扩散模型已经成为一种新的生成高质量样本的生成模型,也被作为有效的逆问题求解器。然而,由于生成过程仍然处于相同的高维(即与数据维相同)空间中,极高的内存和计算成本导致模型尚未扩展到3D逆问题。在本文中,作者将传统的基于模型的迭代重建的思想与扩散模型结合,从而产生了一种高效的方法来提高3D医学图像重建任务,如稀疏视图断层扫描(sparse-view tomography),有限角度断层扫描(limited angle tomography),压缩感知MRI(compressed sensing MRI),这些任务从预训练的2D扩散模型受益。从本质上讲,作者提出,在测试时的剩余方向上使用基于模型的先验来增强2D扩散先验,这样就可以在所有维度上实现重建。该方法可以在单个商业GPU上运行,并建立了新的SOTA,即使所提出的方法在最极端的情况下(例如2-view 3D断层扫描)也可以执行高保真度和准确性的重建。作者进一步发现,该方法的泛化能力惊人地高,可以用来重建与训练数据集完全不同的volumes。
来自:Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
工程地址:https://github.com/HJ-harry/DiffusionMBIR
目录
- 医学影像概念
- 背景概述
- 题外话:MRI不能代替CT
- 建模基础
- 基于模型的迭代重建MBIR
- Score-based diffusion models
- 3D扩散
- 利用扩散模型求解逆问题
- DiffusionMBIR
- 主要思想
- 算法步骤
- 快速实现
- 实验设置
医学影像概念
稀疏视图断层扫描、有限角度断层扫描和压缩感知MRI都是医学影像领域中常见的图像重建技术,用于从有限的采样数据中重建高质量的图像。这些方法可以有效地减少图像采集时间和减少辐射剂量,同时保持较好的图像质量。
-
稀疏视图断层扫描(Sparse-View CT Scan,sparse-view tomography):
在CT(计算机断层扫描,Computed Tomography)中,为了获得完整的三维图像,通常需要对物体进行多次旋转扫描,从不同角度获取大量的投影数据。稀疏视图断层扫描是一种优化技术,它通过只使用有限的视图角度来采集投影数据,然后使用稀疏重建算法从这些有限的数据中重建出高质量的图像。这样可以大大减少扫描时间,降低辐射剂量,同时保持图像质量。 -
有限角度断层扫描(Limited-Angle CT Scan,limited angle tomography):
有限角度断层扫描是一种特殊的CT扫描技术,它在图像采集过程中仅使用有限的角度范围。与传统的全角度扫描相比,有限角度扫描可以显著减少扫描时间和辐射剂量。然而,由于缺乏完整的投影数据,重建图像可能会出现伪影和模糊。为了克服这些问题,需要采用先进的图像重建算法,如稀疏重建和深度学习方法,来从有限的数据中恢复高质量的图像。 -
压缩感知MRI(Compressed Sensing MRI,compressed sensing MRI):
MRI(磁共振成像,Magnetic Resonance Imaging)是一种常用的医学影像技术,它能够产生高质量的图像。然而,MRI采集通常需要较长的扫描时间,这对于一些特定应用场景可能是不可接受的。压缩感知MRI是一种通过减少采样数据并采用稀疏重建技术从有限的数据中恢复高质量图像的方法。压缩感知理论认为,信号通常是稀疏的,即在某种表示下,信号的大部分系数都是零。因此,通过采用非均匀采样和压缩感知重建算法,可以在不损失图像质量的情况下大大减少采样时间,从而提高MRI的效率。
