文章目录
- MQ的发展史
- 阶段一:追求解耦
- 阶段二:追求吞吐量与一致性
- 阶段三:追求平台化
- MQ的通用架构
- 主题topic、生产者producer、消费者consumer
- 分区partition
- MQ 存储
- Kafka
- Good Design ---> 磁盘顺序写盘
- Poor Impact---> topic 数量不能过大
- RocketMQ
- zookeeper vs namesrv
- 局部顺序写(kafka) 与 完全顺序写(rocketmq)
- Rocketmq 存储结构
- Pulsar
- 架构图(分层+分片)
- 服务层设计
- 存储层设计
- 扩容
- 容灾
- 小结

MQ的发展史

如上图我们可以把消息队列的发展切分成了三个大的阶段
阶段一:追求解耦
- 2003-2010年,计算机软件行业兴起。
- 系统间强耦合是程序设计的难题。
- ActiveMQ和RabbitMQ等消息队列出现。
- 消息队列致力于解决系统间耦合和异步化操作问题。
- 系统间解耦和异步化是消息队列最主要的功能和使用场景。
阶段二:追求吞吐量与一致性
- 10 -12 年期间,大数据时代实时计算需求增长,数据规模扩大,Kafka应运而生满足消息队列高吞吐量和并发需求。
- 随着阿里电商业务发展,Kafka在可靠性、一致性、顺序消息等方面无法满足需求。
- RocketMQ诞生,吸收Kafka设计理念之余,解决其痛点。
- RocketMQ不依赖Zookeeper,增强可靠性、一致性、顺序消息能力。
- 阿里将RocketMQ开源,最终成为Apache项目,满足大数据 messaging 需求。
阶段三:追求平台化
- 平台化的产品会取代非平台化的产品,这是行业发展趋势。
- 2012年后,云计算、容器化兴起,公司开始把基础技术能力平台化。
- 阿里云、腾讯云等云服务的出现证明了这一趋势。
