0.摘要
在这项工作中,我们重新审视了在[13]中提出的全局平均池化层,并阐明了它如何明确地使卷积神经网络(CNN)具有出色的定位能力,尽管它是在图像级别标签上进行训练的。虽然这个技术之前被提出作为一种训练规范化的手段,但我们发现它实际上构建了一个通用的可定位的深度表示,揭示了CNN在图像上的隐式注意力。尽管全局平均池化看起来非常简单,但我们在ILSVRC 2014数据集上实现了37.1%的top-5错误率,而没有使用任何边界框标注进行训练。我们在各种实验中证明,我们的网络能够定位到具有区分性的图像区域,尽管它只是被训练用于解决分类任务。
1.引言
周等人最近的研究[34]表明,卷积神经网络(CNN)的各个层的卷积单元实际上可以作为物体检测器,即使没有提供有关物体位置的监督信息。尽管在卷积层中具有定位物体的显著能力,但当使用全连接层进行分类时,这种能力会丧失。最近,一些流行的全卷积神经网络,如网络中的网络(NIN)[13]和GoogLeNet [25],已经提出避免使用全连接层以减少参数数量同时保持高性能。
为了实现这一点,[13]使用全局平均池化作为结构规范化器,在训练过程中防止过拟合。在我们的实验中,我们发现全局平均池化层的优势不仅仅是作为一个规范化器 - 实际上,通过稍微调整,网络可以保持其卓越的定位能力直到最后一层。这种调整使得网络可以在单次前向传递中轻松识别出具有区分性的图像区域,适用于各种任务,甚至是网络最初没有经过训练的任务。如图1(a)所示,经过对象分类训练的CNN能够成功地定位与人类交互的对象而不是人类本身的区域,用于动作分类。
尽管我们的方法看起来非常简单,但在ILSVRC基准测试[21]的弱监督物体定位任务中,我们的最佳网络实现了37.1%的top-5测试错误率,这与完全监督的AlexNet [10]的34.2%的top-5测试错误率非常接近。此外,我们还证明了我们方法中深度特征的可定位性可以轻松地转移到其他识别数据集,用于通用分类、定位和概念发现。

图1.全局平均池化层的简单修改结合我们的类别激活映射(CAM)技术,使经过分类训练的CNN可以在单次前向传递中既对图像进行分类,又定位特定类别的图像区域,例如用于刷牙的牙刷和用于砍树的链锯。
1.1.相关工作
卷积神经网络(CNN)在各种视觉识别任务上取得了令人印象深刻的性能[10,35,8]。最近的研究表明,尽管CNN是在图像级别的标签上进行训练的,但它具有令人瞩目的物体定位能力[1,16,2,15,18]。在这项工作中,我们展示了在使用适当的架构的情况下,我们可以将这种能力从仅定位对象扩展到准确定位图像中用于区分的哪些区域。在这里,我们讨论了与本文最相关的两个研究方向:弱监督的物体定位和可视化CNN的内部表示。