总的来说,这些技术都是在医学影像领域中用于优化图像采集过程、减少扫描时间和辐射剂量,并保持图像质量的重要方法。它们都涉及到先进的数学和图像重建算法,以实现从有限数据中恢复高质量图像的目标。
压缩感知MRI是一种利用压缩感知理论来提高MRI图像采集效率的技术。MRI是一种非侵入性的医学影像技术,用于观察人体内部的结构和组织。传统的MRI图像采集需要大量的采样数据,通常需要数分钟到数十分钟的扫描时间。
压缩感知MRI的目标是通过采用稀疏表示和随机采样技术,以更少的采样数据来恢复高质量的MRI图像。这在医学影像领域具有重要意义,因为减少扫描时间可以减轻患者的不适,并提高MRI设备的利用效率。
压缩感知MRI的关键思想是利用信号在某种表示下具有稀疏性的特点。在MRI图像中,许多图像系数在某种变换域下是接近于零的,即图像是稀疏的。通过随机采样少量数据,并使用稀疏表示算法来恢复缺失的数据,可以重建出高质量的MRI图像。
K-space与MRI:
- K空间是MRI图像的频域表示,它是MRI原始数据的一种表现形式。在MRI采集过程中,通过在空间中的不同位置收集一系列的信号,可以得到一个包含复数数值的K空间。K空间的中心对应着低频信息,而外围则对应着高频信息。在K空间中,采样点越密集,对应的空间中的位置越靠近中心,频率越低;反之,采样点越稀疏,对应的位置越靠近外围,频率越高。
- 在传统的MRI采集过程中,通常需要在K空间中密集地采样,以获取完整的频谱信息,并用于重建高质量的MRI图像。而压缩感知MRI则利用了K空间中的稀疏性,通过在K空间中进行随机稀疏采样,只采集K空间的一部分数据,然后利用压缩感知算法来重建完整的MRI图像。这样可以在保持图像质量的前提下,显著减少MRI图像采集的时间,从而提高了MRI图像采集的效率。
基于CT的重建与NeRF相关(MedNeRF: Medical Neural Radiance Fields for Reconstructing 3D-aware CT-Projections from a Single X-ray),但NeRF不适用于基于MRI的重建,该文的扩散模型则可以提高CT和MRI重建的质量。
背景概述
扩散模型通过学习对数密度的梯度( ∇ x l o g p d a t a ( x ) \nabla_{x}log\thinspace p_{data}(x) ∇xlogpdata(x),score function)来隐式地学习数据分布,而数据分布可以用于生成样本。最近的研究表明,扩散模型可以生成高质量样本,训练起来也很鲁棒。因为它仅仅相当于在去噪问题上最小化均方误差损失。众所周知,扩散模型比其他流行的生成模型更健壮,例如生成对抗网络。此外,可以使用预训练的扩散模型以无监督的方式解决逆问题。这样的策略在很多情况下都是非常有效的,经常在每项任务上建立新的SOTA。具体来说,目前已经提出了在稀疏视图计算机断层扫描(SV-CT)、压缩感知MRI(CS-MRI)、超分辨率(super-resolution)、图像绘制(inpainting)等许多领域的应用。
然而,迄今为止考虑的所有方法都集中在2D成像情况下。这主要是由于生成样本本身的高维性质。具体来说,扩散模型通过从纯噪声开始,迭代去噪数据直到得到干净图像。因此,生成过程涉及与数据保持相同的维度,当试图将数据维度缩放到3D时,这是令人望而却步的。还应该注意,训练3D扩散模型相当于学习数据的3D先验。这在两个方面是不可取的:
- 首先,该模型需要大量数据,因此训练一个3D模型通常需要数千个volumes数据。
- 其次,先前的方法会变得很复杂:当涉及到动态成像或3D成像时,利用时间或者空间相关性是标准做法。如果天真地将问题建模为3D将错过利用这些信息的机会。