- Pulsar诞生于此背景下,目的是解决雅虎内部重复建设、消息队列隔离不好、数据迁移难等问题。
- Pulsar通过提供平台化的消息队列服务来解决这些问题。
- 平台化是Pulsar产生的核心原因,也是解决上述问题的关键所在。
MQ的通用架构
主题topic、生产者producer、消费者consumer
用吃饭的场景生动地诠释了消息队列的几个关键概念:
- 饭堂的不同档口(米饭、面、麻辣香锅)对应消息队列的主题(topic)概念。
- 用户选择某个档口排队取餐,这个过程相当于生产者生产了一条消息到该主题的消息队列中。
- 档口将餐食提供给用户,则相当于消费者从消息队列中消费了一条消息。
- 用户排队等待相当于消息在队列中的存储等待被消费的过程。
- 取餐按排队顺序进行,消费也是按顺序进行的。
通过日常生活的吃饭场景,形象地解释了消息队列的工作原理,包括消息主题、生产者、消费者、消息存储和消费等核心概念。这些概念抽象起来可能较难理解,但结合具象的例子就很容易理解了
分区partition
- 分区是消息队列的一种架构方式,类似于食堂的多个档口。
- 当消息数量增长时,可以通过增加分区数进行扩容,如食堂增加档口数。
- 增加分区可以扩大消息队列的并行处理能力,提高吞吐量,就像增加档口可以减少等待时间。
- 生产者可以根据分区规则,将消息发到不同分区,就像食客可以选择人少的档口。
- 消费者可以从多个分区并行消费消息,提高效率。
- Kafka之所以能达到高吞吐量,是因为它是通过分区实现消息队列并行化和横向扩展的。
总结为:分区实现了消息队列的并行化,是提升吞吐量和实现横向扩展的关键手段。
MQ 存储
特性和性能是存储结构的外在表现,其实质是存储设计。我们需要了解每种消息传递协议的特性,以便更好地理解它们的架构设计。
我们将首先介绍 Kafka、RocketMQ 和 Pulsar 的架构特点,然后比较它们在架构上的不同之处,以及这些不同之处如何影响它们的功能特性。
Kafka
