文章目录
- 一、概述
- 二、缓存
- 1、缓存穿透
- 2、缓存击穿
- 3、缓存雪崩
- 4、双写一致性
- 5、持久化
- 6、数据过期策略
- 7、数据淘汰策略
- 三、分布式锁
- 四、其它面试题
- 1、主从复制
- 2、哨兵
- 3、分片集群结构
- 4、I/O多路复用
一、概述
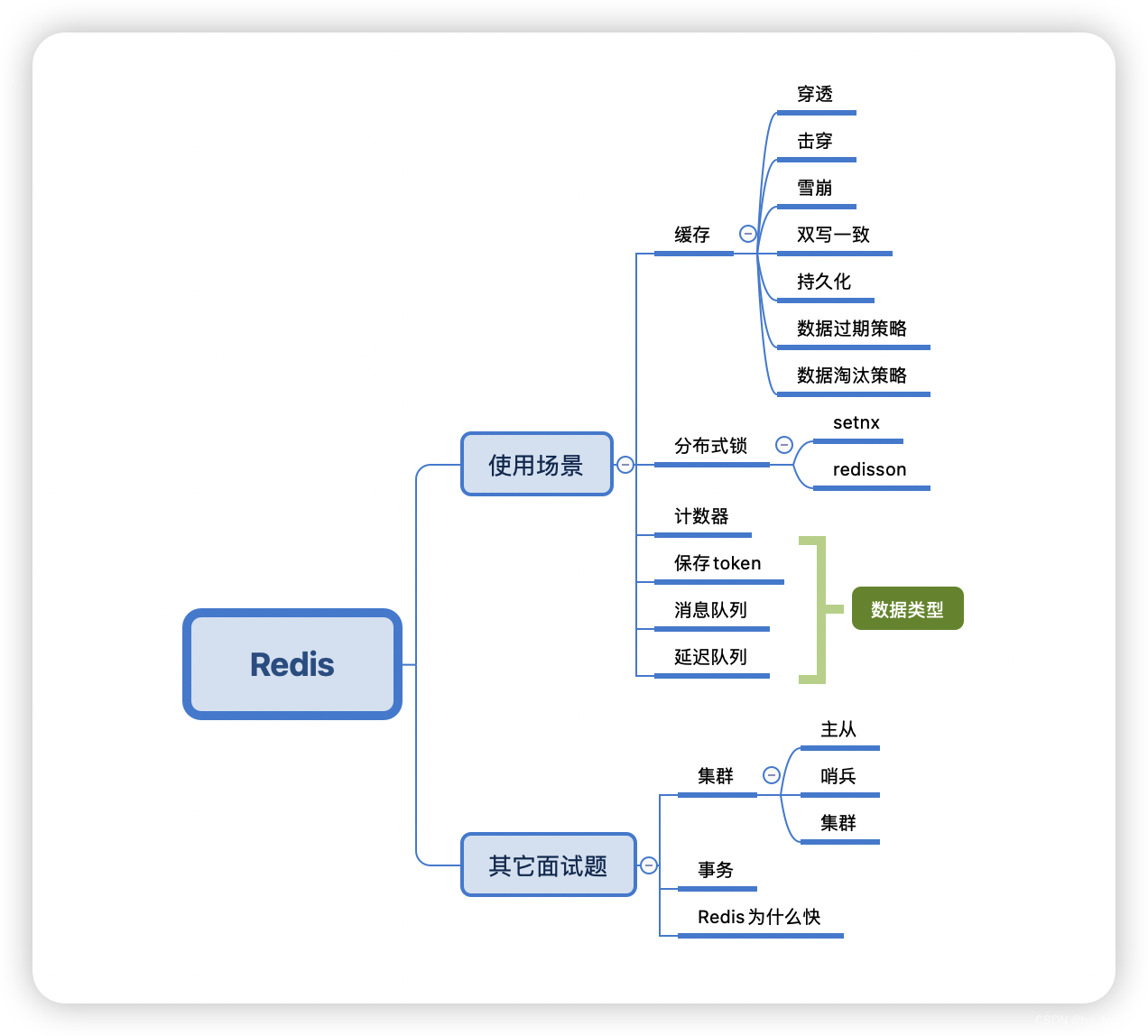
使用场景:
- Redis的数据持久化策略有哪些
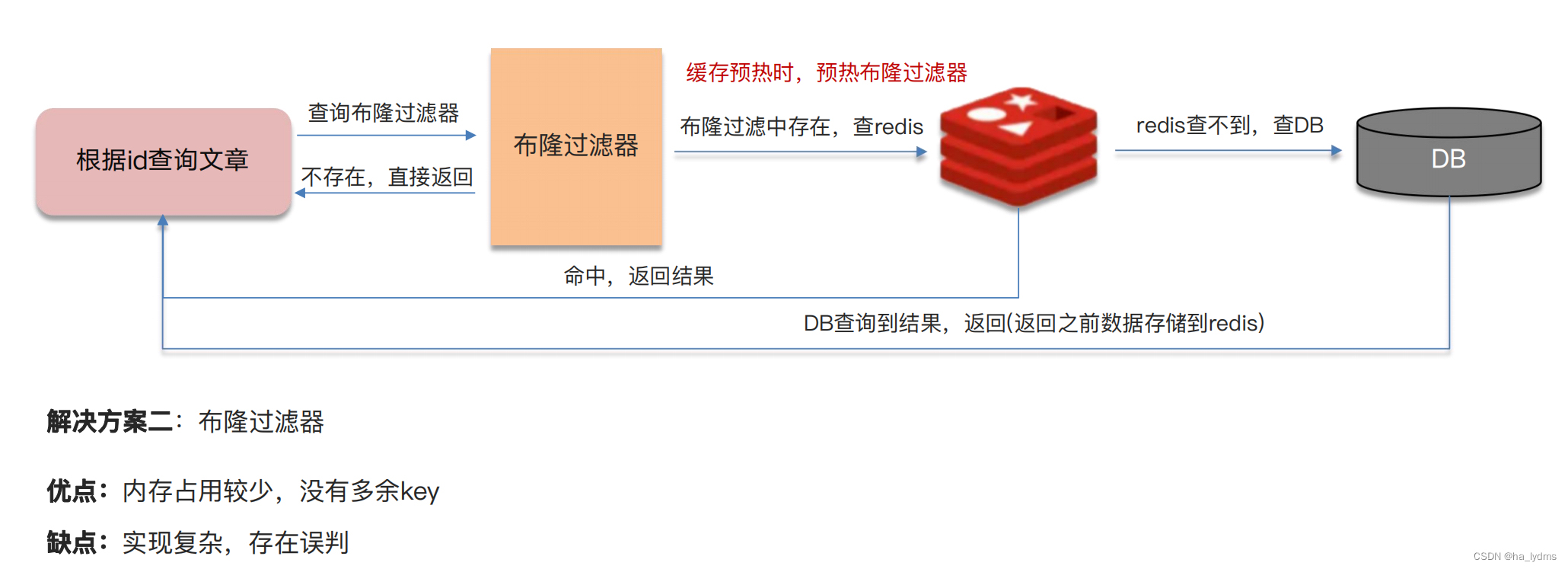
- 什么是缓存穿透,怎么解决
- 什么是布隆过滤器
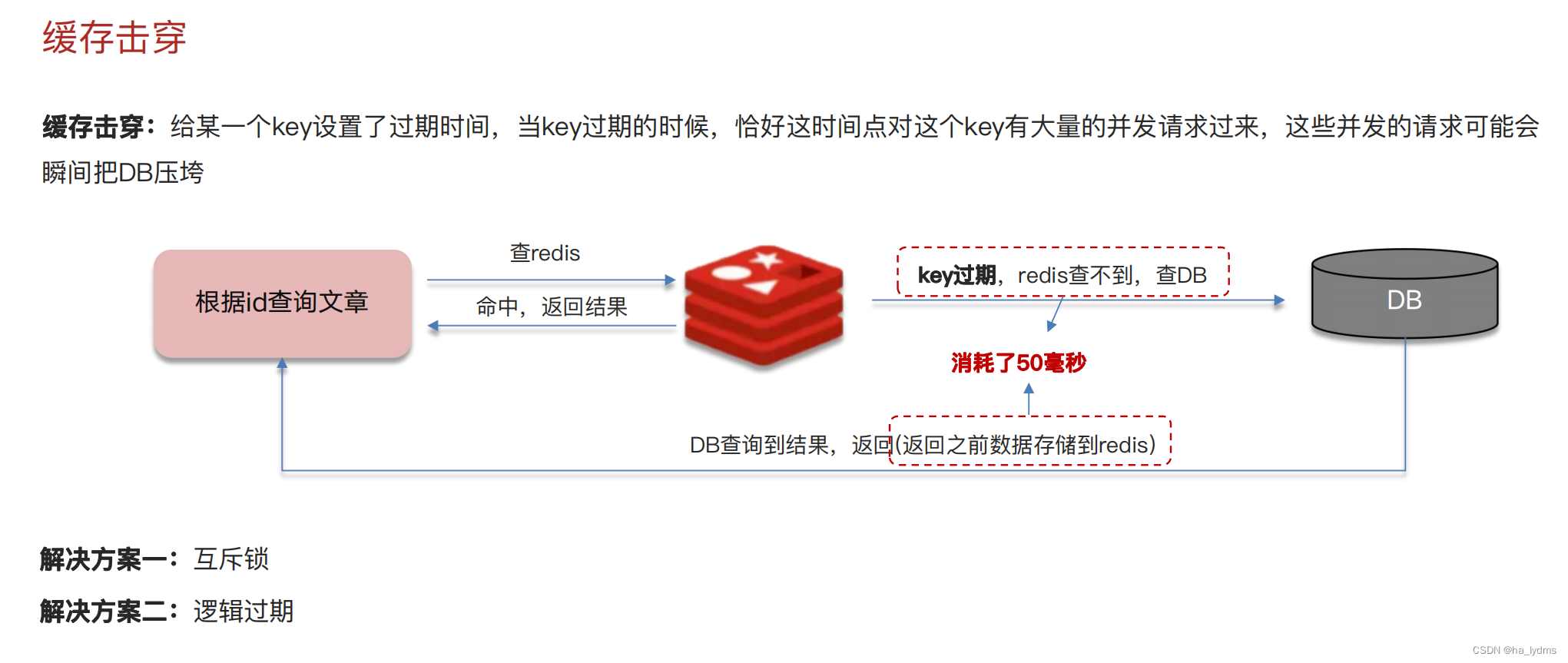
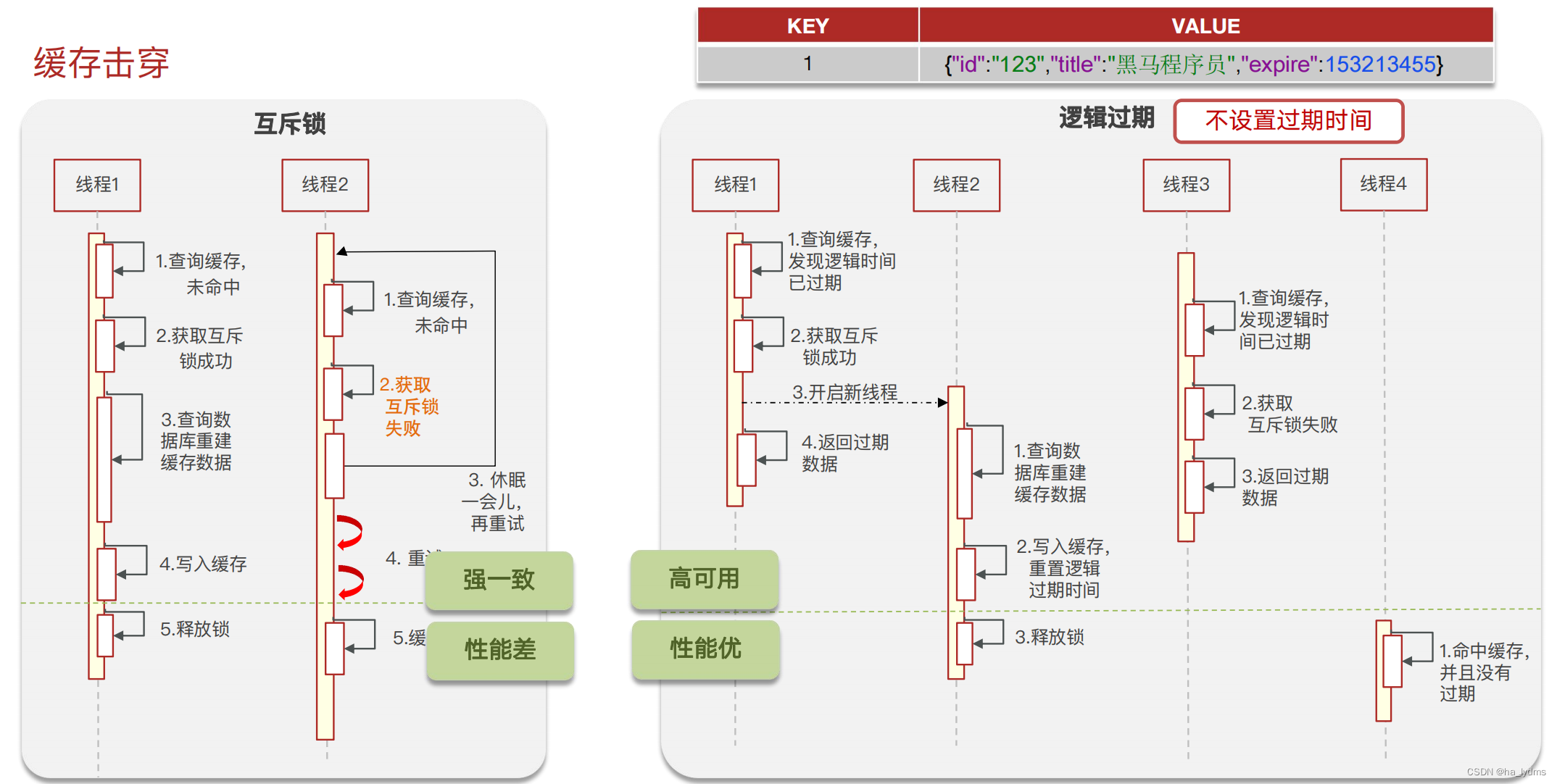
- 什么是缓存击穿,怎么解决