另一种更为完善的解决3D逆问题的方法是基于模型的迭代重建(MBIR,model-based iterative reconstruction),这个问题被形式化为一个由数据一致性项和正则化项构成的加权最小二乘优化问题(WLS,weighted least squares)。在该领域最广泛认可的正则化之一是总变差(TV,total variation)惩罚,它以其有趣的特性而闻名:在保持边缘的同时施加平滑性。虽然TV先验已经被广泛探索,但众所周知,它落后于现代机器学习实践的数据驱动先验,因为该函数过于简单,无法完全模拟图像的“样子”。
作者提出DiffusionMBIR,将MBIR优化策略纳入扩散采样步骤,以便仅在z方向上增强数据驱动先验和传统TV先验。通过SV-CT、LA-CT(有限角度CT)和CS-MRI上进行大量实验来验证该方法的有效性:该方法比目前基于扩散模型的逆问题求解器表现出一致的改进,并且在所有任务上都表现出很强的性能。代表性结果见图1,逆问题概念见图2。
简而言之,DiffusionMBIR主要贡献是设计了一种基于扩散模型的重建方法:
- 使用体素表示。
- 内存效率高,可以将求解器扩展到更高的维度(即 > 25 6 3 >256^{3} >2563)。
- 不需要很多数据,可以用少于10个3D volumes进行训练。

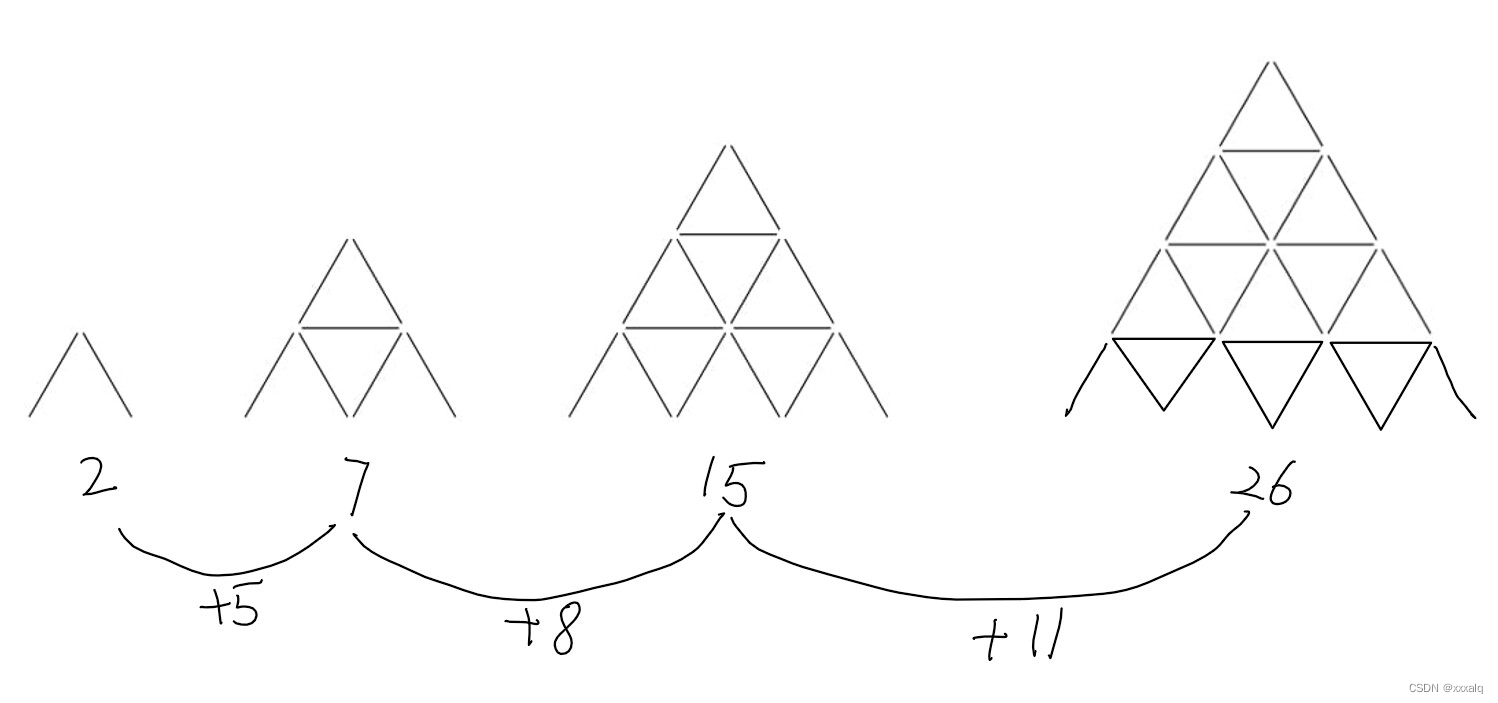
- 图1:使用DiffusionMBIR进行3D重建的结果。第一行:测量,第二行:DiffusionMBIR,第三行:ground truth。黄色插图:测量过程。Sparse-view tomography:8-view测量,Limited-angle tomography:[0-180]度测量中的[0-90]度,Compressed-sensing MRI:×2加速的1D均匀子采样。In-distribution:测试数据与训练数据分布一致,Out-of-distribution:测试数据与训练数据分布不一致。
在1D uniform sub-sampling of ×2 acceleration中,采样点是均匀分布在K空间的一维方向上的,采样间隔为原始采样间隔的两倍。这意味着只采集原始K空间中每隔两个点的数据,然后利用压缩感知算法来重建完整的K空间,从而得到压缩感知重建的MRI图像。

- 图2:三个任务的测量过程可视化:a.图4的有限角度CT测量,b.图3,6,7的稀疏视图CT测量,c.图8的CS-MRI测量。
题外话:MRI不能代替CT
在门诊经常有患者拿MRI片子就诊,给医生看完以后,医生建议再做一个CT检查,有患者就会疑惑:不是说了MRI最清楚了吗,为什么我还要做CT? 病人会觉得MRI已经足够了。其实,CT和MRI的侧重点不一样,相互之间并不能完全替代,举例如下:
- 患者的MRI(左)看到椎体后方突出物进入椎管,容易被诊断为是一个椎间盘突出,完善CT(右)检查发现是一个密度不均匀的占位病变,原来是在T6/7平面的椎间隙后缘长了肿瘤(骨软骨瘤)。

建模基础
基于模型的迭代重建MBIR
考虑成像系统(比如CT或MRI)的线性forward模型: y = A x + n y=Ax+n y=Ax+n其中, y ∈ R m y\in R^{m} y∈Rm表示测量(比如sinogram,k-space), x ∈ R n x\in R^{n} x∈Rn为所希望重建的图像, A ∈ R m × n A\in R^{m\times n} A∈Rm×n为离散的变换矩阵(比如Radon,Fourier), n n n为系统中的测量噪声。