- Kafka 架构中,服务节点没有主从之分,主从概念是针对某个 topic 下的分区。
- 存储单位为分区,通过不同方式分散在各个节点,形成各种架构图。
- 生产者数量为 1,消费者数量为 1,分区数为 2,副本数为 3,服务节点数为 3。
- 图中有两块绿色图案,分别为 topic1-partition1 分区和 topic1-partition2 分区,浅绿色方块为它们的副本。
- 对于服务节点 1,topic1-partition1 是主节点;对于服务节点 2,topic1-partition2 是主节点。
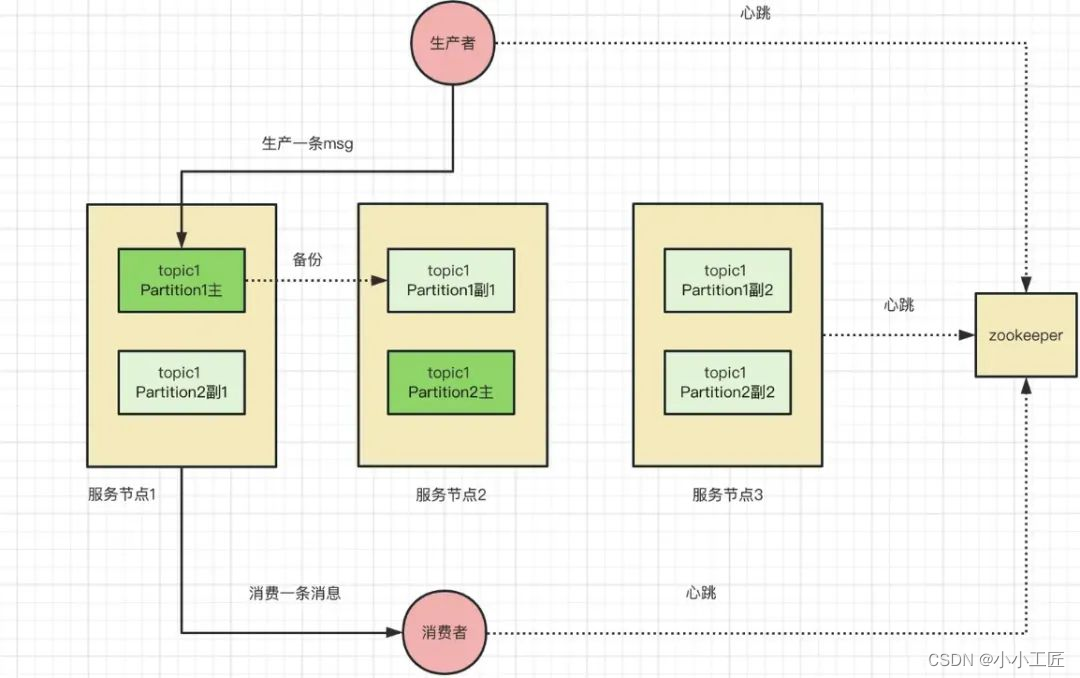
消息队列的大致工作流程如下:
- 生产者、消费者与元数据中心建立连接,并保持心跳,获取服务的实况和路由信息。
- 生产者将消息发送到 topic 下的任一分区中,通过算法保证每个 topic 下的分区尽可能均匀。
- 信息需要落盘才可以给上游返回 ack,以保证宕机后的信息的完整性。
- 在信息写成功主分区后,系统会根据策略选择同步复制还是异步复制,以保证单节点故障时的信息完整性。
- 消费者开始工作,拉取响应的信息,并返回 ack。
- 消费者在获取消息时,会根据偏移量 (offset) 进行拉取,每次拉取后偏移量加 1。
Good Design —> 磁盘顺序写盘
Kafka 在底层设计上强依赖于文件系统(一个分区对应一个文件系统),本质上是基于磁盘存储的消息队列,在我们固有印象中磁盘的读写速度是非常慢的,慢的原因是因为在读写的过程中所有的进程都在抢占“磁头”这把锁,磁头在读写之前需要将其移动到合适的位置,这个“移动”极其耗费时间,这也就是磁盘慢的原因,但是如何不用移动磁头呢,顺序写盘就诞生了。
Kafka 消息存储在分区中,每个分区对应一组连续的物理空间。新消息追加到磁盘文件末尾。消费者按顺序拉取分区数据消费。Kafka 的读写是顺序的,可以高效地利用 PageCache,解决磁盘读写的性能问题。
