一、概述
本文将参考《自己动手写编译器这本书》,自己写一个编译器,但是因为本人水平有限。文章中比较晦涩的内容,自己也没弄明白。因此,本文仅在实践层跑一遍流程。具体的原理还需要大家自行探索。
TinyC 编译器可将 TinyC 源程序编译成 Linux 下的可执行程序,其编译及运行基本流程如下图,首先利用 TinyC 前端将 TinyC 源程序编译成中间代码 Pcode ,再利用 Nasm 的宏程序将 Pcode 翻译成 x86(32位) 汇编指令,然后利用 Nasm 汇编成二进制目标程序,最后链接成 Linux 下的 32 位可执行程序,可直接在 Linux 下运行。另外,中间代码 Pcode 也可以用 Pcode 模拟器直接运行。
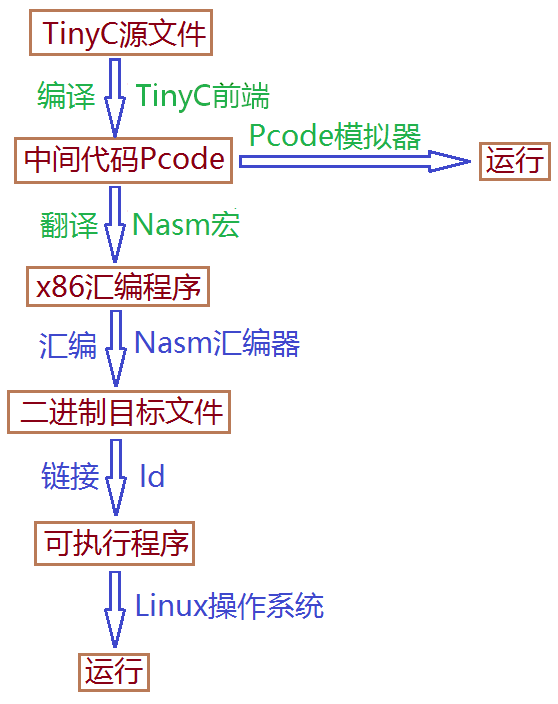
上图中绿色部分的 TinyC 前端、 Nasm 宏以及 Pcode 模拟器为由本人编程实现的部分,其他则是利用了 Nasm 和 ld 来生成可执行的二进制机器码。本书将 Nasm 宏、 Nasm 汇编器、 ld 链接器一起称为 TinyC 后端,将 TinyC 前端和 TinyC 后端一起称为 TinyC 编译器。
二、TinyC语法规范
1、数据类型及源程序结构
TinyC 中变量只有 int 一种数据类型(32位),函数的返回值可以声明为 int 和 void 两种类型,但编译器会自动为 void 函数返回一个 int 值。不支持全局变量,只有局部变量,变量须先声明再使用,且变量声明必须放在函数体的最前面,不支持声明变量的时候赋初值。
不支持函数原型声明,函数声明必须和定义在一起,函数无需先定义再使用。整个程序必须有一个不带参数的 main 函数,此为程序的入口。
“//...” 以及 “#...” 为单行注释。不支持 #include 等预处理命令,不支持多行注释。
典型的 TinyC 源程序是由一个个的函数定义组成的,如下:
int main() {
int a, b;
int c, d; // 变量声明必须放在函数体的最前面
a = 0;
...
}
void func1(int a, int b) {
...
}
...TinyC 函数体内的语句只有四种:赋值语句、函数调用语句、控制语句( if 语句)和循环语句( while 语句)。赋值语句中,左边为变量名,右边为表达式,一个只含有表达式(函数调用除外)的语句是不合法的,如下:
a = 1 + a; // 合法
sum(1, 2); // 合法
if (a > 0) { ... } // 合法
while (a < 0) { ... } // 合法
1; // 不合法
1 + 2; // 不合法2 、数据运算
TinyC 支持以下算术、比较和逻辑运算:
+, -, *, /, %, ==, !=, >, <, >=, <=, &&, ||, !, -
注意上面最后一个 “-” 表示 “反号” ,应和 “减号” 区别开来。
TinyC 不支持 ++ 和 - - 。赋值语句只能单独使用,不能放在表达式内部,如:
x = y = 1; // 不合法
(x = 1) > 0; // 也不合法3 、输入及输出
TinyC 提供两个基本的 io 命令, print 和 readint 。如:
print("x = %d, y = %d", 2, 3); // 输出: x = 2, y = 3
x = readint("Please input an integer");print 命令将字符串打印至标准输出,并自动换行,仅支持 %d 格式化。 readint 命令先打印提示信息,再从标准输入中读取一个整数并返回。注意, readint 命令必须放在赋值语句的右边,单独的 readint 命令是不合法的,而 print 命令只能单独使用,不能放在赋值语句的右边:
x = readint("Please input an integer"); // 合法
readint("Please input an integer"); // 不合法
print("x = %d, y = %d", 2, 3); // 合法
x = print("x = %d, y = %d", 2, 3); // 不合法4 、控制及循环语句
TinyC 仅支持 if/else 和 while 语句, while 循环中支持 continue 和 break 。不支持 for 、 switch 、 goto 等其他语句。if/else 和 while 的执行体必须用花括号括起来。如:
if (x > 0) y = 1; // 不合法
if (x > 0) { y = 1; } // 合法5 、函数调用
TinyC 支持函数调用,支持递归。
6 、关键字
TinyC 中的关键字只有下面这些:
void, int, while, if, else, return, break, continue, print, readint7 、典型 TinyC 程序
好了,以上就是 TinyC 的全部了,够简单吧。典型的 TinyC 程序如下:
#include "for_gcc_build.hh" // only for gcc, TinyC will ignore it.
int main() {
int i;
i = 0;
while (i < 10) {
i = i + 1;
if (i == 3 || i == 5) {
continue;
}
if (i == 8) {
break;
}
print("%d! = %d", i, factor(i));
}
return 0;
}
int factor(int n) {
if (n < 2) {
return 1;
}
return n * factor(n - 1);
}以上代码中的第一行的 #include “for_gcc_build.hh” 是为了利用gcc来编译该文件的,TinyC 编译器会注释掉该行。for_gcc_build.hh 文件源码如下:
#include <stdio.h>
#include <string.h>
#include <stdarg.h>
void print(char *format, ...) {
va_list args;
va_start(args, format);
vprintf(format, args);
va_end(args);
puts("");
}
int readint(char *prompt) {
int i;
printf(prompt);
scanf("%d", &i);
return i;
}
#define auto
#define short
#define long
#define float
#define double
#define char
#define struct
#define union
#define enum
#define typedef
#define const
#define unsigned
#define signed
#define extern
#define register
#define static
#define volatile
#define switch
#define case
#define for
#define do
#define goto
#define default
#define sizeof此文件中提供了 print 和 readint 函数,另外,将所有 C 语言支持、但 TinyC 不支持的关键词全部 define 成空名称,这样来保证 gcc 和 TinyC 编译器的效果差不多。利用 gcc 编译的目的是为了测试和对比 TinyC 编译器的编译结果。
让我们先用 gcc 编译并运行一下上面这个典型的 TinyC 源文件吧。将以上代码分别存为 tinyc.c 和 for_gcc_build.hh,放在同一目录下,打开终端并 cd 到该目录,输入:
$ gcc -o tinyc tinyc.c
$ ./tinyc将输出:
1! = 1
2! = 2
4! = 24
6! = 720
7! = 5040如果您的系统中没有 gcc ,则应先安装 gcc 。如果你使用的是 debian ,可以用 apt-get 命令来安装,如下:
$ sudo apt-get install build-essential
三、中间代码
上一章中介绍了 TinyC 源程序的语法,本章介绍中间代码 Pcode 的语法,同时介绍 Pcode 虚拟机的内部结构、如何用 Pcode 模拟器运行 Pcode 、以及 Pcode 命令与 TinyC 程序之间的对应关系。
1、Pcode 、 Pcode 虚拟机及 Pcode 模拟器概述
Pcode 是 TinyC 编译器的中间代码,是本人参考 pascal 编译器的中间代码 pcode 、并结合逆波兰表达式(后缀表达式)的逻辑后,设计出的一种非常简单的、基于栈和符号表的虚拟代码。
Pcode 虚拟机是一个用来运行 Pcode 命令的、假想的机器,它包括:一个代码区(code)、一个指令指针(eip)、一个栈(stack)、一个变量表(var_table)、一个函数表(func_table)以及一个标签表(label_table)。
Pcode 模拟器是本人用 Python 编写的一个解释和运行 Pcode 的程序,它实现了 Pcode 虚拟机的全部要素。
Pcode 的所有命令都是对栈顶及附近的元素进行操作的,如 push/pop 命令分别将元素入栈和出栈,add 命令将栈顶的两个元素取出,相加后再放回栈顶。如:
x = 1 + 2 * 3;
可以翻译成以下Pcode:
push 1
push 2
push 3
mul
add
pop x看起来是不是很眼熟,和所谓的逆波兰表达式(后缀表达式)有点相似吧?