- 什么是缓存雪崩,怎么解决
- redis双写问题
- Redis分布式锁如何实现
- Redis实现分布式锁如何合理的控制锁的有效时长
- Redis的数据过期策略有哪些
- Redis的数据淘汰策略有哪些
其它面试题
- Redis集群有哪些方案, 知道嘛
- 什么是 Redis 主从同步
- 你们使用Redis是单点还是集群 ? 哪种集群
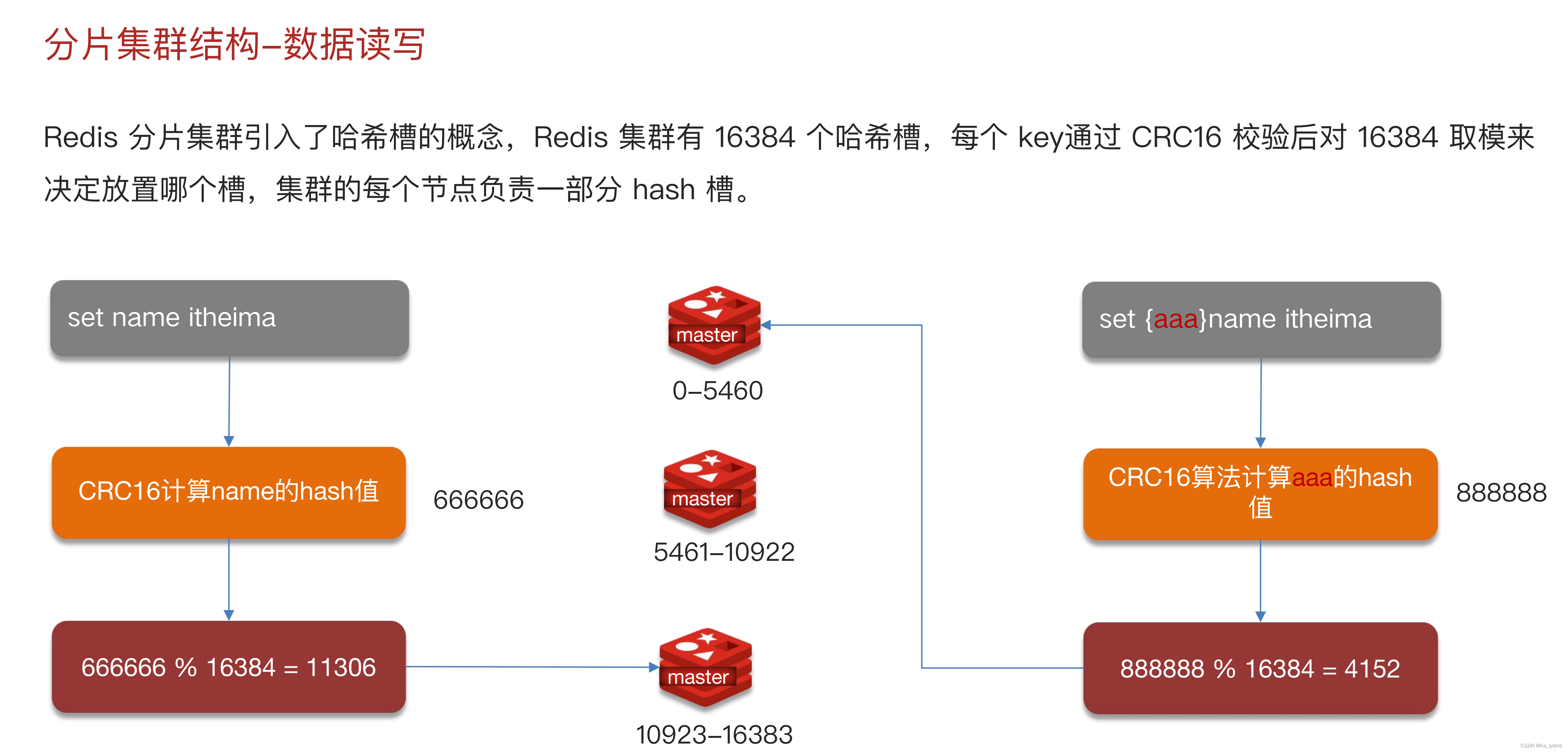
- Redis分片集群中数据是怎么存储和读取的
- redis集群脑裂
- 怎么保证redis的高并发高可用
- 你们用过Redis的事务吗 ? 事务的命令有哪些
- Redis是单线程的,但是为什么还那么快?
二、缓存
1、缓存穿透

2、缓存击穿
3、缓存雪崩