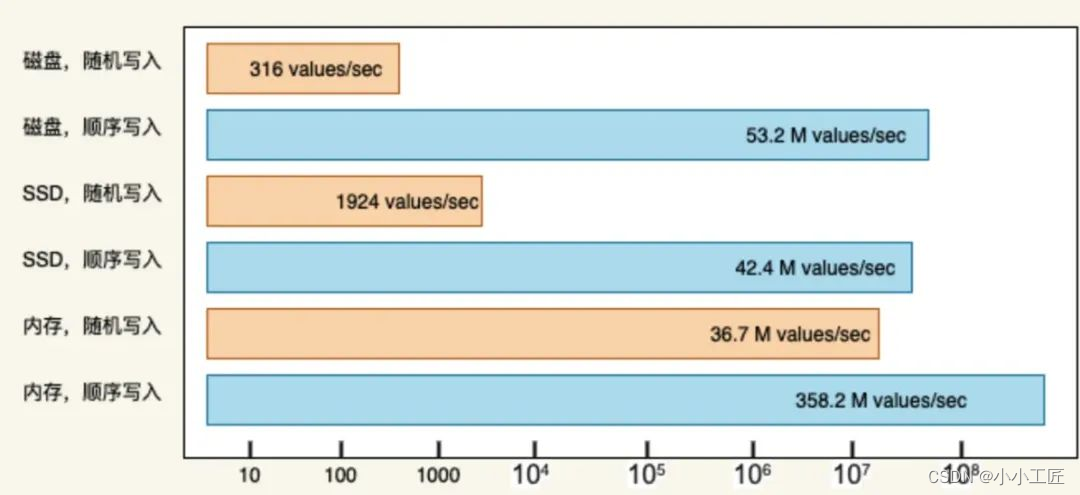
这一特性非常重要,很多组件的底层存储设计都会用到这点,理解好这点对理解消息队列尤为重要。
The Pathologies of Big Data
Poor Impact—> topic 数量不能过大
kafka 的整体性能收到了 topic 数量的限制,这和底层的存储有密不可分的关系,我们上面讲过,当消息来的时候,底层数据使用追加写入的方式,顺序写盘,使得整体的写性能大大提高,但这并不能代表所有情况,当我们 topic 数量从几个变成上千个的时候,情况就有所不同了
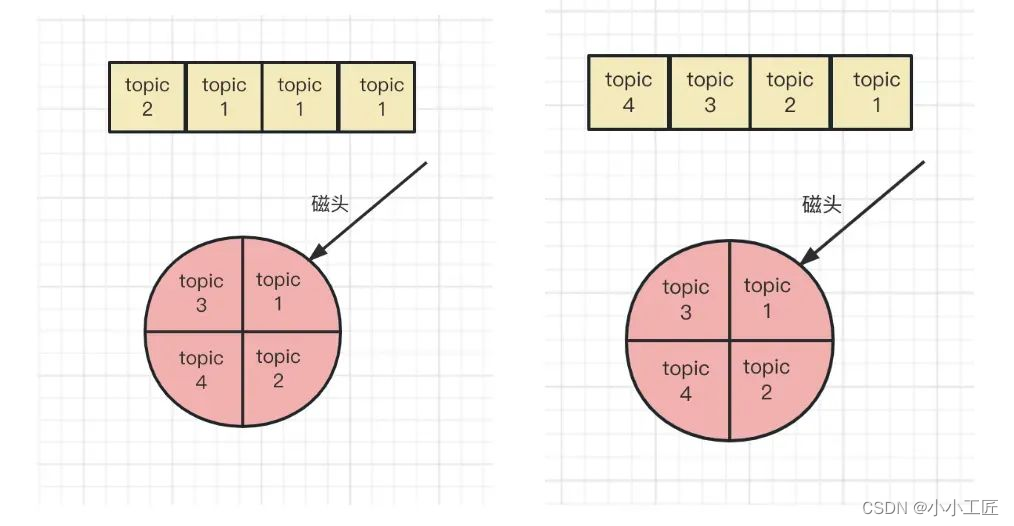
- 左图代表了,队列中从头到尾的信息为:topic1、topic1、topic1、topic2,在这种情况下,很好地运用了顺序写盘的特性,磁头不用去移动
- 右边图的情况,队列中从头到尾的信息为:topic1、topic2、topic3、topic4,当队列中的信息变的很分散的时候,这个时候我们会发现,似乎没有办法利用磁盘的顺序写盘的特性,因为每次写完一种信息,磁头都需要进行移动
就很好理解,为什么当 topic 数量很大时,kafka 的性能会急剧下降了。
当然没有其他办法了吗,当然有。我们可以把存储换成速度更快 ssd 或者针对每一个分区都搞一块磁盘,当然这都是钱! 这也是架构设计中的一种 trade off

RocketMQ
对比 kafka,rocketmq 有两点很大的不同:
- 元数据管理系统,从 zookeeper 变成了轻量级的独立服务集群。
- 服务节点变为 多主多从架构
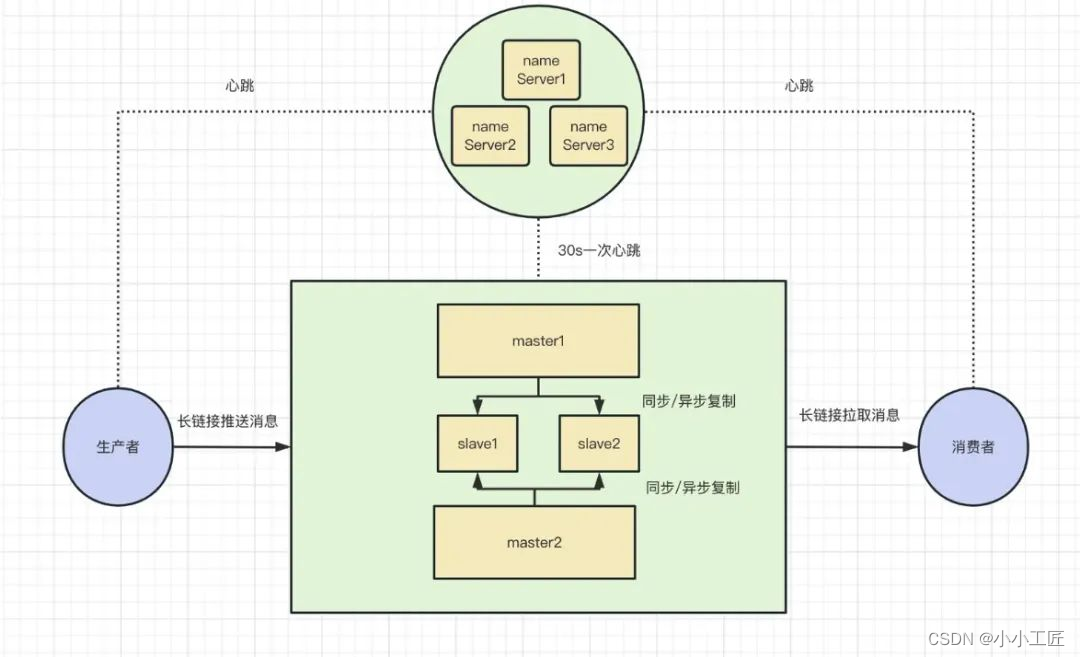
zookeeper vs namesrv
ookeeper 是 cp 强一致架构的一种,其内部使用 zab 算法,进行信息同步和容灾,在信息量较小的情况下,性能较好,当信息交互变多,因为同步带来的性能损耗加大,性能和吞吐量降低。如果 zookeeper 宕机,会导致整个集群的不可用,对于一些交易场景,这是不可接受的
