使用IntelliJ Idea开发Flink应用程序
- 一、实验目的
- 二、实验内容
- 三、实验原理
- 四、实验环境
- 五、实验步骤
- 5.1 启动IntelliJ Idea并创建flink项目
- 5.2 编写flink代码
- 5.2.1 准备工作
- 5.2.2 批处理
- 5.2.3 有界流处理
- 5.2.4 无界流处理
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计5696字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
一、实验目的
掌握IntelliJ Idea创建Flinnk应用程序的过程。
需求:统计一段文字中,每个单词出现的频次。
二、实验内容
1、使用IntelliJ Idea创建flink应用程序。
三、实验原理
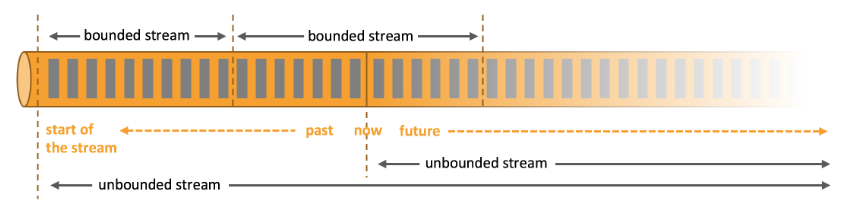
Apache Flink擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
四、实验环境
硬件:x86_64 CentOS 7.5 服务器
软件:JDK1.8,Flink-1.17.1,Hadoop-3.3.3,IntelliJ Idea-2022
五、实验步骤
5.1 启动IntelliJ Idea并创建flink项目
1、创建一个Maven工程,,结构目录如左下
2、导入POM依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jerry</groupId>
<artifactId>FlinkTutorial1.17</artifactId>
<version>1.0-SNAPSHOT</version>
<name>Archetype - FlinkTutorial1.17</name>
<url>http://maven.apache.org</url>
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
5.2 编写flink代码
5.2.1 准备工作
环境准备:在src/main/java目录下,新建一个包,命名为com.jerry.wordcount
数据准备:
(1)在工程根目录下新建一个input文件夹,并在下面创建文本文件word.txt
(2)在words.txt中输入一些文字,例如:
hello flink
hello world
hello java
5.2.2 批处理
1、批处理基本思路:
(1)先逐行读入文件数据,然后将每一行文字拆分成单词;
(2)接着按照单词分组,统计每组数据的个数,就是对应单词的频次。
2、编写代码
package com.jerry.wordcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.asm9.org.objectweb.asm.tree.analysis.Value;
import org.apache.flink.util.Collector;
/**
* ClassName: WordCountBatchDemo <br>
* Package: com.jerry.wordcount <br>
* Description:
*
* @Author: jerry_jy
* @Create: 2023-06-12 16:29
* @Version: 1.0
*/
public class WordCountBatchDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// TODO 2. 读取数据:从文件中读取
DataSource<String> dataSource = env.readTextFile("input/word.txt");
// TODO 3. 按行切分、转换(word,1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = dataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// TODO 3.1 按照空格切分单词
String[] words = s.split(" ");
// TODO 3.2 将单词转为(word,1)
for (String word : words) {
Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);
// TODO 3.3 使用 Collector 向下游发送数据
collector.collect(wordTuple2);
}
}
});
// TODO 4. 按照 word 分组
// 这里的0是位置,代表第1个元素
UnsortedGrouping<Tuple2<String, Integer>> wordAndOnrGroupby = wordAndOne.groupBy(0);
// TODO 5. 各分组内聚合
// 这里的1是位置,代表第二个元素
AggregateOperator<Tuple2<String, Integer>> sum = wordAndOnrGroupby.sum(1);
// TODO 6. 输出
sum.print();
}
}
3、输出
(flink,1)
(world,1)
(hello,3)
(java,1)
需要注意的是,这种代码的实现方式,是基于DataSet API的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSet API就没什么用了,在实际应用中我们只要维护一套DataStream API就可以。这里只是为了方便大家理解,我们依然用DataSet API做了批处理的实现。
5.2.3 有界流处理
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的DataStream API更加强大,可以直接处理批处理和流处理的所有场景。
下面我们就针对不同类型的输入数据源,用具体的代码来实现流处理。
package com.jerry.wordcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* ClassName: WordCountStreamDemo <br>
* Package: com.jerry.wordcount <br>
* Description: dataStream 实现word count 读文件(有界流)