弱监督物体定位:最近有很多研究探索使用CNN进行弱监督物体定位[1,16,2,15]。Bergamo等人[1]提出了一种自我学习的物体定位技术,涉及遮盖图像区域以识别导致最大激活的区域,以定位物体。Cinbis等人[2]和Pinheiro等人[18]将多实例学习与CNN特征相结合,用于物体定位。Oquab等人[15]提出了一种将中层图像表示转移的方法,并展示了通过在多个重叠的补丁上评估CNN的输出可以实现一定程度的物体定位。然而,这些作者并没有实际评估定位能力。另一方面,尽管这些方法取得了有希望的结果,但它们并没有进行端到端的训练,需要多次前向传递网络来定位物体,使得它们难以应用于实际的数据集。我们的方法进行了端到端的训练,并可以在单次前向传递中定位物体。
与我们的方法最相似的是Oquab等人[16]基于全局最大池化的工作。他们将全局最大池化应用于定位物体上的一个点,而不是确定物体的完整范围。然而,他们的定位仅限于物体边界上的一个点,而不是确定物体的完整范围。我们认为,虽然最大和平均函数非常相似,但使用平均池化会鼓励网络识别物体的完整范围。这背后的基本直觉是,与最大池化相比,平均池化的损失在网络识别物体的所有区域时更有利于网络。这在第3.2节中有更详细的解释,并通过实验证实。此外,与[16]不同的是,我们证明了这种定位能力是通用的,即使是对于网络没有经过训练的问题,也可以观察到这种定位能力。
我们使用类别激活映射来指代为每个图像生成的加权激活映射,如第2节所述。我们想强调的是,虽然全局平均池化不是我们在这里提出的一种新技术,但我们认为它可以用于准确的判别性定位的观察是我们工作独有的。我们相信,这种技术的简单性使其具有可移植性,并可以应用于各种计算机视觉任务,实现快速准确的定位。
可视化CNN:最近有一些研究[30,14,4,34]试图通过可视化CNN学习到的内部表示来更好地理解它们的特性。Zeiler等人[30]使用反卷积网络来可视化每个单元激活的模式。Zhou等人[34]展示了CNN在训练中学习到的物体检测器,并证明同一个网络可以在单次前向传递中同时进行场景识别和物体定位。这两项工作只分析了卷积层,忽略了全连接层,因此描绘了不完整的情况。通过去除全连接层并保持大部分性能,我们能够从头到尾地理解我们的网络。
Mahendran等人[14]和Dosovitskiy等人[4]通过反转不同层次的深度特征来分析CNN的视觉编码。虽然这些方法可以反转全连接层,但它们只显示深度特征中保存的信息,而没有突出显示这些信息的相对重要性。与[14]和[4]不同,我们的方法可以准确地突出显示图像的哪些区域对于区分是重要的。总体而言,我们的方法为我们进一步了解CNN提供了另一个视角。
2.类激活映射(Class Activation Mapping,CAM)
在本节中,我们描述了使用全局平均池化(GAP)在CNN中生成类别激活映射(CAM)的过程。对于特定的类别,类别激活映射指示CNN用于识别该类别的区分性图像区域(例如,图3)。生成这些映射的过程如图2所示。
我们使用的网络架构类似于Network in Network [13]和GoogLeNet [25],该网络主要由卷积层组成,在最终输出层(在分类任务中是softmax层)之前,我们对卷积特征图进行全局平均池化,并将其作为全连接层的特征,该全连接层生成所需的输出(分类或其他)。在这种简单的连接结构下,我们可以通过将输出层的权重投影到卷积特征图上来确定图像区域的重要性,我们称之为类别激活映射技术。
