fill 填充效果及位置:

通常用
0、*、#等进行填充。如果不写填充值,则使用默认填充值,默认填充值为空格。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/17/0017 8:02
print(format(99, '@<10')) # 用@填充,宽度为10个空格
print(format(99, '@>10')) # 用@填充,宽度为10个空格
输出结果为:

继续来看参数说明:
-
align(对齐方式):指在width(数字宽度)内输出时的对齐方式,分别使用<、>、^和=四个符号表示左对齐、右对齐、居中对齐和数字填充(只用于数字,在符号后进行补齐)。 -
width(数字宽度):指设定输出字符宽度,如果数据的实际位数比width指定宽度值大,则使用数据实际的长度。如果该值的实际位数小于指定宽度,则位数将设定的fill值填充或设定的0值填充,如果没有设置填充值,则用空格填充。
来看个小测试:
s = "PYTHON"
print(format(s, '10')) # 没有标志符,如果是字符串则默认左对齐,不足宽度部分默认用空格填充
print(format(10.24, '10')) # 没有标志符,如果是数字则默认右对齐,不足宽度部分默认用空格填充
print(format(s, '0>10')) # 右对齐,不足指定宽度部分用0号填充
print(format(s, '>04')) # 右对齐,因字符实际宽度大于指定宽度4,不用填充
print(format(s, '*>10')) # 右对齐,不足部分用“*”号填充
print(format(s, '>010')) # 右对齐,不足部分用0号填充
print(format(s, '>10')) # 右对齐,默认用空格填充
print(format(s, '<10')) # 左对齐,默认用空格填充
print(format(s, '<010')) # 左对齐,不足部分用0号填充
print(format(s, '@^10')) # 中间对齐,不足部分用“@”填充,宽度为10个空格
print(format(10.24, '0<10')) # 左对齐,不足部分用0号填充
print(format(10.24, '@^10')) # 右对齐,不足部分用“@”填充
print(format(10.24, '0>10')) # 右对齐,不足部分用0号填充
print(format(-10.24, '0=10')) # 右对齐,负号后面不足部分用0号填充,
我在注释中已经解释的很清楚了,大家可以自行验证~
得到的输出为:

继续进行 参数说明
-
Precision(精度):精度由小数点(.)开头。对于浮点数,精度表示小数部分输出的有效位数。对于字符串,精度表示输出的最大长度。 Precision(精度)通常和Type(类型)配合起来使用。 -
Type(类型):表示输出字符串、整数和浮点数类型的格式规则,默认为字符型s。对于整数类型,输出格式包括7 种:
(1)b: 输出整数的二进制方式;
(2)c: 输出整数对应的 Unicode 字符;
(3)d: 输出整数的十进制方式;
(4)n: 输出整数的十进制方式;
(5)o: 输出整数的八进制方式;
(6)x: 输出整数的小写十六进制方式;
(7)X: 输出整数的大写十六进制方式;
对于浮点数类型,输出格式包括7种:
(1)e: 输出浮点数对应的小写字母 e 的指数形式;
(2)E: 输出浮点数对应的大写字母 E 的指数形式;
(3)f: 输出浮点数的浮点表示形式,默认保留6位小数
(4)F: 输出浮点数的浮点表示形式,默认保留6位小数,无穷大转换成大写字母’INF’
(5)g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)。
(6)G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置 (如果是科学计数则是E)
(7)%: 输出浮点数的百分形式。
🔍2.2 示例
🎈2.2.1 格式转换
使用
format()函数可以实现格式转换。如果format()函数的参数format_spec未提供,则默认为将其他格式数据格式化为字符型,和调用str(value)效果相同。如:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/17/0017 8:19
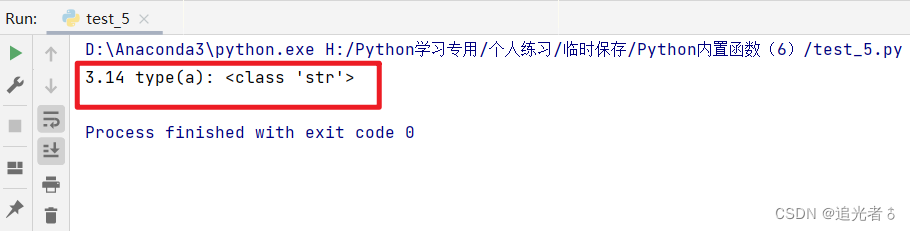
a = 3.14
a = format(a) # 使用format ()函数将浮点数转换成字符
print(a, "type(a):", type(a))
这和str()函数的效果是相同的:
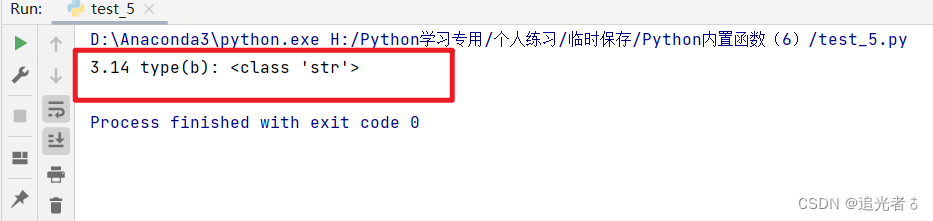
b = 3.14
b = str(3.14) # 使用str()函数将浮点数转换成字符
print(b,"type(b):",type(b))
再来看个将 日期 格式化为字符输出的示例:
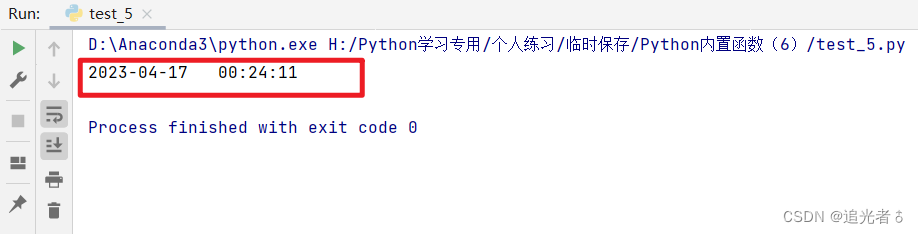
# 将日期格式化为字符
import datetime
print(format(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")))
设置参数
format_spec的值,可以进行相应数据类型的格式化,字符串可以提供的参数为’s’ 。十进制整形提供的参数为’d’ 和’n’,二进制的参数为’b’,八进制的参数为’o’,十六进制小写的参数为 ‘x’ ,十六进制大写的参数为 ‘X’ ,ASC码的参数为’c’,浮点数的参数为’f’。以上格式化后的数据类型都为字符型,举例如下:
print(format(12.2, 'f')) # 转换成浮点数,默认为小数保留6位
print(format(12, 'd')) # 转换成十进制
print(format(13)) # 不带参数默认为10进制
print(format(13, 'n')) # 转换成十进制数
print(format(13, 'b')) # 转换成二进制
print(format(65, 'c')) # 转换unicode成字符
print(format(97, 'c')) # 转换unicode成字符
print(format(8750, 'c')) # 转换unicode成字符
print(format(12, 'o')) # 转换成八进制
print(format(12, 'x')) # 转换成十六进制小写字母表示
print(format(12, 'X')) # 转换成十六进制大写字母表示
输出如下:

🎈2.2.2 生成数据编号
利用format()函数实现
数据编号。对数据进行编号,也是对字符串格式化操作的一种方式,使用format()方法可以对字符串进行格式化编号。只需设置填充字符(编号通常设置0),设置对齐方式时可以使用 <、> 和 ^ 符号表示左对齐、右对齐和居中对齐,对齐填充的符号在“宽度”范围内输出时填充,即可。对数字1进行3位编号,右对齐,需要设置format()方法的填充字符为0,对齐方式为右对齐,宽度为3。具体代码为:
print(format(1, '0>3')) # 001
print(format(1, '>03')) # 001
print(format(15, '0>5')) # 00015
要生成的编号通常比较复杂,如根据当天的日期建立编号,或者批量生成编号,或者将给定的批量数据中的数字转换成位数固定的编号,下面给出实现如上编号的实现方法:
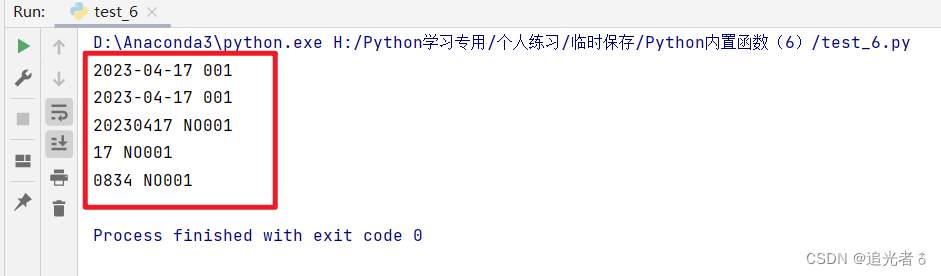
import datetime
# 时间+编号
wx = datetime.datetime.now().date()
now = datetime.datetime.now()
print(str(wx), format(1, '0>3')) # 年月日 +3位编号
print(format(now, '%Y-%m-%d'), format(1, '0>3')) # 年月日 +3位编号
print(format(now, '%Y%m%d'), 'NO' + format(1, '0>3')) # 年月日+NO+3位编号
print(format(now, '%d'), 'NO' + format(1, '0>3')) # 日期+NO+3位编号
print(format(now, '%H%M'), 'NO' + format(1, '0>3')) # 时钟+分 +NO+3位编号
输出:
# 批量生成编号
for i in range(1, 6):
print(format(i, '0>2'))