1 2 3 * +
Pcode 中以分号 ”;” 开始的为注释,以标识符加冒号的为标签(如 “Label:” )。
Pcode 命令一共只有7组,都是非常简单的命令,其中也可以分为系统命令和自定义命令两种,自定义命令其实就是函数调用,是对系统命令的扩充。以下详细介绍 Pcode 的系统命令、各命令执行过程中 Pcode 虚拟机的状态变化、如何创建自定义命令(函数)、以及如何用 Pcode 模拟器运行 Pcode 。
2、变量声明命令
var 命令,声明变量,向下增长栈的空间,将新增的空间分配(绑定)给刚声明的变量,并将变量名及分配给它的地址保存到变量表中。有以下用法:
var a ; 栈顶向下增长 1 个单元,将新的栈顶单元分配(绑定)给 a
var x, y, z ; 栈顶向下增长 3 个单元,将新的栈顶单元分配(绑定)给 x, y, z“var a” 命令运行后栈及符号表的变化如下所示,其中左边为栈,右边为绑定的符号表,”<-” 指向栈顶,该命令运行后,栈顶向下增长1个单元,并将变量a绑定到新的栈顶单元上。斜杠 “/” 来表示此单元尚未赋初始值,如果此单元在被赋初值之前被使用(读取),则虚拟机将出错终止。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- ------------+-----------
... | ... |
------------+----------- var a ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... |<- ... |
------------+----------- ------------+-----------
/ |<- a
------------+-----------“var x, y, z” 命令运行后栈及符号表的变化所示,该命令运行后,栈顶向下增长 3 个单元,并将变量 x, y, z 绑定到新的栈顶单元上。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- ------------+-----------
... | ... |
------------+----------- var x, y, z ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... |<- ... |
------------+----------- ------------+-----------
/ | x
------------+-----------
/ | y
------------+-----------
/ |<- z
------------+-----------var 命令运行后, Pcode 虚拟机会将刚刚声明的变量及分配给它的地址记录在变量表中,在后面的命令中可以根据变量名称来引用其内容。
以上图示中,栈的增长方向都是向下,这是为了和大部分计算机系统架构和编译原理教材的惯例保持一致。
3、入栈及出栈命令
push / pop 命令,将元素放入栈顶,或取出栈顶元素。有以下用法:
push 2 ; 将常数 2 入栈
push a ; 将变量 a 的值入栈, a 必须已被声明、且已被赋值过
pop ; 将栈顶向上减少一个单位
pop a ; 取出栈顶元素,并赋给变量 a , a 必须已被声明“push 2” 命令运行后,常数 2 被放入栈顶,如下:
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- push 2 ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... |<- ... |
------------+----------- ------------+-----------
2 |<-
------------+-----------“push a” 命令运行后,变量 a 的值 <5> 被放入栈顶,如下图。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- ------------+-----------
5 | a 5 | a
------------+----------- push a ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... |<- ... |
------------+----------- ------------+-----------
5 |<-
------------+-----------当虚拟机执行 push 命令时,若后面是一个变量名,则虚拟机会在其变量表中查找此变量名,如果查到了,且该变量的值不是空值 “/” ,则将此变量名对应的值放入栈顶,但若此时该变量尚未被赋初值(为空值 “/” ),则虚拟机将出错而终止,如果没有查找到,则虚拟机也会出错终止。
“pop” 命令运行后,栈顶向上减少一个单位,栈顶元素被丢弃,如下:
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- pop ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... | ... |<-
------------+----------- ------------+-----------
... |<-
------------+-----------“pop a” 命令运行后,栈顶的元素被取出,并将其值赋给了变量 a ,相当于 a = stack.pop() ,此命令是唯一一个能给 直接 给变量赋值的命令。栈的变化如下:
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- ------------+-----------
... | a 5 | a
------------+----------- pop a ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... | ... |<-
------------+----------- ------------+-----------
5 |<-
------------+-----------当虚拟机执行 pop 命令后,若后面是一个变量名,虚拟机会在其变量表中查找此变量名,若查到了,则虚拟机会将栈顶元素取出,赋给该变量名对应的栈单元,若没查到,虚拟机会出错终止。
此处同样需要注意的是,若此时 栈顶单元 尚未被赋初值(为空值 “/” ),则虚拟机将出错而终止。总而言之,栈上未被赋初值的单元是不能被使用(读取)的,此约束对后面将要介绍的所有命令都有效,因此后面就不再重复申明此约束了。
4、数据运算命令
add / sub / mul / div / mod / cmpeq / cmpne / cmpgt / cmplt / cmpge / cmple / and / or / not / neg 命令,包括算术、比较和逻辑运算命令。对应于 TinyC 中的以下运算符:
+, -, *, /, %, ==, !=, >, <, >=, <=, &&, ||, !, -
注意最后一个 “ - ” 是反号的意思,应和减号区别开来。
以上命令中,除 not 和 neg 命令外,其余命令均为二元操作命令,先取出栈顶两个元素,进行运算后,再将结果放回栈顶, not 和 neg 命令则为一元操作命令,只对栈顶一个元素进行操作。所有二元操作中, 原栈顶元素是第二个操作符 。
“ add ” 命令运行后栈的变化如下:
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- add ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
5 | 17 |<-
------------+----------- ------------+-----------
12 |<-
------------+-----------“ sub ” 命令运行后栈的变化如下,注意, 原栈顶元素是第二个操作符 ,最后的结果是 5 - 12 。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- sub ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
