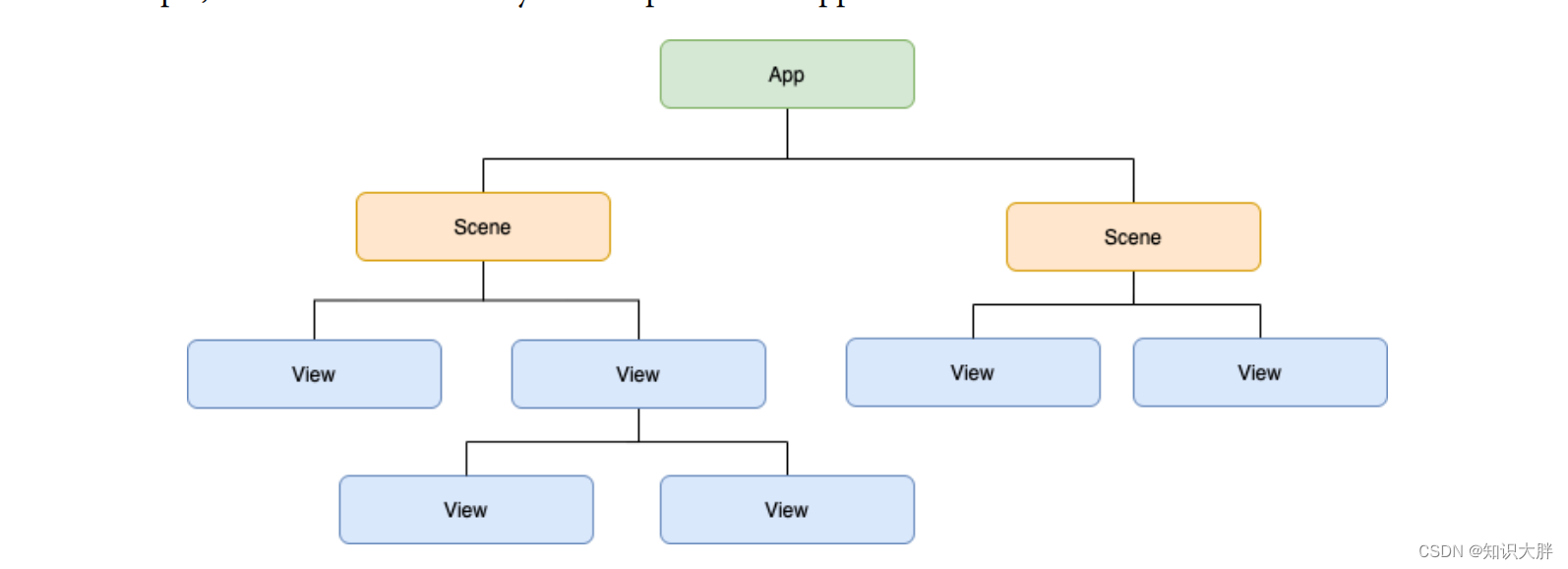
GRU是LSTM的简化结构,而LSTM是RNN的优化结构。
1.RNN
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息.
将网络的输出保存在一个记忆单元中,这个记忆单元的输出经过权重参数调整后和下一次的输入一起进入神经网络中。区别于传统DPN和CNN,RNN除了第一轮输入输出以外,每轮输入输出都保有上一轮的信息(上一轮输出经过参数调整后又变为本轮的输入),其输出结果与输入信息顺序有关。
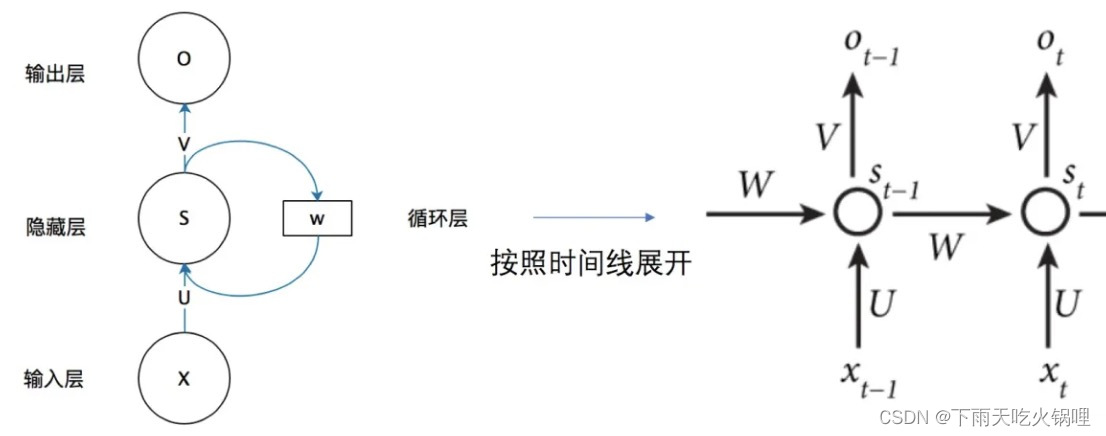
W其实是每个时间点之间的权重矩阵,RNN之所以可以解决序列问题,是因为它可以记住每一时刻的信息,每一时刻的隐藏层不仅由该时刻的输入层决定,还由上一时刻的隐藏层决定。
2.Long short-term memory
RNN每一时刻的隐藏状态都不仅由该时刻的输入决定,还取决于上一时刻的隐藏层的值,如果一个句子很长,到句子末尾时,它将记不住这个句子的开头的内容详细内容。
RNN什么信息它都存下来,因为它没有挑选的能力,而LSTM不一样,它会选择性的存储信息,因为它能力强,它有门控装置,它可以尽情的选择。
LSTM多了三个Gate:
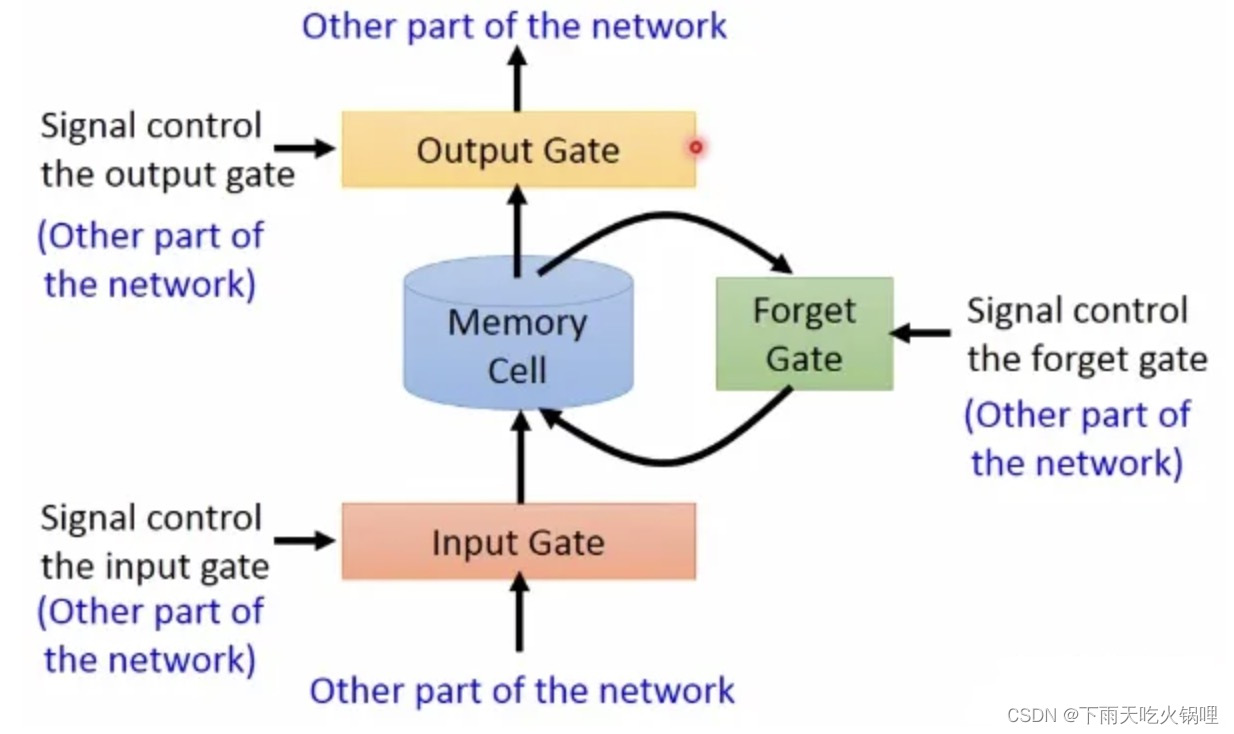
- Input Gate:输入门,在每一时刻从输入层输入的信息会首先经过输入门,输入门的开关会决定这一时刻是否会有信息输入到Memory Cell。
- Output Gate:输出门,每一时刻是否有信息从Memory Cell输出取决于这一道门。
- Forget Gate:遗忘门,每一时刻Memory Cell里的值都会经历一个是否被遗忘的过程,就是由该门控制的,如果打卡,那么将会把Memory Cell里的值清除,也就是遗忘掉。

3.GRU(Gated Recurrent Unit, LSTM变体)
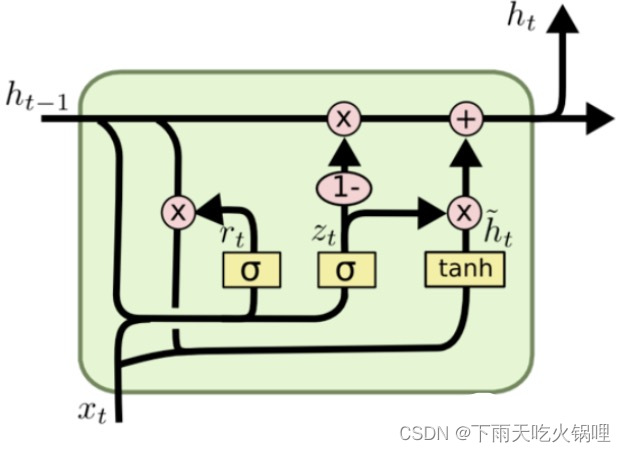
GRU比LSTM复杂程度低,去掉了每一步公式的偏置值b,也将LSTM的细胞态(长期记忆)Ct和上轮输出St-1两个变量整合成h,将LSTM的遗忘和输入门两个门整合成了更新门单独一个门,大大简化了LSTM的计算量,而且大体保留了LSTM的功能,使其既能不大影响LSTM准确度的同时,还对LSTM进行了精简。






![[附源码]计算机毕业设计基于协同过滤的资讯推送平台Springboot程序](https://img-blog.csdnimg.cn/7f9c151cc99e4115ac3f2a411b09a248.png)