从测量 y y y估计未知图像 x x x的逆问题的标准方法是执行以下正则化重建: x ∗ = a r g m i n x 1 2 ∣ ∣ y − A x ∣ ∣ 2 2 + R ( x ) x^{*}=argmin_{x}\frac{1}{2}||y-Ax||_{2}^{2}+R(x) x∗=argminx21∣∣y−Ax∣∣22+R(x)其中 R R R是 x x x的合适正则化,例如,某个变换域中的稀疏性。一个广泛使用的函数是TV惩罚, R ( x ) = ∣ ∣ D x ∣ ∣ 2 , 1 R(x)=||Dx||_{2,1} R(x)=∣∣Dx∣∣2,1,其中 D = [ D x , D y , D z ] T D=[D_{x},D_{y},D_{z}]^{T} D=[Dx,Dy,Dz]T计算每个轴的有限差。上式的最小化可以通过鲁棒优化算法来实现,例如快速迭代软阈值算法(FISTA)或ADMM。
Score-based diffusion models
Score-based扩散模型是一个生成模型,它将生成过程定义为与数据施加噪声过程相反的过程。特别是,考虑一个随机过程 { x ( t ) = x t } , t ∈ [ 0 , 1 ] \left\{x(t)=x_{t}\right\},t\in[0,1] {x(t)=xt},t∈[0,1],我们引入时间变量 t t t表示随机变量的演化。定义 p ( x 0 ) = p d a t a ( x ) p(x_{0})=p_{data}(x) p(x0)=pdata(x),即数据分布, p ( x T ) p(x_{T}) p(xT)近似为高斯分布。演化可以用下面的随机微分方程形式化: d x = f ( x , t ) d t + g ( t ) d w dx=f(x,t)dt+g(t)dw dx=f(x,t)dt+g(t)dw其中, f ( x , t ) : R n × 1 → R n f(x,t):R^{n\times1}\rightarrow R^{n} f(x,t):Rn×1→Rn为漂移函数, g ( t ) : R → R g(t):R\rightarrow R g(t):R→R为标量扩散函数, w w w为 n n n-dim的标准布朗运动。令 f ( x , t ) = 0 f(x,t)=0 f(x,t)=0, g ( t ) = d [ σ 2 ( t ) ] d t g(t)=\sqrt{\frac{d[\sigma^{2}(t)]}{dt}} g(t)=dtd[σ2(t)]。然后,SDE简化为下面的布朗运动: d x = d [ σ 2 ( t ) ] d t d w dx=\sqrt{\frac{d[\sigma^{2}(t)]}{dt}}dw dx=dtd[σ2(t)]dw其中,均值在整个演化过程中保持不变,而高斯噪声将不断添加到 x x x中,最终接近纯高斯噪声,因为噪声项占主导地位。这也是所谓的variance-exploding SDE(VE-SDE,方差爆炸SDE),当在VE-SDE上构造后面的所有方法时,从上式得出以下内容。直接应用Anderson定理可以得到如下的反向SDE: d x = − d [ σ 2 ( t ) ] d t ∇ x t l o g p ( x t ) d t + d [ σ 2 ( t ) ] d t d w ‾ dx=-\frac{d[\sigma^{2}(t)]}{dt}\nabla_{x_{t}}log\thinspace p(x_{t})dt+\sqrt{\frac{d[\sigma^{2}(t)]}{dt}}d\overline{w} dx=−dtd[σ2(t)]∇xtlogp(xt)dt+dtd[σ2(t)]dw其中, d t , d w ‾ dt,d\overline{w} dt,dw为反向时间差,反向标准 n n n-dim布朗运动。