*
* @Author: jerry_jy
* @Create: 2023-07-24 20:24
* @Version: 1.0
*/
public class WordCountStreamDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 2. 读取数据:从文件中读取
DataStreamSource<String> lineDS = env.readTextFile("input/word.txt");
// TODO 3. 按行切分、转换(word,1)
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// TODO 3.1 按照空格切分单词
String[] words = s.split(" ");
// TODO 3.2 将单词转为(word,1)
for (String word : words) {
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);
// TODO 3.3 使用 Collector 向下游发送数据
collector.collect(wordsAndOne);
}
}
});
// TODO 4. 按照 word 分组
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
});
// TODO 5. 各分组内聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);
// TODO 6. 输出
sumDS.print();
// TODO 7、启动,类似于sparkstreaming 最后的ssc.start()
env.execute();
}
}
输出:
3> (java,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
13> (flink,1)
9> (world,1)
主要观察与批处理程序BatchWordCount的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 转换处理之后,得到的数据对象类型不同。
- 分组操作调用的是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
- 代码末尾需要调用env的execute方法,开始执行任务。
5.2.4 无界流处理
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续地处理捕获的数据。为了模拟这种场景,可以监听socket端口,然后向该端口不断的发送数据。
(1)将StreamWordCount代码中读取文件数据的readTextFile方法,替换成读取socket文本流的方法socketTextStream。
具体代码实现如下:
package com.jerry.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* ClassName: WordCountUnboundedDemo <br>
* Package: com.jerry.wordcount <br>
* Description: dataStream 实现wordCount 读socket(无界流)
*
* @Author: jerry_jy
* @Create: 2023-07-24 20:50
* @Version: 1.0
*/
public class WordCountUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 2. 读取数据:从文件中读取
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3. 处理数据:切分、转换、分组、聚合
socketDS
.flatMap(
(String s, Collector<Tuple2<String, Integer>> collector) -> {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
)
// 这里由于Lambda表达式存在类型擦除,所以必须指定返回元素的类型
.returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(stringIntegerTuple2 -> stringIntegerTuple2.f0)
.sum(1)
.print();
// TODO 4. 输出
// TODO 5、执行
env.execute();
}
}
(2)在Linux环境的主机hadoop102上,执行下列命令,发送数据进行测试
[root@hadoop102 ~]# nc -lk 7777
说明:CentOS 下安装nc的命令
yum install -y netcat
注意:要先启动端口,后启动StreamWordCount程序,否则会报超时连接异常。
(3)启动StreamWordCount程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的,因为Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
(4)从hadoop102发送数据
①在hadoop102主机中,输入“hello flink”,输出如下内容
13> (flink,1)
5> (hello,1)
②再输入“hello world”,输出如下内容
2> (world,1)
5> (hello,2)
提醒:
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于Java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的——只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
因为对于flatMap里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
注意:
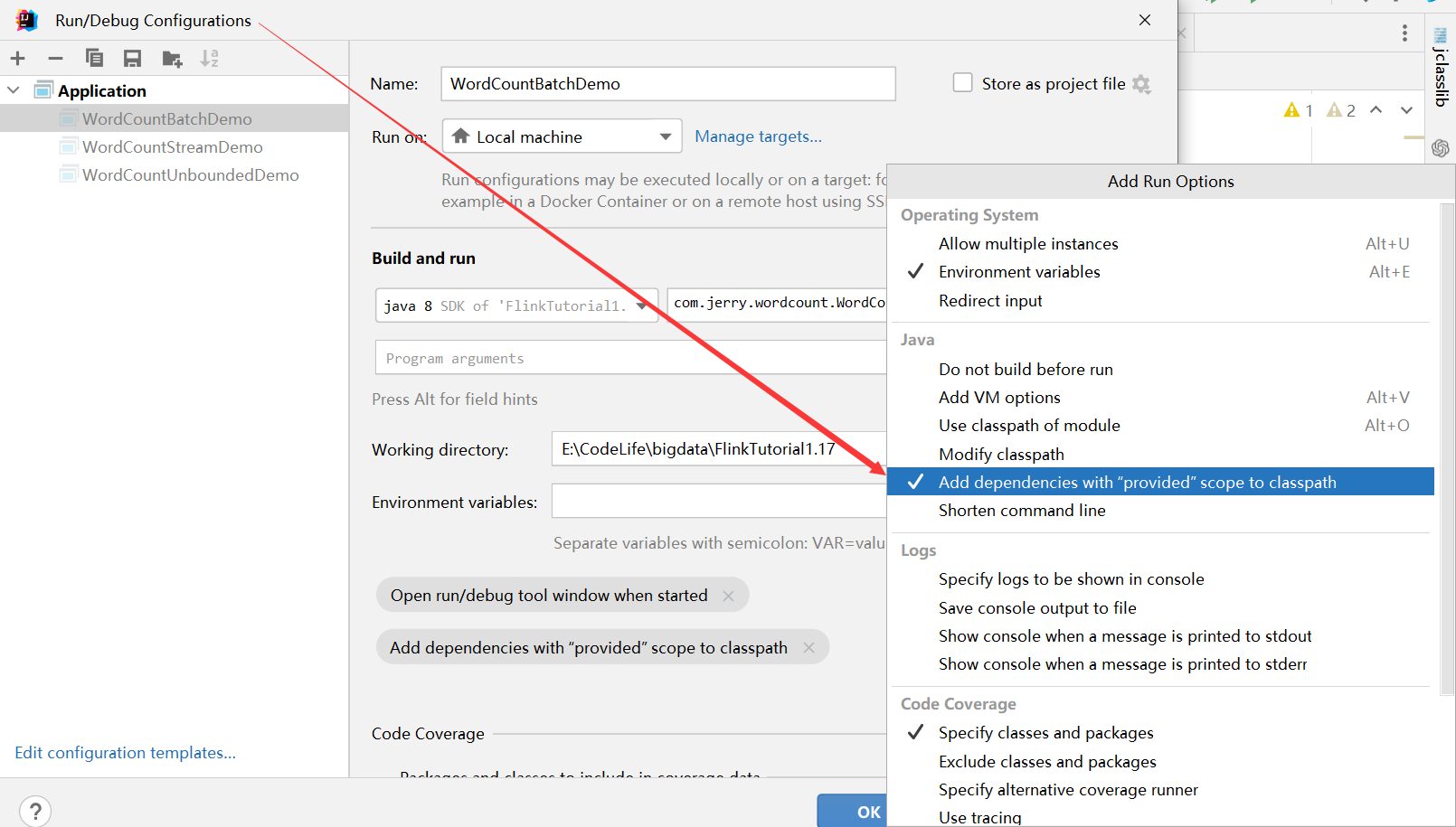
前面的POM.xml文件中关于flink的依赖作用域是provided,也就是说,在生产环境下不会被打包上传,这里我们需要在【Run】–> 【Edit Configuration】中做如下配置,才能运行成功程序
–end–