索引的代价
空间上的代价
每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用 16KB 的存储空间,一棵很大的B+树由许多数据页组成,那就是很大的一片存储空间。
时间上的代价
每次对表中的数据进行增、删、改操作的时候,都需要去修改各个B+树索引。而且,B+树每层节点都是按照索引列的值,从小到大的顺序去排列,从而构成了双向链表。无论用户记录还是目录项记录,都是按照索引列的值从小到大的顺序形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,索引存储引擎需要额外的时间进行一些记录移位、页面分裂、页面回收等操作来维护好节点和操作的顺序。如果我们建立了许多索引,每个索引对应的B+树都要进行相关的维护操作,会非常影响性能。
MySQL数据结构选择的合理性
Hash
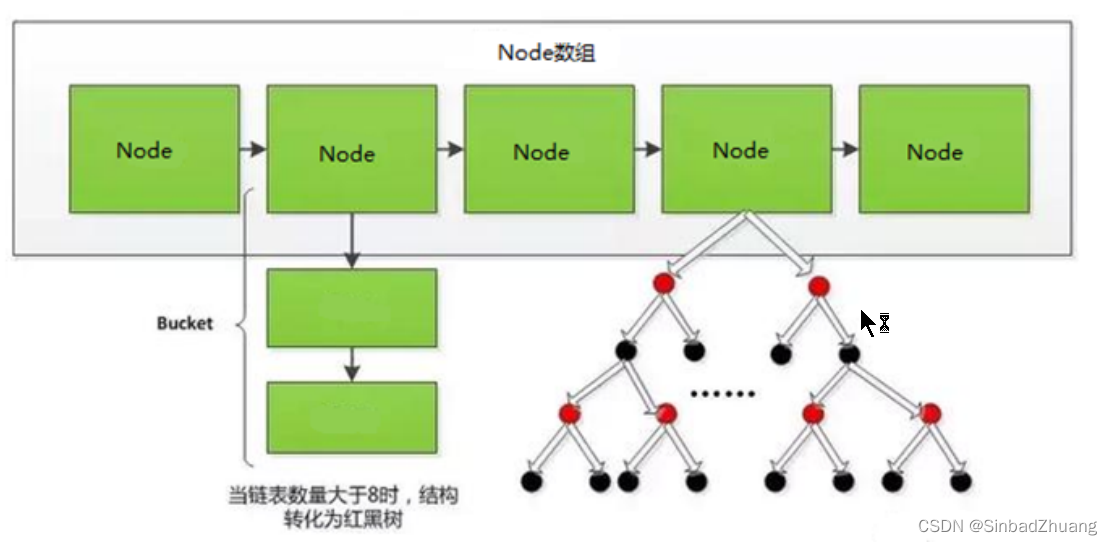
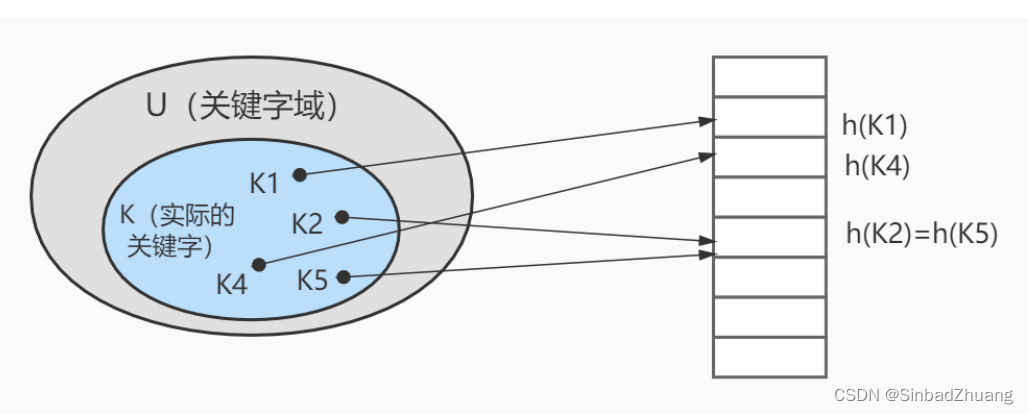 hash函数有可能会将两个不同的关键字映射到相同的位置,称之为碰撞。通常采用链接法来解决。
hash函数有可能会将两个不同的关键字映射到相同的位置,称之为碰撞。通常采用链接法来解决。
 Hash索引适用的存储引擎
Hash索引适用的存储引擎
- MyISAM:不支持
- InnoDB:不支持
- Memory:支持
自适应 hash
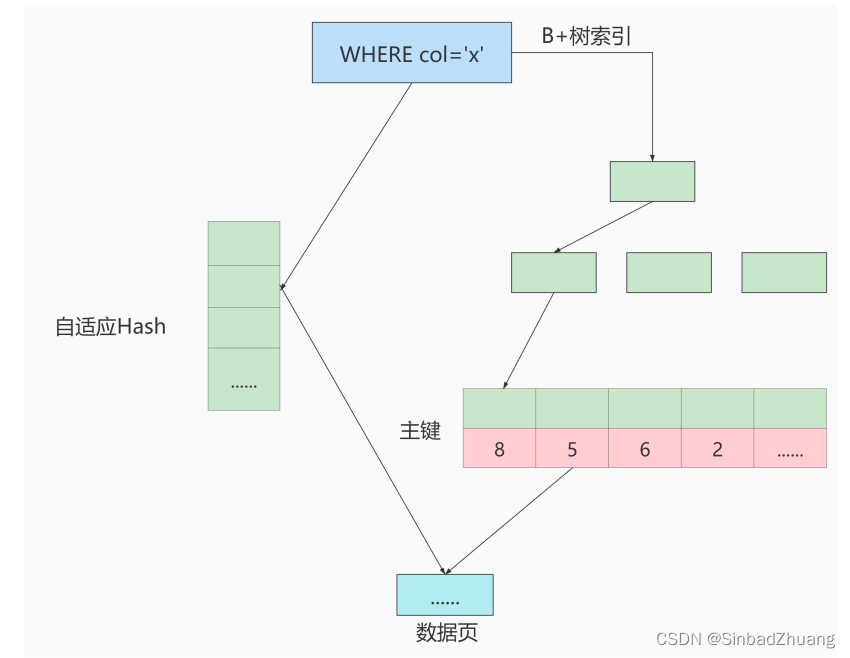
自适应hash索引的目的是加速根据SQL查询条件定位到叶子节点,尤其是当B+树特别深的时候,通过自适应hash索引可以明显提高数据的查询效率。
查看是否开启了自适应索引