5 | -7 |<-
------------+----------- ------------+-----------
12 |<-
------------+-----------“ cmpgt ” 命令运行后栈的变化如下,注意原栈顶元素是第二个操作符,最后的结果是 5 > 12 ,因此是 0 (非真)。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- cmpgt ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
5 | 0 |<-
------------+----------- ------------+-----------
12 |<-
------------+-----------“ neg ” 命令运行后栈的变化如下,栈顶位置不变,栈顶元素被反号。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- neg ------------+-----------
... | -------------> ... |
------------+----------- ------------+-----------
... | ... |
------------+----------- ------------+-----------
12 |<- -12 |<-
------------+----------- ------------+-----------数据运算命令和入栈、出栈命令组合,即可实现简单的表达式求值。如:
a = 1 + 2 * 3;
b = 8 - 5;可以翻译成以下 Pcode :
push 1 ; a = 1 + 2 * 3;
push 2
push 3
mul
add
pop a
push 8 ; b = 8 - 5;
push 5
sub
pop b注意表达式中的元素的入栈顺序为 从左向右入栈 ,这样的顺序和人的阅读顺序是一致的。
5、输入及输出命令
print / readint 命令,用法如下:
print "Hello world" ; 输出:Hello world
push 1
push 2 ; 相当于 print("(%d, %d)", 1, 2);
print "(%d, %d)" ; 输出:(1, 2)
readint "Input: "
pop x ; 相当于 x = readint("Input: ");print 命令会根据字符串的 “ %d ” 依次将栈顶元素取出,并打印出来,也就是说,上面第二个例子中 print 命令之前入栈的两个参数 1 和 2 ,在 print 后都将出栈。另外注意:参数的入栈的顺序需要从左向右入栈。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- print "(%d, %d)" ------------+-----------
... | ---------------> ... |<-
------------+----------- ------------+-----------
1 | |
------------+----------- ------------+-----------
2 |<- |
------------+----------- ------------+-----------
terminal out>> (1, 2)readint 命令先打印提示信息,再从标准输入中读取一个整数,返回后将其放入栈顶。
------------+----------- ------------+-----------
stack | bind var stack | bind var
------------+----------- readint "Input: " ------------+-----------
... |<- ---------------> ... |
------------+----------- ------------+-----------
| 2 |<-
------------+----------- ------------+-----------
| |
------------+----------- ------------+-----------
terminal out>> Input: 26、退出命令
exit 命令,退出虚拟机的运行,并设置退出码,有以下用法:
exit 0 ; 退出码为 0
exit a ; 退出码为 a 的值
exit ~ ; 退出码为栈顶元素的值上面的代码中用 “ ~ ” 来代表栈顶,这将是 Pcode 中的一个约定。
7、使用 Pcode 模拟器运行 Pcode
Pcode 模拟器是本人用 python 编写的用来运行 Pcode 的程序,下载地址在这里:pysim.py。
下面先让我们来运行一个简单的例子:
; int a, b;
var a, b
; a = 1 + 2;
push 1
push 2
add
pop a
; b = a * 2
push a
push 2
mul
pop b
; print("a = %d, b = %d", a, b);
push a
push b
print "a = %d, b = %d"下面再来单步执行以上 Pcode 代码,先将终端最大化(为达到好的显示效果,建议使用 gnome-terminal 或 Mate-terminal ),再输入:
$ python pysim.py pcode_1.asm -d之后,终端上就出现了下图所示的内容:
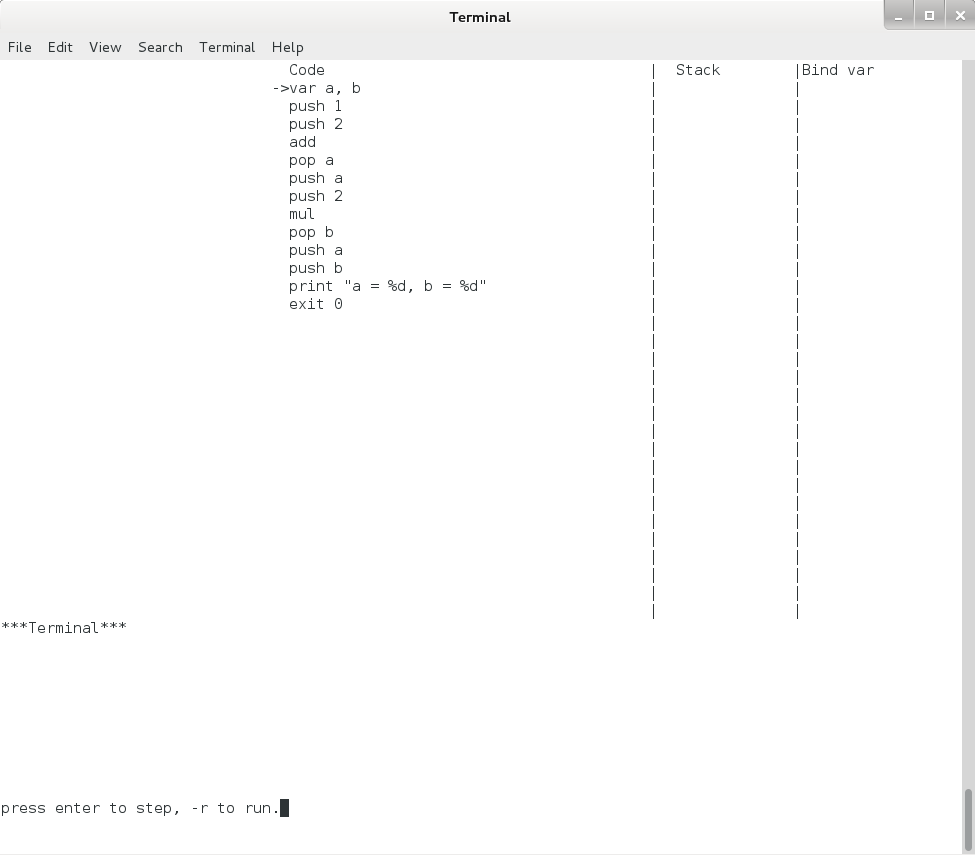
Pcode模拟器单步执行界面1
上图中,上半部分一共有 3 列,分别是 Code、 Stack 和 Bind var,分别表示代码、栈和绑定的变量。各列之间都用 “|” 隔开了。其中 Code 列下是我们编写的 Pcode 代码,注释已经全部都过滤掉了,在第一行的 “var a, b” 的最前面有一个 “->” ,这就是指令指针(eip),它永远指向下一个将要执行的指令。 Code 列中最后一行 “exit 0” 是模拟器自动增加的,这样程序运行到这里时会自动退出。
图中的下半部分有一行 ***”Terminal”***, 此行下面的区域用来表示 Pcode 虚拟机中的终端,print 和 readint 命令的输入和输出内容都将显示在此行以下。
最底下一行是 “press enter to step, -r to run.” ,表示若按回车,则模拟器会执行一步,按 “-r” 再回车,则模拟器会一直运行到程序结束。
现在,让我们敲一下回车,可以看到模拟器运行了一步,终端上的内容变成了下面的:
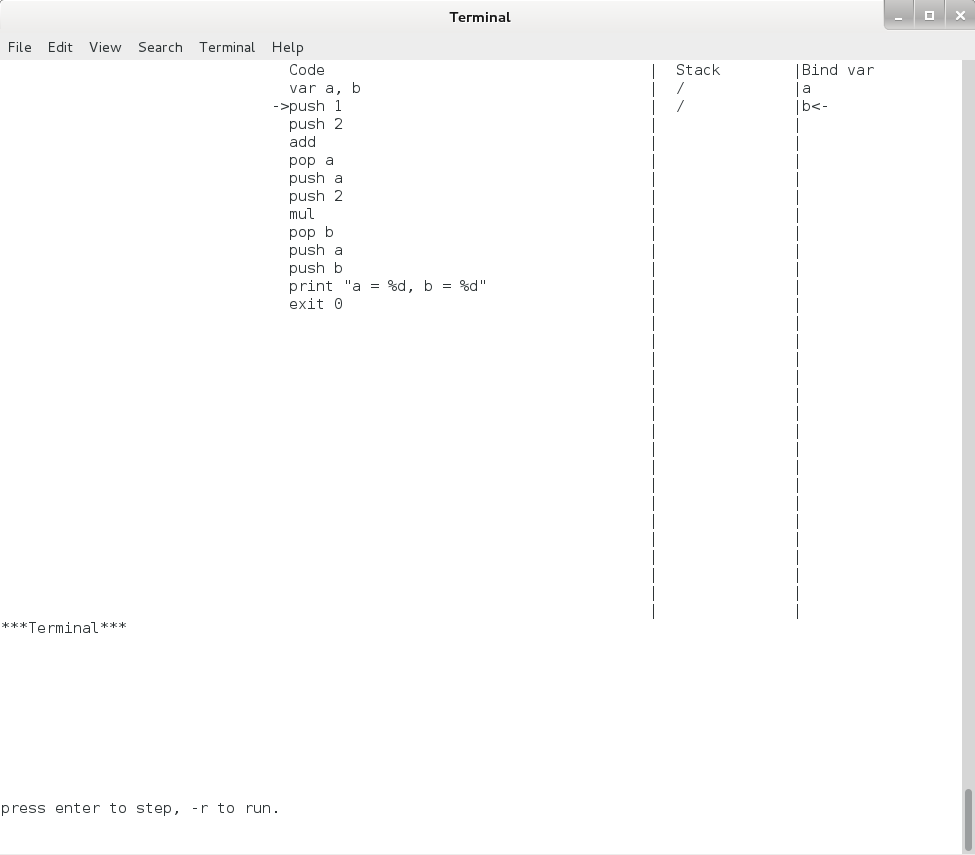
Pcode 模拟器单步执行界面2
可以看到 “var a, b” 执行之后,指令指针(eip)指向了第二行,栈上的第一行和第二行的内容由空内容都变成了 “/”,而 “Bind var” 那一列上多了 “a” 和 “b” ,且 “b” 的后面有一个 “<-” , 这是用来指示栈顶的。这些变化和上一章中对 var 命令的描述是完全一致的。
接下来,让我们一步一步的运行代码,细心观察每一步运行后代码区、栈区以及终端区的变化,可以看到随着命令的运行,指令指针一直在向下移动,栈顶指针则随 push / pop /print 等命令不断的上、下移动,终端区则在 print 命令运行后出现了 “a = 3, b = 6” ,程序在 “exit 0” 后退出,整个过程如下:

Pcode 模拟器单步执行过程
好了,Pcode 模拟器的使用就介绍完了,建议读者利用上一章中介绍的 Pcode 命令编写一些简单的程序,再使用 Pcode 单步运行一遍,以加深对这些命令及虚拟机的记忆。
下面来介绍 Pcode 的最后两组命令。
8、跳转命令
jmp / jz 命令。jmp 命令为无条件跳转命令,直接跳转到标签处,用法如下:
jmp Label
...
...