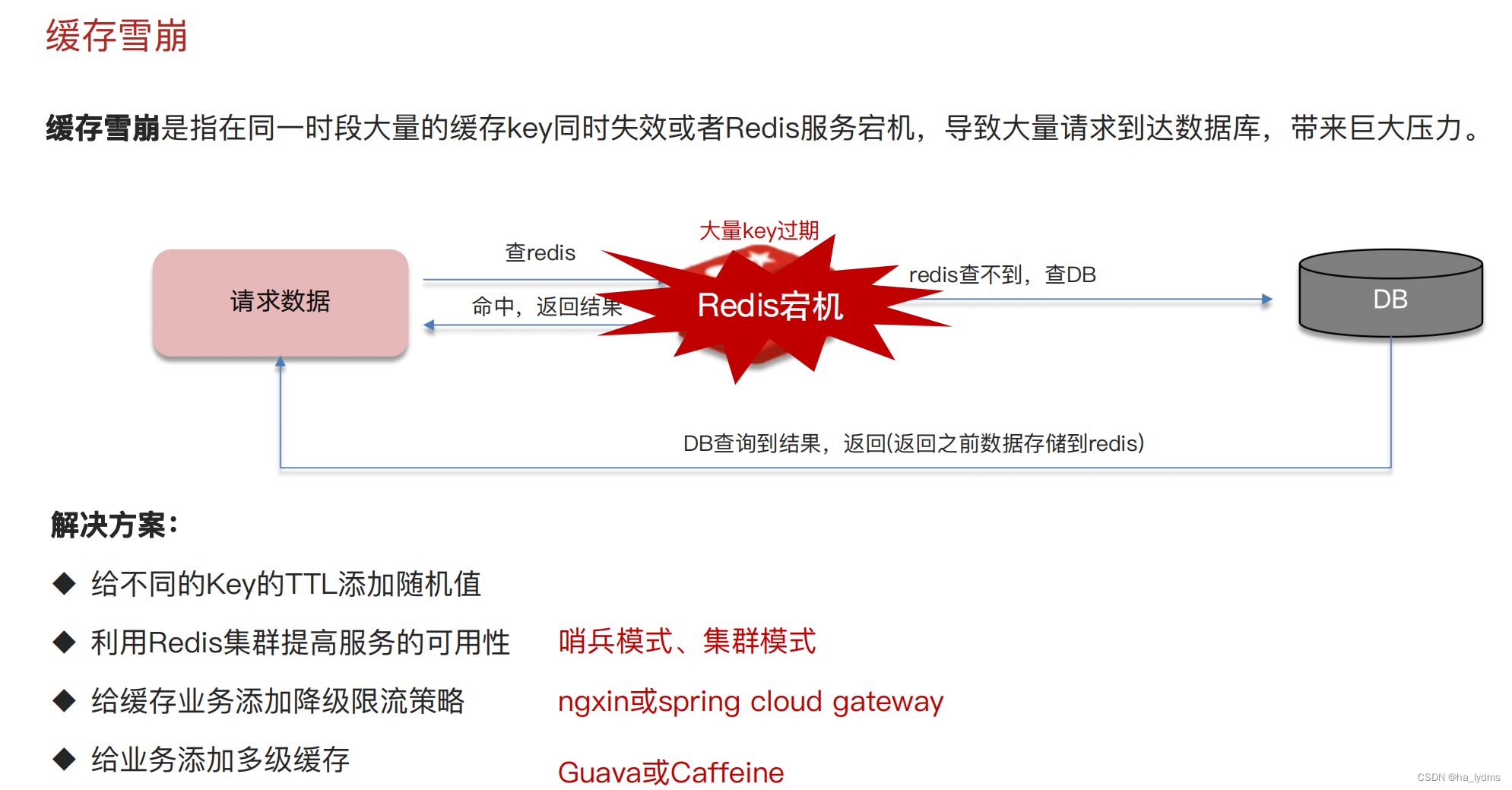
4、双写一致性
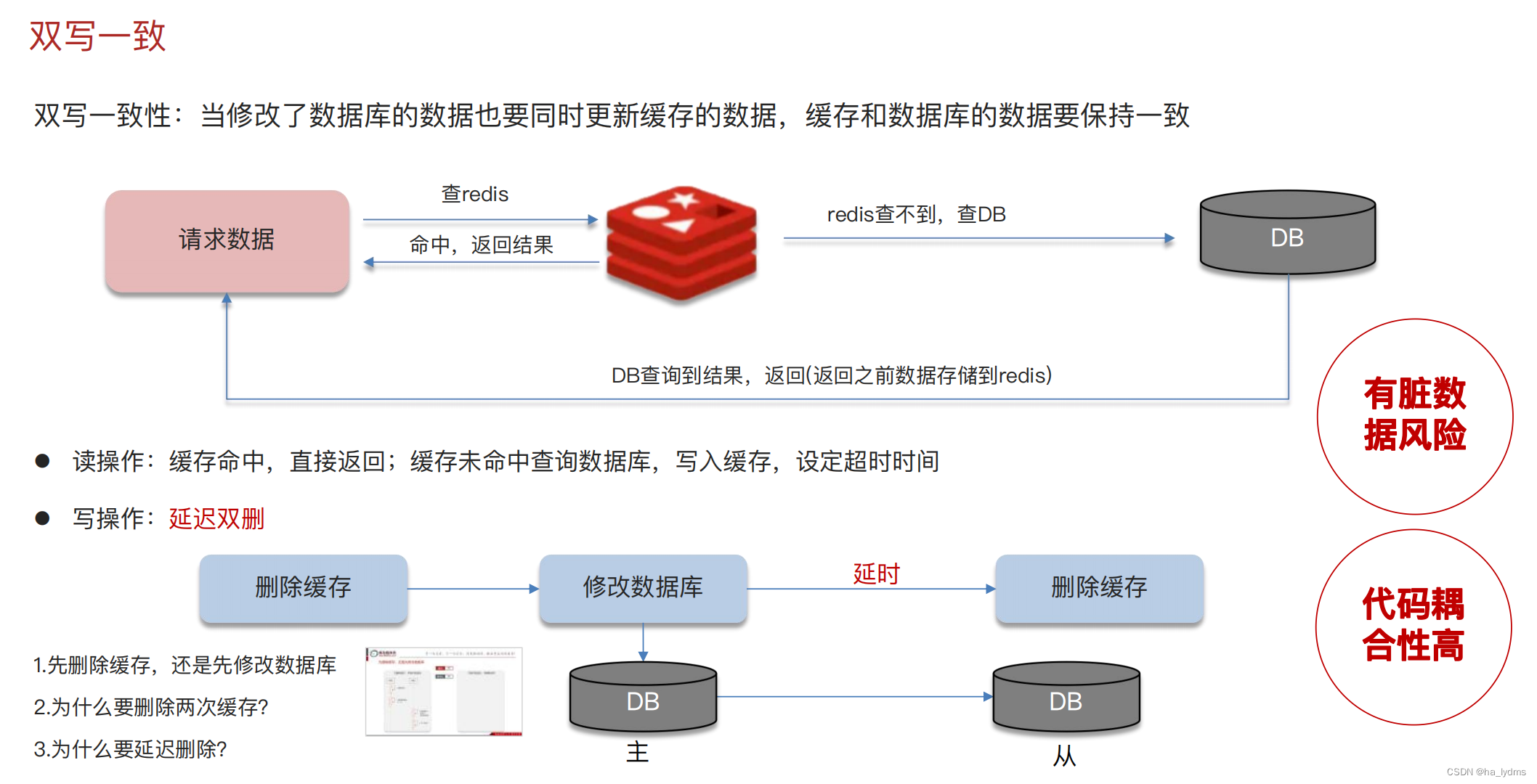
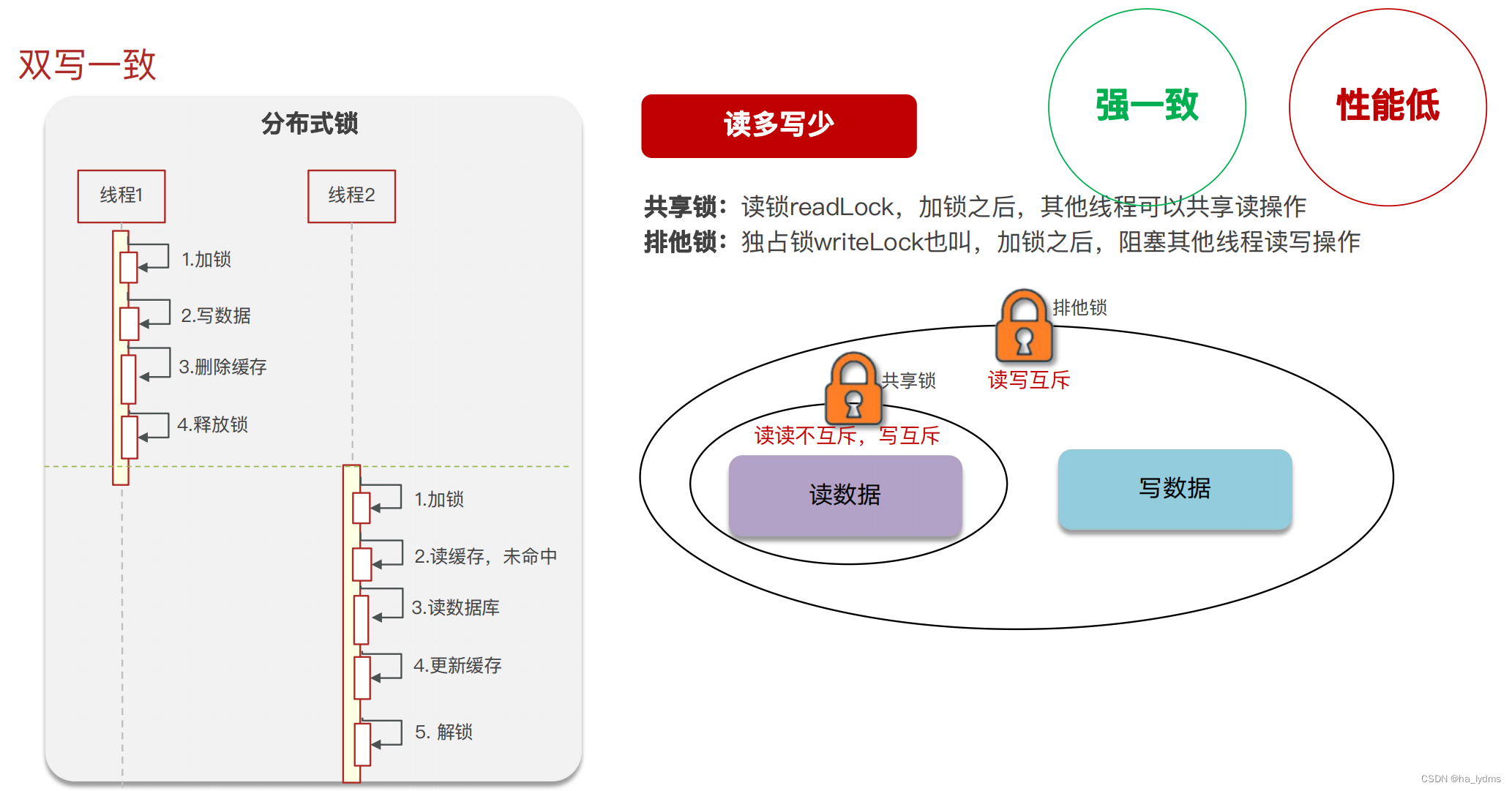
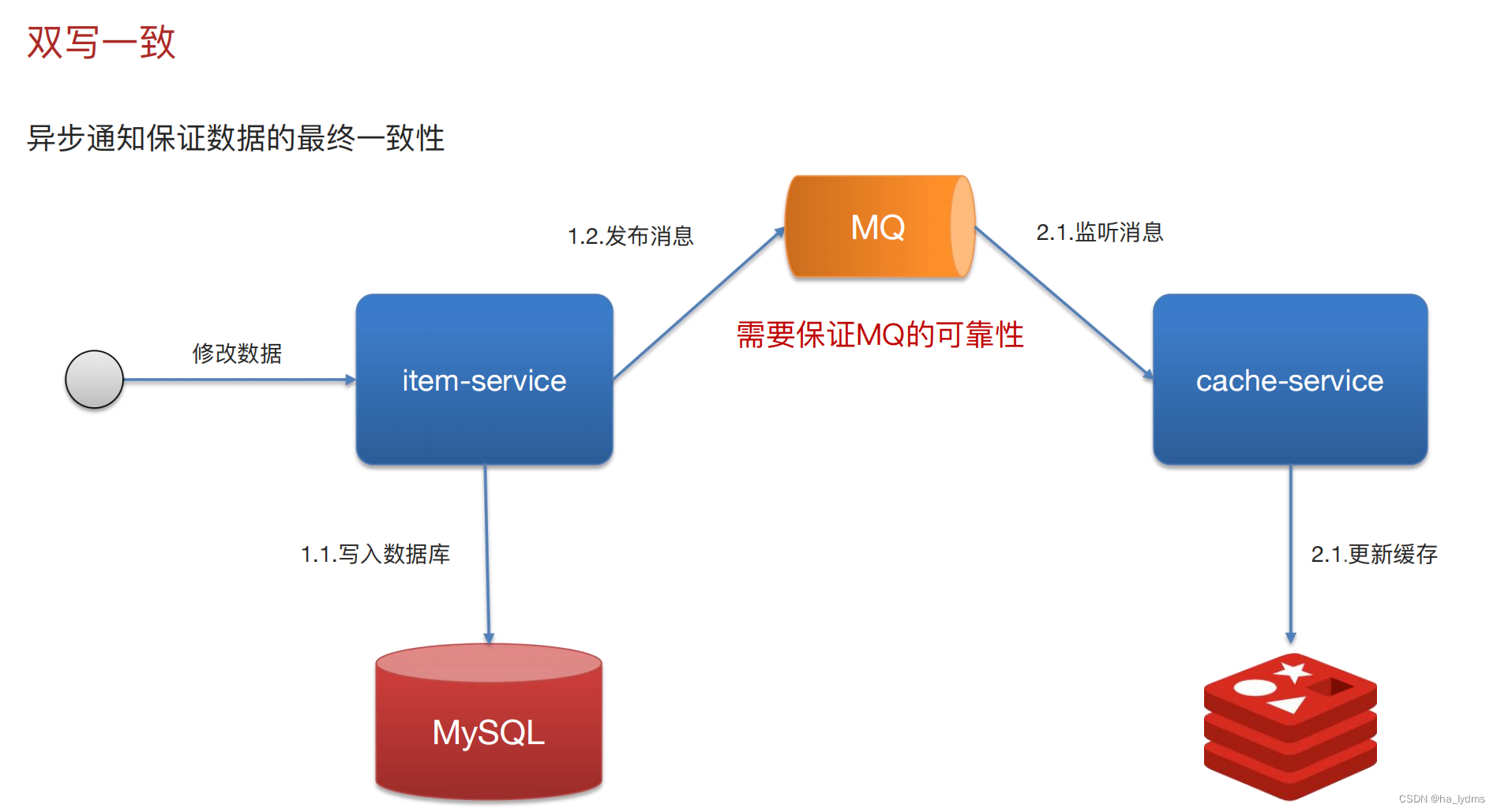
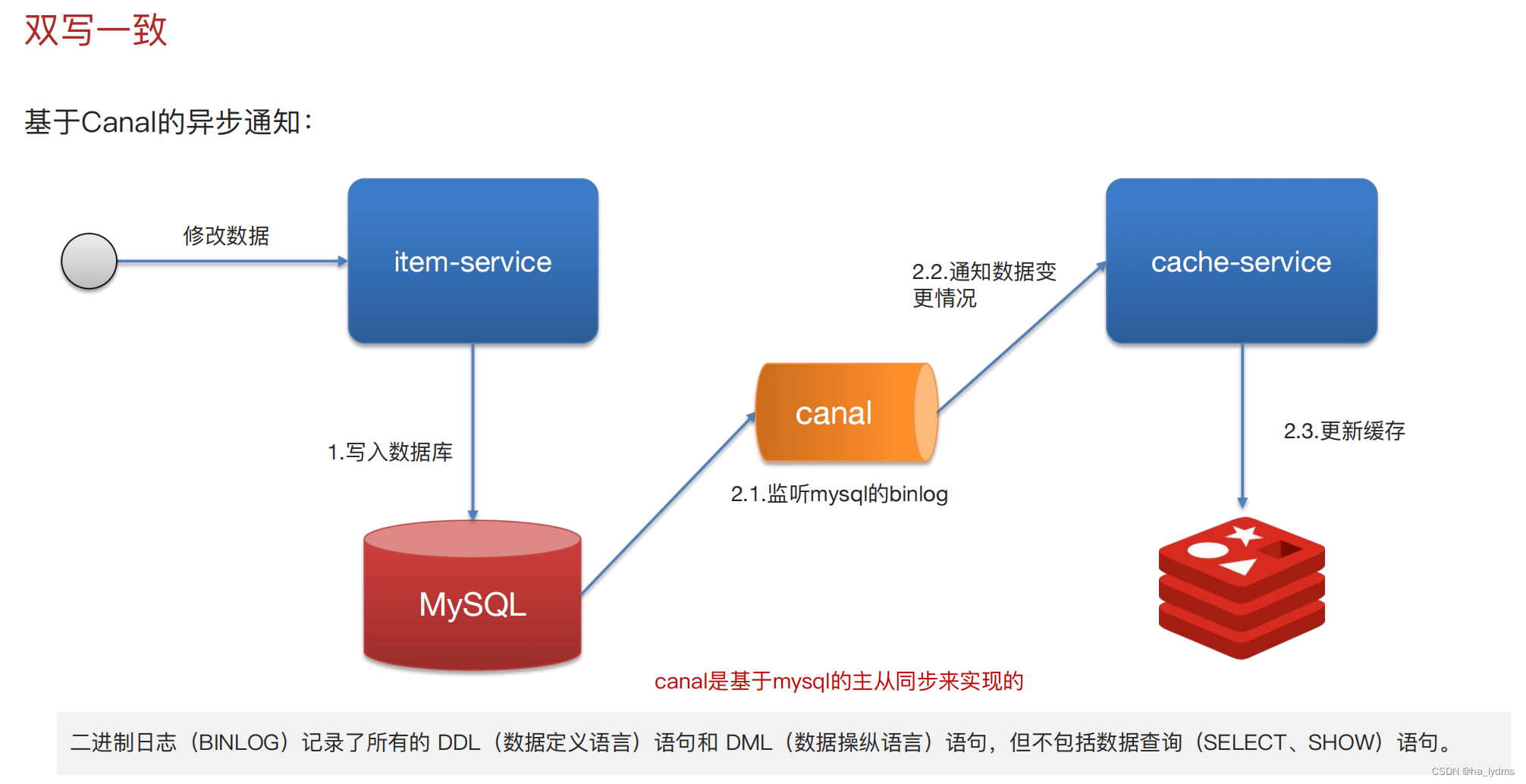
5、持久化
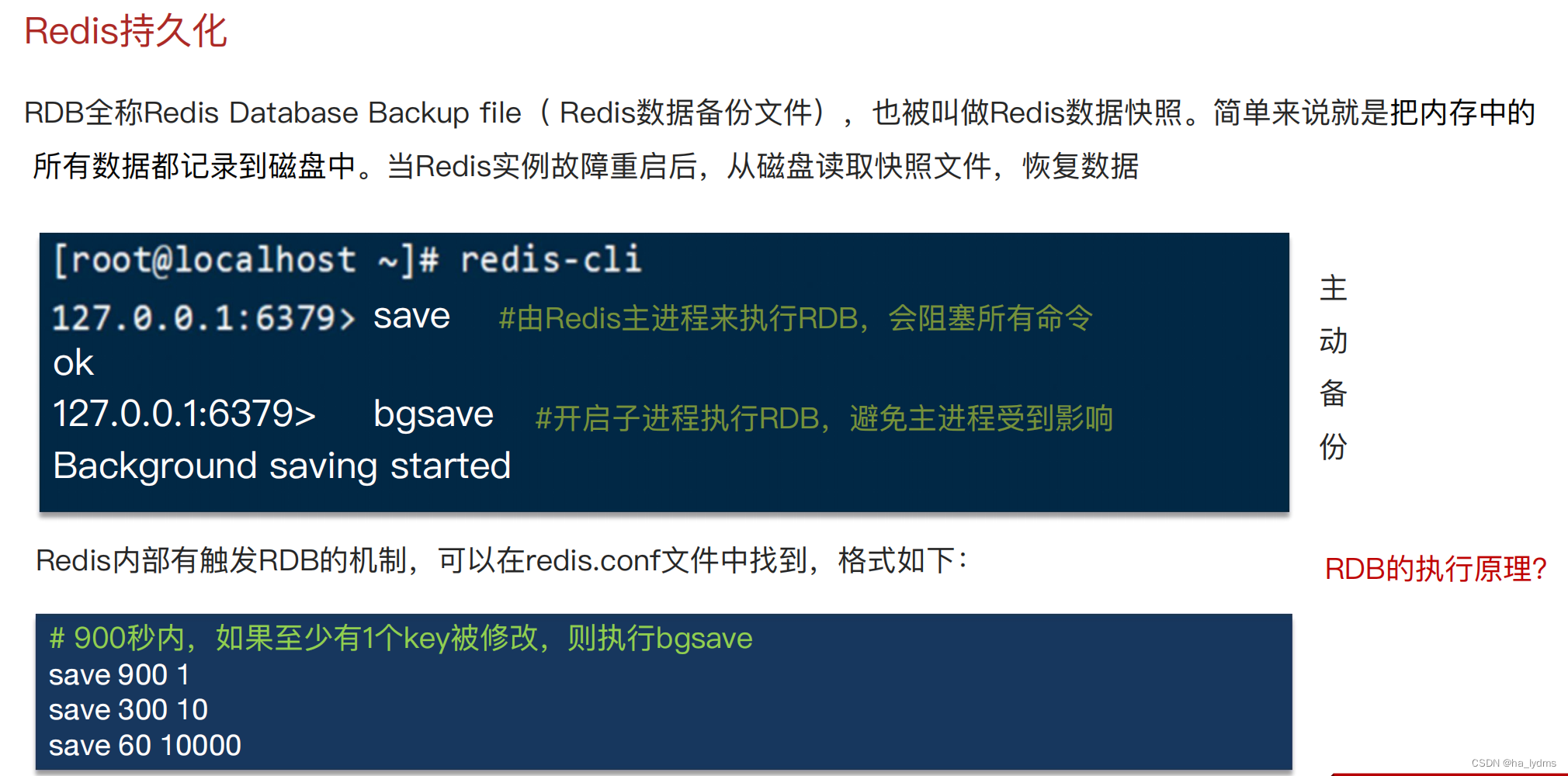
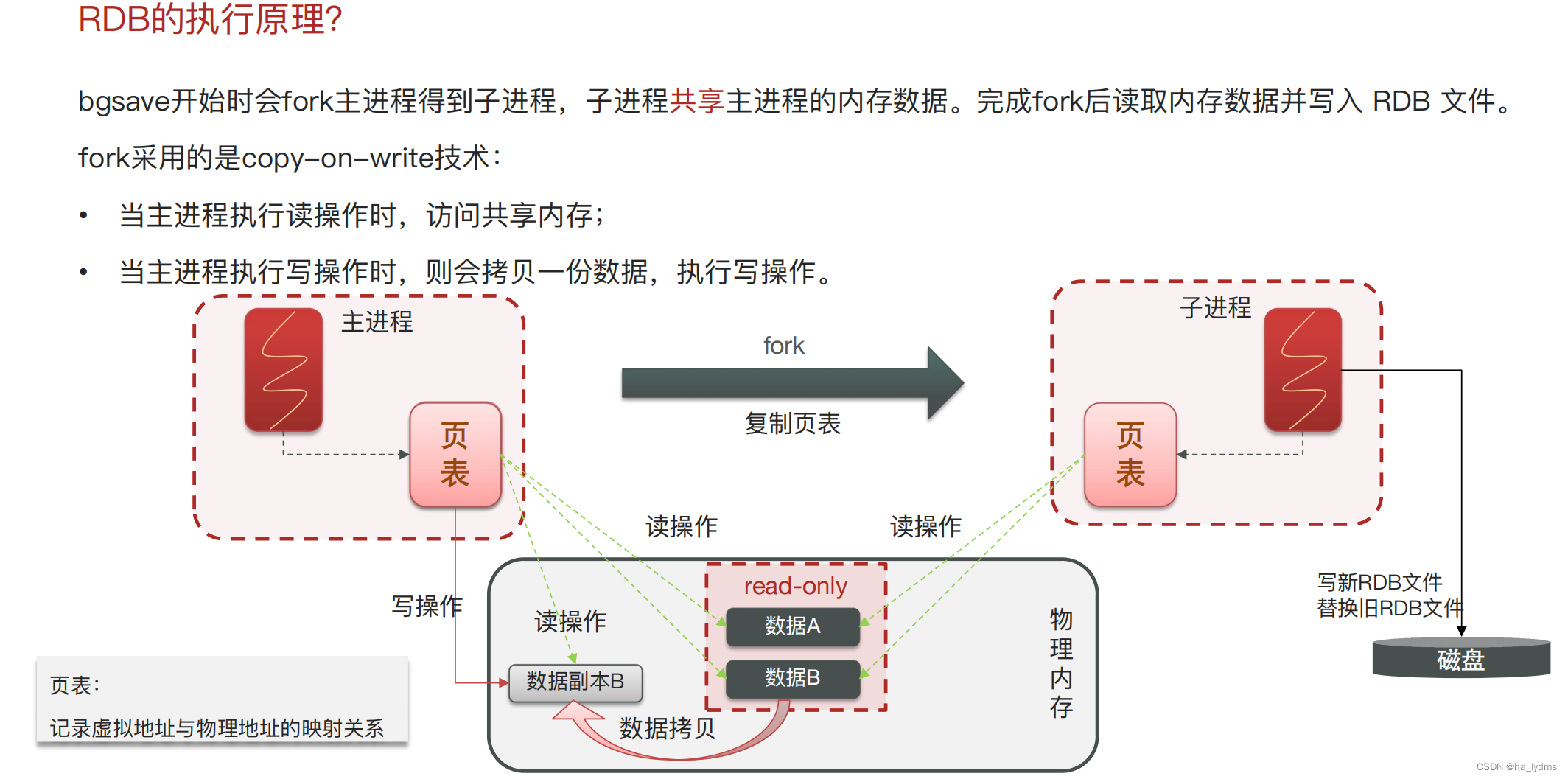
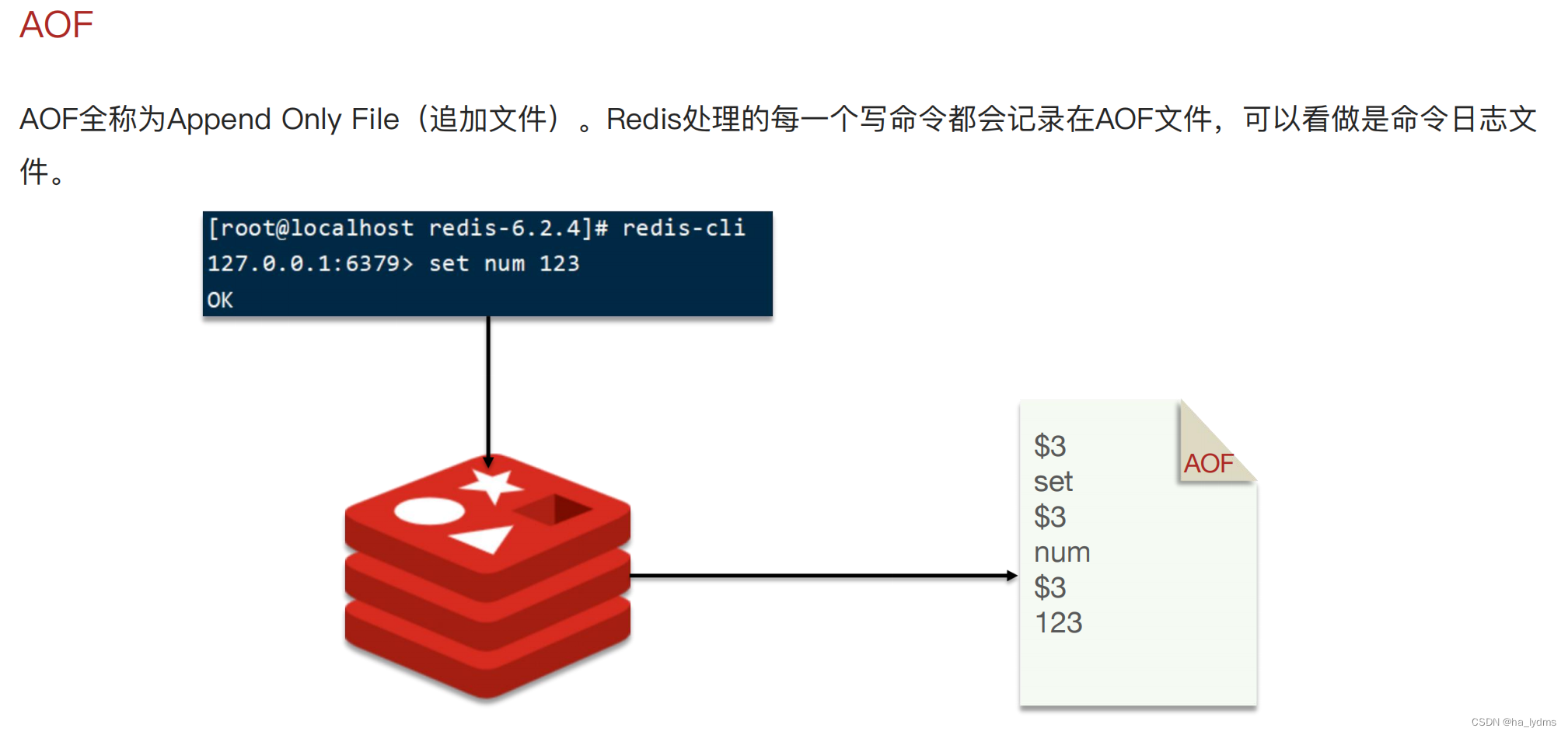


RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
6、数据过期策略


7、数据淘汰策略

数据淘汰策略-使用建议
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的
冷热数据区分,建议使用。
-
如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
-
如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
-
如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
关于数据淘汰策略其他的面试问题
- 数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据
- Redis的内存用完了会发生什么?
