🚀个人主页:为梦而生~ 关注我一起学习吧!
⭐️往期关于树的文章:
【哈夫曼树】基本概念、构建过程及C++代码
【线索二叉树】C++代码及线索化过程详解
欢迎阅读!

- 实验内容
根据二叉树先序和中序遍历的结果,生成该二叉树。并输出后序、层序遍历结果。
- 实验步骤
- 结构体的定义:定义链表、队列、以及二叉树的结构体,方便算法的设计。
- 输入数据:根据给定先序遍历和中序遍历结果,确定二叉树的根节点,并分别得到左右子树的先序遍历和中序遍历序列。
- 树的创建:对于根节点左右子树分别递归地执行第1步得到子树,并将其连接到根节点上。
- 重复第2步直到所有子树都生成,将所有的结点信息记录到数组中。
- 根据所求得的二叉树以及数组中的信息,计算后序遍历的结果并输出。
- 根据所求得的二叉树以及数组中的信息,利用队列的辅助,计算并输出层序遍历的结果。
- 详细设计
本设计使用的是广度优先搜索算法,并且需要输出路径,所以用到了栈和队列。详细设计方案如下:
- 首先,定义二叉树、链表和队列结构体数据类型。
//定义树的存储结构
typedef struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
}*BiTree;
//定义链表的存储结构
typedef struct Node {
TreeNode* data;
struct Node* next;
}Node, *QueueNode;
//定义队列的存储结构
typedef struct Queue{
Node* front, * rear;
}*LinkQueue;
- 随后,定义空队以及辅助全局变量并初始化。
int pre[MAXSIZE], in[MAXSIZE], post[MAXSIZE]; // 定义全局数组,存放遍历结果
int idx[MAXSIZE]; // 记下每个节点在中序遍历结果中的下标位置
int leaves[MAXSIZE]; // 存放所有叶子节点
int post_idx = 0; // 定义全局变量,记录后序遍历的当前位置
int leaf_idx = 0; // 定义全局变量,记录叶子节点的个数
LinkQueue level_queue = (Queue*)malloc(sizeof(Queue)); //创建用于层序遍历的队列
- 输入前序和中序遍历结果以及结点个数,用于二叉树的创建。
int n;
printf("请输入节点个数:");
scanf("%d", &n);
printf("请输入二叉树前序遍历结果:");
for (int i = 0; i < n; i++) {
scanf("%d", &pre[i]);
}
printf("请输入二叉树中序遍历结果:");
for (int i = 0; i < n; i++) {
scanf("%d", &in[i]);
idx[in[i]] = i;
}
- 根据给定的二叉树先序遍历和中序遍历结果构建二叉树,通过递归来实现对于左右子树的构建。首先根据当前前序遍历序列的第一个元素在中序遍历序列中找到对应的下标;根据找到的下标,可以得到当前元素的左右子树的前序和中序遍历序列范围;递归调用 buildTree 函数生成当前结点的左子树和右子树;在递归调用的过程中,每次都会基于当前的范围值不断更新相关索引值,直至生成完整棵二叉树。最后将生成的根结点指针返回,并完成二叉树的构建。
// 根据前序和中序遍历结果构建二叉树
BiTree buildTree(int pre_left, int pre_right, int in_left, int in_right) {
//根据边界判断是否到叶子结点
if (pre_left > pre_right) {
return NULL;
}
int root_val = pre[pre_left]; //结点的值为当前前序遍历当前的值
int in_idx = idx[root_val]; //找到中序遍历该结点对应的下标
TreeNode* root = createNode(root_val); //创建新的结点
root->left = buildTree(pre_left + 1, pre_left + (in_idx - in_left), in_left, in_idx - 1); //递归生成左子树
root->right = buildTree(pre_left + (in_idx - in_left) + 1, pre_right, in_idx + 1, in_right);//递归生成右子树
return root; //返回根结点指针
}
- 递归遍历二叉树,输出后序遍历结果。采用递归算法实现,按照“左-子-根”的顺序访问每一个结点,并将其值存储到后序遍历结果数组 post 里。首先判断当前结点是否为空,若为空则直接返回;对于非空结点,先递归遍历其左子树,再递归遍历其右子树,以保证左右子树都已经访问完;最后,在左右子树均访问完毕之后,输出当前结点的值到后序遍历结果数组;将当前结点的值插入到后序遍历结果数组,这样最终我们就能得到符合要求的后序遍历结果。
// 递归遍历二叉树,生成后序遍历结果
void generate_postorder(BiTree root) {
if (root == NULL) {
return;
}
generate_postorder(root->left); //递归遍历左字数
generate_postorder(root->right);//递归遍历右子树
post[post_idx++] = root->val; //输出当前结点值
}
- 进行层序遍历并输出遍历结果。首先将二叉树的根节点入队,然后从队列中取出队头元素,并输出其值;若当前结点存在左子树,则将其左子节点入队;若当前结点存在右子树,则将其右子节点入队;继续对队列进行操作,直到队列为空。
void level_traversal(BiTree root, LinkQueue queue) {
if (root == NULL) {
return;
}
// 根结点入队
enQueue(queue, root);
// 队列不空时遍历
while(queue->front != NULL){
TreeNode* p = (TreeNode*)malloc(sizeof(TreeNode));
deQueue(queue, &p); // 出队
printf("%d ", p->val); // 输出
if(root->left != NULL){
enQueue(queue, p->left); //若左子树不为空,将左子树根节点入队
}
if(root->right != NULL){
enQueue(queue, p->right); //若右子树不为空,将右子树根节点入队
}
}
}
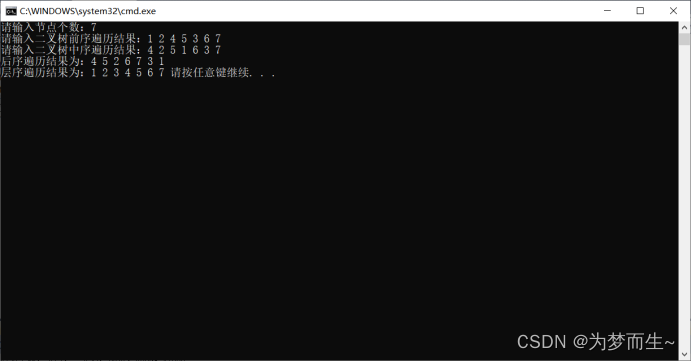
- 最终结果:
代码实现:
#define _CRT_SECURE_NO_WARNINGS //在VS中使用 避免出现scanf printf不安全的警告
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 100 // 定义最大结点数量
//定义树的存储结构
typedef struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
}*BiTree;
//定义链表的存储结构