上式定义了扩散模型的生成过程,其中的方程可以通过数值积分求解。积分中的关键工作是分数函数score function ∇ x t l o g p ( x t ) \nabla_{x_{t}}log\thinspace p(x_{t}) ∇xtlogp(xt),可以用去噪分数匹配(DSM,denoising score matching)进行训练: m i n θ E t , x ( t ) [ λ ( t ) ∣ ∣ s θ ( x ( t ) , t ) − ∇ x t l o g p ( x ( t ) ∣ x ( 0 ) ) ∣ ∣ 2 2 ] min_{\theta}\mathbb{E}_{t,x(t)}[\lambda(t)||s_{\theta}(x(t),t)-\nabla_{x_{t}}log\thinspace p(x(t)|x(0))||_{2}^{2}] minθEt,x(t)[λ(t)∣∣sθ(x(t),t)−∇xtlogp(x(t)∣x(0))∣∣22]其中, s θ ( x ( t ) , t ) : R n × 1 → R n s_{\theta}(x(t),t):\mathbb{R}^{n\times 1}\rightarrow\mathbb{R}^{n} sθ(x(t),t):Rn×1→Rn是时间依赖的神经网络, λ ( t ) \lambda(t) λ(t)是加权列表。由于 ∇ x t l o g p ( x ( t ) ∣ x ( 0 ) ) \nabla_{x_{t}}log\thinspace p(x(t)|x(0)) ∇xtlogp(x(t)∣x(0))是 x ( t ) x(t) x(t)中 x ( 0 ) x(0) x(0)与噪声方差比例的残差噪声,因此对上式的优化相当于跨多个噪声尺度训练残差去噪器。因此有近似分数函数 approximated score function: d x = − d [ σ 2 ( t ) ] d t s θ ∗ ( x ( t ) , t ) d t + d [ σ 2 ( t ) ] d t d w ‾ dx=-\frac{d[\sigma^{2}(t)]}{dt}s_{\theta^{*}}(x(t),t)dt+\sqrt{\frac{d[\sigma^{2}(t)]}{dt}}d\overline{w} dx=−dtd[σ2(t)]sθ∗(x(t),t)dt+dtd[σ2(t)]dw
3D扩散
生成过程可以表示为上面的式子,在全数据维度 R n \mathbb{R}^{n} Rn中运行。众所周知,3D数据的体素表示非常繁重,并且将数据大小扩展到 6 4 3 64^{3} 643就需要过多的GPU内存。例如,最近一项利用扩散模型进行3D形状重建的研究使用了样本大小为 6 4 3 64^3 643的数据集。其他使用扩散模型进行3D生成的工作通常侧重于更有效的点云表示,其中点云的数量保持在几千个以下,比如2048个。当然,点云表示是有效的,但非常稀疏,不适合医学图像重建,医学图像重建需要准确估计身体内部细节。
有一篇同期的研讨会论文旨在设计一个可以模拟3D体素表示的扩散模型,通过训练latent扩散模型,其中潜在维数相对较小( 20 × 28 × 20 20 × 28 × 20 20×28×20),训练了一个可以建模 160 × 224 × 160 160 × 224 × 160 160×224×160 volume的分数函数。然而,该模型需要1000个合成3D volumes作为训练数据集。更重要的是,使用潜在扩散模型求解医学图像重建这种逆问题并不简单,并且从未在文献中报道过。