如图2所示,全局平均池化将最后一个卷积层的每个单元的特征图的空间平均值输出。这些值的加权和用于生成最终的输出。类似地,我们计算最后一个卷积层的特征图的加权和,以获取我们的类别激活映射。我们将在下面更正式地描述这个过程,以softmax为例。相同的技术可以应用于回归和其他损失函数。


根据之前的研究[34,30]的直觉,我们期望每个单元被其感受野内的某种视觉模式激活。因此,fk是这种视觉模式存在的映射。类别激活映射只是不同空间位置上这些视觉模式存在程度的加权线性和。通过将类别激活映射上采样到输入图像的尺寸,我们可以确定与特定类别最相关的图像区域。在图3中,我们展示了使用上述方法输出的一些CAMs示例。我们可以看到各个类别的图像的区分性区域被突出显示。在图4中,我们突出显示了在使用不同的类别c生成映射时单个图像的CAMs的差异。我们观察到,即使对于给定的图像,不同类别的区分性区域也是不同的。这表明我们的方法按预期工作。我们将在后面的章节中定量地证明这一点。
全局平均池化(GAP)与全局最大池化(GMP)之间的区别:根据之前有关使用GMP进行弱监督目标定位的研究[16],我们认为强调GAP和GMP之间的直观区别非常重要。我们认为,与GMP鼓励网络仅识别一个区分性部分相比,GAP损失鼓励网络识别对象的范围。这是因为在对映射进行平均时,通过找到对象的所有区分性部分,可以使值最大化,因为所有低激活都会降低特定映射的输出。另一方面,对于GMP来说,除了最具区分性的部分之外的所有图像区域的低分数不会影响分数,因为只执行最大值操作。我们在ILSVRC数据集上在第3节进行了实验证明了这一点:尽管GMP在分类性能上与GAP相似,但是GAP在定位方面表现优于GMP。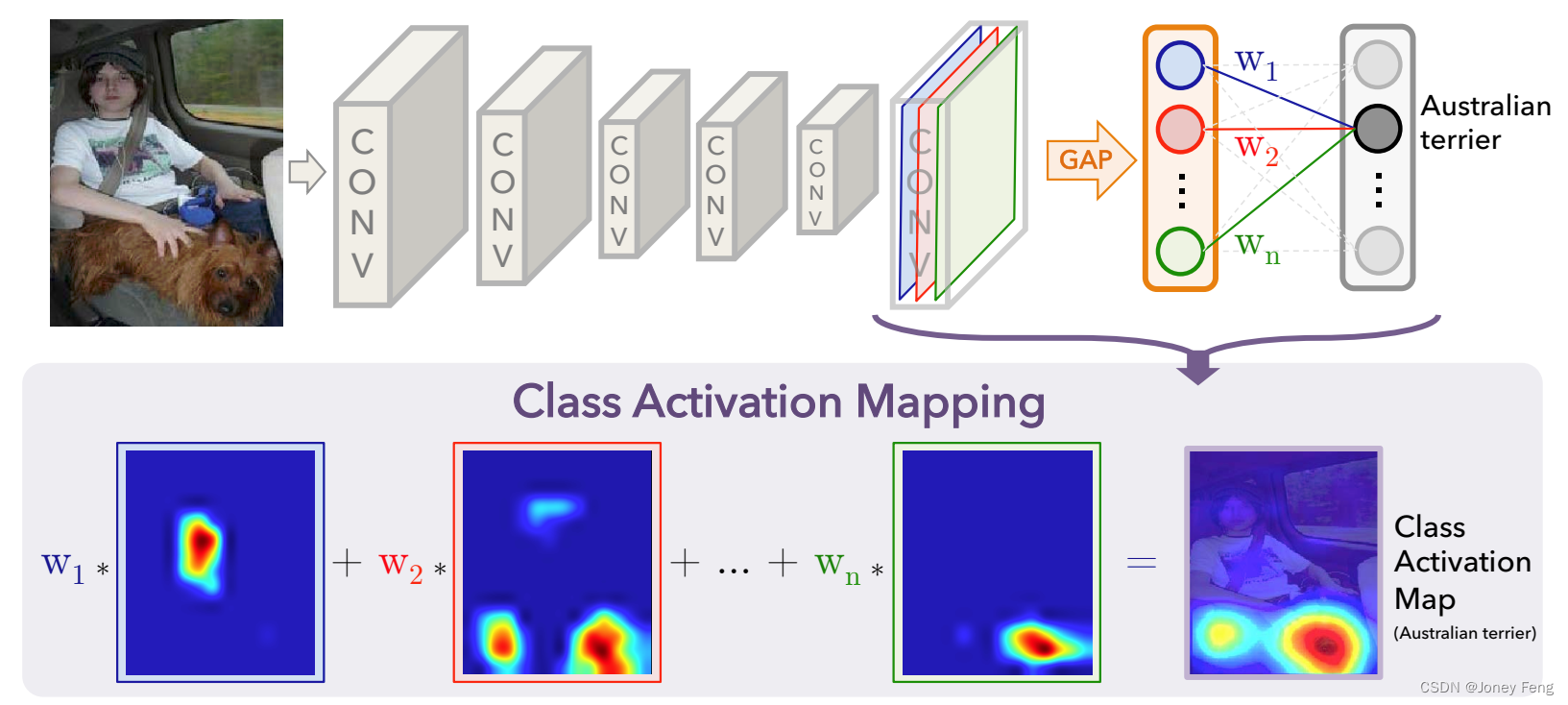
图2. 类别激活映射:预测的类别分数被映射回之前的卷积层,生成类别激活映射(CAMs)。CAM突出显示了类别特定的区分性区域。
图3. 来自ILSVRC [21]的两个类别的CAMs。这些映射突出显示了用于图像分类的区分性图像区域,例如briard类别的动物头部和杠铃上的盘子。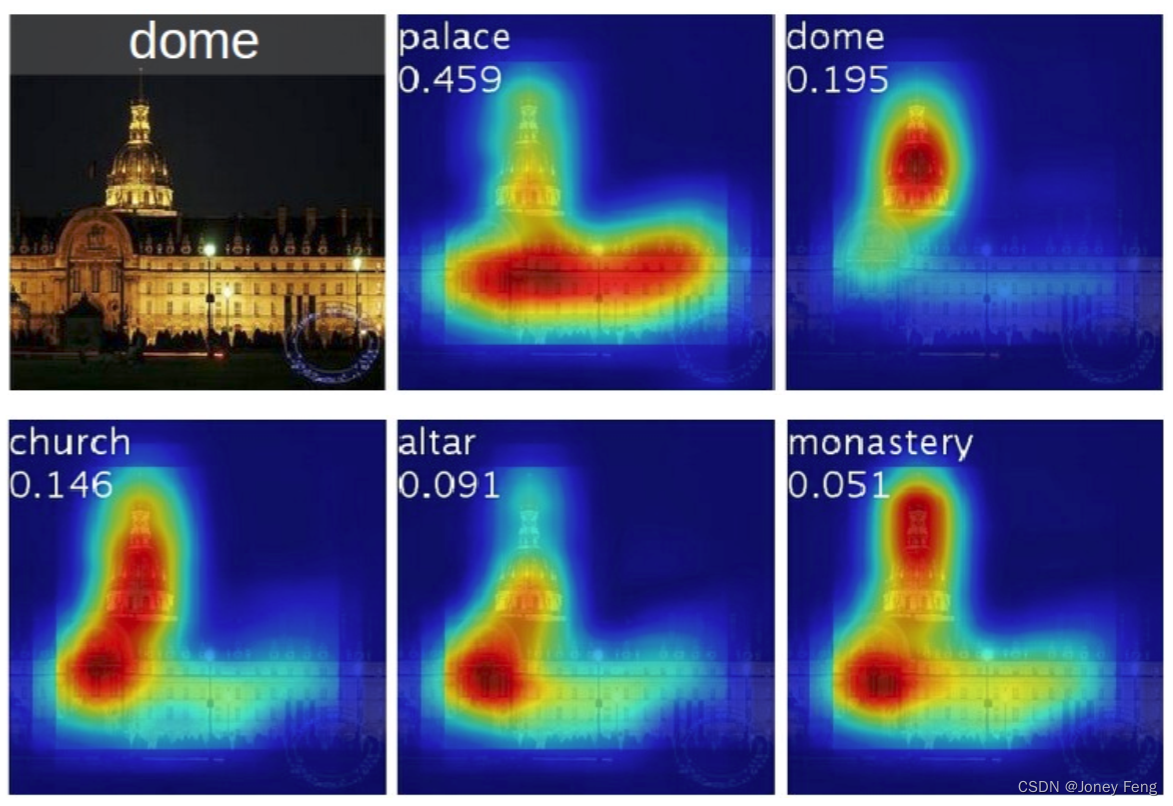
图4. 从给定图像的前5个预测类别生成的CAMs示例,其中地面实况为圆顶。每个类别激活映射上方显示了预测的类别及其得分。我们观察到,突出显示的区域在预测的类别之间有所变化,例如,圆顶激活了上部的圆形部分,而宫殿激活了复合物的下部平坦部分。
3.弱监督目标定位
在本节中,我们评估了在ILSVRC 2014基准数据集[21]上训练的CAM的定位能力。我们首先在第3.1节中描述了实验设置和使用的各种CNN。然后,在第3.2节中,我们验证了我们的技术在学习定位时不会对分类性能产生不利影响,并提供了弱监督目标定位的详细结果。
3.1.实验设计
对于我们的实验,我们评估了在以下流行的CNN上使用CAM的效果:AlexNet [10],VGGnet [24]和GoogLeNet [25]。一般来说,对于这些网络的每一个,我们在最终输出之前移除全连接层,并用GAP紧随其后,然后是一个全连接的softmax层。需要注意的是,移除全连接层大大减少了网络参数(例如,对于VGGnet,减少了90%的参数),但也会带来一些分类性能的下降。
