原文地址:https://zhanghan.xyz/posts/22426/
文章目录
- 一、摘要
- 二、数据集
- 三、相关环境
- 四、功能展示
- 1.系统主界面
- 2.中文分词
- 3.命名实体识别
- 4.文本分类
- 5.文本聚类
- 6.其他界面
- 五、源码链接
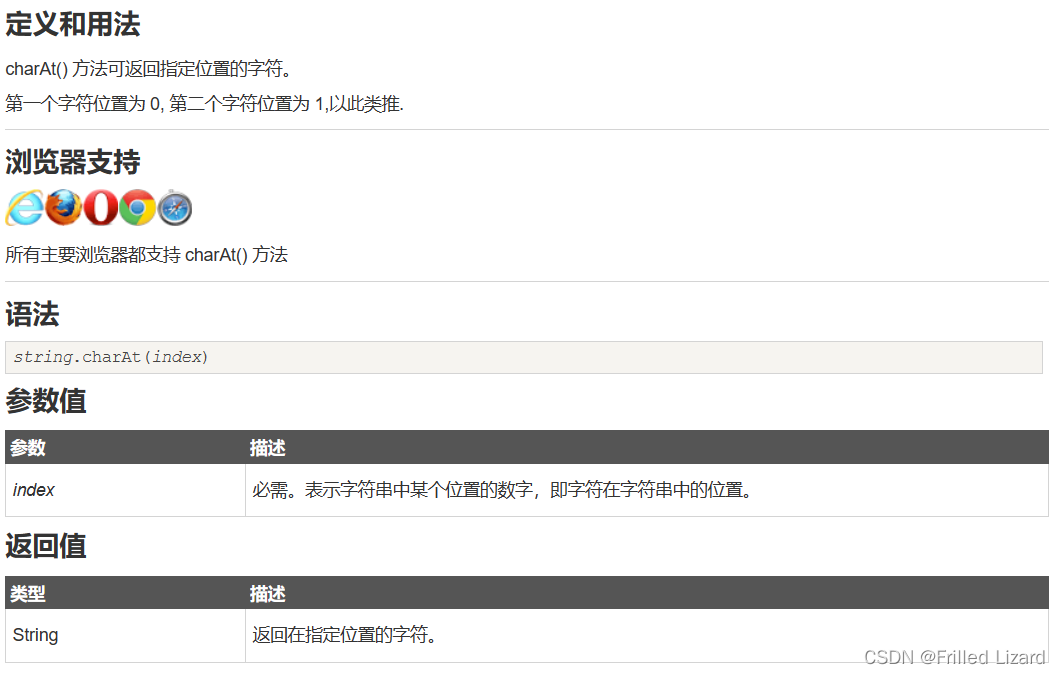
一、摘要
将自然语言处理课程设计中实现的模型集成到自然语言处理应用程序中,作为系统的功能模块。集成的模型包括分词、命名实体识别、文本分类、文本聚类等方面的内容。该综合程序使用PyQT5和Qt Designer进行界面开发。PyQT5是Python语言的Qt框架的Python绑定库,可以快速、方便地开发GUI应用程序。Qt Designer是Qt的可视化界面设计工具,可以帮助开发人员快速创建用户界面。
二、数据集
训练数据:我们使用MSR语料库,以及搜狗文本分类语料库,人民日报1998语料库等。
测试数据:使用搜狗实验室的新闻数据集。
三、相关环境
Python3.7和JDK1.8
Pyqt5 + Qtdesigner
四、功能展示
1.系统主界面

系统主界面主要由三部分构成:
① 功能选择区:有四个功能选择按钮,可以点击选择功能,包括分词、命名实体识别、文本分类、文本聚类四个功能,选择功能后子界面区也会跟随功能变化。
② 子界面区:子界面区和功能一一对应,包括分词、命名实体识别、文本分类、文本聚类四个子界面,子界面根据功能不同布局和组件也各不相同,后续会详细介绍。
③ 日志输出区:这里会显示部分操作日志,用来提示使用者。
2.中文分词
这里我们使用的是隐马尔可夫模型进行中文分词,隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。
点击选择中文分词界面之后,系统界面如下所示:

可以在字体设置中选择下方显示的字体类型,在输入框输入需要进行分词的文本之后,点击运行按钮,运行完成之后可以在下方分词结果的输出框中进行查看。

3.命名实体识别
这部分我们一共部署了以下三种模型:
① 基于隐马尔可夫模型序列标注的命名实体识别
基于隐马尔可夫模型(Hidden Markov Model,HMM)序列标注的命名实体识别是一种常见的命名实体识别方法。HMM本质上是一种生成式模型,可以通过对文本序列的统计分析来学习实体的上下文信息,并通过序列标注方法对实体进行识别。
② 基于感知机序列标注的命名实体识别
基于感知机序列标注的命名实体识别是一种常见的命名实体识别方法,其主要思想是通过机器学习算法学习实体的特征,并根据这些特征对文本中的实体进行识别。感知机是一种二分类模型,可以用于处理输入向量和输出标签之间的关系,它可以通过迭代算法不断调整权值和阈值,最终得到一个最优的分类模型。
③ 基于条件随机场序列标注的命名实体识别
基于条件随机场(Conditional Random Field, CRF)序列标注的命名实体识别是一种常见的命名实体识别方法。CRF是一种判别式模型,可以利用输入特征和输出标签之间的关系来学习实体的上下文信息,从而实现对文本中实体的识别和标注。
点击选择命名实体识别界面之后,系统界面如下所示:

可以在子界面中选择使用的模型,在输入框输入需要进行命名实体识别的文本之后,点击运行按钮,运行完成之后可以在下方命名实体识别结果的输出框中进行查看。

4.文本分类
这部分我们一共部署了以下两种模型:
① 朴素贝叶斯分类器
在各种各样的分类器中,朴素贝叶斯法( naive Bayes)可算是最简单常用的一种生成式模型。朴素贝叶斯法基于贝叶斯定理将联合概率转化为条件概率,然后利用特征条件独立假设简化条件概率的计算。
② 线性支持向量机进行文本分类
支持向量机( Support Vector Machine, SVM)是一种二分类模型,其学习策略在于如何找出一个决策边界,使得边界到正负样本的最小距离都最远。这种策略使得支持向量机有别于感知机,能够找到一个更加稳健的决策边界。支持向量机最简单的形式为线性支持向量机,其决策边界为一个超平面,适用于线性可分数据集。
点击选择文本分类界面之后,系统界面如下所示:

可以在子界面中选择使用的模型,在输入框输入需要进行文本分类的文本之后,点击运行按钮,运行完成之后,下方的文本分类结果块会变成绿色,测试结果如下所示。
5.文本聚类
这部分我们一共部署了以下两种算法:
① k-means实现文本聚类
首先加载停用词表和文本数据,然后使用jieba库对每个文本进行分词,并去除停用词和低频词。接着,它使用sklearn库中的TfidfVectorizer类对每个文本的词袋进行向量化,得到一个 TF-IDF 矩阵。最后,它使用sklearn库中的KMeans类对 TF-IDF 矩阵进行聚类,得到每个文本所属的聚类,并输出结果。
② 基于层次聚类算法(Agglomerative Clustering)
基于层次聚类算法使用了sklearn库中的Agglomerative
Clustering类来实现层次聚类算法。它的参数n_clusters指定聚类数目,linkage指定链接方式,这里使用的是 ‘ward’ 链接方式,是一种基于方差的链接方式。
点击选择文本聚类界面之后,系统界面如下所示:

可以在子界面中选择使用的分类器,在输入聚类数量之后,点击上传文件,选择需要进行文本聚类的txt文件,txt文件中包含多条文本数据,点击运行按钮进行聚类,运行完成之后,右上方会显示多个聚类结果的txt文件列表,点击文件名称可以在下方进行查看,左下方会显示不同类别的关键词,运行示例如下:

6.其他界面


五、源码链接
https://gitee.com/zhgn2020814/nlp-Applications.git