背景
跨洋消息队列CKafka,是腾讯出品开源消息队列组件,为了解决客户跨地域容灾、冷备的诉求跨地域秒级准实时数据同步而开源的腾讯云中间件。
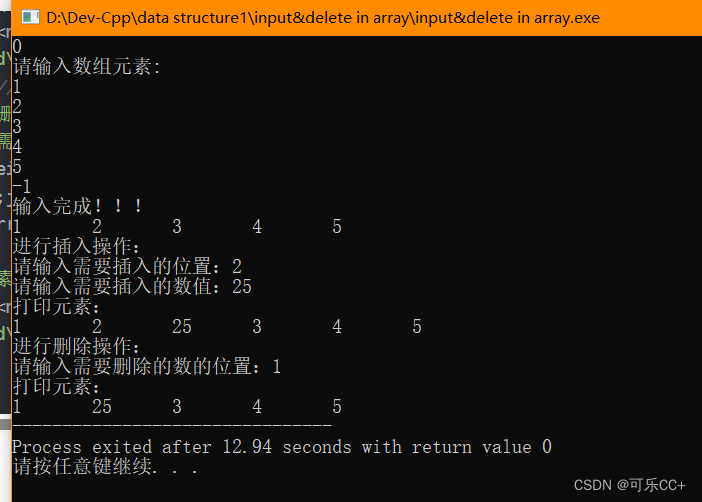
整体架构图
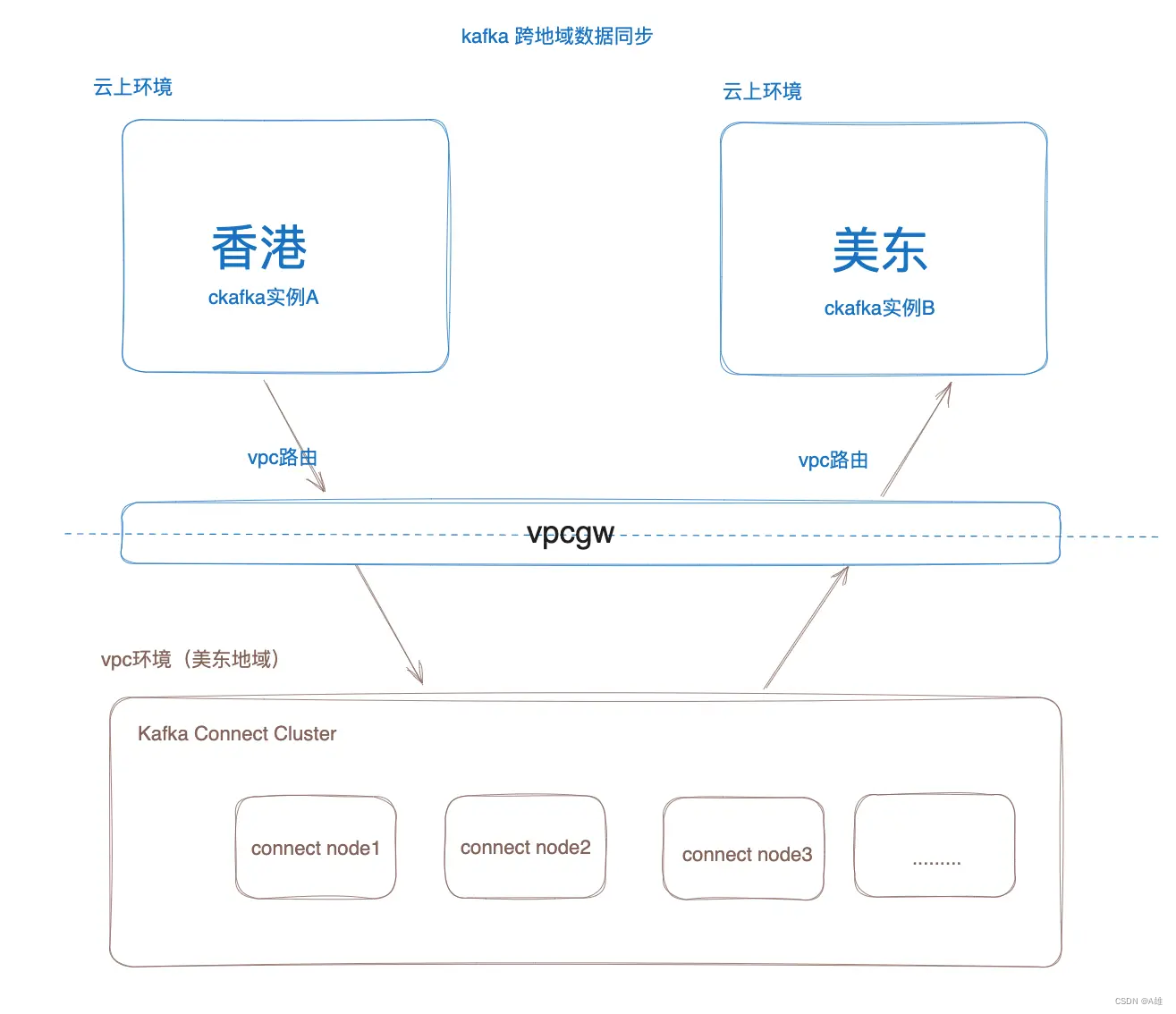
数据同步主要流程
-
Connect 集群初始化 Connect Task,每个 Task 会新建多个 Worker ConsumerClient(具体多少取决于源实例的分区数)从源 CKafka 实例拉取数据。
-
Connect 集群从源实例拉取数据后,会启动 Producer 发送数据到目标 CKafka 实例。
在某个客户业务场景中,客户希望通过跨地域同步能力,把香港 CKafka 实例的数据同步到美东 CKafka 实例。
消息堆积常见的原因
Kafka 在生产消费过程中,出现消息堆积常见的原因主要有以下几点:
● Broker 集群负载过高:包括 CPU 高、内存高、磁盘 IO 高导致消费吞吐慢。
● 消费者处理能力不足:如果消费者的处理能力不足,无法及时消费消息,就会导致消息堆积。可以通过增加消费者的数量或者优化消费者的处理逻辑来解决该问题。
● 消费者异常退出:如果消费者异常退出,就会导致消息无法及时消费,从而在 Broker 中积累大量未消费的消息。可以通过监控消费者的状态和健康状况,及时发现并处理异常情况。
● 消费者提交偏移量失败:如果消费者提交偏移量失败,就会导致消息重复消费或者消息丢失,从而在 Broker 中积累大量未消费的消息。可以通过优化消费者的偏移量提交逻辑,或者使用 Kafka 的事务机制来保证偏移量的原子性和一致性。
● 网络故障或者 Broker 故障:如果网络故障或者 Broker 故障,就会导致消息无法及时传输或者存储,从而在 Broker 中积累大量未消费的消息。可以通过优化网络的稳定性和可靠性,或者增加 Broker 的数量和容错能力来解决该问题。
● 生产者发送消息速度过快:如果生产者发送消息速度过快,超过了消费者的处理能力,就会导致消息堆积。可以通过调整生产者的发送速度,或者增加消费者的数量来解决该问题。