利用扩散模型求解逆问题
用近似分数函数 approximated score function 求解反向SDE相当于从先验分布 p ( x ) p(x) p(x)中抽样。对于解逆问题的情况,我们希望从后验分布 p ( x ∣ y ) p(x|y) p(x∣y)中抽样。两者之间的关系可以用贝叶斯规则 p ( x ∣ y ) = p ( x ) p ( y ∣ x ) p(x|y)=p(x)p(y|x) p(x∣y)=p(x)p(y∣x)表示,因此有: ∇ x l o g p ( x ∣ y ) = ∇ x l o g p ( x ) + ∇ x l o g p ( y ∣ x ) \nabla_{x}log\thinspace p(x|y)=\nabla_{x}log\thinspace p(x)+\nabla_{x}log\thinspace p(y|x) ∇xlogp(x∣y)=∇xlogp(x)+∇xlogp(y∣x)这里,似然项加强了数据的一致性,从而产生了满足 y = A x y = Ax y=Ax的样本。首先,可以将更新步骤拆分为:先去噪,然后投影到测量子空间。形式上,在离散的情况下: x i − 1 ′ ← S o l v e ( x i − 1 , s θ ∗ ) x'_{i-1}\leftarrow Solve(x_{i-1},s_{\theta^{*}}) xi−1′←Solve(xi−1,sθ∗) x i ← P { x ∣ A x = y } ( x i − 1 ′ ) x_{i}\leftarrow P_{\left\{x|Ax=y\right\}}(x'_{i-1}) xi←P{x∣Ax=y}(xi−1′)其中Solve为求解近似分数函数 approximated score function中反向SDE的一般数值求解器, P C P_{C} PC为集合 C C C的投影算子。具体来说,当使用Euler-Maruyama离散化时,方程为: x i − 1 ′ ← ( σ i 2 − σ i − 1 2 ) s θ ∗ ( x i − 1 , i − 1 ) + σ i 2 − σ i − 1 2 ϵ x'_{i-1}\leftarrow(\sigma_{i}^{2}-\sigma_{i-1}^{2})s_{\theta^{*}}(x_{i-1},i-1)+\sqrt{\sigma_{i}^{2}-\sigma_{i-1}^{2}}\epsilon xi−1′←(σi2−σi−12)sθ∗(xi−1,i−1)+σi2−σi−12ϵ x i ← P { x ∣ A x = y } ( x i − 1 ′ ) x_{i}\leftarrow P_{\left\{x|Ax=y\right\}}(x'_{i-1}) xi←P{x∣Ax=y}(xi−1′)
DiffusionMBIR
主要思想
为了有效地利用扩散模型进行3D重建,一种可能的解决方案是逐片应用2D扩散模型。具体地说,Euler-Maruyama离散化方程可以相对于z−轴平行应用。然而,这种方法有一个基本的限制。当这些步骤在没有考虑片之间的相互依赖性的情况下运行时,重建的片将不会彼此一致(特别是当我们有更稀疏的视角时)。因此,当从冠状/矢状面切片观察时,图像包含严重的伪影。(见图3-d、4-d第2-3行)。