typedef struct Node {
TreeNode* data;
struct Node* next;
}Node, *QueueNode;
//定义队列的存储结构
typedef struct Queue{
Node* front, * rear;
}*LinkQueue;
int pre[MAXSIZE], in[MAXSIZE], post[MAXSIZE]; // 定义全局数组,存放遍历结果
int idx[MAXSIZE]; // 记下每个节点在中序遍历结果中的下标位置
int leaves[MAXSIZE]; // 存放所有叶子节点
int post_idx = 0; // 定义全局变量,记录后序遍历的当前位置
int leaf_idx = 0; // 定义全局变量,记录叶子节点的个数
// 创建新节点
BiTree createNode(int val) {
TreeNode* newNode = (TreeNode*)malloc(sizeof(struct TreeNode));
newNode->val = val;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
// 根据前序和中序遍历结果构建二叉树
BiTree buildTree(int pre_left, int pre_right, int in_left, int in_right) {
//根据边界判断是否到叶子结点
if (pre_left > pre_right) {
return NULL;
}
int root_val = pre[pre_left]; //结点的值为当前前序遍历当前的值
int in_idx = idx[root_val]; //找到中序遍历该结点对应的下标
TreeNode* root = createNode(root_val); //创建新的结点
root->left = buildTree(pre_left + 1, pre_left + (in_idx - in_left), in_left, in_idx - 1); //递归生成左子树
root->right = buildTree(pre_left + (in_idx - in_left) + 1, pre_right, in_idx + 1, in_right);//递归生成右子树
return root; //返回根结点指针
}
// 递归遍历二叉树,生成后序遍历结果
void generate_postorder(BiTree root) {
if (root == NULL) {
return;
}
generate_postorder(root->left); //递归遍历左字数
generate_postorder(root->right);//递归遍历右子树
post[post_idx++] = root->val; //输出当前结点值
}
// 初始化队列
void initQueue(LinkQueue queue) {
queue->front = NULL;
queue->rear = NULL;
}
// 入队操作
void enQueue(LinkQueue queue, TreeNode* val) {
QueueNode node = (QueueNode) malloc(sizeof(Node));
node->data = val;
node->next = NULL;
if (queue->rear == NULL) {
queue->front = node;
queue->rear = node;
} else {
queue->rear->next = node;
queue->rear = node;
}
}
// 出队操作
void deQueue(LinkQueue queue, BiTree* val) {
if (queue->front == NULL) {
printf("Error: queue is empty!\n");
exit(1);
}
*val = queue->front->data;
QueueNode temp = queue->front;
queue->front = queue->front->next;
if (queue->front == NULL) {
queue->rear = NULL;
}
free(temp);
}
// 层序遍历二叉树
void level_traversal(BiTree root, LinkQueue queue) {
if (root == NULL) {
return;
}
// 根结点入队
enQueue(queue, root);
// 队列不空时遍历
while(queue->front != NULL){
TreeNode* p = (TreeNode*)malloc(sizeof(TreeNode));
deQueue(queue, &p); // 出队
printf("%d ", p->val); // 输出
if(root->left != NULL){
enQueue(queue, p->left); //若左子树不为空,将左子树根节点入队
}
if(root->right != NULL){
enQueue(queue, p->right); //若右子树不为空,将右子树根节点入队
}
}
}
// 找出所有叶子节点
void find_leaves(BiTree root) {
if (root == NULL) {
return;
}
if (root->left == NULL && root->right == NULL) {
leaves[leaf_idx++] = root->val;
}
find_leaves(root->left);
find_leaves(root->right);
}
int main() {
LinkQueue level_queue = (Queue*)malloc(sizeof(Queue)); //创建用于层序遍历的队列
int n;
printf("请输入节点个数:");
scanf("%d", &n);
printf("请输入二叉树前序遍历结果:");
for (int i = 0; i < n; i++) {
scanf("%d", &pre[i]);
}
printf("请输入二叉树中序遍历结果:");
for (int i = 0; i < n; i++) {
scanf("%d", &in[i]);
idx[in[i]] = i;
}
BiTree root = buildTree(0, n - 1, 0, n - 1);
generate_postorder(root);
find_leaves(root);
printf("后序遍历结果为:");
for (int i = 0; i < n; i++) {
printf("%d ", post[i]);
}
printf("\n");
printf("层序遍历结果为:");
initQueue(level_queue);
level_traversal(root, level_queue);
printf("\n");
printf("所有叶子节点为:");
for (int i = 0; i < leaf_idx; i++) {
printf("%d ", leaves[i]);
}
printf("\n");
return 0;
}