Label:
print "jump here"jz 命令为条件跳转命令,先取出栈顶元素,判断其是否为 0 ,若为 0 ,则跳转至标签处,若不为 0 ,则转到下一条命令,用法如下:
push 0
jz Label
print "top is not zero"
Label:
print "top is zero"Pcode 虚拟机会将所有以 “ xxx: ” 开始的行记录在其标签表中,在 jmp / jz 命令运行时,虚拟机会根据命令后的标签名在标签表中查找对应的地址,如果查不到标签名,虚拟机会出错终止。
jmp 命令运行后 eip 的变化如下,运行后栈保持不变。
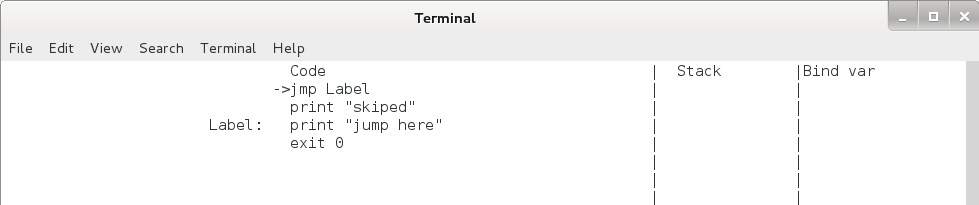
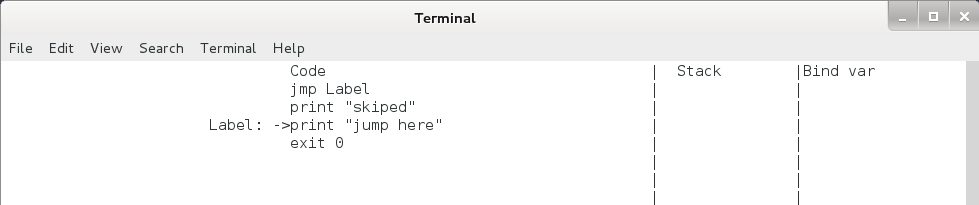
jmp命令
jz 命令运行后 eip 和栈的变化如下,注意无论是否发生跳转,栈顶的元素都将出栈。
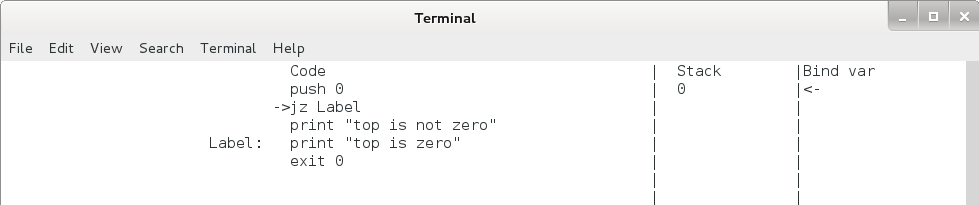
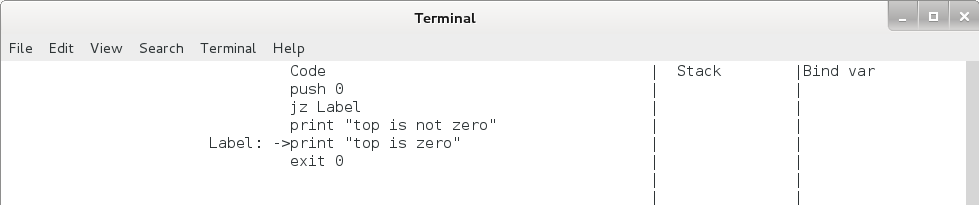
jz 命令执行过程(栈顶为 0 时)
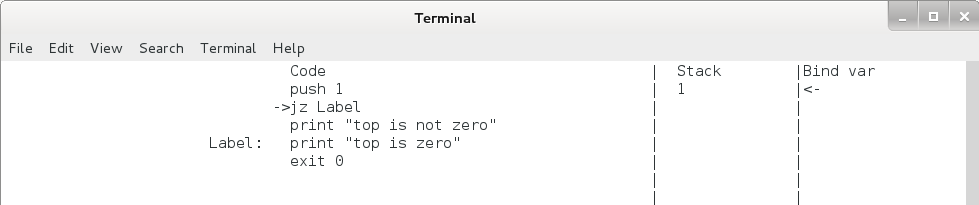
jz 命令(栈顶不为 0 时)
9、自定义函数命令
FUNC / ENDFUNC / arg / ret / $func_name 命令。这组命令用来定义函数,这是 Pcode 的最后一组命令,也是最为复杂的一组命令,还是用个简单的例子来说明这组命令吧。
C 语言:
...
sum(1, 2);
...
void sum(int a, int b) {
return a + b;
}对应的Pcode:
push 1
push 2
$sum
FUNC @sum:
arg a, b
push a
push b
add
ret ~
ENDFUNC现在来对照着 C 语言中的函数定义和调用来说明这组命令。
FUNC 和 ENDFUNC 分别为函数开始和结尾,FUNC 后的函数名以 @ 开始,这是为了不与系统命令冲突,因为在 C 语言中有可能会定义一个名为 add 或 push 等和系统命令同名的函数。函数名后接一个冒号。
函数体内开始的第一个命令为 arg ,这是声明函数参数的,注意此命令不能和 FUNC 行写在同一行。如果函数没有参数,则此命令可以去掉。声明了函数参数,函数内部就可以根据参数名来引用函数调用者传递进来的参数了。
函数调用的时候,在函数名前加 “$” 就可以了,函数的参数通过栈传递,先 从左向右 将参数压入栈中(再次强调,是 从左向右 ,也是为了更接近于源文件的阅读顺序),再调用函数。
Pcode 虚拟机会将所有用 FUNC 和 ENDFUNC 定义的函数名、函数入口地址及函数参数等相关信息记录在其函数表(func_table)中,当遇到以 $ 开头的命令时,它根据 $ 后面的函数名在函数表中查找,若查找到,则会根据函数信息进行函数调用,若没查找到,则会出错终止。
函数用 ret 命令向调用者返回值,有以下形式:
ret ; 返回空值 “/”
ret 1 ; 返回常数
ret a ; 返回变量值
ret ~ ; 取出栈顶元素,返回其值。函数返回时,会将调用者入栈的参数出栈,并在清栈后将返回值压入栈顶。
下面让我们来一步一步的执行这个程序,看看各命令执行过程中 eip 和栈的变化,看看调用者如何向函数传递参数,函数又如何向调用者返回结果。
在以上Pcode程序的第一行添加 “var a, b, c” ,并在 $sum 后面添加 “exit 0” ,之后存为 pcode_2.asm ,和 pysim.py 文件一起都放在终端的当前目录,并在终端输入:
$ python pysim.py pcode_2.asm -d
终端显示如下,注意模拟器自动在 ENDFUNC 的后面加了一句 ret ,这样对于函数体内不写任何 ret 的程序,程序运行到此处也会返回的。

图4.7 函数调用执行过程1
再敲3下回车,使程序运行到 $sum 这一行,可以看出此时栈上已经分配并绑定了 3 个变量 a, b, c ,函数的参数 1 和 2 也都压入到栈上了。见下图:
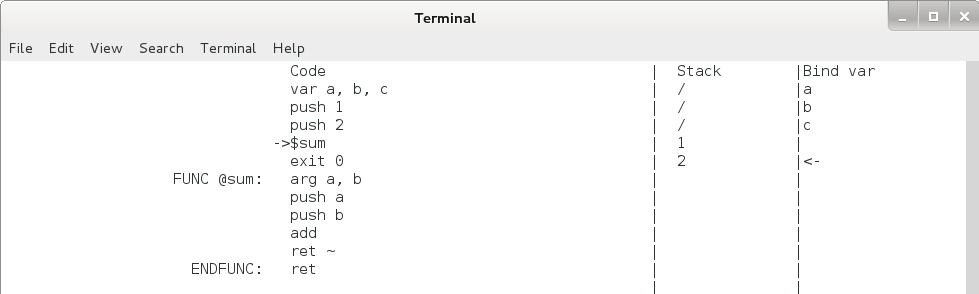
图4.8 函数调用执行过程2
下面就要开始调用函数了,让我们再敲 1 下回车,看看发生了什么:

图4.9 函数调用执行过程3
可以看到,code 区中,eip 已经跳到 sum 函数内的第1条命令 push a 那里了;而栈区中,栈顶向下增长了一个单元,栈顶单元里多了一个 (RetInfo) ,调用者压入的两个参数 1 和 2 被绑定了变量 a 和 b,而原来绑定的三个变量 a, b, c 消失了。
(RetInfo) 里面有什么?原来绑定的变量呢,到哪去了?
