HTML字符编码/HTML实体编码
html实体编码 unicode urlcode 在字符的十六进制前加百分号(%),用于浏览器的网址输入框 utf-8
字符数字表示法
HTML允许使用Nuicode码点表示字符,浏览器会自动将码点转成对应的字符。
字符的码点表示法是:&#N(十进制,N代表码点)或者&#xN(十六进制,N代表码点)
a ---- a(十进制) ---- a(十六进制)
中 ---- 𠀓(十进制) ----中(十六进制)
<p>hello</p>
<!-- 等同于 -->
十进制
<p>hello</p>
<!-- 等同于 -->
十六进制
<p>hello</p>
可以使用CyberChef快速解析编码
浏览器本身不能使用码点表示,否则浏览器会认为这是要显示的内容,而不是标签。
字符的实体表示法
< : <
> : >
" : "
' : '
& : &
# : #
¥: ¥
$ : &dollor;
% : %
* : *
@ : @
^ : ^
空格 :
unicode编码,UTF-8
UTF-8 编码是 Unicode 字符集的一种表达方式。每个字符有一个 Unicode 号码,称为码点。如果知道码点,就能查到这是什么字符。字符的码点表示法是&#N;(十进制,N代表码点)或者&#xN;(十六进制,N代表码点),比如,字符a可以写成a(十进制)或者a(十六进制),字符中可以写成中(十进制)或者中(十六进制),浏览器会自动转换它们。
Unicode字符编码,格式: 以符号&#开头,分号;结尾
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1、对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2、对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码
URL字符
URL 编码将字符转换为可通过因特网传输的格式。
URL 只能使用 ASCII 字符集 通过因特网进行发送。
26个英文字母(大小写),10个阿拉伯数字,连词号(-),句点(.),下划线(_)
由于 URL 通常包含 ASCII 集之外的字符,因此必须将 URL 转换为有效的 ASCII 格式。
URL 字符转义的方法是,在这些字符的十六进制 ASCII 码前面加上百分号(%)。
URL 不能包含空格。URL 编码通常使用加号(+)或 %20 替代空格。
JS
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
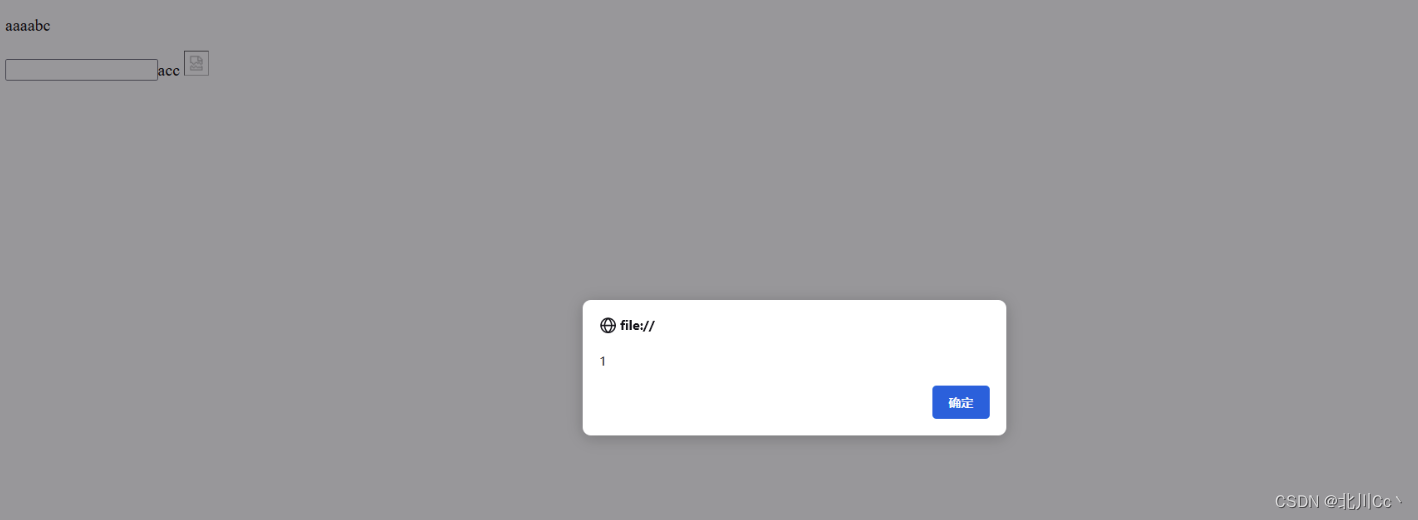
<p id="demo">aaaabc</p>
<input type="text" name="username" onclick="alert(1)">acc</input> <!-- 点击的时候弹出弹窗 -->
<img src="123" onerror="alter(321)">
</body>
<script type="text/javascript">
alert(1) /* 除数字外都要加双引号 */
confirm(1)
prompt(1) /* 反应写的内容 */
</script>
</html>
-->x=2 /* 注释符一定要和注释写在同一行否则不生效 */
console.log(x);
== (相等运算符)--- 只判断值相不相等 x==y
=== (严格相等运算符)--- 判断类型和值相不相等 x===y