主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错
三、分布式锁

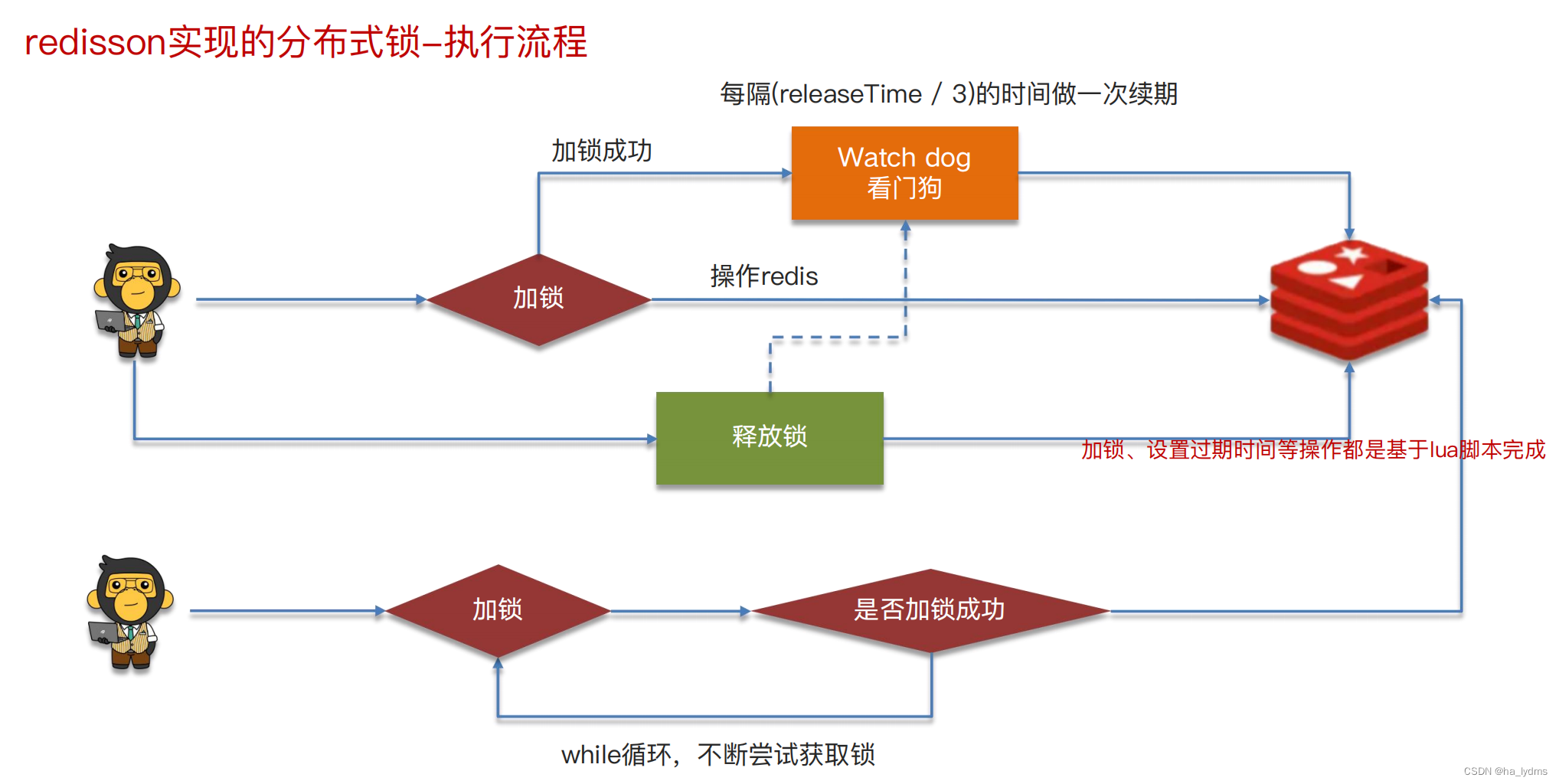
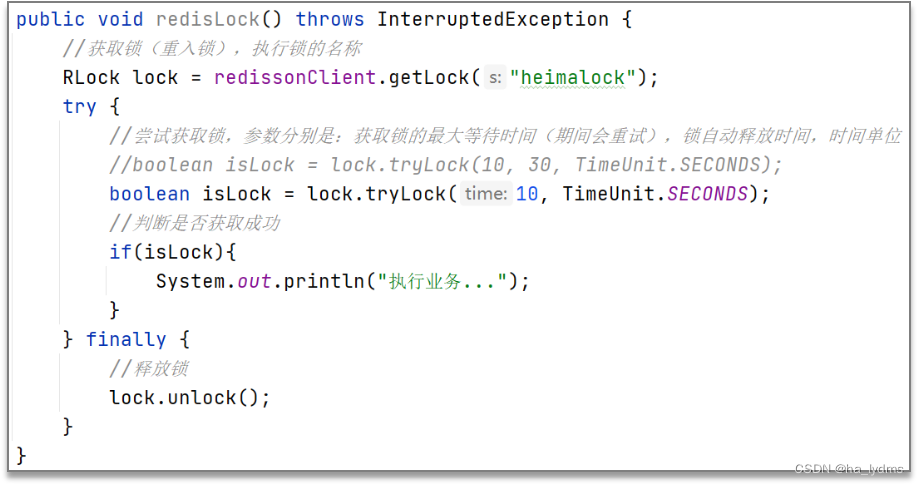

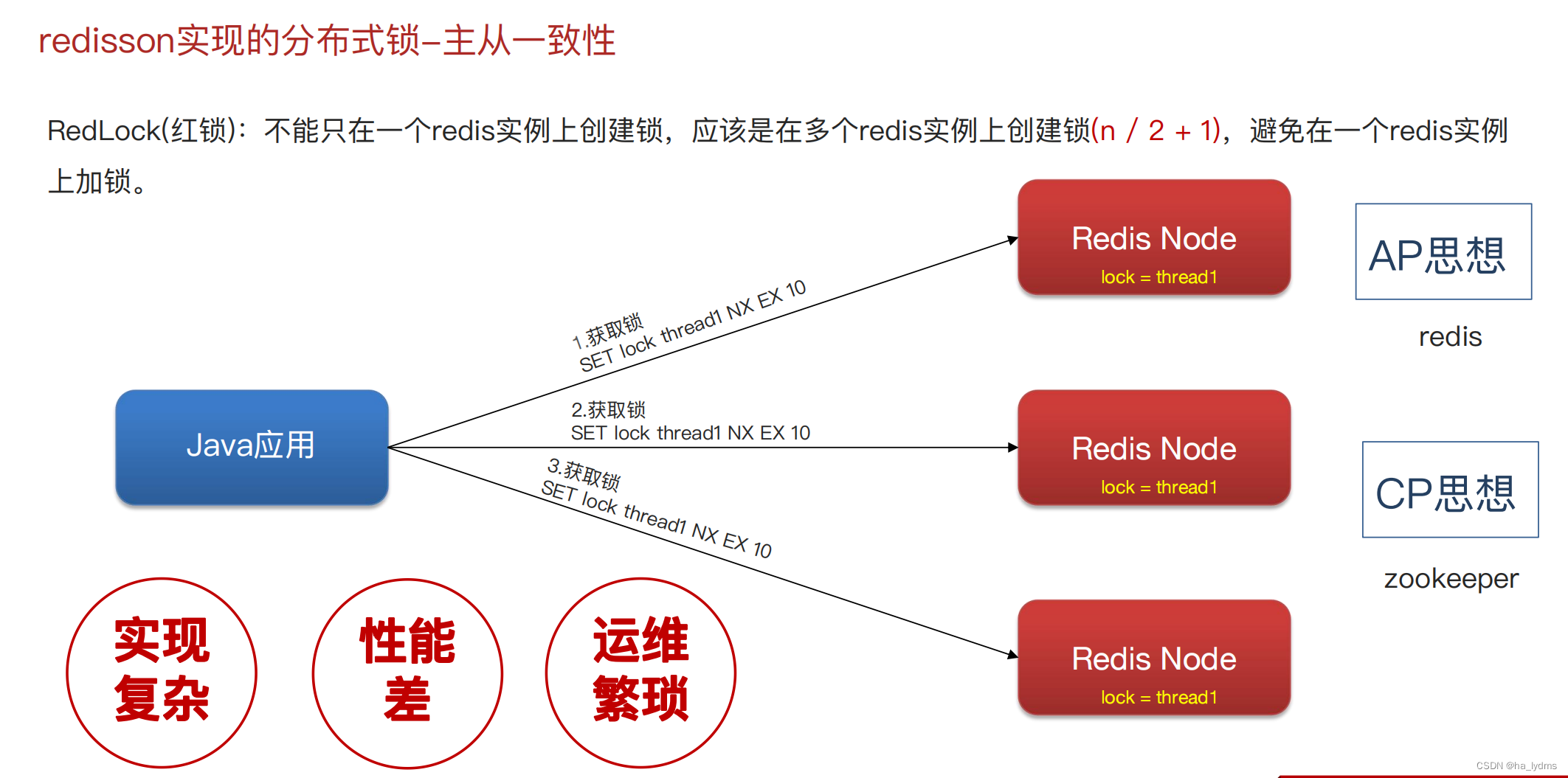

四、其它面试题
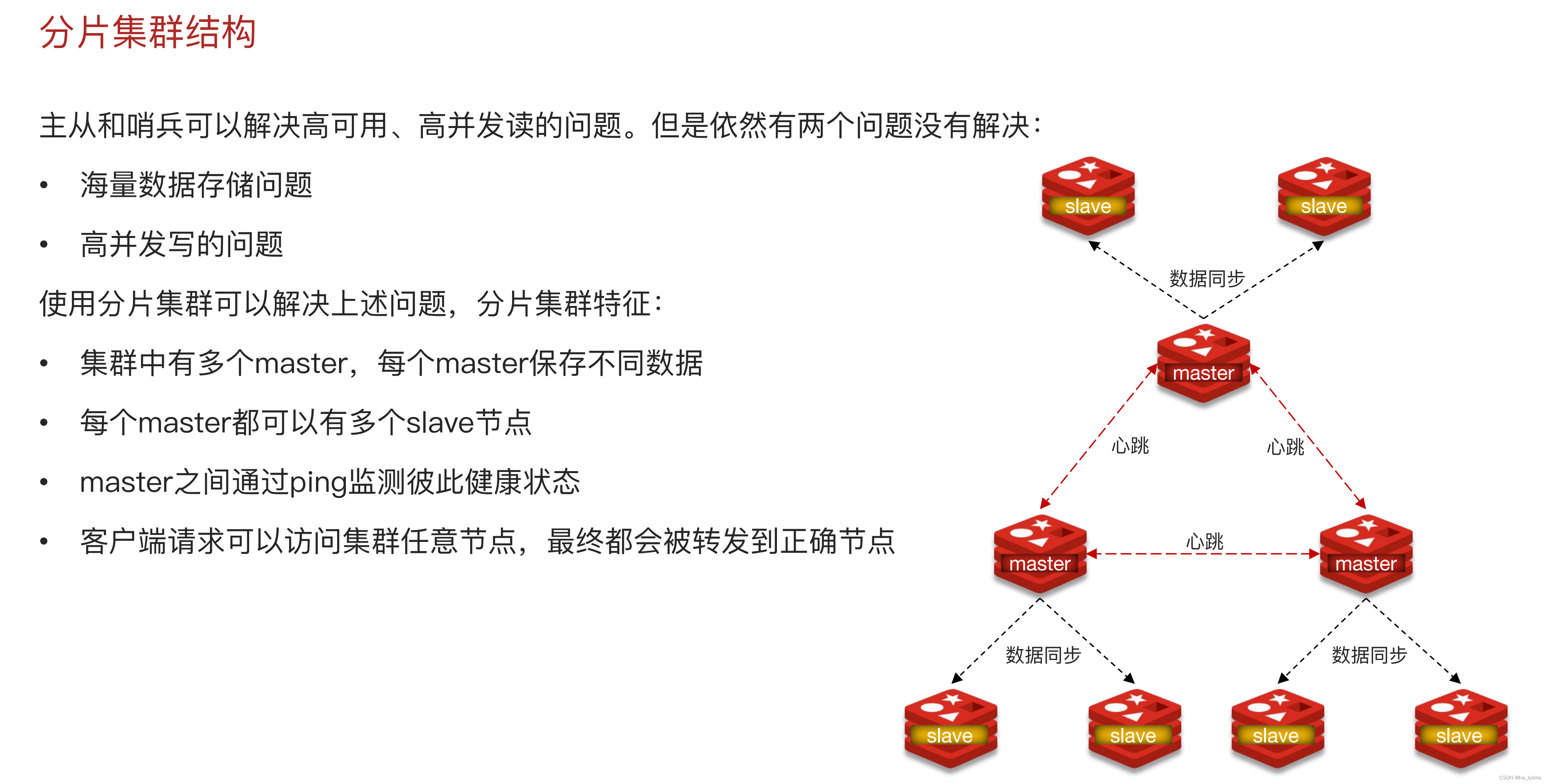
在Redis中提供的集群方案总共有三种
- 主从复制
- 哨兵模式
- 分片集群
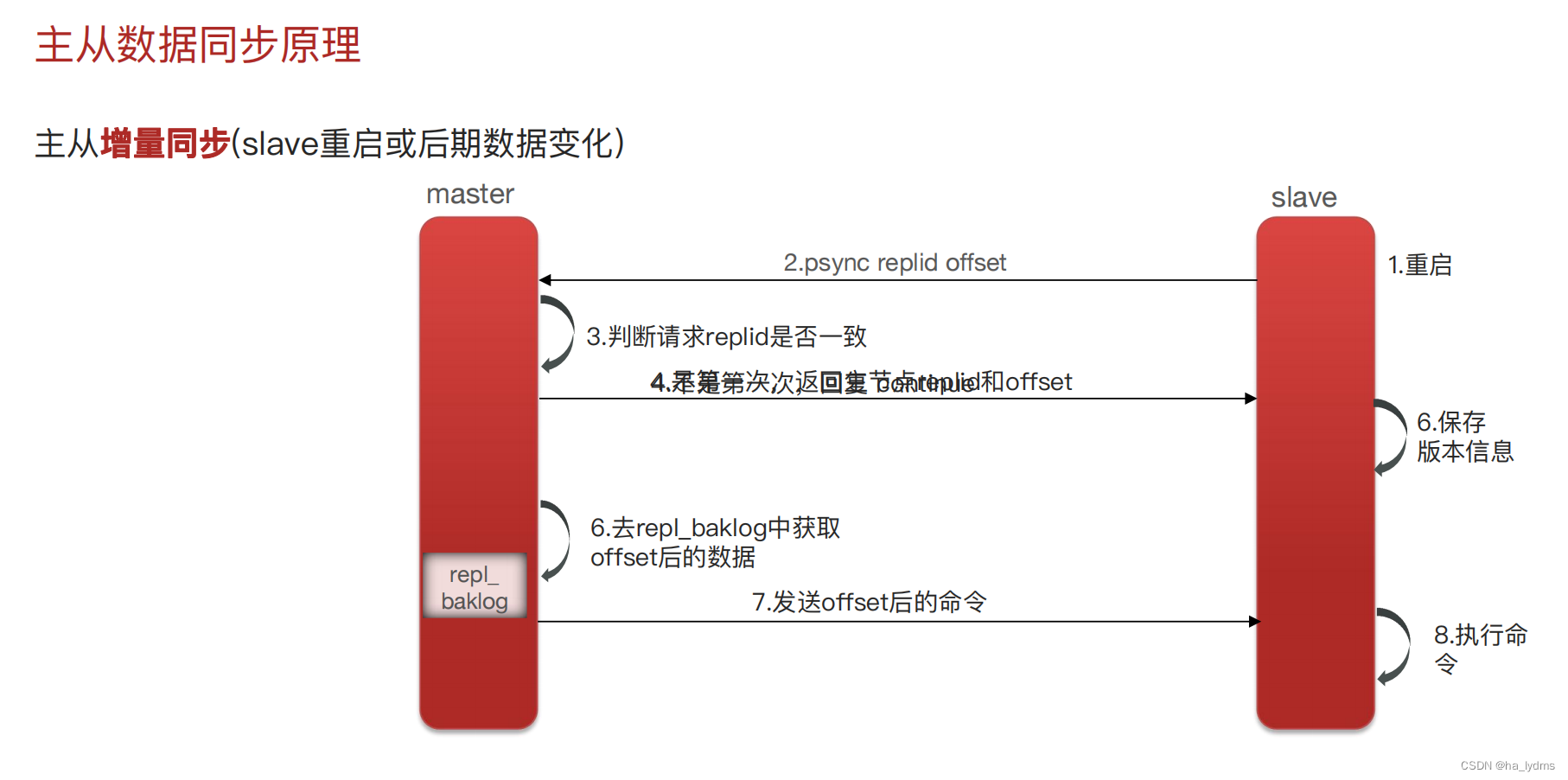
- redis主从数据同步的流程是什么?