我们先把这两个问题放一放,先一步一步运行函数内的命令,到 ret ~ 这一行停下来,见下图:
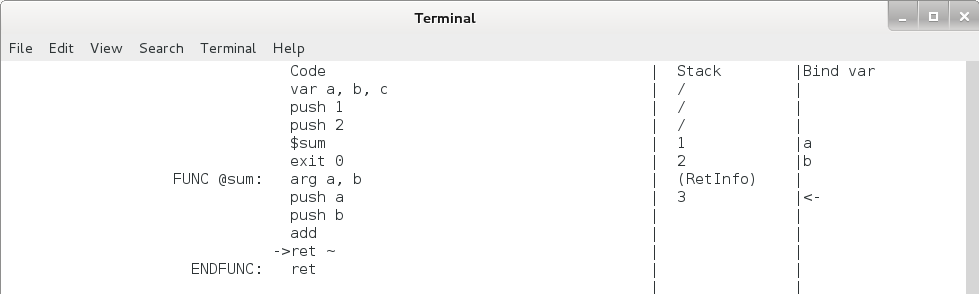
图4.10 函数调用执行过程4
可以看出,此时 a + b 的结果已经计算出来并放到栈顶了,让我们再敲一下回车,执行一下 ret ~ 这条命令,看看发生了什么:
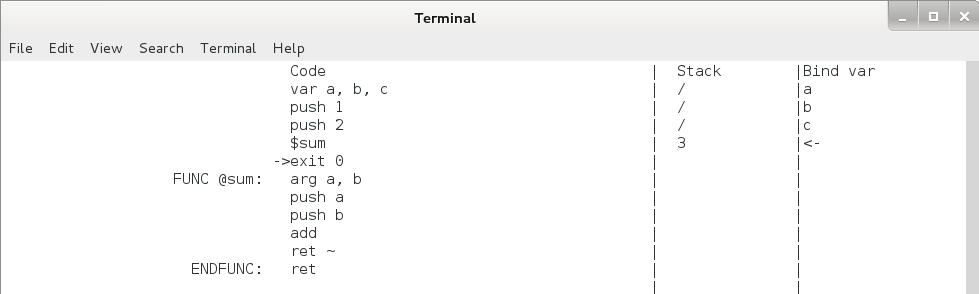
图4.11 函数调用单步执行过程5
可以看到,eip 跳回到了 $sum 后面的 exit 0 这一行,栈顶指针向上退回了 3 个单元,新的栈顶元素变成了 3 。我们把图4.11和图4.8对比一下可以看出,eip 移动到了下一条命令,压入的两个参数 1 和 2 出栈了,而 sum(1 , 2) 则被压入了栈顶,这个 $sum 命令和 add 命令的效果是完全一样的。
下面再详细的说明函数调用的整个过程中发生了什么事情,并解释前面的两个问题:(RetInfo) 里面有什么?原来绑定的变量到哪去了?
(1) 在函数调用之前,函数调用者按 从左向右 的顺序把函数的参数压入栈内。
(2) 在函数调用时,也就是 $sum 这条命令执行时, Pcode 虚拟机把:
- 函数的返回地址,也就是 $sum 下面那条命令的地址
- 虚拟机中当前的变量表(var_table)
- 函数的参数数量
这三个东西打包进 (RetInfo) ,并将其压入栈顶。注意这只是虚拟机,栈单元中可以放你想放的任何东西。
之后,虚拟机新建一个空的变量表,再根据 arg 后面的参数名称,把这些参数名称按顺序绑定到调用者压入栈内的几个单元上,并在新的变量表中记录下这些参数名及绑定的地址,再将此变量表设为当前变量表。这就是为什么图 4.6 中,原来的 a, b, c 不见了,而新的 a, b 则绑定到 (RetInfo) 上面的两个单元上。
最后,虚拟机跳转到函数内的第一条命令,开始执行函数过程。
(3) 当函数调用完毕后,也就是 ret 命令执行的时,虚拟机首先根据 ret 命令的型式计算出函数的返回值。
之后虚拟机从不停地将栈顶指针向上退回,直到遇到一个 (RetInfo) ,这时虚拟机将其出栈并解包,得到函数的返回地址、虚拟机的上一个变量表(也是函数调用者的变量表)、以及函数参数的数量。
然后虚拟机根据参数数量清栈(把调用者入栈的参数出栈),并将返回值放入栈顶。
再删掉当前变量表,将上一个变量表恢复为当前变量表,所以图 4.11 中,参数 a, b 都不见了,而原来的 a, b, c 又回来了。
最后,虚拟机跳转到函数的返回地址,开始执行 $sum 后面的命令,整个函数调用过程完毕。
10、中间代码 Pcode 总结
好了,中间代码 Pcode 、 Pcode 虚拟机和 Pcode 模拟器就讲完了, Pcode 一共才7组命令,都很容易学习,学过计算机系统架构和汇编语言的读者应该很快就能掌握好。熟悉 python 的读者可以先结合这两章对 Pcode 命令和 Pcode 虚拟机的描述阅读一下 Pcode 模拟器的源码,了解一下 Pcode 虚拟机的具体实现。
Pcode 提供了一些如 push / pop / add / jmp 等操作非常简单的命令,足够接近真实的计算机指令操作,有些命令几乎和 x86 指令一模一样,这使得它易于被翻译成真正的计算机指令,我们将在第 15 章介绍如何将 Pcode 翻译成 x86 汇编。
另一方面,Pcode 也提供了如 var / FUNC / ENDFUNC 这样和高级语言接近的命令,它采用了逆波兰表达式这样的逻辑顺序,易于理解和实现,这些都降低了将高级语言编译成 Pcode 的难度,我们将在下一章介绍如何手工将 TinyC 源程序翻译成 Pcode ,然后在下下一章开始介绍编译器的普遍原理,介绍如何分析 TinyC 源程序的语法结构,以及如何自动生成 Pcode 等。
总而言之,用 Pcode 作为我们的 TinyC 编译组件的中间代码是非常合适的。
四、手工编译 TinyC
1、函数定义
本章介绍如何手工将 TinyC 源程序翻译成 Pcode ,因为只有我们对翻译的过程和细节都了如指掌后,才可能编写出程序来进行自动翻译。
函数定义的翻译在上一章其实讲的差不多了,函数的开头和结尾分别改成 FUNC 和 ENDFUNC 就可以了,FUNC 后接 @ + func_name + ”:” ,若函数有参数,则在函数体的第一行加 arg + 参数列表,具体如下:
TinyC:
int foo(int a, int b) {
...
}Pcode:
FUNC @foo:
arg a, b
...
ENDFUNC2、变量声明、赋值语句、函数调用语句
变量声明直接将 TinyC 的 int 改成 var 就可以了。
赋值语句的左边为变量名,右边为表达式,先将表达式转换成后缀表达式,再按顺序翻译相应的 Pcode ,最后在加一个 pop var_name:
赋值语句:
a = 1 + 2 * b / sum (5, 8);
逆波兰表达式:
1 2 b * 5 8 sum / +
Pcode:
push 1
push 2
push b
mul
push 5
push 8
$sum
div
add
pop a注意对于自定义的函数,需在函数名前面加 $ 。
可以看出对于复杂一点的表达式,人工将其转化成正确的后缀表达式是很困难的,必须借助计算机程序来做这件事了,这个就留给我们的 TinyC 编译器吧。
函数调用语句其实在上面的表达式转换中就有了,先从左向右将参数入栈,再调用函数,若参数是一个表达式,则先将这个表达式翻译成 Pcode 。
TinyC:
foo(1, a, sum(b, 5));
Pcode:
push 1
push a
push b
push 5
$sum
$foo
pop注意最后的 pop 是为了将 foo 函数的返回值出栈的,因为这个值以后都不会再被使用到。如果函数调用是在表达式的内部,则不需要使用 pop 。
3、控制和循环语句
if 和 while 语句利用 jz 和 jmp 命令就可以实现,首先看 if 语句:
TinyC:
if (a > 0) {
print("a is a positive number");
} else {
print("a is a negative number");
}Pcode:
_beg_if:
; test expression
push a
push 0
cmpgt
jz _else
; statements when test is true
print "a is a positive number"
jmp _end_if
_else:
; statements when test is false
print "a is a negative number"
_end_if:可以看出上述 Pcode 有固定的结构型式,将测试语句和两个执行体翻译成 Pcode 放到相对应的地方即可。
再来看 while 语句:
TinyC:
while (a > 0) {
a = a - 1;
}Pcode:
_beg_while:
; test expression
push a
push 0
cmpgt
jz _endwhile
; statements when test is true
push a
push 1
sub
pop a
jmp _beg_while
_end_while:结构也很简单,将测试语句和执行体翻译成 Pcode 放到相对应的地方即可。
continue 和 break 呢?将 continue 换成 jmp _beg_while,break 换成 jmp _end_while 就可以啦。