- 相比 Zookeeper,RocketMQ 选择了轻量级的独立服务器 NameSRV。
- NameSRV 使用简单的 K/V 结构保存信息。
- NameSRV 支持集群模式,每个 NameSRV 相互独立,不进行任何通信。
- Data 都保存在内存当中,Broker 的注册过程通过循环遍历所有 NameSRV 进行注册。

局部顺序写(kafka) 与 完全顺序写(rocketmq)
- Kafka 将不同分区写入对应的文件系统中,保证了优秀的水平扩容能力。
- RocketMQ 追求极致的消息写,将所有 topic 消息存储在同一个文件中,确保消息发送时按顺序写文件,提高可用性和吞吐量。
- RocketMQ 的设计使得其不支持删除指定 topic 功能,因为 topic 信息在磁盘上是一段非连续的区域,不像 Kafka 一个 topic 是一段连续的区域。
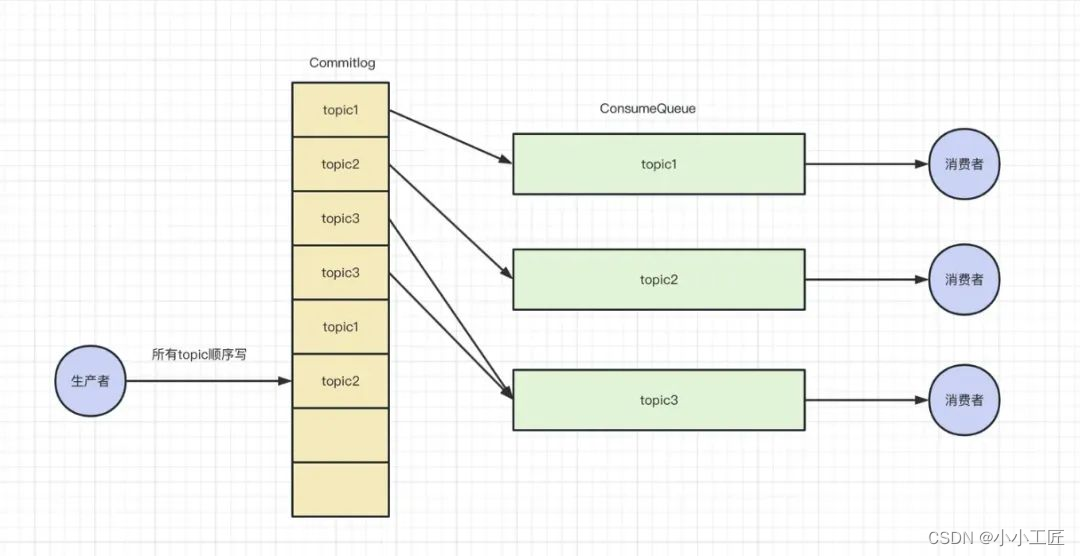
Rocketmq 存储结构
RocketMQ 的存储结构设计是为了追求极致的消息写性能,它采用了混合存储的方式,将多个 Topic 的消息实体内容都存储于一个 CommitLog 中。在 RocketMQ 的存储架构中,有三个重要的存储文件,分别是 CommitLog、ConsumeQueue 和 IndexFile。
-
CommitLog
CommitLog 是存储消息的主体。Producer 发送的消息都会顺序写入 commitLog 文件,所以随着写入的消息增多,文件也会随之变大。单个文件大小默认 1G,文件名长度为 20 位,左边补零,剩余为起始偏移量。例如,00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G。当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。存储路径为HOME/store/commitLog。 -