- 怎么保证redis的高并发高可用?
- 你们使用redis是单点还是集群,哪种集群?
- Redis分片集群中数据是怎么存储和读取的?
- Redis集群脑裂,该怎么解决呢?
1、主从复制
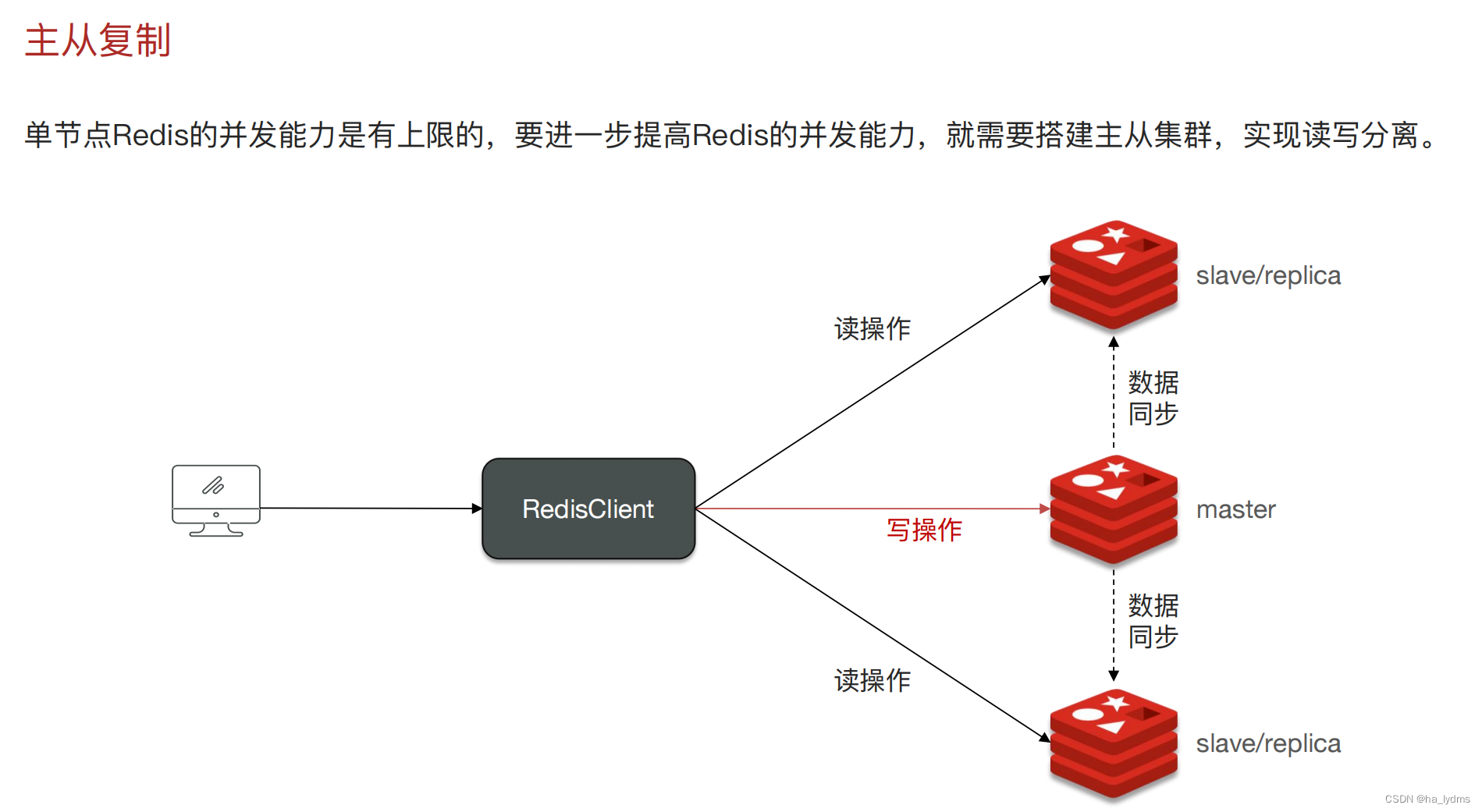


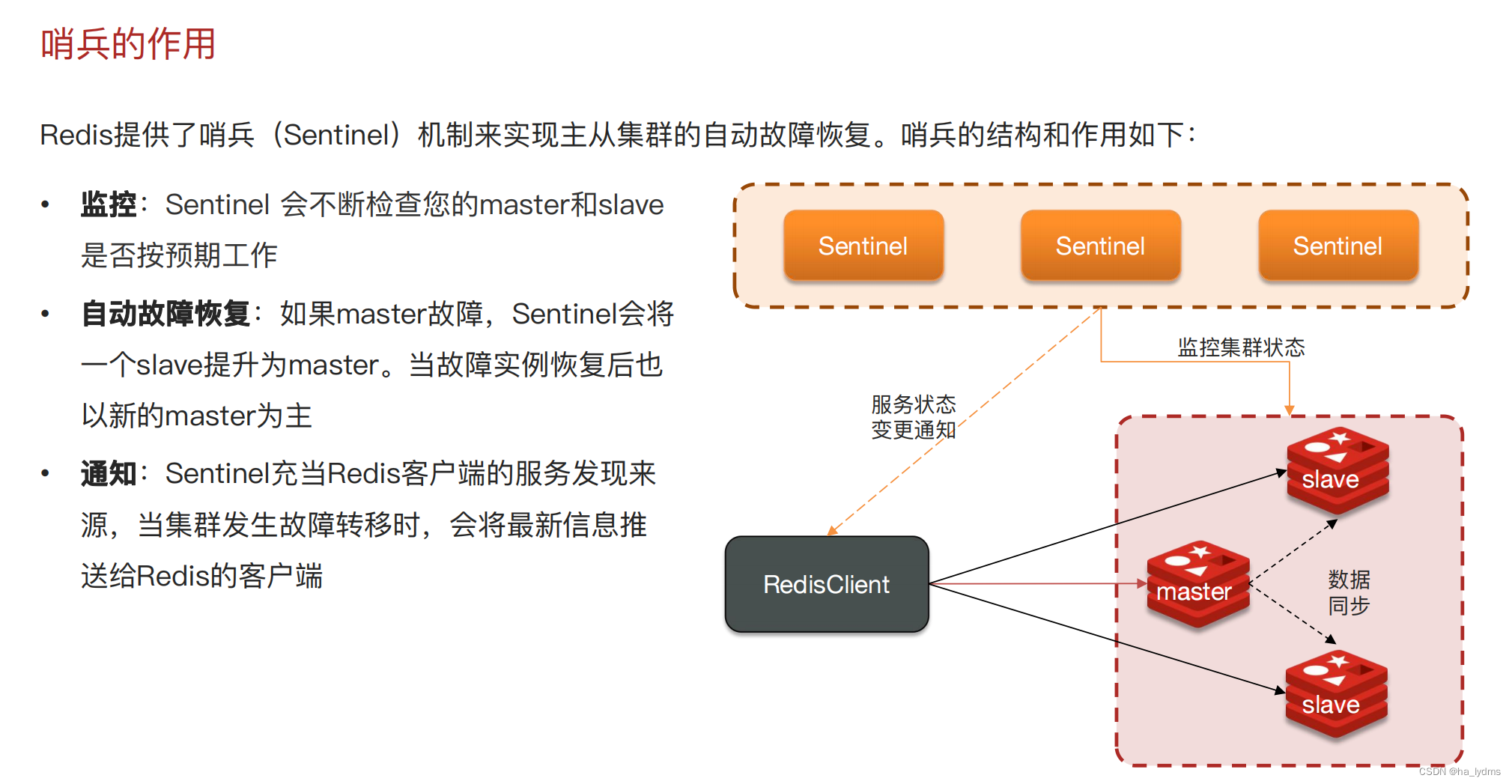
2、哨兵

