直接看paper云里雾里,一些推荐的讲解:
The Annotated Diffusion Model
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
生成扩散模型漫谈(二):DDPM = 自回归式VAE
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
1、目的
已知确定的forward / diffusion过程:训练图像,逐步加噪声,最终得到高斯噪声图像
求解reverse过程:采样高斯噪声图像,逐步去噪,最终得到生成的图像
其中, ~
的尺寸均一致
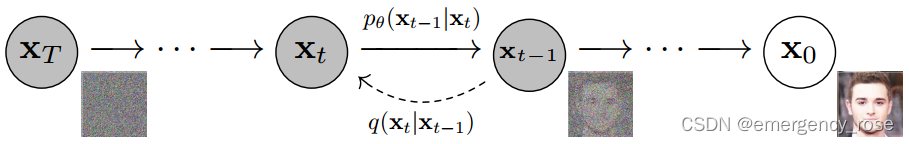
为什么不直接一步到位?类比建楼和拆楼过程。我们想要把建筑原材料建设成高楼大厦是很难的,那么不妨考虑将高楼大厦一步步拆为砖瓦水泥,然后逆向学习拆楼的一小步过程,从而一步步建楼。当然DDPM是建立在严格数学推导的基础之上的。

2、建模
1)分布
![]()
![]()
2)forward
![]()
重参数化后,有
该式的两个重要特性:马尔可夫过程,且系数平方和为1。基于这两点,经推导可得重要结论:
![]()
其中,![]()
重参数化后,有:
![]()
![]()
![]() ......................................................(1)
......................................................(1)
注:要保证经过T步后,,此时
3)reverse
![]()
经推导可得重要性质:
![]()
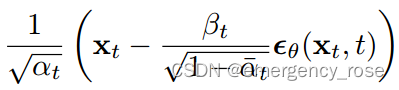 ............................................(2)
............................................(2)
本文固定了forward和reverse过程中的方差
3、训练过程
我们的目标是已知输入,去预测
。网络直接学习这样的映射关系比较困难,可以通过“输入
-> 预测
-> 根据公式(2)得到
-> 从N(
,
)中采样出
”的方式来进行
1)Training
已知样本,随机取1~T中的一个时间t,可以根据公式(1)采样出
,同时采样的
作为网络训练的标答

2)Sampling
从高斯噪声开始逐步采样至

注:训练数据需要线性放缩到[-1, 1]
4、网络结构
1)U-Net
2)group normalization
3)在16 x 16分辨率的特征图上使用self-attention
4)不同time共享一套网络结构和网络参数。time经过Transformer sinusoidal position embedding输入网络