为了解决这个问题,作者对结合MBIR和扩散模型的优势来抑制不需要的工件很感兴趣。具体而言,建议是采用Euler-Maruyama离散化方程中的交替最小化方法,但不是在2D域中应用它们,而是逐片应用去噪步骤,再将2D投影步骤替换为3D volume中的ADMM更新步骤。具体来说,考虑以下子问题: m i n x 1 2 ∣ ∣ y − A x ∣ ∣ 2 2 + ∣ ∣ D z x ∣ ∣ 1 min_{x}\frac{1}{2}||y-Ax||_{2}^{2}+||D_{z}x||_{1} minx21∣∣y−Ax∣∣22+∣∣Dzx∣∣1这里没有采用标准的TV取 ∣ ∣ D x ∣ ∣ 1 ||Dx||_{1} ∣∣Dx∣∣1,而是只用了z轴的范数。这种选择源于这样一个事实,即相对于x-y平面的先验已经被神经网络 s θ ∗ s_{θ^*} sθ∗处理好了,所需要暗示的就是相对于剩余方向的空间相关性。换句话说,是在用基于模型的稀疏性先验来增强生成先验。从实验中观察到先验增强策略在所有三个轴上产生连贯的3D重建是非常有效的。
算法步骤
更新步骤为: x + = ( A T A + ρ D z T D z ) − 1 ( A T y + ρ D T ( z − w ) ) x^{+}=(A^{T}A+\rho D_{z}^{T}D_{z})^{-1}(A^{T}y+\rho D^{T}(z-w)) x+=(ATA+ρDzTDz)−1(ATy+ρDT(z−w)) z + = S λ / ρ ( D z x + + w ) z^{+}=S_{\lambda/\rho}(D_{z}x^{+}+w) z+=Sλ/ρ(Dzx++w) w + = w + D z x + − z + w^{+}=w+D_{z}x^{+}-z^{+} w+=w+Dzx+−z+其中, ρ \rho ρ为超参数, S S S为软阈值算子。此外, x + x^{+} x+的更新式子可以用共轭梯度(CG)求解,它有效找到 x x x满足 A x = b Ax=b Ax=b的解:表示以初始点 x x x运行 K K K次CG迭代为 C G ( A , b , x , K ) CG(A,b,x,K) CG(A,b,x,K)。为简单起见,将更新步骤写为 x + , z + , w + = A D M M ( x , z , w ) x^+,z^+,w^+=ADMM(x,z,w) x+,z+,w+=ADMM(x,z,w)。其中, A D M M ( x , z , w ) ADMM(x,z,w) ADMM(x,z,w)可以有效解决 m i n x 1 2 ∣ ∣ y − A x ∣ ∣ 2 2 + ∣ ∣ D z x ∣ ∣ 1 min_{x}\frac{1}{2}||y-Ax||_{2}^{2}+||D_{z}x||_{1} minx21∣∣y−Ax∣∣22+∣∣Dzx∣∣1的最小化问题。因此,朴素实现为: x i − 1 ′ ← S o l v e ( x i , s θ ∗ ) x'_{i-1}\leftarrow Solve(x_i,s_{\theta^{*}}) xi−1′←Solve(xi,sθ∗) x i − 1 ← a r g m i n x i − 1 ′ 1 2 ∣ ∣ y − A x i − 1 ′ ∣ ∣ 2 2 + ∣ ∣ D z x i − 1 ′ ∣ ∣ 1 x_{i-1}\leftarrow argmin_{x'_{i-1}}\frac{1}{2}||y-Ax'_{i-1}||_{2}^{2}+||D_{z}x'_{i-1}||_{1} xi−1←argminxi−1′21∣∣y−Axi−1′∣∣22+∣∣Dzxi−1′∣∣1具体来说,上面第一个式子相当于对每个切片进行并行去噪,而第二个式子则增强了z方向TV先验并强制一致性。这里需要注意的是,算法中有三个迭代源:SDE的数值积分,ADMM迭代,内部CG迭代。