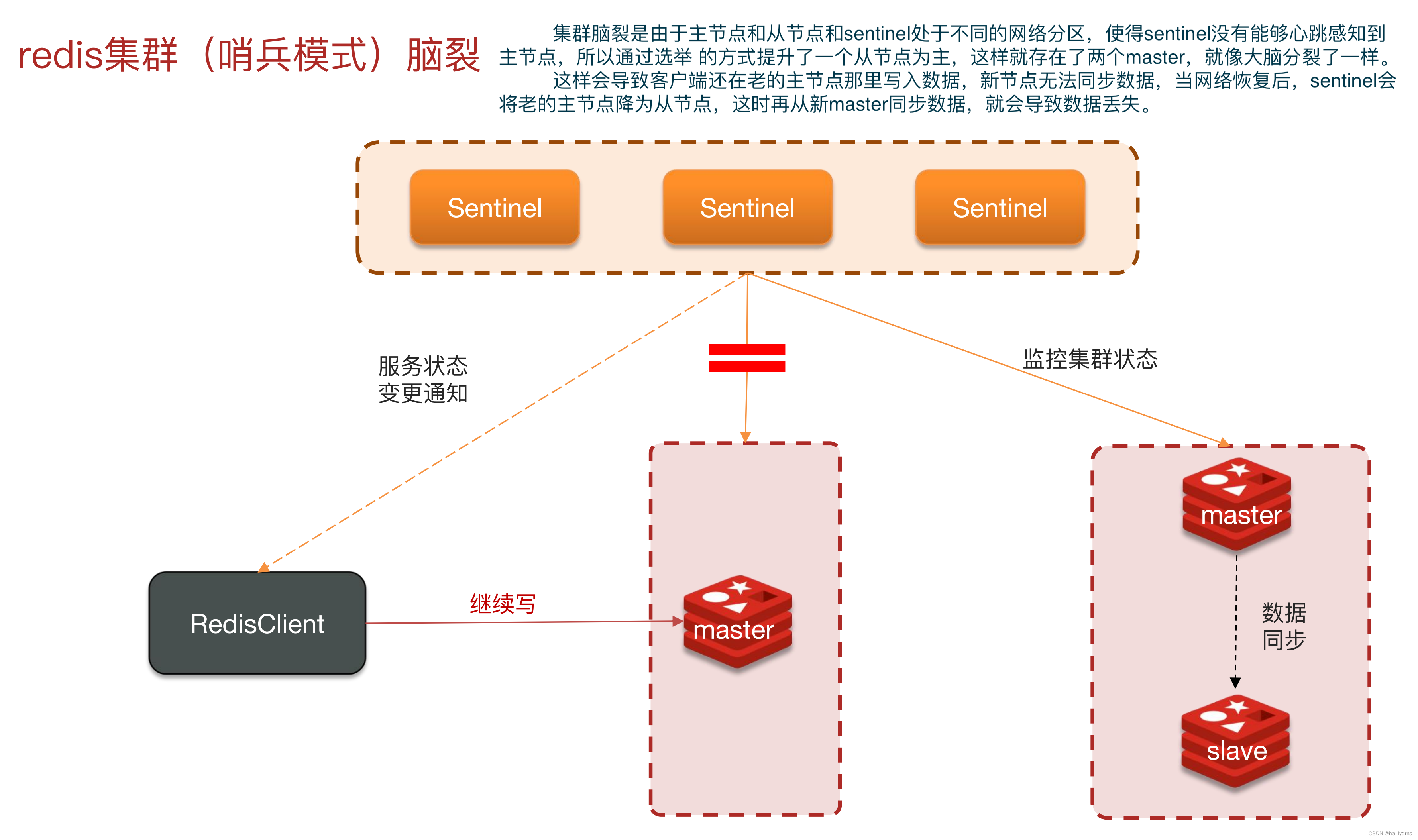
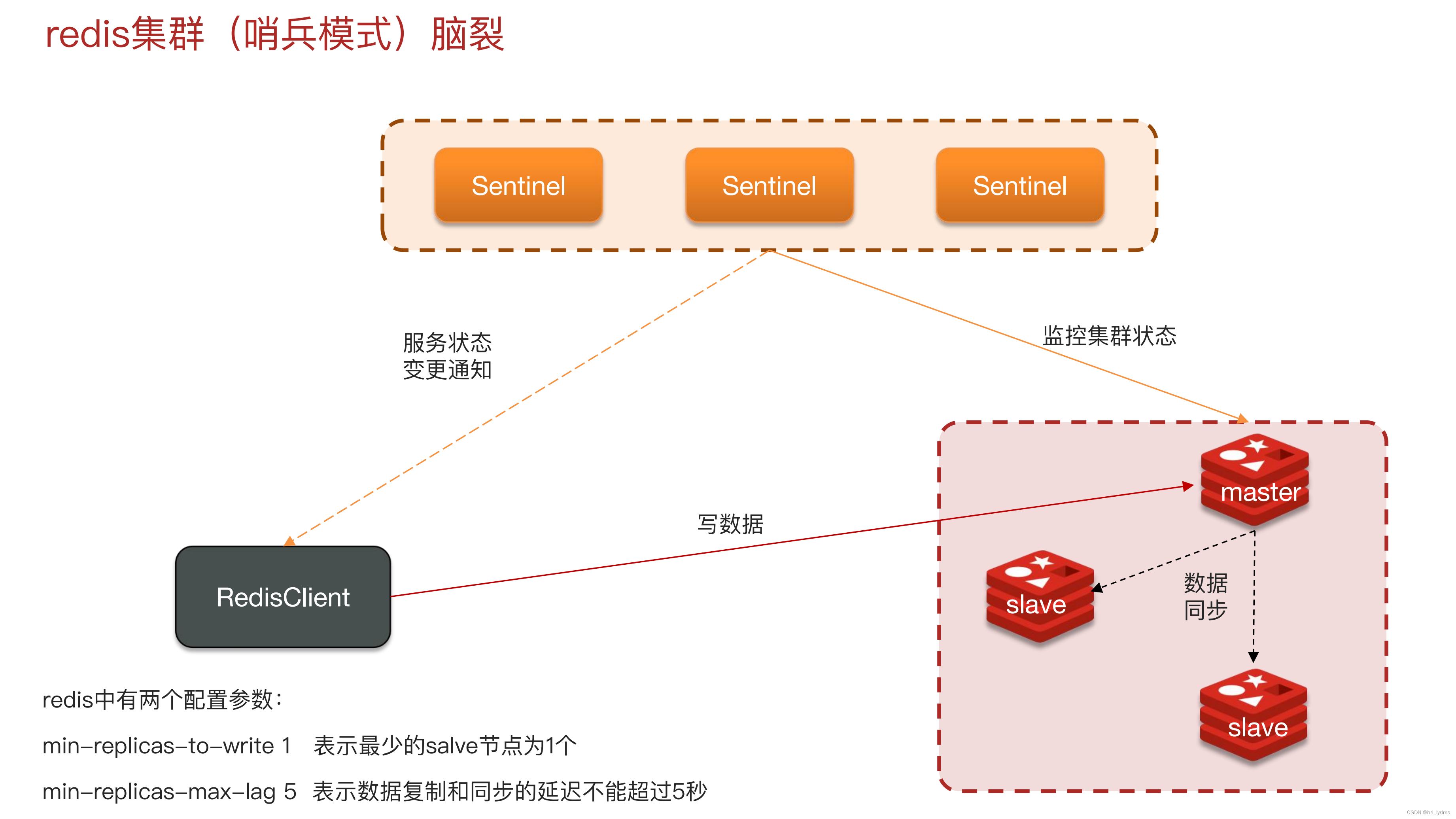

3、分片集群结构


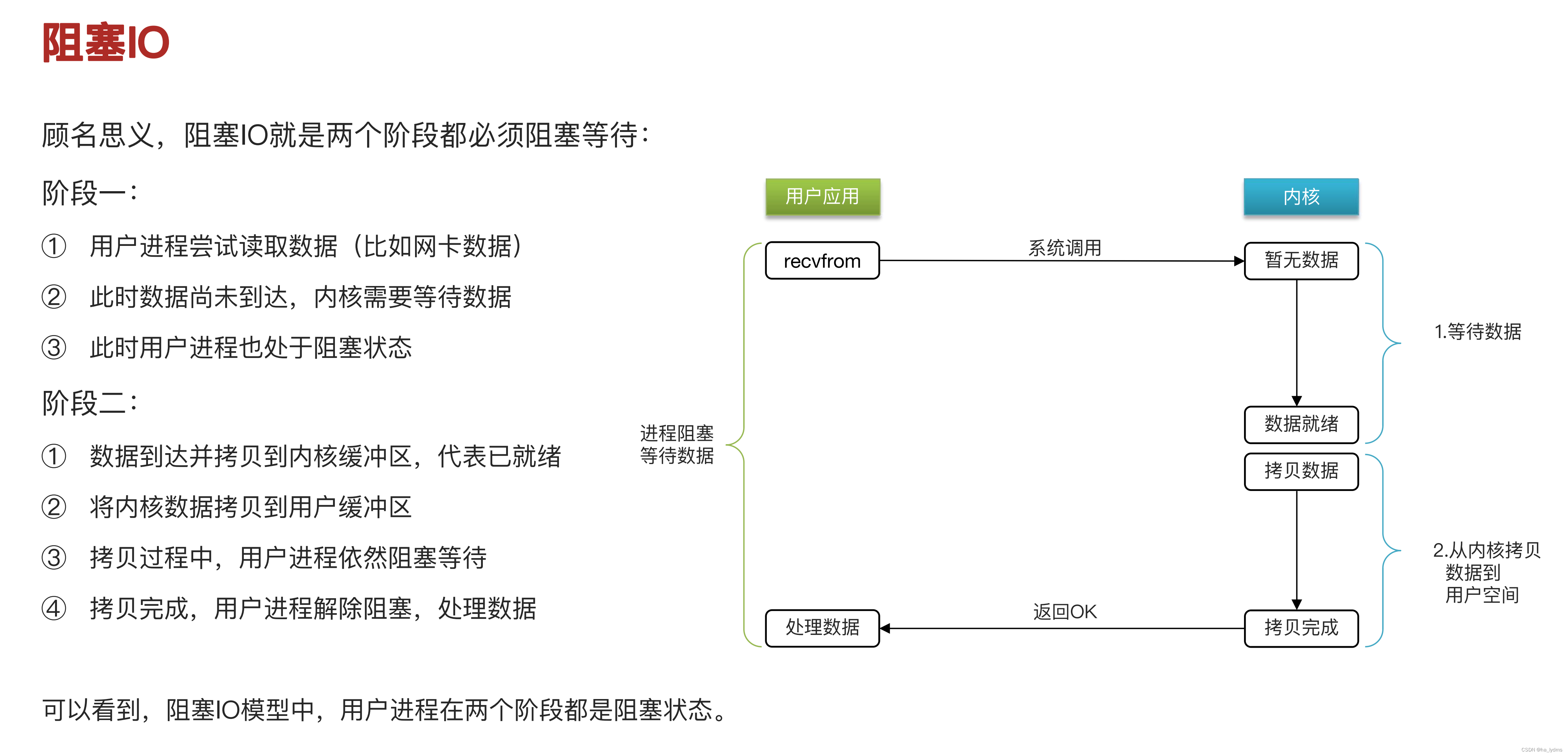
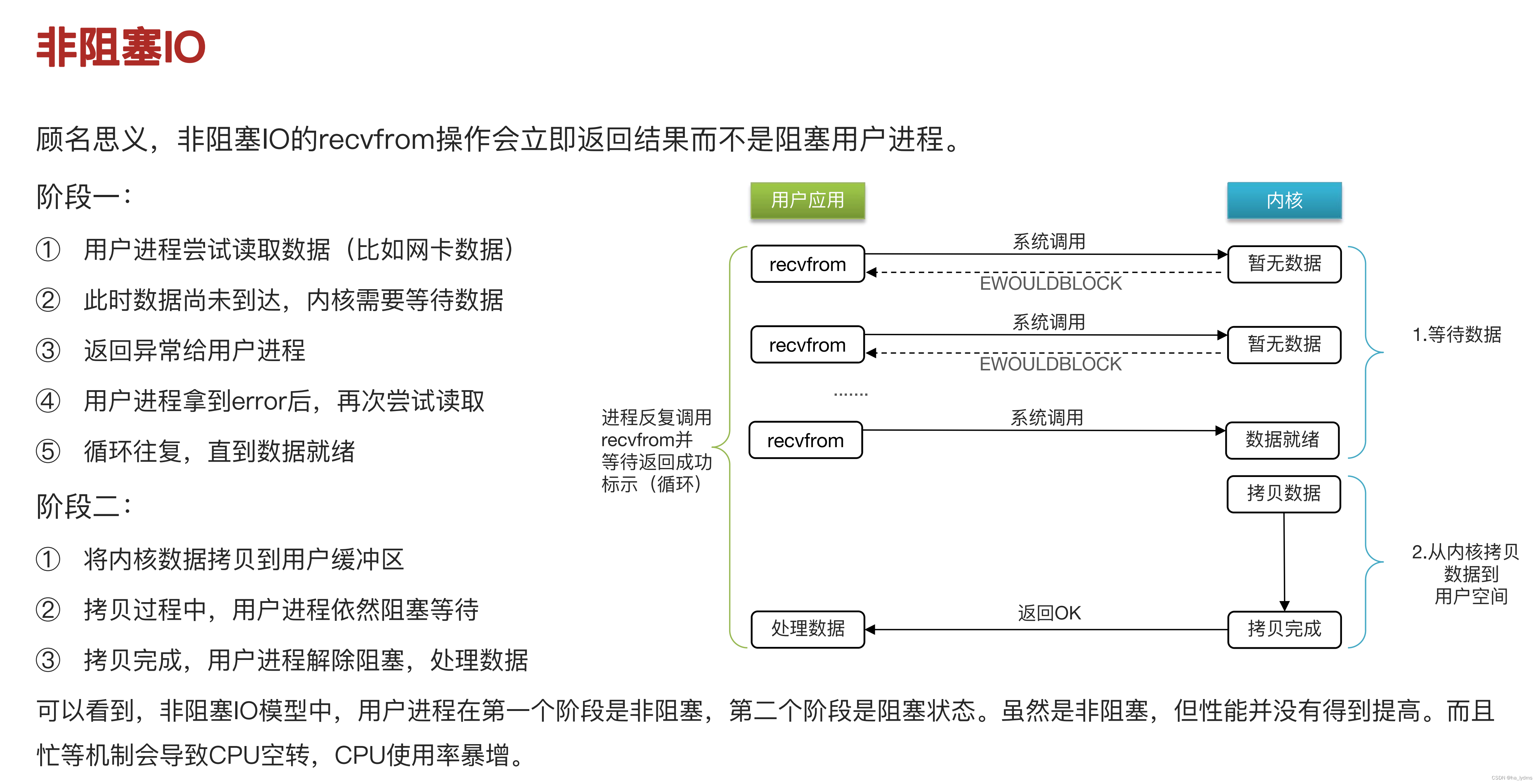
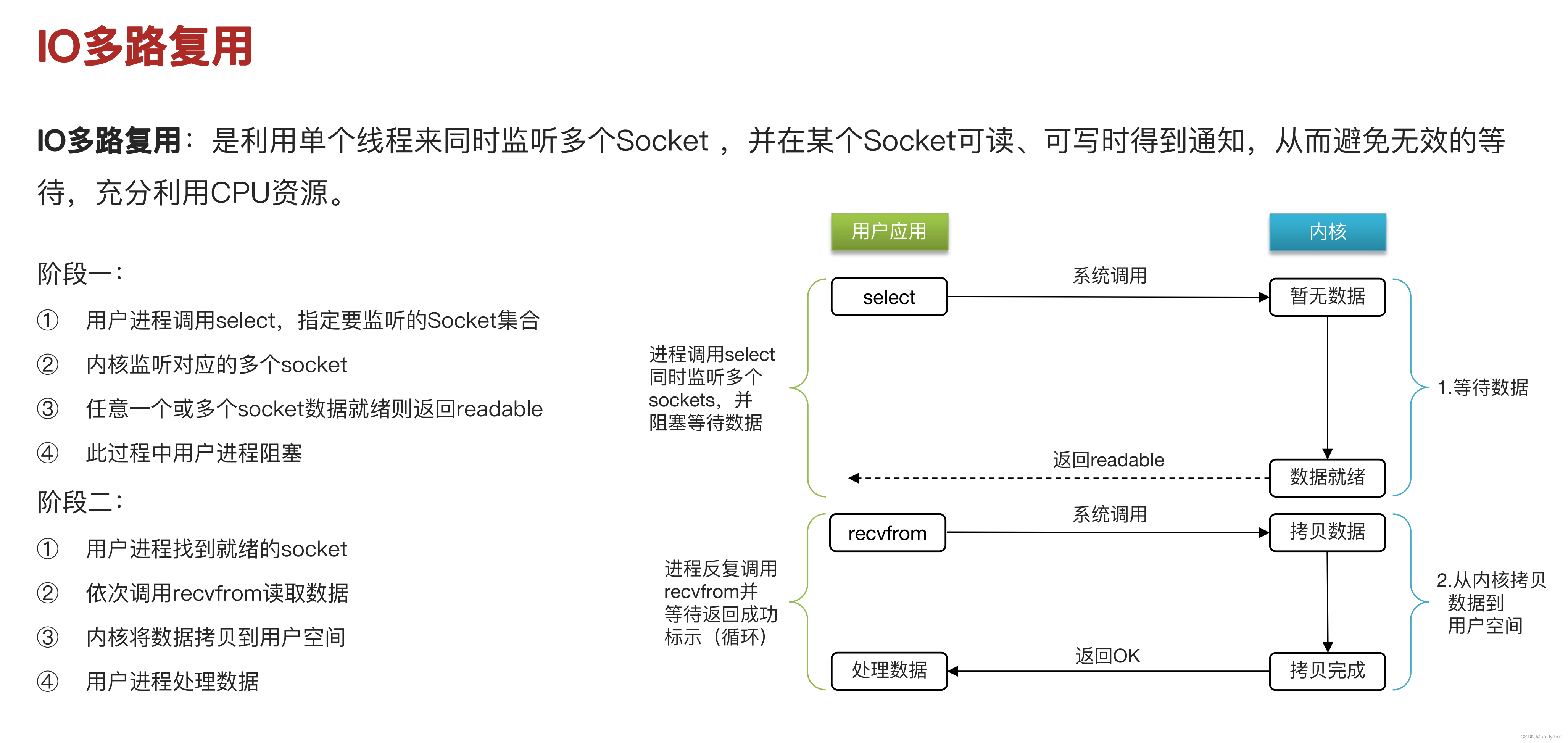
