文章目录
- 一 需求
- 二 流程分析
- 1 登录
- 2 获取书架的数据
- 三 完整代码
一 需求
通过处理cookie来访问自己的书架资源。
二 流程分析
带着cookie,去请求url,得到书架内容。
要将上述的两个操作连续起来,可以使用session。
session是一连串的请求,这个过程中不会丢失cookie。
1 登录
首先需要获取登录的数据信息。
先进入要访问的网站
然后按 F12 ,进入检查的页面。
进行个人的用户密码的输入。
此时查看“检查”,找到login,获取我们想要的 URL、请求方式、用户名和密码信息
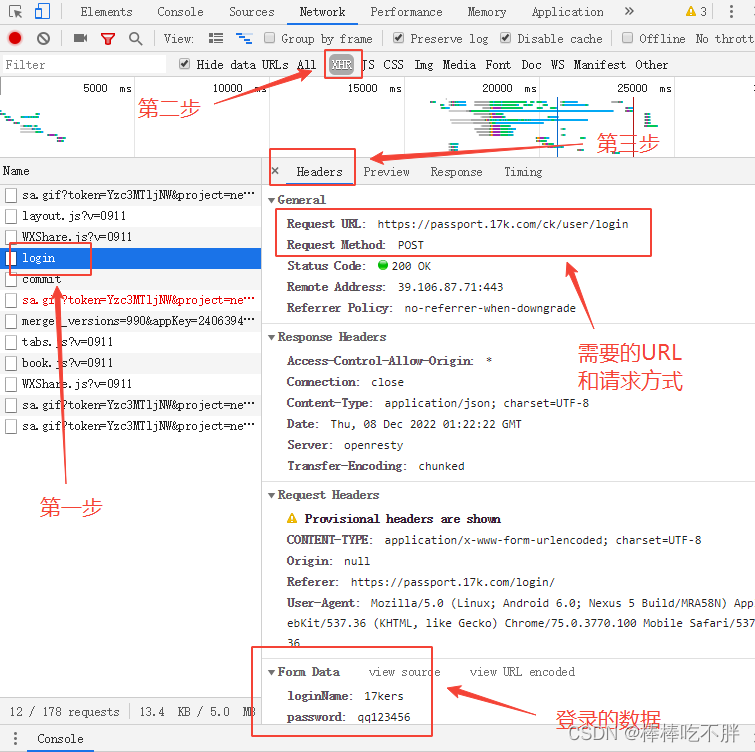
然后执行代码,获取资源。
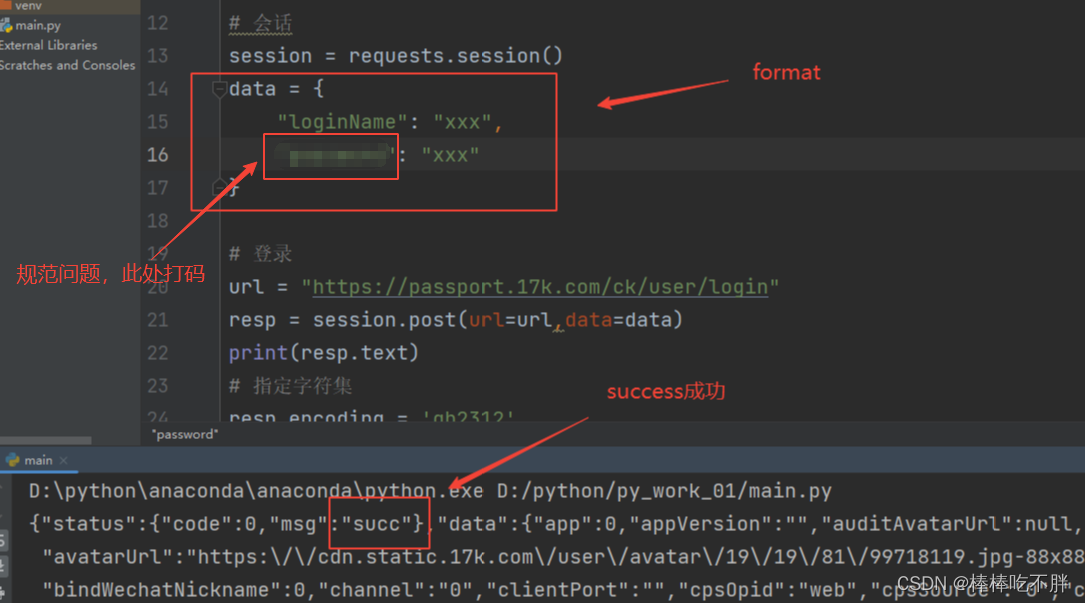
上述的xxx部分,请填写自己的信息。
2 获取书架的数据
先进行“检查”,然后刷新页面的源代码。
根据下图标注,找到自己书架上的书。
接着返回headers,获取我们写代码时需要的参数。
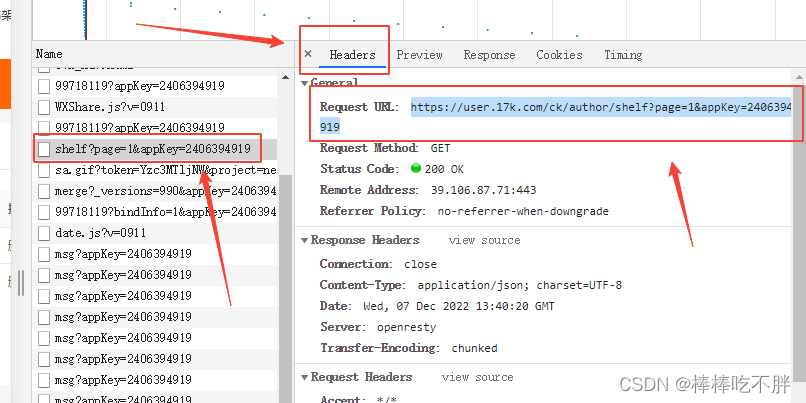
接着使用session.get()来进行访问刚才的session。
注意,这里不能使用requests.get(),否则就是一个新的页面访问请求。
三 完整代码
# -*- coding: gb2312 -*-
import requests
import sys
import io
# 改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb2312')
# 会话
session = requests.session()
data = {
"loginName": "用户名",
"mima(此处请修改)": "mima"
}
# 1.登录
url = "https://passport.17k.com/ck/user/login"
resp = session.post(url=url,data=data)
# print(resp.cookies)
# 指定字符集
resp.encoding = 'gb2312'
# 2.拿书架上的数据
# 拿刚才的session中得到的cookie
resp = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919")
# 输出结果
print(resp.json())
# 关闭请求响应的连接
resp.close()






![[附源码]计算机毕业设计基于协同过滤的资讯推送平台Springboot程序](https://img-blog.csdnimg.cn/7f9c151cc99e4115ac3f2a411b09a248.png)