巧用for循环来 格式化列表编号:
# 格式化列表编号
# 对已有非编号数字进行格式化编号
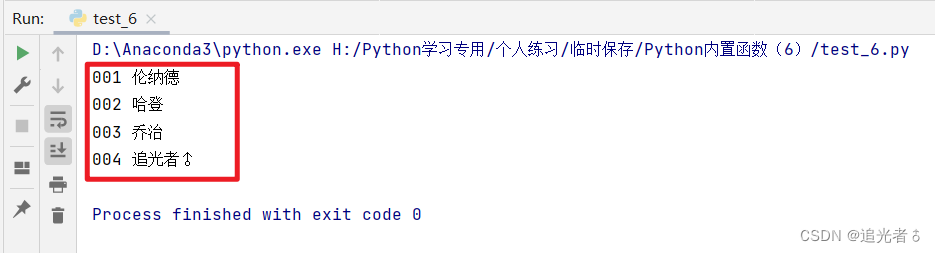
nba = {1: '伦纳德', 2: '哈登', 3: '乔治', 4: '追光者♂'}
for key, value in nba.items():
print(format(key, '0>3'), value)
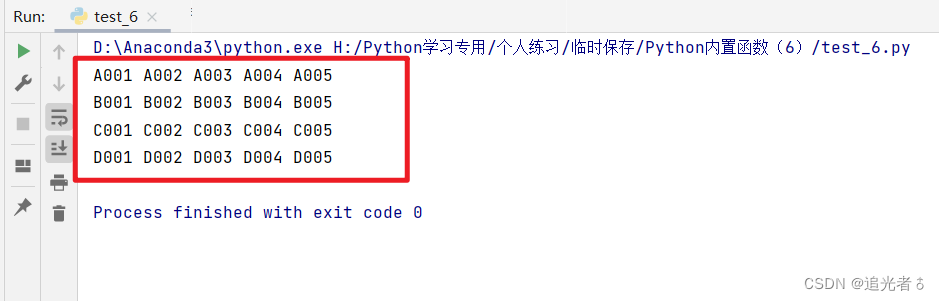
要实现嵌套编号,如A001-A005,B001-B005,C001-005的嵌套编号。代码如下:
for i in range(65, 69):
for j in range(1, 6):
data = chr(i) + format(j, '0>3') + ' '
print(data, end='')
print()
🎈2.2.3 格式化十进制整数
对于不同的类型数据,format函数的参数format_spec提供的值都不一样,对于十进制整数,整形数值可以提供的参数有’d’、’n’。具体如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/17/0017 8:40
print(format(99, '8d')) # 8位整数显示,不足部分整数前用空格填充
print(format(99, '+d')) # 格式化为带符号整数显示数据
print(format(-99, '8d')) # 格式化为8位带符号整数显示,补位空格放到符号前
print(format(99, '=8d')) # 格式化为8位正整数,用空格补位
print(format(-99, '=8d')) # 格式化为8位负整数,不足部分在负号后填充
print(format(99, '+8d')) # 格式化为8位正整数,不足部分在符号前填充
print(format(-99, '8d')) # 格式化为8位负整数,不足部分在符号前填充