我们发现,当GAP之前的最后一个卷积层具有更高的空间分辨率时,网络的定位能力得到改善,我们称之为映射分辨率。为了实现这一点,我们从一些网络中移除了几个卷积层。具体而言,我们进行了以下修改:对于AlexNet,我们移除了conv5之后的层(即pool5到prob),从而得到一个13×13的映射分辨率。对于VGGnet,我们移除了conv5-3之后的层(即pool5到prob),从而得到一个14×14的映射分辨率。对于GoogLeNet,我们移除了inception4e之后的层(即pool4到prob),从而得到一个14×14的映射分辨率。对于上述每个网络,我们添加了一个大小为3×3,步长为1,填充为1,具有1024个单元的卷积层,然后是一个GAP层和一个softmax层。然后,我们对这些网络进行了2次微调,使用ILSVRC [21]的130万个训练图像进行1000种物体分类,得到了我们的最终网络AlexNet-GAP,VGGnet-GAP和GoogLeNet-GAP。
对于分类任务,我们将我们的方法与原始的AlexNet [10],VGGnet [24]和GoogLeNet [25]进行比较,并提供Network in Network (NIN) [13]的结果。对于定位任务,我们将我们的方法与原始的GoogLeNet [3],NIN和使用反向传播[23]而不是CAM进行比较。此外,为了比较平均池化和最大池化,我们还提供了使用全局最大池化(GoogLeNet-GMP)进行训练的GoogLeNet的结果。我们使用与ILSVRC相同的错误度量(top-1、top-5)来评估我们的网络在分类和定位任务中的性能。对于分类任务,我们在ILSVRC验证集上进行评估,对于定位任务,我们在验证集和测试集上进行评估。
3.2.结果
我们首先报告物体分类的结果,以证明我们的方法不会对分类性能造成重大影响。然后,我们证明我们的方法在弱监督目标定位方面是有效的。
分类:表1总结了原始网络和我们的GAP网络的分类性能。我们发现,在大多数情况下,从各种网络中移除额外的层会导致1-2%的小幅度性能下降。我们观察到,AlexNet在移除全连接层时受到的影响最大。为了补偿,我们在GAP之前添加了两个卷积层,得到了AlexNet*-GAP网络。我们发现,AlexNet*-GAP的性能与AlexNet相当。因此,总体上我们发现我们的GAP网络在分类性能方面基本保持不变。此外,我们观察到,GoogLeNet-GAP和GoogLeNet-GMP在分类上有类似的性能,正如预期的那样。需要注意的是,网络在分类上表现良好是为了在定位任务中能够准确识别物体类别和边界框位置,从而实现高性能的定位任务非常重要。