ConsumeQueue
ConsumeQueue(逻辑消费队列) 可以看成基于 topic 的 commitLog 的索引文件。因为 CommitLog 是按照顺序写入的,不同的 topic 消息都会混淆在一起,而 Consumer 又是按照 topic 来消费消息的,这样的话势必会去遍历 commitLog 文件来过滤 topic,这样性能肯定会非常差,所以 rocketMq 采用 ConsumeQueue 来提高消费性能。即每个 Topic 下的每个 queueId 对应一个 Consumequeue,其中存储了单条消息对应在 commitLog 文件中的物理偏移量 offset,消息大小 size,消息 Tag 的 hash 值。存储路径为HOME/store/consumequeue/topic/queueId/fileName。 -
IndexFile
IndexFile 提供了一种可以通过 key(topicmsgId) 或时间区间来查询消息的方法。他的存在主要是针对在客户端 (生产者和消费者) 和控制台接口提供了根据 key 查询消息的实现。为了方便用户查询具体某条消息。IndexFile 的存储结构可以认为是一个 hashmap。存储路径为HOME/store/index/.HOME/store/index/fileName文件名 fileName 是以创建时的时间戳命名的。
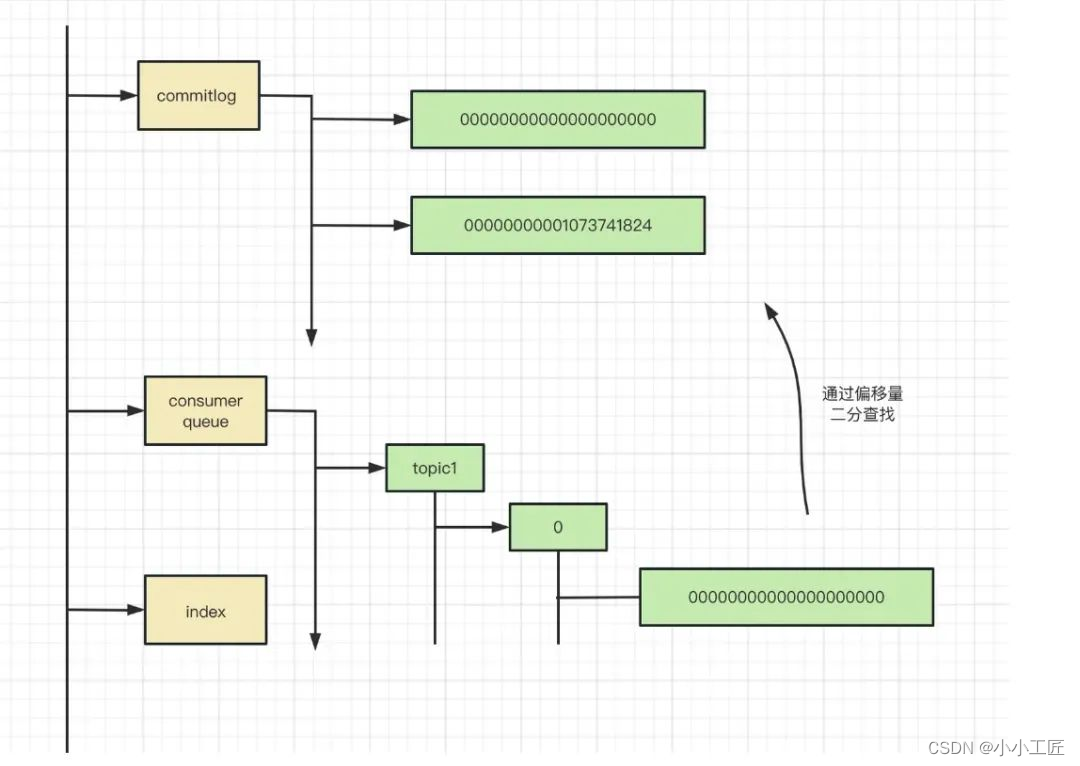
我们在想想 kafka 是怎么做的,对的,kafka 并没有类似的烦恼,因为所有信息都是连续的
总结起来,RocketMQ 的存储结构设计非常复杂,但它通过合理的设计实现了高效的消息写入和读取性能。同时,RocketMQ 也支持多种存储方式,如本地存储、分布式存储和云存储等,可以满足不同场景下的需求。