print(format(99, '>10')) # 右对齐,宽度为10个空格
print(format(99, '<10')) # 左对齐,宽度为10个空格
print(format(99, '010')) # 用0填充空格,宽度为10个空格
print(format(99, '@<10')) # 用@填充空格,宽度为10个空格
print(format(99, '@>10')) # 用@填充空格,宽度为10个空格
print(format(+99, '=10')) # 用@填充空格,宽度为10个空格
print(format(99, '0^10')) # 用@填充空格,宽度为10个空格

s = 133
print(format(s, '0>10')) # 右对齐,不足指定宽度部分用0号填充
print(format(s, '>04')) # 右对齐,因字符实际宽度大于指定宽度4,不用填充
print(format(s, '*>10')) # 右对齐,不足指定宽度部分用*号填充
print(format(s, '>010')) # 右对齐,指定0标志位填充
print(format(s, '>10')) # 右对齐,没指定填充值,用默认值空格填充
print(format(s, '+^30')) # 居中对齐,用+号填充不足部分
print(format(s, '*<8')) # 右对齐,不足指定宽度部分用*号填充
print(format(s, '08')) # 右对齐,指定0标志位填充

🎈2.2.4 格式化浮点数
对于浮点数类型,可以提供的参数有 ‘
e’ ‘E’ ‘f’ ‘F’ ‘g’ ‘G’ ‘n’ ‘%’None输出格式。
用 f 表示浮点类型,并可以在其前边加上精度控制:用于控制输出宽度。这里由于输出位数大于宽度,就按实际位数输出了。还可以为浮点数指定符号,
+表示在正数前显示+,负数前显示 -;(空格)表示在正数前加空格,在负数前加 -;- 与什么都不加({:f})时一致:.3f表示浮点数的精度为3(小数位保留3位).3 指定除小数点外的输出位数。
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/17/0017 8:44
# 格式化浮点数
print(format(628, '.1f')) # 格式化为保留1位小数的浮点数
print(format(628, '.2f')) # 格式化为保留2位小数的浮点数
print(format(3.14159, '.1f')) # 格式化为保留1位小数的浮点数
print(format(3.14159, '.2f')) # 格式化为保留2位小数的浮点数
print(format(3.14159, '.5f')) # 格式化为保留5位小数的浮点数
print(format(-3.14159, '.3f')) # 格式化为保留1位小数的浮点数
print(format(3.1415926535898, 'f')) # 默认精度保留6位小数
print(format(3.14159, 'f')) # 默认精度保留6位小数,不足部分用空格填充

print(format(3.14159, '+.3f')) # 格式化为保留3位小树带符号的浮点数
print(format(3.14159, '>8.2f')) # 右对齐,保留三位小数
print(format(3.14159, '<10.2f')) # 左对齐,宽度为10,保留2位小数,不足空格填充
print(format(3.14159, '<.3f')) # 左对齐,保留3位小数点
print(format(3.14159, '@>10.3f')) # 右对齐,用@填充不足位置
print(format(-3.14159, '=10.2f')) # 格式化为保留2位小数的10位数,默认用空格填充
print(format(-3.14159, '0=10.2f')) # 格式化为保留2位小数的10位数,空格用0填充
print(format(3.14159, '0^10.2f')) # 保留2位小数的10位数,居中显示,空格用0填充

🎈2.2.5 格式化百分数
在格式化解释中单独或者在精度之后添加“
%”号,可以实现用百分数显示浮点数,如:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/17/0017 8:51
# 格式化百分数
print(format(0.161896, '%')) # 将小数格式化成百分数
print(format(0.161896, '.2%')) # 格式化为保留两位小数的百分数
print(format(0.0238912, '.6%')) # 格式化为保留六位小数的百分数
print(format(2 / 16, '.2%')) # 格式化为保留两位小数的百分数
print(format(3.1415926, '.1%')) # 格式化为保留一位小数的百分数
print(format(0.161896, '.0%')) # 格式化为保留整数的百分数
print(format(0.0238912, '8.6%')) # 格式化为保留六位小数的八位百分数
print(format(0.0238912, '>8.3%')) # 格式化为保留三位小数的八位百分数