对于有多个 if / while ,以及有嵌套 if / while 语句,就要注意对同一个 if / while 语句块使用同一个Label,不同的语句块的 Label 不能冲突,continue 和 break 要 jmp 到正确的 Label ,这些工作人工来做显然很困难也容易出错,留给我们的 TinyC 编译器吧。
五、编译器基本流程
1、什么是编译器,为什么要开发编译器
编译器是将一种程序语言(源程序:source language)翻译为另一种程序语言(目标程序:target language)的计算机程序。一般来说,源程序为高级语言,而目标语言则是汇编语言或机器码。
早期的计算机程序员们用机器码写程序,编程十分耗时耗力,也非常容易出错,很快程序员们发明了汇编语言,提高了编程的速度和准确度,但编写起来还是不容易,且程序严格依赖于特定的机器,很难移植和重复利用。
上世纪50~60年代,第一批高级语言及编译器被开发出来,程序的文法非常接近于数学公式以及自然语言,使得编写、阅读和维护程序的难度大为降低,程序编制的速度、规模和稳定性都有了质的飞跃。
可以说是编译器的产生带来了计算机行业的飞跃发展,所以开发编译器是非常有必要的。
2、编译器的工作流程
先让我们回忆一下我们在上一章中是如何手工将源程序翻译成中间代码的,想一想翻译的第一步是什么?第一步是我们的人脑要理解源程序,理解源程序的结构,理解源程序的含义、作用,然后才能根据我们的理解进行翻译。
要让计算机将源程序翻译成目标程序,我们也要让计算机真正的理解源程序,让计算机分析出源程序的结构,将源程序由一串无意义的字符流解析为一个个的有特定含义的构件,将这些构件进行转换后,再按特定的规则和顺序将转换后的构件拼装成目标程序。
编译器的工作流程见下图:
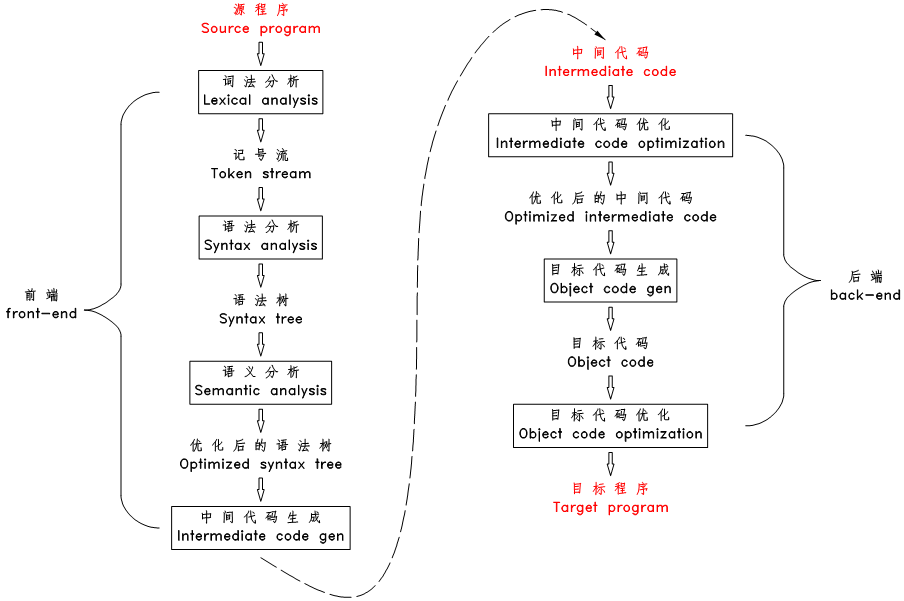
图6.1 编译器工作流程
编译器的工作流程简要描述如下:
- 对源文件进行扫描,将源文件的字符流拆分分一个个的词(记号),此为词法分析
- 根据语法规则将这些记号构造出语法树,此为语法分析
- 对语法树的各个节点之间的关系进行检查,检查语义规则是否被违背,同时对语法树进行必要的优化,此为语义分析
- 遍历语法树的节点,将各节点转化为中间代码,并按特定的顺序拼装起来,此为中间代码生成
- 对中间代码进行优化
- 将中间代码转化为目标代码
- 对目标代码进行优化,生成最终的目标程序
以上阶段划分仅仅是示意性的,实际的编译器中,上面说的这些阶段经常组合在一起,但将这些阶段设想为编译器中一个个单独的片断是对于我们理解编译器的工作流程是非常有用的,且对于编译器设计的模块化也是非常有利的。
下面再以简单的例子来形象一点的说明以上工作流程:
下面再以简单的例子来形象一点的说明以上工作流程:
(1) 词法分析
编译器扫描源文件的字符流,过滤掉字符流中的空格、注释等,并将其分割为一个个的词(或称为记号、token,下文中都将称为 token )。例如下面的语句:
a = value + sum(5, 123);
将被拆分为11个 token :
a 标识符
= 赋值运算符
value 标识符
+ 加号
sum 标识符
( 左括号
5 整数
, 逗号
123 整数
) 右括号
; 分号(2) 语法分析
词法分析完成后,上面的字符流就被转换为 token 流了:
ID<a> '=' ID<value> '+' ID<sum> '(' NUM<5> ',' NUM<123> ')' ';'
上面的 ID<a> 表示这一个标识符类型的 token ,其内容为 a。
接下来,根据语言的语法规则来解析这个 token 流。首先,这是一个语句。而TinyC 中只有四种语句:赋值语句,函数调用语句, if 语句和 while 语句。把这四种语句的语法结构和这个 token 流对比一下发现只有赋值语句的结构才能和它匹配:
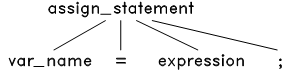
图6.2 赋值语句的语法结构树
于是将此语法结构应用到 token 流上,把源程序的等号两边的内容分别放在该语法结构树的对应节点上,生成语法树如下:
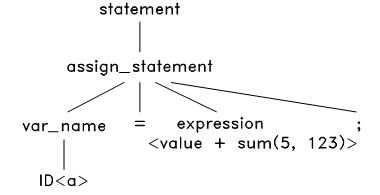
图6.3 语法解析第1步
接下来,对这个语法树上的 expresion<value + sum(5, 123)> 进行解析。TinyC中的表达式有很多种,包括:变量表达式、数字表达式、加法表达式、减法表达式等等。经过对比,发现只有加法表达式的结构才能匹配这个 <value + sum(5, 123)>,于是将加法表达式的语法结构应用到此表达式上,生成:
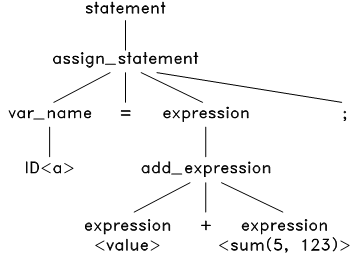
图6.4 语法解析第2步
然后,解析这个语法树上的 <value> 和 <sum(5, 123> ,经过对比,发现只有变量表达式和函数调用表达式的结构能匹配成功,应用后,得到:
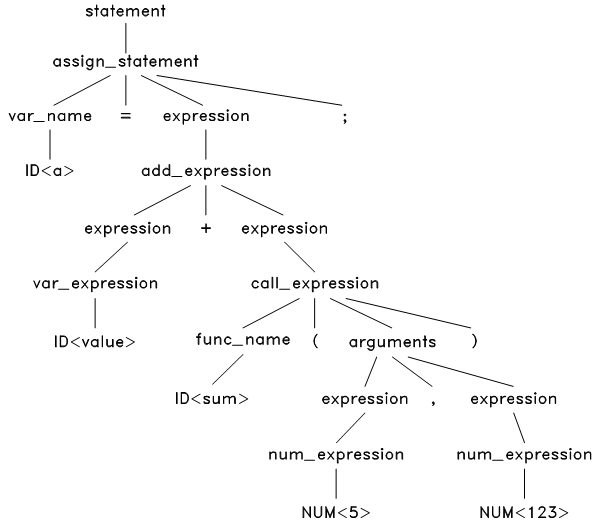
图6.5 语法解析第3步
这个语法树中,有些节点是可以去掉的,如 assign expression 中的 ‘=’ 和 ‘;’ ,既然我们已经知道这是一个赋值表达式,那么这两个节点是不必要的了,我们去掉这样的节点,同时对语法树进一步浓缩,可以得到最终的抽象语法树:
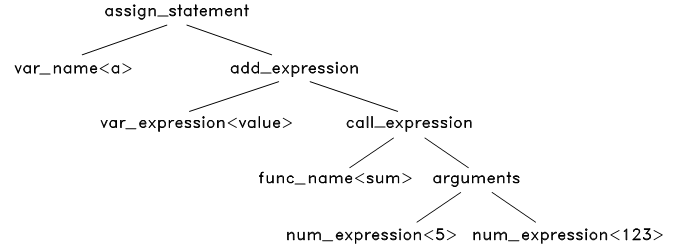
图6.6 语法解析第4步
可以看出,语法分析的过程就是不断的将语法规则应用于源程序,将源程序 解析 成一颗抽象语法树。
语法分析可以说是编译器中最基础的一步,它将人可以理解的语法规则转换成计算机可以 “理解” 的树形结构,之后的语义分析、代码生成甚至代码优化都是基于对这个抽象树进行遍历、检查和修改优化的操作上进行的。
(3) 语义分析
语义分析阶段,编译器开始对语法树进行一次或多次的遍历,检查程序的语义规则。主要包括声明检查和类型检查,如上一个赋值语句中,就需要检查:
- 语句中的变量 a 和 value 、函数 sum 是否被声明过
- sum 函数的参数数量和类型是否与其声明的参数数量及类型匹配
- 加号运算的两个操作数的类型是否匹配(sum 函数的返回值类型是否和变量 value 匹配)
- 赋值运算符两边的操作数的类型是否匹配
语义检查的步骤和人对源代码的阅读和理解的步骤差不多,一般都是在遍历语法树的过程中,遇到变量声明和函数声明时,则将变量名——类型、函数名——返回类型——参数数量及类型等信息保存到符号表里,当遇到使用变量和函数的地方,则根据名称在符号表中查找和检查,查找该名称是否被声明过,该名称的类型是否被正确的使用等等。显然,对于有些变量和函数的声明可以放在其使用位置的后面的语言(比如 java ),语义检查至少需要对语法树进行 2 次遍历。
语义检查时,也会对语法树进行一些优化,比如将只含常量的表达式先计算出来,如:
a = 1 + 2 * 9;
会被优化成:
a = 19;
语义分析完成后,源程序的结构解析完成,所有编译期错误都已被排除,所有使用到的变量名和函数名都绑定到其声明位置(地址)了,至此编译器可以说是真正理解了源程序,可以开始进行代码生成和代码优化了。
(4) 中间代码生成
一般的编译器并不直接生成目标代码,而是先生成某种中间代码,然后再生成目标代码。
之所以先生成中间代码,一个是为了降低编译器开发的难度,从第 4 章中对 Pcode 的总结中可以看到,对于这种既有部分高级语言特性、又有接近机器语言操作的中间代码,将高级语言翻译成中间代码、将此中间代码再翻译成目标代码的难度都比直接将高级语言翻译成目标代码的难度要低。