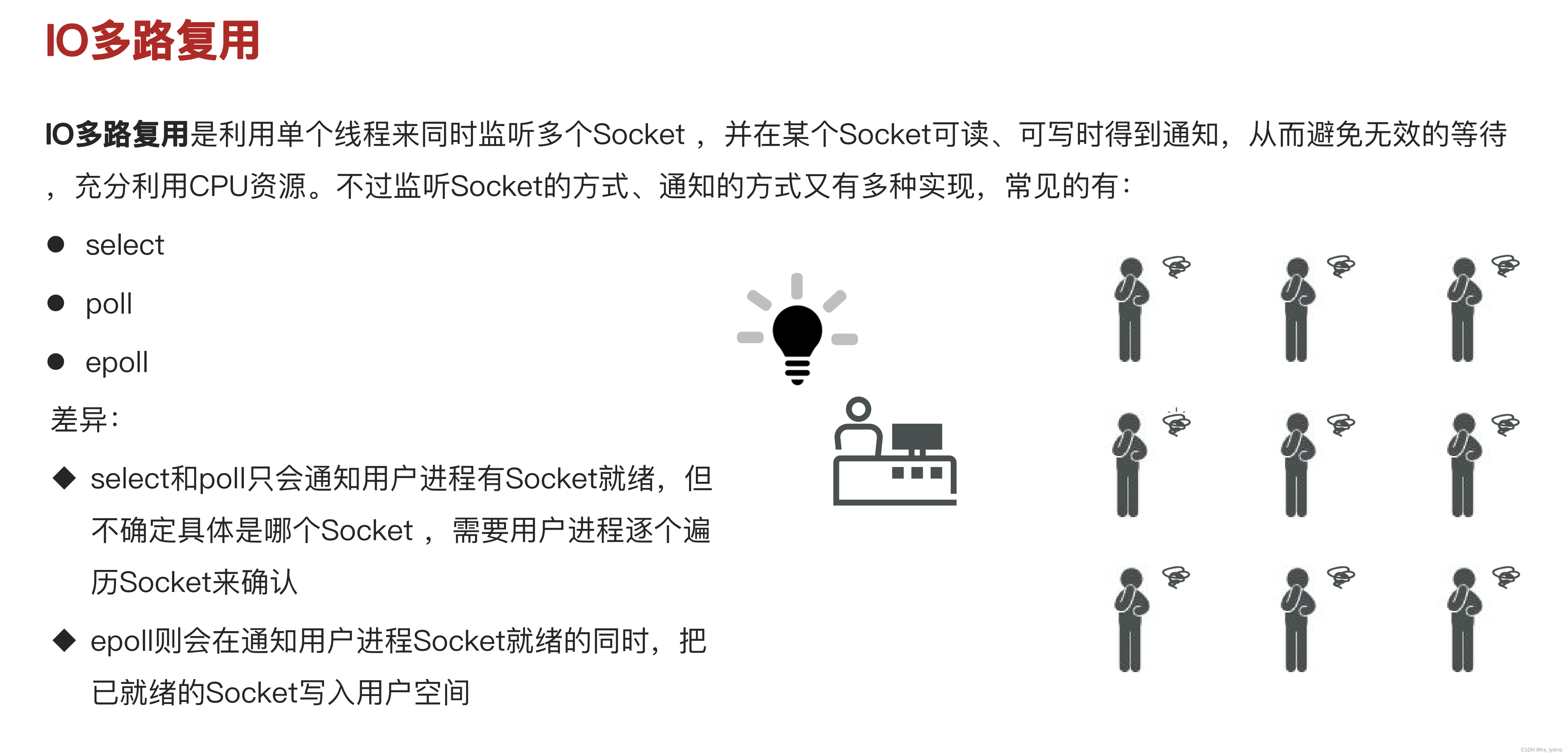
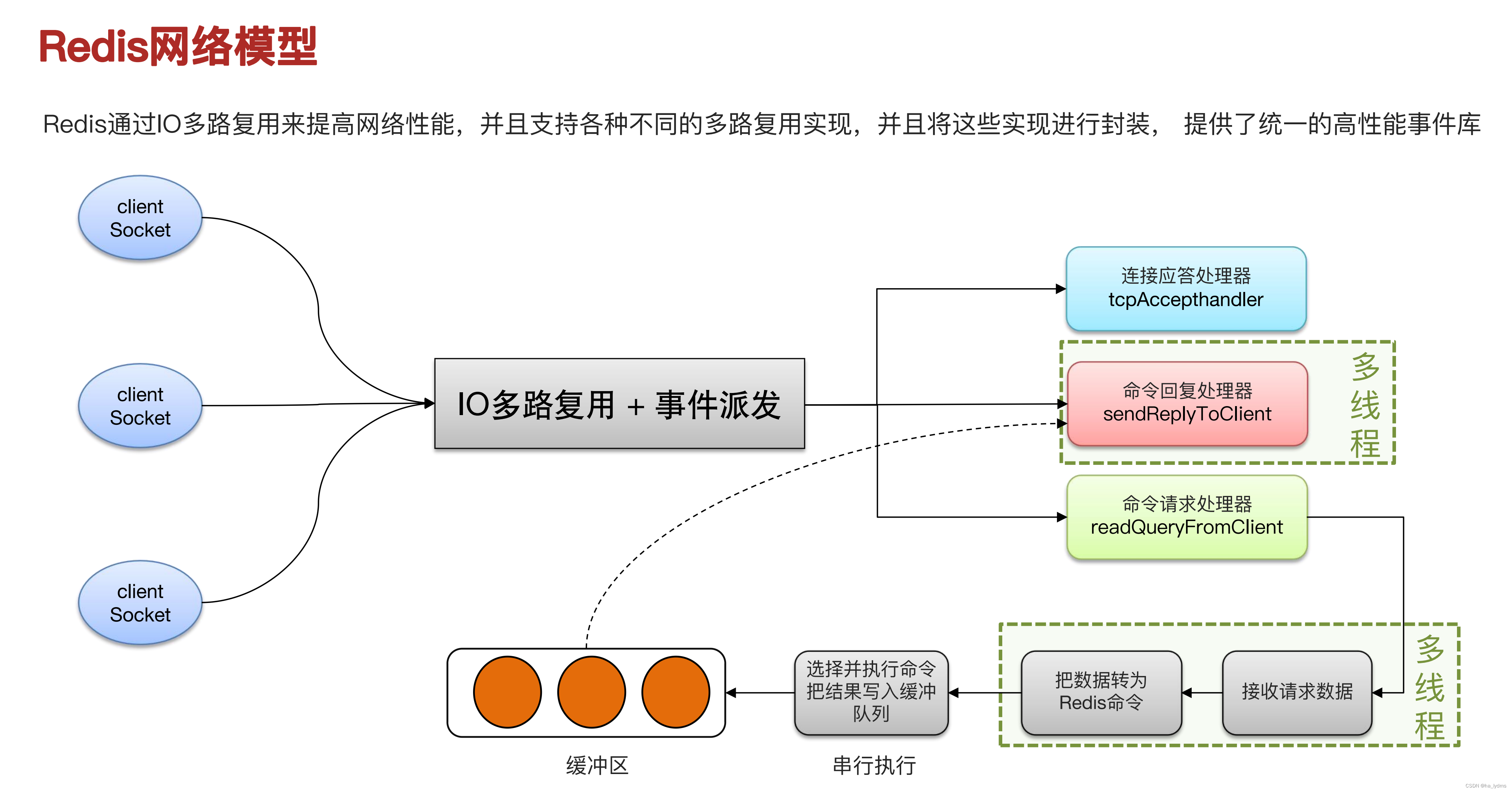
4、I/O多路复用


![[PyTorch][chapter 44][RNN]](https://img-blog.csdnimg.cn/5c9ce532a7874142a72ff4c348583dc2.png)