🎈2.2.6 格式化科学记数法
如果要将浮点数采用
科学记数法表示,可以在格式化解释中使用“e”和“E”或者“g”和“G”。‘e’ 为通用的幂符号,用科学计数法打印数字,用’e’表示幂。使用’g’时,将数值以fixed-point格式输出。当数值特别大的时候,用幂形式打印。
# 格式化科学记数法
# e和E
print(format(3141592653589, 'e')) # 科学计数法,默认保留6位小数
print(format(3.14, 'e')) # 科学计数法,默认保留6位小数
print(format(3.14, '0.4e')) # 科学计数法,默认保留6位小数
print(format(3141592653589, '0.2e')) # 科学计数法,保留2位小数
print(format(3141592653589, '0.2E')) # 科学计数法,保留2位小数,采用大写E表示
# g和G
print(format(3.14e+1000000, 'F')) # 小数点计数法,无穷大转换成大小字母
print(format(3141592653589, 'g')) # 科学计数法,保留2位小数
print(format(314, 'g')) # 科学计数法,保留2位小数
print(format(3141592653589, '0.2g')) # 科学计数法,保留2位小数,采用大写E表示
print(format(3141592653589, 'G')) # 小数点计数法,无穷大转换成大小字母
print(format(3.14e+1000000, 'g')) # 小数点计数法,无穷大转换成大小字母

🎈2.2.7 格式化金额
format()函数提供千位分隔符用逗号还能用来做金额的千位分隔符。如果要实现通常格式化后金额前面带上相关货币的符号,需要在该函数前面手动加上相应货币符号。如:
# 格式化金额
print('$' + format(1201398.2315, '.2f')) # 添加美元符号,小数保留两位
print(chr(36) + format(1201398.2315, '.2f')) # ASCII码添加美元符号,小数保留两位
print('¥' + format(78088888, ',')) # 添加人民币符号,用千位分隔符进行区分金额
print('£' + format(7908.2315, '.2f')) # 添加英镑符号,用千位分隔符进行区分
print('€' + format(7908.2315,
',.2f')) # 添加欧元符号,保留两位小数,千位分隔print( chr(8364) + format(1201398.2315,'.2f')) # 添加欧元符号,保留两位小数
print(chr(0x20ac) + format(1201398.2315, ',f')) # 使用十六进制编码添加欧元符号
那么得到的输出效果如下:

🎈2.2.8 补充:快速理解
在Python中,我们可以通过多种方式实现格式化处理。下面我将简单介绍三种常用的方法:字符串的format()方法、旧式的格式化字符串和格式化字符串字面量(f-string)。
通过下面这些方法,我们可以方便地在字符串中插入变量和格式化输出,并且可以根据需要选择最适合的方式来进行格式化处理。
-
字符串的
format()方法:name = "John" age = 25 print("My name is {} and I'm {} years old.".format(name, age)) # 输出:My name is John and I'm 25 years old.在这个例子中,我们使用花括号
{}作为占位符来指示格式化的位置。然后,通过format()方法,我们将需要插入的值作为参数传递给字符串,并将其替换相应的占位符。 -
旧式的格式化字符串:
name = "John" age = 25 print("My name is %s and I'm %d years old." % (name, age)) # 输出:My name is John and I'm 25 years old.在旧式的格式化字符串中,我们使用
%符号来指示要插入的格式化值的类型。%s是字符串的占位符,%d是整数的占位符。我们在字符串的末尾使用%运算符,并将要插入的值作为元组传递给%运算符。 -
格式化字符串字面量(f-string):
name = "John" age = 25 print(f"My name is {name} and I'm {age} years old.") # 输出:My name is John and I'm 25 years old.在格式化字符串字面量中,我们可以使用
f前缀来指示这是一个格式化字符串。在字符串中使用大括号{}来嵌入变量和表达式。在{}内部,可以直接引用变量,并在需要时进行任意的表达式求值。
篇幅所限,本篇暂时分享到此哦~
此外,本篇记录的所有代码,也已经上传至资源,大家可以在我主页的资源内搜索进而下载哦~
🍒 热门专栏推荐:
- 🥇Python&AI专栏:【Python从入门到人工智能】
- 🥈前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 🥉文献精读&项目专栏:【小小的项目 (实战+案例)】
- 🍎C语言/C++专栏:【C语言、C++ 百宝书】(实例+解析)
- 🍏Java系列(Java基础/进阶/Spring系列/Java软件设计模式等)
- 🌞问题解决专栏:【工具、技巧、解决办法】
- 📝 加入Community 一起追光:追光者♂社区
持续创作优质好文ing…✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!













![P3611 [USACO17JAN] Cow Dance Show S](https://img-blog.csdnimg.cn/9a99efbf48524136ac8f270ebcdb519a.png)