定位:为了进行定位,我们需要生成一个边界框及其对应的物体类别。为了从CAMs生成边界框,我们使用一个简单的阈值技术来分割热图。我们首先将值大于CAM的最大值的20%的区域进行分割。然后,我们选择覆盖分割图中最大连通组件的边界框。对于前5个预测类别,我们使用这种方法生成边界框,并计算定位评估指标。图6(a)显示了使用此技术生成的一些示例边界框。表2显示了在ILSVRC验证集上的定位性能,并在图5中展示了示例输出。
我们观察到,我们的GAP网络在所有基准方法中表现得更好,其中GoogLeNet-GAP在top-5定位错误率方面达到了最低的43%,这是非常显著的,因为该网络没有在单个标注的边界框上进行训练。我们观察到,我们的CAM方法在定位任务上明显优于[23]中的反向传播方法(参见图6(b)进行比较)。此外,我们观察到,尽管在分类任务中情况相反,GoogLeNet-GAP在定位任务上明显优于GoogLeNet。我们认为,GoogLeNet的低映射分辨率(7×7)使其无法获得准确的定位结果。最后,我们观察到,GoogLeNet-GAP相对于GoogLeNet-GMP有着明显的优势,这说明了对于确定物体的范围,平均池化比最大池化更重要。
为了进一步将我们的方法与现有的弱监督[23]和全监督[25,22,25]的CNN方法进行比较,我们在ILSVRC测试集上评估了GoogLeNet-GAP的性能。我们在这里采用了稍微不同的边界框选择策略:我们从前两个预测类别的类激活图中选择两个边界框(一个紧密的和一个松散的),并从第三个预测类别中选择一个松散的边界框。这种启发式方法在分类精度和定位精度之间进行权衡。我们发现,这种启发式方法有助于提高验证集的性能。性能总结如表3所示。在弱监督设置下,具有启发式方法的GoogLeNet-GAP实现了37.1%的top-5错误率,与全监督设置下AlexNet(34.2%)的top-5错误率非常接近。虽然令人印象深刻,但与相同架构的全监督网络进行比较时(即弱监督的GoogLeNet-GAP与全监督的GoogLeNet),我们还有很长的路要走。
表1. ILSVRC验证集上的分类错误率。
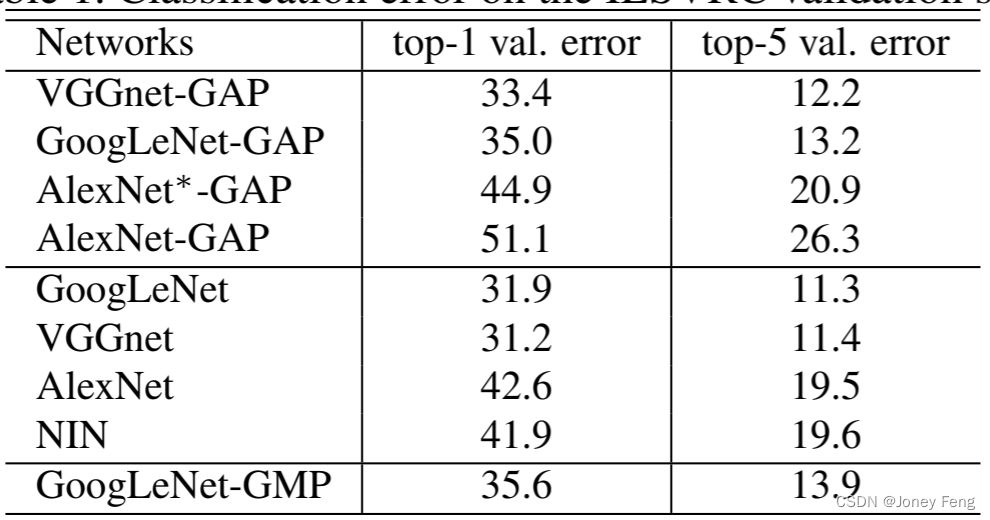
表2. ILSVRC验证集上的定位错误率。Back prop表示使用[23]进行定位,而不是CAM。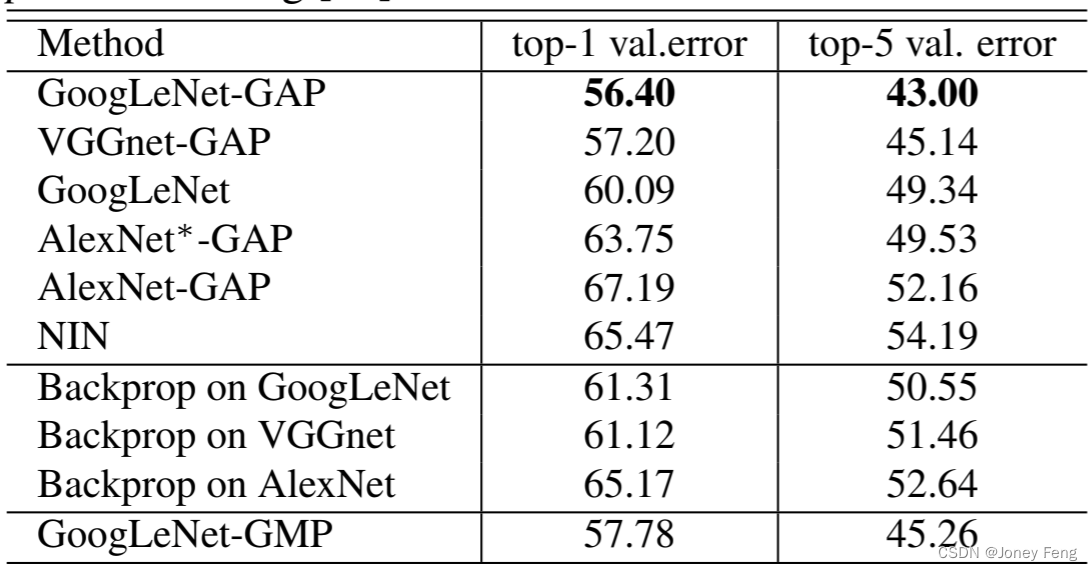
表3.各种弱监督和全监督方法在ILSVRC测试集上的定位错误率。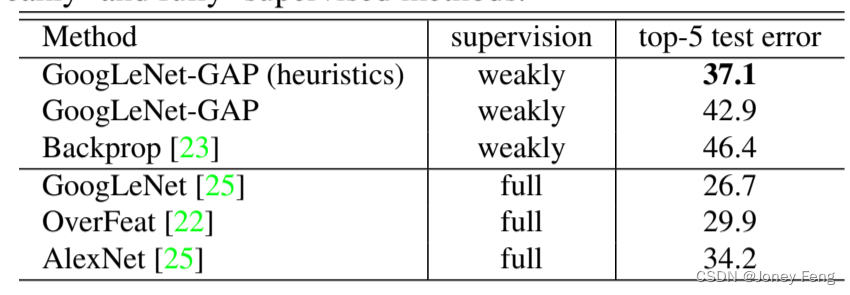
4.通用定位的深度特征
在CNN的高层级特征(例如AlexNet的fc6和fc7)的响应已被证明是非常有效的通用特征,并在各种图像数据集上达到了最先进的性能[3,20,35]。在这里,我们展示了我们的GAP CNN所学习到的特征也作为通用特征表现良好,并且作为额外的奖励,可以确定用于分类的有区别的图像区域,尽管它们没有被训练用于这些特定任务。为了获得类似于原始softmax层的权重,我们简单地在GAP层的输出上训练了一个线性SVM [5]。