Pulsar
架构图(分层+分片)
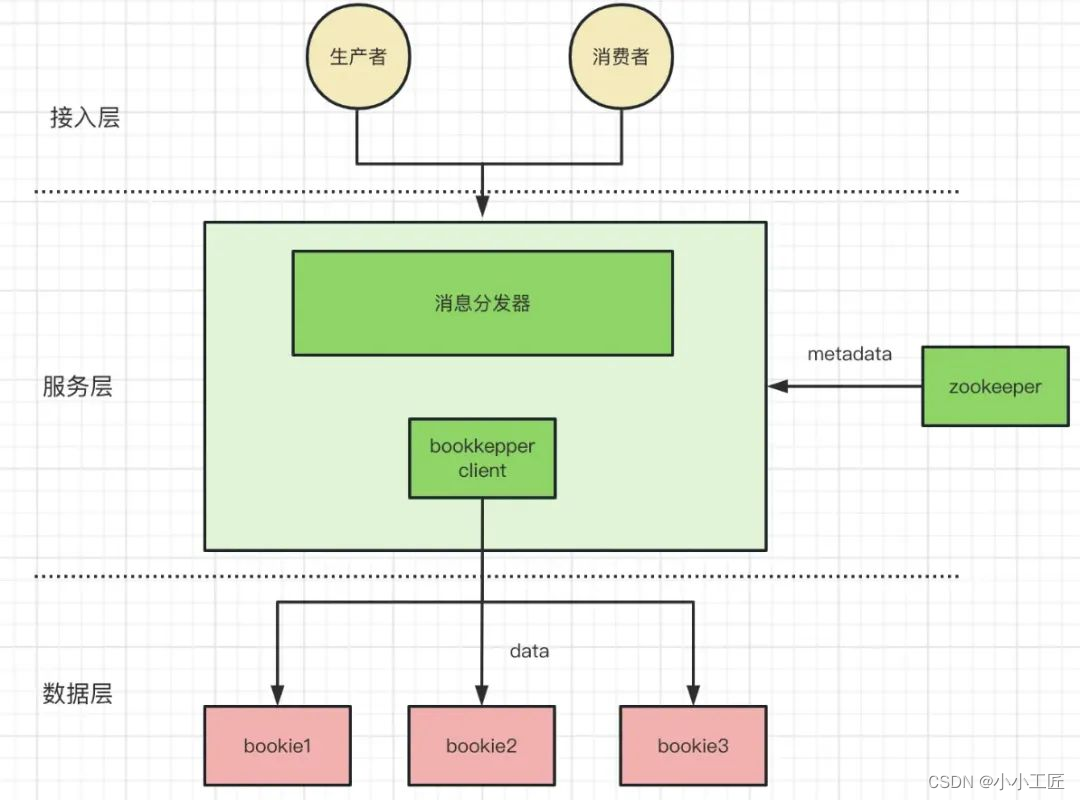
pulsar 相比与 kafka 与 rocketmq 最大的特点则是使用了分层和分片的架构,回想一下 kafka 与 rocketmq,一个服务节点即是计算节点也是服务节点,节点有状态使得平台化、容器化困难、数据迁移、数据扩缩容等运维工作都变的复杂且困难。
-
分层:Pulsar 分离出了 Broker(服务层)和 Bookie(存储层)架构,Broker 为无状态服务,用于发布和消费消息,而 BookKeeper 专注于存储。
-
分片 : 这种将存储从消息服务中抽离出来,使用更细粒度的分片(Segment)替代粗粒度的分区(Partition),为 Pulsar 提供了更高的可用性,更灵活的扩展能力
服务层设计
Broker 集群在 Pulsar 中形成无状态服务层。服务层是“无状态的”,所有的数据信息都存储在了 BookKeeper 上,所有的元信息都存储在了 zookeeper 上,这样使得一个 broker 节点没有任何的负担,这里的负担有几层含义:
- 容器化没负担,broker 节点不用考虑任何数据状态带来的麻烦。
- 扩容、缩容没负担,当请求量级突增或者降低的同时,可以随时的添加节点或者减少节点以动态的调整资源,使得整体在一种“合适”的状态。
- 故障转移没负担,当一个节点宕机、服务不可用时,可以通快速地转移所负责的 topic 信息到别的基节点上,可以很好做到故障对外无感知。
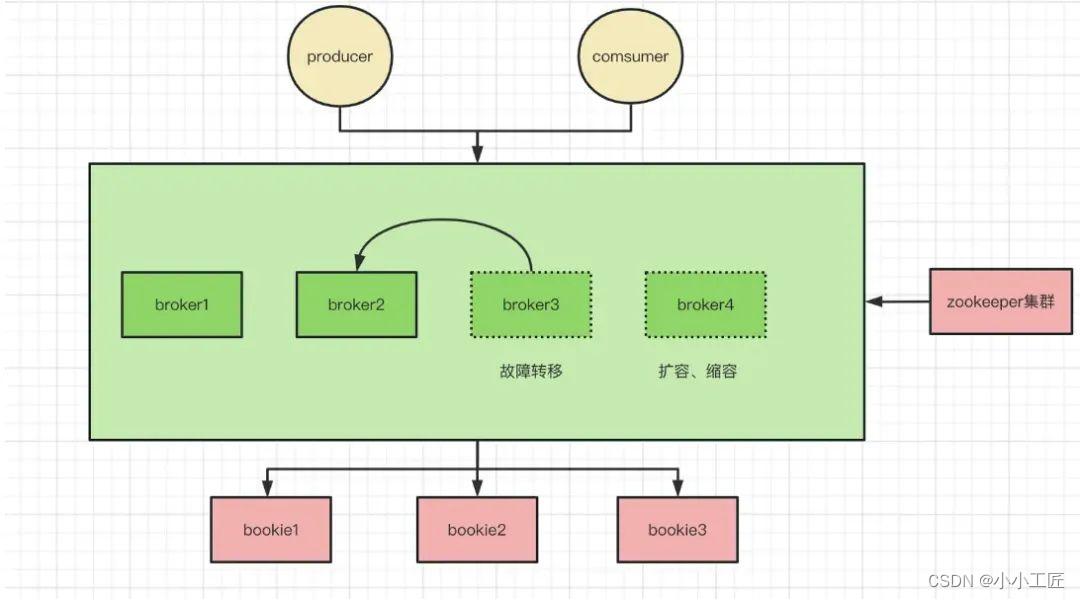
存储层设计
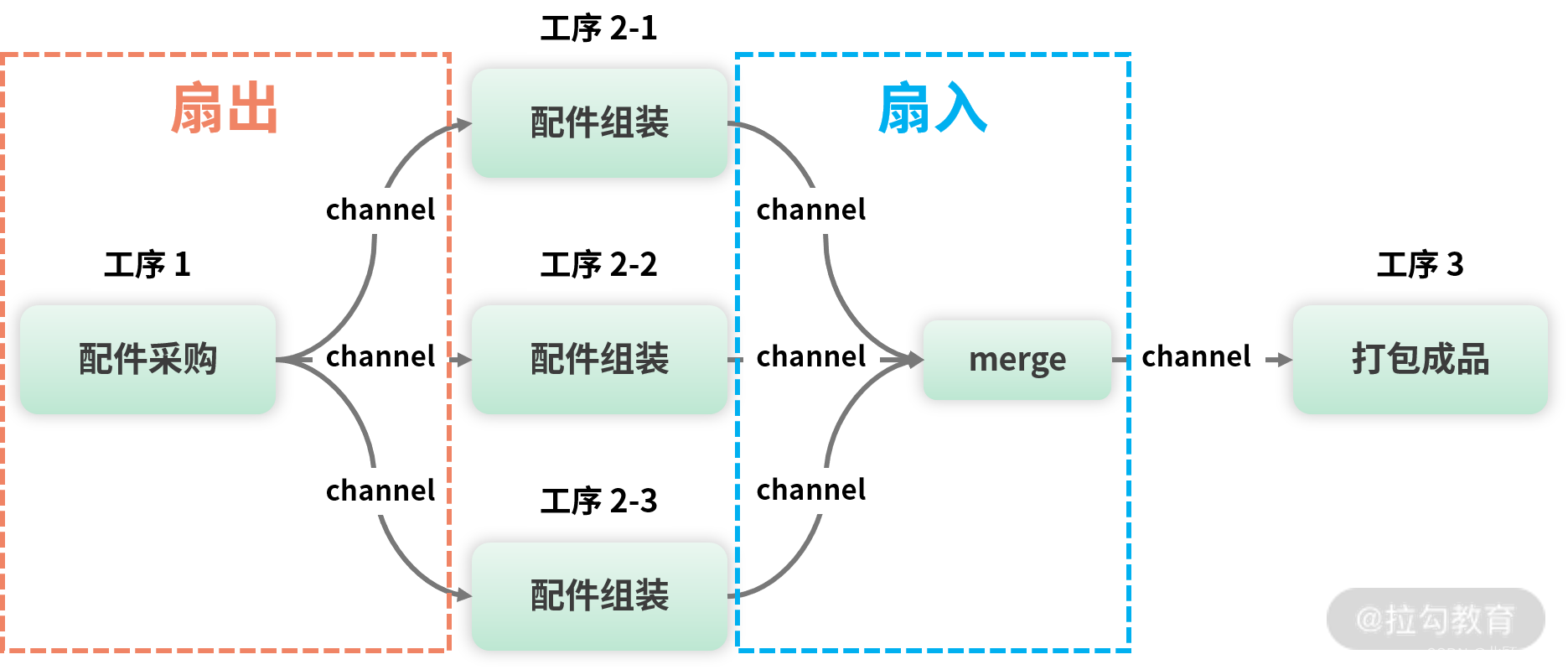
pulsar 使用了类似于 raft 的存储方案,数据会并发的写入多个存储节点上,下图为四存储节点、三副本架构。
