PgSQL-使用技巧-如何衡量网络对性能的影响
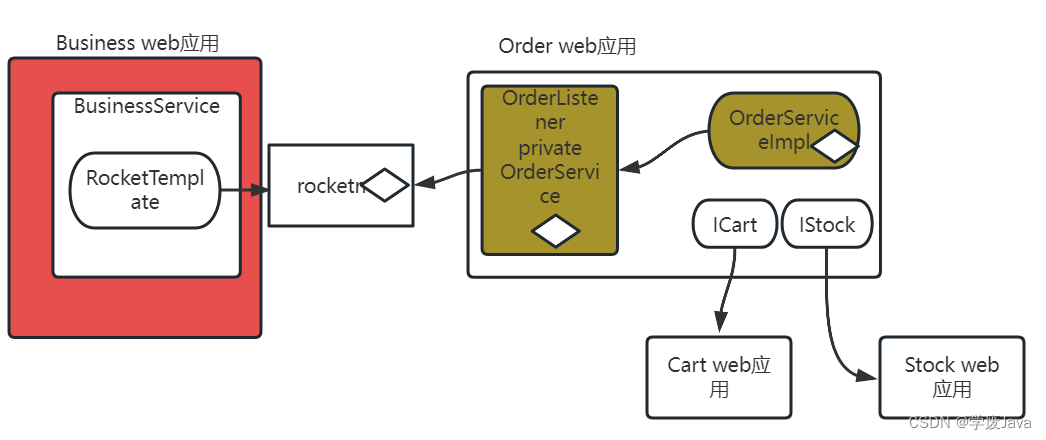
PG数据库和应用之间常见的部件有连接池、负载平衡组件、路由、防火墙等。我们常常不在意或者认为涉及的网络hops对整体性能产生的额外开销是理所当然的。但在很多情况下,它可能会导致严重的性能损失和拖累整体吞吐量。相当长一段时间,我试图对这种开销进行良好的评估,之前写过how the volume of data transmission as part of SQL execution, as well as the cursor location, affects the overall performance:
https://www.percona.com/blog/impact-of-network-and-cursor-on-query-performance-of-postgresql/
如何检测和衡量影响
没有简单的机制用来衡量网络开销的影响。但是对pg_stat_activity中的wait_events可以尽可能多的告诉我们相关信息。所以,我们应该对等待世界进行采样。我们使用pg_gather作为收集和分析等待事件。他是一个独立的SQL脚本,无需在数据库系统上安装任何东西。他的设计也很轻巧,每隔会话可以采集2000个样本。该项目地址:
https://github.com/jobinau/pg_gather
pg_gather分析报告可以显示等待事件以及每个会话的相关信息:

本文仅讨论等待事件的部分,同时介绍不同类型工作负载下网络性能如何在等待事件中显示。
案例1:检索大量行数据的查询
考虑下pg_dump在另一台机器上进行逻辑备份。如果网络速度很快,可能会看到大量的CPU利用率和“DataFileRead”作为等待事件:

当然,还有“ClientWrite”事件,本例中,这是与将数据写入客户端pg_dump相关的等待事件。如果客户端是像psql一样的轻量级工具,并且网络很快,则“ClientWrite”可能甚至变得不可见。
接着,看下网络速度变慢时,等待事件会是什么样子:

可以看到,CPU利用率和“DataFileRead”等待事件下降,表明整体服务端会话活动减慢。同时“ClientWrite”飙升到1821,表明会话花费了大量时间将数据发送到客户端(pg_dump)。花样“ClientRead”,表明pg_dump的确认需要时间。
“ClientWrite”中的峰值并不取决于客户端工具。下面是检索大量记录的查询,常规psql会话的屏幕截屏:

这些情况下,过多的“ClientWrite”足以发现问题。
案例2:批量数据加载
与前面的情况相反。但PG批量些操作需要做大量工作。下面的等待事件是从真实的fast/low延迟网络采集的:

显然,PG进程必须在“DataFileExtend”、“WALWrite”和“WALSync”上花费事件。现在,如果网络速度变慢,随着性能瓶颈的出现,我们看到的许多等待事件可能看不见。
以下是较慢网络下加载批量数据的等待事件:

正如所见,“ClientRead”已成为主要的等待事件。意味着服务器会话花费更多事件从客户端读取数据。许多系统中,这种变化可能并不明显,但总体而言,“ClientRead”变得更加突出。
案例3:对事务的影响
OLTP负载上,SQL可能简单且短小,不会造成任何可观察到的网络影响。但服务器和客户端之间的来回通信可能会导致SQL和最终提交或回滚之间出现不必要的延迟。即每隔语句之间的间隙。
下面是快速网络下pgbench的微事务的等待事件:

显然,与 WAL 相关的等待事件和 CPU 使用率很高。但我们可以看到也有相当多的“ClientRead”。发生这种情况是因为微事务会有大量的网络交互。ClientRead 对于事务来说是不可避免的,预计 5-10% 就可以了。
但随着网络速度变慢,“ClientRead”变得越来越重要。以下是来自较慢网络上相同 pgbench 事务工作负载的信息。

在这种情况下,ClientRead 成为最大的等待事件。
您可能想知道,“Net/Delay*”显示的是什么?新版本的 pg_gather(版本 21)中提供了此附加分析,用于评估事务块外的延迟。详情请参阅下一节。
案例4:连接利用率
随着网络延迟的增加,客户端连接将无法尽可能使用服务器会话。服务器会话必须等待第八个“ClientRead”/“ClientWrite”或闲置。无论哪种方式,它都会极大地影响系统的吞吐量。
在事务内,延迟被捕获为“ClientRead”,但不会捕获两个事务之间的延迟,因为会话暂时变为“空闲”。pg_gather 新版本准备了对服务器浪费时间或“网络/延迟*”时短暂切换到空闲的估计。这可能是由于网络延迟或应用程序响应不佳造成的。从数据库方面来说,很难区分它们。但“网络/延迟*”可以很好地了解浪费了多少服务器时间。
当客户端和服务器之间存在大量来回通信时,延迟/等待时间变得更加明显。通过创建单个语句文件可以轻松测试这一点。
echo "SELECT 1" > query.sql这可以通过 TCP 连接针对远程数据库执行指定的秒数。
$ pgbench -h 10.197.42.1 -T 20 -f query.sql在我的服务器之间的快速网络上,我可以获得以下结果作为单个会话的 TPS。
…
latency average = 0.030 ms
initial connection time = 5.882 ms
tps = 32882.734311 (without initial connection time)但 pg_gather 的等待事件分析告诉我,更多的时间花在了 Net/Delay* 上。

这是有道理的,因为“SELECT 1”在服务器上不需要做太多事情,而且这个工作负载都是关于发送来回通信。
使用本地Unix套接字连接,单个会话吞吐量增加了一倍以上!
latency average = 0.013 ms
initial connection time = 1.498 ms
tps = 75972.733205 (without initial connection time)但等待事件分析告诉我们,客户端-服务器通信仍然是主要的时间消耗者。

“ClientRead”增加是因为从客户端传输了更多数据。
如果在这种情况下网络速度变慢,“Net/Delay*”也会增加,并且 CPU 使用率和 TPS 会下降,因为会话在处理两个语句之间花费更多时间不执行任何操作。

由于这个特定的工作负载没有事务并且发送到服务器的数据较少,因此“ClientRead”可能会下降到不明显的水平,正如我们所看到的。
总结
来自 pg_stat_activity 的“wait events”信息可以告诉我们有关性能和网络拥塞的许多详细信息。不仅仅是事件的总和,两个等待事件和模式之间的差距也有很多信息需要挖掘。pg_gather独立 SQL 脚本可以方便地发现问题和瓶颈。尽管这篇博文专门针对网络,但等待事件分析对于许多情况都是通用的。
原文
https://www.percona.com/blog/how-to-measure-the-network-impact-on-postgresql-performance/




![[Bug] ls: reading directory ‘.‘: Input/output error, Ubuntu系统某一挂载目录下数据全部消失](https://img-blog.csdnimg.cn/f3aa8c44bb50407496869aff90562fb6.png#pic_center)
![LeetCode[315]计算右侧小于当前元素的个数](https://img-blog.csdnimg.cn/dec7aa4baf124f2abb0c7a8112dc15ce.png)