首先,我们将我们的方法与一些基线方法在以下场景和对象分类基准测试中进行比较:SUN397 [28],MIT Indoor67 [19],Scene15 [11],SUN Attribute [17],Caltech101 [6],Caltech256 [9],Stanford Action40 [29]和UIUC Event8 [12]。实验设置与[35]中相同。在表5中,我们将我们最好的网络GoogLeNet-GAP的特征性能与AlexNet的fc7特征和GoogLeNet的ave pool特征进行比较。
正如预期的那样,GoogLeNet-GAP和GoogLeNet在性能上明显优于AlexNet。此外,我们观察到,尽管GoogLeNet-GAP具有更少的卷积层,但其性能与GoogLeNet相似。总体而言,我们发现GoogLeNet-GAP特征作为通用视觉特征与最先进的方法具有竞争力。
更重要的是,我们希望探索在这种情况下使用我们的CAM技术与GoogLeNet-GAP生成的定位图是否具有信息量。图8展示了各种数据集的一些示例图。我们观察到,最具区分性的区域在所有数据集上都被突出显示。总的来说,我们的方法可以有效地生成可定位的深度特征用于通用任务。
在第4.1节中,我们探索了对鸟类的细粒度识别,并展示了我们如何评估通用定位能力并利用它来进一步提高性能。在第4.2节中,我们展示了如何使用GoogLeNet-GAP从图像中识别通用的视觉模式。
4.1.细粒度识别
在这一部分中,我们将我们的通用可定位深度特征应用于在CUB-200-2011 [27]数据集中识别200种鸟类。该数据集包含11,788张图像,其中5,994张用于训练,5,794张用于测试。我们选择这个数据集是因为它还包含边界框注释,可以让我们评估我们的定位能力。表4总结了结果。
我们发现,当在训练和测试中使用完整的图像而没有任何边界框注释时,GoogLeNet-GAP的性能与现有方法相当,准确率达到了63.0%。当使用边界框注释时,准确率提高到了70.5%。现在,鉴于我们网络的定位能力,我们可以使用类似于第3.2节(即阈值法)的方法,在训练和测试集中首先识别出鸟类边界框。然后,我们再次使用GoogLeNet-GAP从边界框内的图像裁剪中提取特征进行训练和测试。我们发现,这显著提高了性能,达到了67.8%。这种定位能力在细粒度识别中特别重要,因为各个类别之间的区别微妙,有一个更加聚焦的图像裁剪可以实现更好的区分。
此外,我们发现,在0.5交并比(IoU)准则下,GoogLeNet-GAP能够准确地定位41.0%的图像中的鸟类,而随机情况下的准确率为5.5%。我们在图7中展示了一些示例。这进一步验证了我们方法的定位能力。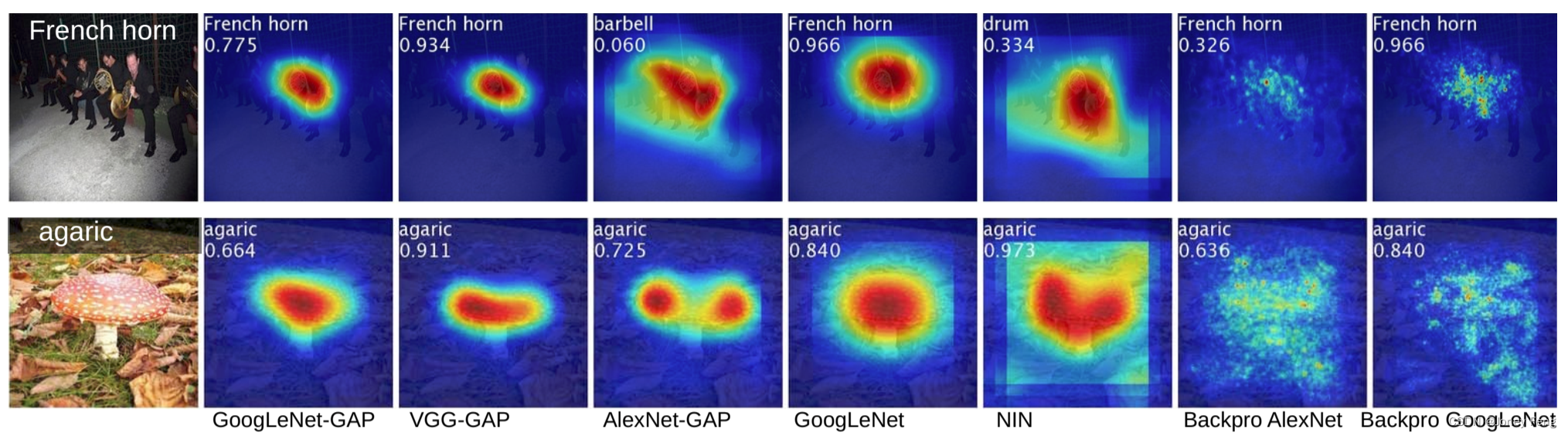
图5.CNN-GAP的类激活图和反向传播方法的类别特定显著性图。

图6.a)来自GoogleNet-GAP的定位示例。b)GooleNet-GAP定位和使用AlexNet进行反向传播的对比。绿色表示真实边界框,红色表示来自类激活图的预测边界框。
4.2.模式识别