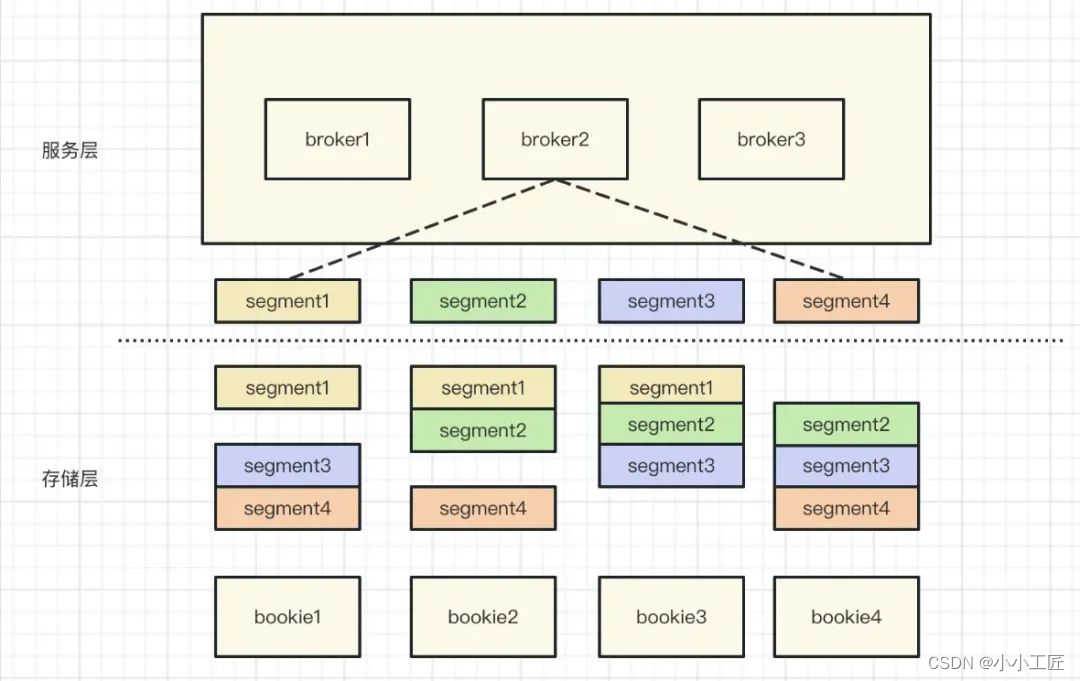
broker2 节点当前需要写入 segment1 到 segment4 数据,流程为: segment1 并发写入 b1、b2、b3 数据节点、segment2 并发写入 b2、b3、b4 数据节点、segment3 并发写入 b3、b4、b1 数据节点、segment4 并发写入 b1、b2、b4 数据节点。这种写入方式称为条带化的写入方式。
这种方式潜在的决定了数据的分布方式、通过路由算法,可以很快的找到对应数据的位置信息,在数据迁移与恢复中起到重要的作用。
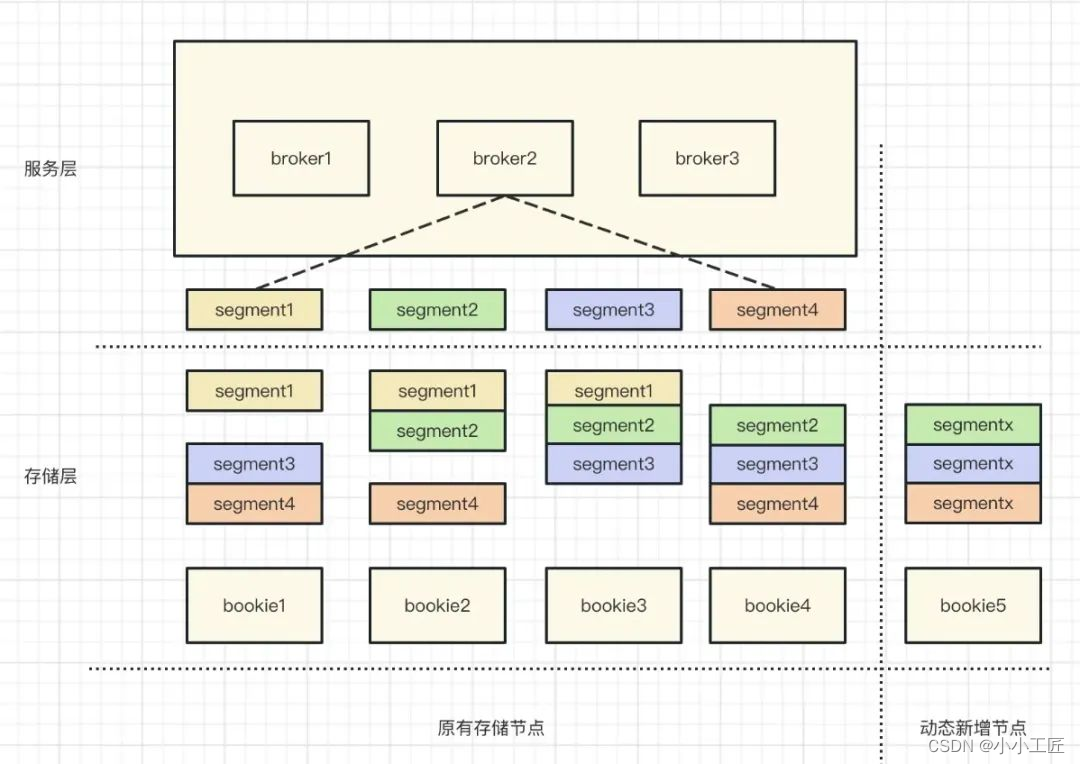
扩容
当存储节点资源不足的时候,常规的运维操作就是动态扩容,相比 kafka 与 rocketmq、pulsar 不用考虑原数据的"人为"搬移工作,而是动态新增一个或者多个节点,broker 在写入数据时通过路有算法优先写入资源充足的节点,使得整体的资源利用力达到一个平衡的状态,如图所示。
以下是一张 kafka 分区和 pulsar 分片的一张对比图,左图是 kafka 的数据存储特点,因为数据和分区的强绑定,导致了第三艘小船没有任何的数据,而相比 pulsar,数据不和任何存储节点绑定,而是实时的动态写入,从数据分布和资源利用来说,要做的更好。

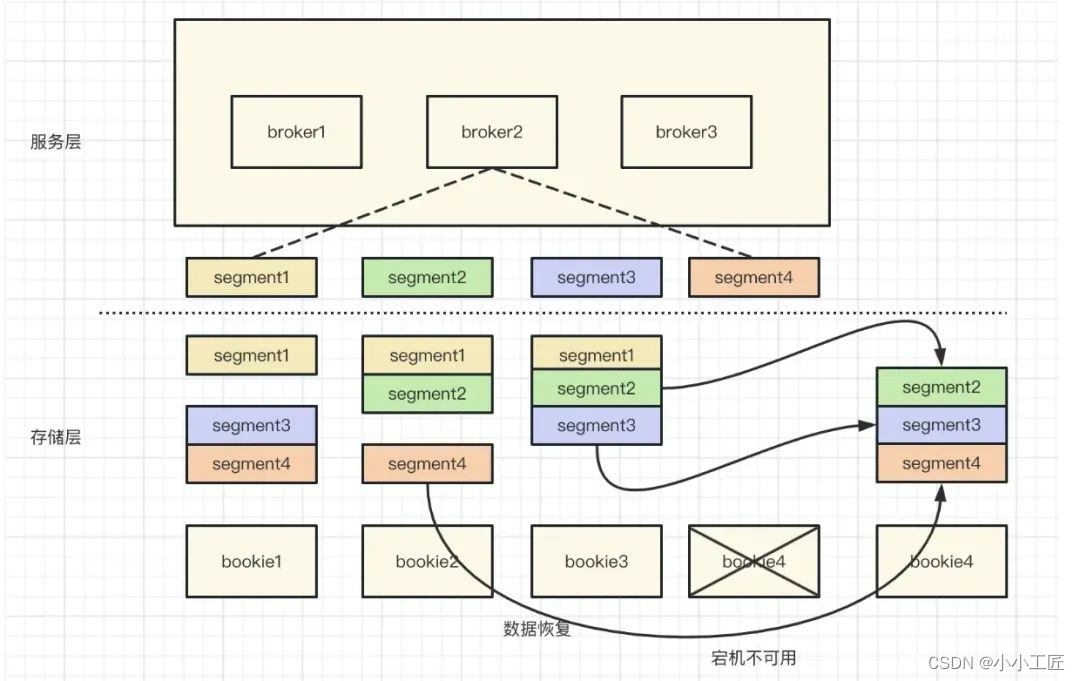
容灾
当 bookie4 存储节点宕机不可用时,如何恢复节点数据?这里只需要增加新的存储节点,并且拷贝 bookie2 与 bookie3 上的数据即可,这个过程对外是无感知的,实现了平滑切换,如图所示
小结
每种设计都有其特定的优势和局限,适应不同场景和需求。因此,在选用产品时,需要根据实际业务场景和需求,权衡各种设计的优缺点,作出最合适的选择。这种选择过程正是体现了设计与需求之间的平衡。所以,针对不同场景选择合适的产品是非常关键的。