第二个原因是是为了增加编译器的模块化、可移植性和可扩展性,一般来说,中间代码既独立于任何高级语言,也独立于任何目标机器架构,这就为开发出适应性广泛的编译器提供了媒介。如下图中,可以通过编写 m + n 个编译模块而获得 m * n 种编译器。
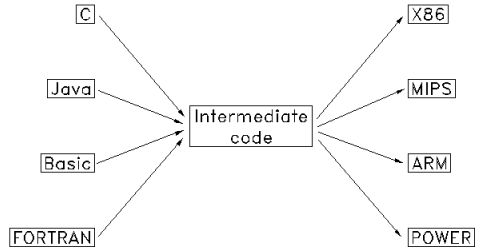
图6.7 编译模块示意图
第三个原因是为了代码优化,一般来说,计算机直接生成的代码比人手写的汇编要庞大、重复很多,计算机科学家们对一些具有固定格式的中间代码(最典型的是三地址中间码)的进行大量的研究工作,提出了很多广泛应用的、效率非常高的优化算法,可以对中间代码进行优化,比直接对目标代码进行优化的效果要好很多。
下面以图6.6的语法树为例说明中间代码生成的方法,首先从根节点 assign_statement 开始:
GEN_CODE( assign_statement<a = value + sum(5, 123);> )
第5章的手工编译 TinyC 中已经介绍了,对于赋值语句,先将其右边的表达式翻译成 Pcode ,再在最后加一个 pop var_name 就可以了,如下:
GEN_CODE( add_expression<value + sum(5, 123)> )
pop a对于加法表达式,将两个操作符翻译成 Pcode ,再加上 add ,如下:
GEN_CODE( var_expression<value> )
GEN_CODE( call_expression<sum(5, 123)> )
add
pop a对于变量表达式,直接翻译成 push var_name ,对于函数调用表达式,将其参数翻译成 Pcode ,再加上 $func_name,如下:
push value
GEN_CODE( arguments<5, 123> )
$sum
add
pop a最后将各参数翻译成 Pcode ,最终得到:
push value
push 5
push 123
$sum
add
pop a对比一下手工翻译的结果,是不是完全一样?
从以上过程可以看出,代码生成的算法是一个递归的算法,递归的遍历语法树,将语法树上的一些节点替换成中间代码块,再根据特定的规则和顺序将这些中间代码块拼装起来。
(5) 中间代码优化
在本阶段,编译器对中间代码进行优化,尝试生成体积最小、最快、最有效率的代码。常见的优化方法有:
- 去除永远都不会被执行的代码区
- 去掉未被使用到的变量
- 优化循环体,将每次循环中的运行结果不变的语句移到循环的最外面
- 算术表达式优化,将乘 1 和 加 0 等操作去掉,将乘 2 优化成左移 1 位等
(6)目标代码生成
本阶段,编译器根据中间代码和目标机器架构生成目标代码,由于大部分中间代码接近低级语言,这一步的难度较低。比如 Pcode 中,很多 Pcode 命令可以用一组 x86 指令代替,如:
; ------------------------------------------------
; Pcode
push 3
; x86
PUSH DWORD 3
; ------------------------------------------------
; Pcode
push a
; x86
PUSH DWORD [EBP - 12] ; 假定a的地址为 EBP - 12
; ------------------------------------------------
; Pcode
add
; x86
POP EAX
ADD [ESP], EAX注意以上代码中,Pcode命令全部小写,x86指令则全部大写,以区分二者中的同名命令,这将是本书采用的一个惯例。另外,本书中的x86仅指 32位 的x86。
(7)目标代码优化
本阶段,编译器利用目标机器的提供的特性对目标代码做进一步的优化,如利用 CPU 的流水线,利用 CPU 的多核等,生成最终的目标代码。
(8)编译过程的错误检查
在词法、语法和语义分析的过程中,都伴随着错误检查,词法错误主要是字符错误(如非法字符、未结束的注释、未结束的字符串等),语法错误主要是格式错误(如语句后未加分号、不匹配的括号等),最常发生的是语义错误(如变量名错误、表达式类型错误、函数参数不匹配等)。编译器不仅检查错误,还需要精确定位出错误发生的位置,协助编程人员修改。
错误检查和代码优化是编译器中两个很重要的步骤,也是最难实现的部分,前者定位出所有的编译期错误所在,协助程序员写出正确的程序,后者则保证生成高效的目标程序,这两点是早期编译器获得广泛接受的基石。
(9)编译器的前端和后端
一般以中间代码为界,将编译器分为前端和后端,其中前端包括词法分析、语法分析、语义分析以及中间代码生成,后端包括中间代码优化、目标代码生成和目标代码优化。前端一般只依赖于源程序语言,独立于机器架构,而后端则只依赖于机器架构、独立于高级语言。
(10)编译器的遍数
从词法分析到语法分析生成语法树一般只需要对源文件进行一遍扫描就可以了,生成语法树后,语义检查、代码优化的过程中可能需要对语法树进行反复的遍历,5 、 6 遍,甚至 8 遍都是有可能的。但有些语言(如 C 语言)也可能 1 遍就编译完成,其语义检查和代码生成可以在语法分析的同时同步进行,此时一般无任何代码优化。
3、TinyC 编译器的工作流程
TinyC 编译器是一个非常 “tiny” 的编译器,仅保留了编译器中最基本的功能,只保留了词法分析、语法分析、中间代码生成以及目标代码生成,其中中间代码是在语法分析的过程中同步进行的,TinyC 编译器的工作流程如下:

六、词法分析与语法分析
1、flex
1、安装flex
1、到下面这个链接下载安装包:
http://ftp.gnu.org/gnu/m4/m4-1.4.9.tar.gzhttp://ftp.gnu.org/gnu/m4/m4-1.4.9.tar.gz2、把安装包上传到/usr/local/src目录下,并解压:
tar -xvf m4-1.4.9.tar.gz 3、进入到解压后的目录m4-1.4.9
cd m4-1.4.94、配置
./configure5、编译
make6、安装
make install 7、下载 Flex
首先,打开网站:Releases · westes/flex · GitHub。下载flex的源码,最新版本是flex-2.6.4.tar.gz,下载到Linux系统中保存。

8、解压缩源码
使用命令:tar -xvzf flex-2.5.35.tar.gz 解压缩下载的源码。
9、编译源码
进入flex-2.5.35文件夹,输入命令:./configure & make -f Makefile.in。
10、安装
最后,输入命令:make install进行安装即可。
11、测试
新建一个文本文件,输入以下内容:
%%
[0-9]+ printf("?");
# return 0;
. ECHO;
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}将此文件另存为 hide-digits.l 。注意此文件中的 %% 必须在本行的最前面(即 %% 前面不能有任何空格)。
之后,在终端输入:
$ flex hide-digits.l
此时目录下多了一个 “lex.yy.c” 文件,把这个 C 文件编译并运行一遍:
$ gcc -o hide-digits lex.yy.c
$ ./hide-digits然后在终端不停的敲入任意键并回车,可以发现,敲入的内容中,除数字外的字符都被原样的输出了,而每串数字字符都被替换成 ? 了。最后敲入 # 后程序退出了。如下:
eruiewdkfj
eruiewdkfj
1245
?
fdsaf4578
fdsaf?