由于扩散模型本身是缓慢的,倍增的额外成本因素将是令人望而却步的,应该避免。在下面,作者设计了一个简单的方法来显著降低这个成本。
快速实现
在slow版本算法中,每次在ADMM迭代运行SDE的第
i
i
i次迭代之前,都会重新初始化原始变量
z
z
z和对偶变量
w
w
w。反过来,这将导致ADMM算法收敛缓慢。此外,由于求解扩散模型会有大量的离散化步骤
N
N
N,两个相邻迭代
x
i
x_i
xi和
x
i
+
1
x_{i+1}
xi+1之间的差是最小的。当去掉
z
z
z和
w
w
w的值时,从第
i
+
1
i + 1
i+1次迭代开始,并在第
i
i
i次迭代时重新初始化,将丢失有价值的信息,并浪费计算时间。因此,作者提出
z
,
w
z,w
z,w值全局共享,并且在实验中发现,选择
M
=
1
,
K
=
1
M = 1,K = 1
M=1,K=1,即ADMM和CG的单次迭代都是高保真重建所必需的。下面进一步给出了快速版本的DiffusionMBIR。


另一个警告是,当运行神经网络前向遍历整个volume时,在内存方面是不可行的,例如,当将Solve安装到单个GPU中时。可以通过将批处理维度划分为子批,分别对子patch运行去噪步骤,然后再次将它们聚集到完整的volume中来解决这个问题。ADMM步骤可以应用于聚合后的整个volume。对于慢速和快速版本的算法,当希望精确匹配测量约束时,也可以在最后对测量子空间应用投影。
实验设置
作者对医学图像重建中三个研究最广泛的任务进行了实验:稀疏视图CT即SV-CT,有限角度CT即LA-CT和压缩感知MRI。
数据集:对于两项CT重建任务,即SV-CT, LA-CT,使用了AAPM 2016 CT低剂量挑战的数据(AAPM 2016 CT low-dose grand challenge)。除1 volume外,其余volumes用于训练2D分数函数,留1 volume用于测试。对于CS-MRI的任务,从多模态脑肿瘤图像分割基准BRATS中获取数据进行测试。注意,使用的预训练分数函数仅在fastMRI膝关节图像上训练,因此不需要在这里分割训练和测试数据(属于OOD问题)。
- 对于AAPM:轴向图像的矩阵大小为512 × 512。作者调整轴向切片的大小为256 × 256,并使用这些切片来训练分数函数。整个数据集由9volumes即3142slices的训练数据和1volume即500slices的测试数据组成。
- 对于BRATS:数据集来自多模态脑肿瘤分割BRATS 2018挑战赛,选择第一个volume作为测试数据,其矩阵大小为240 × 240 × 154。所有方法均使用单独的fastMRI 2019膝关节数据库进行训练。
网络训练和推断:对于CT任务,作者在AAPM数据集上训练ncsnpp模型( Score-based generative modeling through stochastic differential equations),该数据集由大约3000个2D slices组成。对于CS-MRI任务,采用https://github.com/HJ-harry/score-MRI预训练的模型检查点。对于推理,采样器基于预测校正采样方案。设 N = 2000 N = 2000 N=2000,这相当于用 s θ ∗ s_{θ^∗} sθ∗进行4000次神经功能评估。使用单个RTX 3090 GPU训练200次epoch(batch_size=2),训练花了大约一周半的时间。