在本节中,我们探讨了我们的技术是否能够在图像中识别除了物体之外的常见元素或模式,如文本或高层概念。给定一组包含共同概念的图像,我们希望确定我们的网络识别哪些区域是重要的,并且这是否与输入模式相对应。我们采用了与之前类似的方法:对GoogLeNet-GAP网络的GAP层进行线性SVM训练,并应用CAM技术来确定重要区域。我们进行了三个模式发现实验,使用了我们的深度特征。结果如下所述。请注意,在这种情况下,我们没有训练和测试集的划分-我们只是使用我们的CNN进行视觉模式发现。
在场景中发现有信息量的对象:我们从SUN数据集[28]中选择了10个场景类别,其中包含至少200个经过完全标注的图像,总共4675个经过完全标注的图像。我们为每个场景类别训练一个一对多的线性SVM,并使用线性SVM的权重计算CAM。在图9中,我们绘制了预测场景类别的CAM,并列出了与高CAM激活区域最频繁重叠的前6个对象,针对两个场景类别。我们观察到,高激活区域经常对应于表明特定场景类别的对象。
在弱标注图像中的概念定位:使用[33]中的硬负样本挖掘算法,我们学习概念检测器,并应用我们的CAM技术来定位图像中的概念。为了训练一个短语的概念检测器,正样本集包含在其文本标题中包含短语的图像,负样本集由随机选择的在其文本标题中没有任何相关词语的图像组成。在图10中,我们展示了两个概念检测器的排名靠前的图像和CAM。请注意,CAM定位了概念的信息区域,即使这些短语比典型的物体名称更抽象。
弱监督的文本检测器:我们使用来自SVT数据集[26]的350个包含文本的Google StreetView图像作为正样本集,以及来自SUN数据集[28]中的户外场景图像的随机采样图像作为负样本集,训练了一个弱监督的文本检测器。如图11所示,我们的方法能够准确地突出显示文本,而无需使用边界框注释。
解释视觉问答:我们在视觉问答中使用我们的方法和可定位的深度特征,这是在[36]中提出的基准方法。在开放式轨道的测试标准上,它的总体准确率为55.89%。如图12所示,我们的方法突出显示与预测答案相关的图像区域。
表格4. 在CUB200数据集上的细粒度分类性能。GoogLeNet-GAP能够成功定位重要的图像裁剪,提升分类性能。
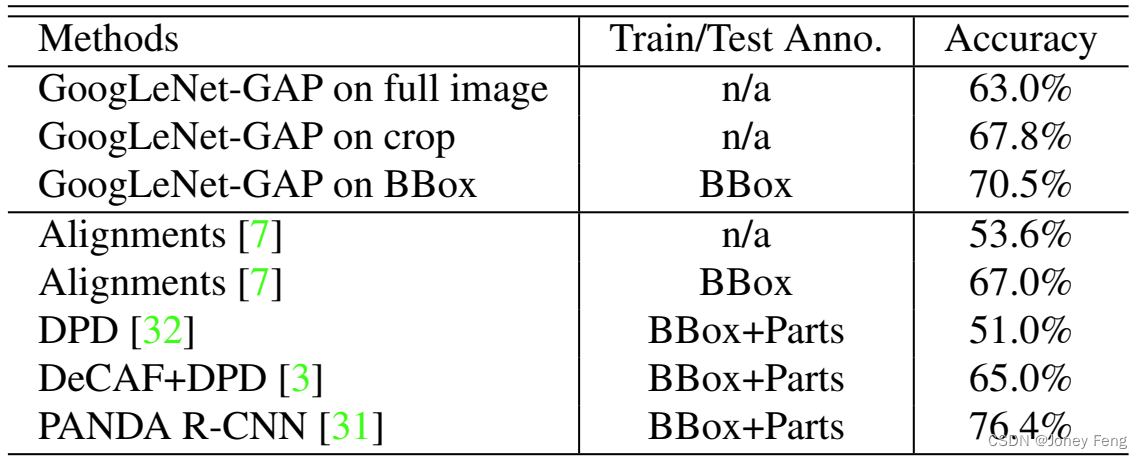

图7. CUB200数据集中四个鸟类别的选定图像的CAMs和推断出的边界框(以红色表示)。在第4.1节中,我们对边界框的质量进行了定量评估(0.5 IoU的准确率为41.0%)。我们发现,在这些CAM边界框中提取GoogLeNet-GAP特征并重新训练SVM可以将鸟类别的分类准确率提高约5%(表4)。
表格5. 不同深度特征在代表性场景和物体数据集上的分类准确率。

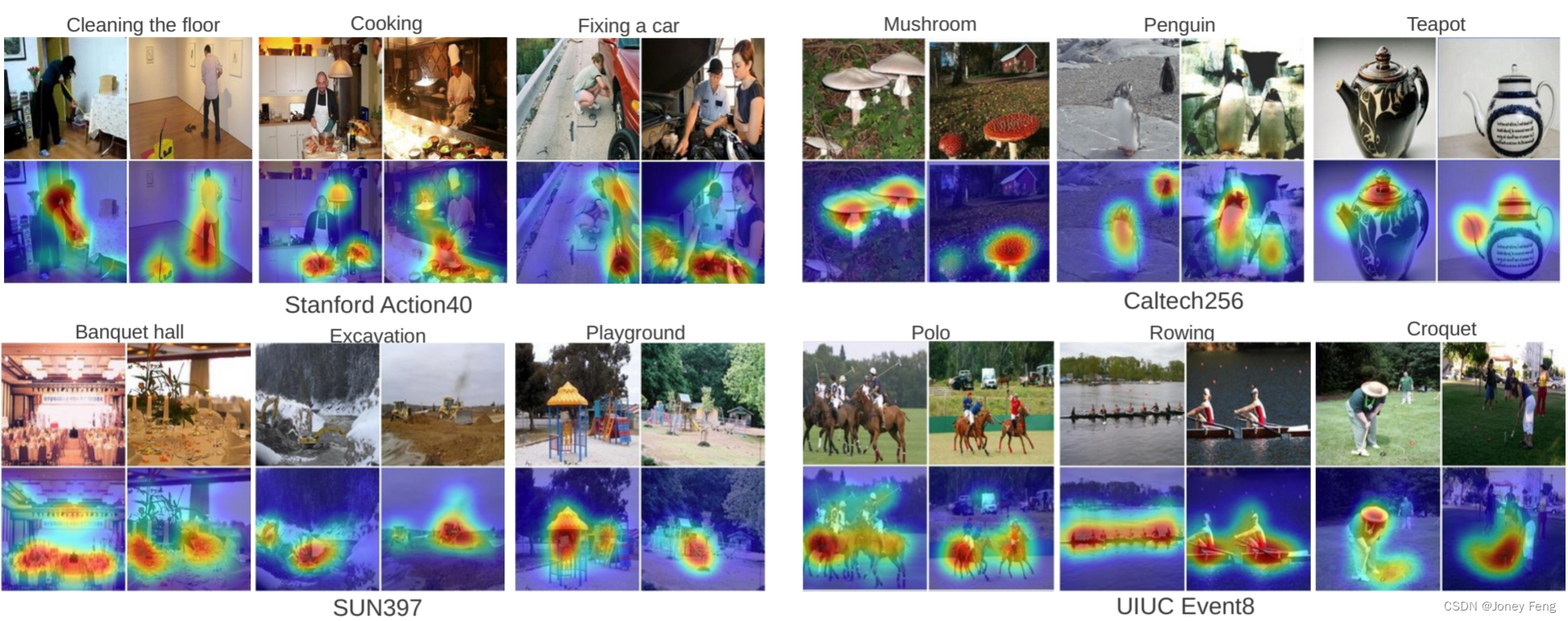
图8. 使用我们的GoogLeNet-GAP深度特征进行通用判别定位。我们展示了来自4个数据集的3个类别中的2个图像,并在它们下方显示了它们的类别激活图。我们观察到图像的判别区域经常被突出显示,例如,在斯坦福行动40中,拖把被定位用于清洁地板,而在烹饪中,平底锅和碗被定位,类似的观察也适用于其他数据集。这证明了我们的深度特征的通用定位能力。