show variables like '%adaptive_hash_index';
二叉搜索树
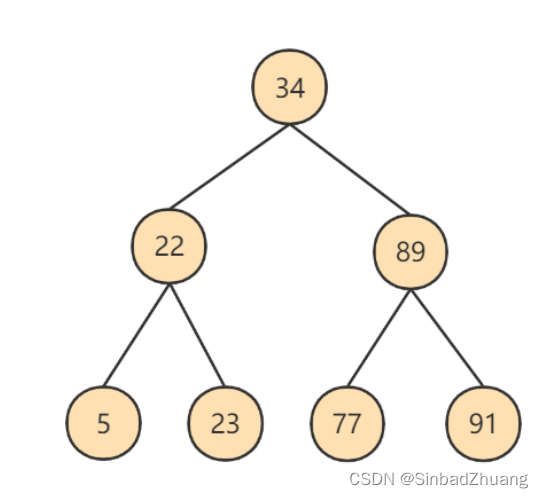
如果采用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。
在极端的情况下,二叉搜索树会产生如下结构:

为了提高查询效率,需要减少磁盘IO的次数,进一步就需要减少树的高度。所以,树越“矮胖”越好,树的每层分叉越多越好。
AVL树
 将二叉树改为M叉树,当M=3时,结构如下
将二叉树改为M叉树,当M=3时,结构如下
 B 树相比于平衡二叉树来说磁盘 I/O 操作要少 ,在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。
B 树相比于平衡二叉树来说磁盘 I/O 操作要少 ,在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。
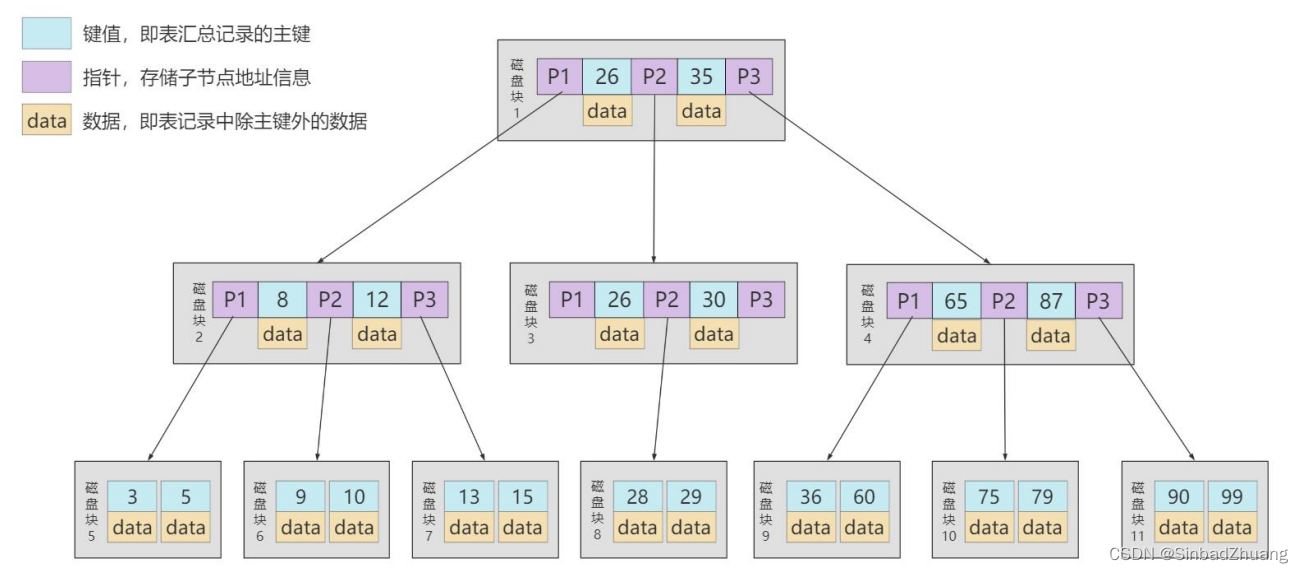
B+Tree
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数+1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非叶子节点既保存索引,也保存数据记录 。
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树。它们各有自己的应用场景。
R树
R-Tree在MySQL很少使用,仅支持 geometry数据类型 ,支持该类型的存储引擎只有myisam、bdb、innodb、ndb、archive几种。