图9. 两个场景类别的信息对象。对于餐厅和浴室类别,我们展示了原始图像的示例(顶部),并列出了该场景类别中出现频率最高的6个对象及其对应的出现频率。底部显示了CAMs以及与高激活区域最频繁重叠的6个对象的列表。
图10. 从弱标注图像中学到的概念的信息区域。尽管这些概念相当抽象,但我们的GoogLeNet-GAP网络能够对其进行适当的定位。
图11. 学习一个弱监督的文本检测器。即使我们的网络没有使用文本或任何边界框注释进行训练,但文本仍然能够准确地在图像上被检测到。
图12. 在视觉问答中,展示了对于预测的答案类别而突出显示的图像区域的示例。
5.可视化特定类别的单元
Zhou等人[34]已经表明,CNN的各个层的卷积单元充当视觉概念检测器,识别从低级概念(如纹理或材料)到高级概念(如物体或场景)的概念。随着网络的深入,单元的区分能力越来越强。然而,在许多网络中存在全连接层,很难确定不同单元对于识别不同类别的重要性。在这里,通过使用GAP和排序的softmax权重,我们可以直接可视化对于给定类别最具有区分性的单元。我们称之为CNN的类特定单元。
图13展示了在用于物体识别的ILSVRC数据集(顶部)和用于场景识别的Places数据库(底部)上训练的AlexNet∗-GAP的类特定单元。我们遵循与[34]类似的程序,估计最终卷积层中每个单元的感受野并分割其顶部激活图像。然后,我们简单地使用softmax权重对给定类别的单元进行排序。从图中,我们可以确定对于分类最具有区分性的物体部分以及哪些单元检测到了这些部分。例如,检测到狗脸和身体毛发的单元对于拉克兰梗是重要的;检测到沙发、桌子和壁炉的单元对于客厅是重要的。因此,我们可以推断CNN实际上学习了一组单词,其中每个单词都是一个具有区分性的类特定单元。这些类特定单元的组合指导CNN对每个图像进行分类。

图13. 分别为在ImageNet(顶部)和Places(底部)上训练的AlexNet*-GAP的类特定单元的可视化。每个数据集显示了三个选定类别的前三个单元。每一行显示了由该单元的感受野分割的最可信图像。例如,对于用于场景识别的网络,检测到黑板、椅子和桌子的单元对于教室的分类是重要的。
6.结论
在这项工作中,我们提出了一种通用技术,称为类别激活映射(CAM),用于具有全局平均池化的CNN。这使得经过分类训练的CNN能够学习进行对象定位,而无需使用任何边界框注释。类别激活图允许我们在任何给定图像上可视化预测的类别分数,突出显示CNN检测到的具有区分性的对象部分。我们在ILSVRC基准测试中评估了我们的方法在弱监督对象定位上的效果,证明我们的全局平均池化CNN能够进行准确的对象定位。此外,我们还证明了CAM定位技术可以推广到其他视觉识别任务,即我们的技术可以产生通用的可定位的深度特征,可以帮助其他研究人员理解CNN在其任务中使用的鉴别基础。











![P3611 [USACO17JAN] Cow Dance Show S](https://img-blog.csdnimg.cn/9a99efbf48524136ac8f270ebcdb519a.png)