...
#2、flex原理
当在命令行中运行 flex 时,第二个命令行参数(此处是 hide-digits.l )是提供给 flex 的分词模式文件, 此模式文件中主要是用户用正则表达式写的分词匹配模式,用flex 会将这些正则表达式翻译成 C 代码格式的函数 yylex ,并输出到 lex.yy.c 文件中,该函数可以看成一个有限状态自动机。
下面再来详细解释一下 hide-digits.l 文件中的代码,首先第一段是:
%%
[0-9]+ printf("?");
# return 0;
. ECHO;
%%flex 模式文件中,%% 和 %% 之间的内容被称为 规则(rules),本文件中每一行都是一条规则,每条规则由 匹配模式(pattern) 和 事件(action) 组成, 模式在前面,用正则表达式表示,事件在后面,即 C 代码。每当一个模式被匹配到时,后面的 C 代码被执行。
简单来说,flex 会将本段内容翻译成一个名为 yylex 的函数,该函数的作用就是扫描输入文件(默认情况下为标准输入),当扫描到一个完整的、最长的、可以和某条规则的正则表达式所匹配的字符串时,该函数会执行此规则后面的 C 代码。如果这些 C 代码中没有 return 语句,则执行完这些 C 代码后, yylex 函数会继续运行,开始下一轮的扫描和匹配。
当有多条规则的模式被匹配到时, yylex 会选择匹配长度最长的那条规则,如果有匹配长度相等的规则,则选择排在最前面的规则。
第二段中的 main 函数是程序的入口, flex 会将这些代码原样的复制到 lex.yy.c 文件的最后面。最后一行的 yywrap 函数的作用后面再讲,总之就是 flex 要求有这么一个函数。
int main(int argc, char *argv[]) {
yylex();
return 0;
}
int yywrap() { return 1; }因此,程序开始运行后,就开始执行 yylex 函数,然后开始扫描标准输入。当扫描出一串数字时,[0-9]+ 被匹配到,因此执行了 printf(”?”) ,当扫描到其他字符时,若不是 # ,则 . 被匹配,后面的 ECHO 被执行, ECHO 是 flex 提供的一个宏,作用是将匹配到的字符串原样输出,当扫描到 # 后, # 被匹配, return 0 被执行, yylex 函数返回到 main 函数,之后程序结束。
下面再来看一个稍微复杂一点的例子:
%{
#define T_WORD 1
int numChars = 0, numWords = 0, numLines = 0;
%}
WORD ([^ \t\n\r\a]+)
%%
\n { numLines++; numChars++; }
{WORD} { numWords++; numChars += yyleng; return T_WORD; }
<<EOF>> { return 0; }
. { numChars++; }
%%
int main() {
int token_type;
while (token_type = yylex()) {
printf("WORD:\t%s\n", yytext);
}
printf("\nChars\tWords\tLines\n");
printf("%d\t%d\t%d\n", numChars, numWords, numLines);
return 0;
}
int yywrap() {
return 1;
}将此文件另存为 word-spliter.l 。注意此文件中的 %{ 和 %} 必须在本行的最前面(前面不能有空格),同时,注意 %} 不要写成 }% 了。在终端输入:
$ flex word-spliter.l
$ gcc -o word-spliter lex.yy.c
$ ./word-spliter < word-spliter.l将输出:
WORD: %{
WORD: #define
...
WORD: }
Chars Words Lines
470 70 27可见此程序其实就是一个原始的分词器,它将输入文件分割成一个个的 WORD 再输出到终端,同时统计输入文件中的字符数、单词数和行数。此处的 WORD 指一串连续的非空格字符。
下面,详细介绍 flex 输入文件的完整格式,同时解释一下本文件的代码。一个完整的 flex 输入文件的格式为:
%{
Declarations
%}
Definitions
%%
Rules
%%
User subroutines输入文件的第 1 段 %{ 和 %} 之间的为 声明(Declarations) ,都是 C 代码,这些代码会被原样的复制到 lex.yy.c 文件中,一般在这里声明一些全局变量和函数,这样在后面可以使用这些变量和函数。
第 2 段 %} 和 %% 之间的为 定义(Definitions),在这里可以定义正则表达式中的一些名字,可以在 规则(Rules) 段被使用,如本文件中定义了 WORD 为 ([^ \t\n\r\a]+) , 这样在后面可以用 {WORD} 代替这个正则表达式。
第 3 段为 规则(Rules) 段,上一个例子中已经详细说明过了。
第 4 段为 用户定义过程(User subroutines) 段,也都是 C 代码,本段内容会被原样复制到 yylex.c 文件的最末尾,一般在此定义第 1 段中声明的函数。
以上 4 段中,除了 Rules 段是必须要有的外,其他三个段都是可选的。
输入文件中最后一行的 yywrap 函数的作用是将多个输入文件打包成一个输入,当 yylex 函数读入到一个文件结束(EOF)时,它会向 yywrap 函数询问, yywrap 函数返回 1 的意思是告诉 yylex 函数后面没有其他输入文件了,此时 yylex 函数结束,yywrap 函数也可以打开下一个输入文件,再向 yylex 函数返回 0 ,告诉它后面还有别的输入文件,此时 yylex 函数会继续解析下一个输入文件。总之,由于我们不考虑连续解析多个文件,因此此处返回 1 。
和上一个例子不同的是,本例中的 action 中有 return 语句,而 main 函数内是一个 while 循环,只要 yylex 函数的返回值不为 0 ,则 yylex 函数将被继续调用,此时将从下一个字符开始新一轮的扫描。
另外,本例中使用到了 flex 提供的两个全局变量 yytext 和 yyleng,分别用来表示刚刚匹配到的字符串以及它的长度。
为方便编译,使用 makefile 进行编译及运行:
run: word-spliter
./word-spliter < word-spliter.l
word-spliter: lex.yy.c
gcc -o $@ $<
lex.yy.c: word-spliter.l
flex $<将以上内容保存为 makefile ,和 word-spliter.l 文件放在当前目录,再在终端输入:
make将输出和前面一样的内容。 makefile 的语法本站就不介绍了,后文中的大部分程序都将使用 makefile 编译。
好了, flex 的使用就简单介绍到这,以上介绍的功能用来解析 TinyC 文件已经差不多够了。有兴趣的读者可以到其主页上去阅读一下它的手册,学习更强大的功能。下面介绍如何使用 flex 对 TinyC 源文件进行词法分析。
3、使用 flex 对 TinyC 源文件进行词法分析
上一节的第二个例子 word-spliter 就是一个原始的分词器,在此例的框架上加以扩展就可以做为 TinyC 的词法分析器了。
word-spliter 中只有 WORD 这一种类型的 token ,所有连续的非空格字符串都是一个 WORD ,它的正则表达式非常简单: [^ \t\n\r\a]+ 。 该程序中为 WORD 类型的 token 定义了一个值为 1 的编号: T_WORD ,每当扫描出一个完整的 WORD 时,就向 main 函数返回 T_WORD ,遇到文件结束则返回 0 。 main 函数则根据 yylex 函数的返回值进行不同的处理。
从 word-spliter 程序的框架和流程中可以看出,词法分析器的扩展方法非常简单:
(1) 列出 TinyC 中所有类型的 token;
(2) 为每种类型的 token 分配一个唯一的编号,同时写出此 token 的正则表达式;
(3) 写出每种 token 的 rule (相应的 pattern 和 action )。
TinyC 中的 token 的种类非常少,按其词法特性,分为以下三大类。
第 1 类为单字符运算符,一共 15 种:
+ * - / % = , ; ! < > ( ) { }
第 2 类为双字符运算符和关键字,一共 16 种:
<=, >=, ==, !=, &&, ||
void, int, while, if, else, return, break, continue, print, readint第 3 类为整数常量、字符串常量和标识符(变量名和函数名),一共 3 种。
除第 3 类 token 的正则表达式稍微麻烦一点外,第 1 、 2 类 token 的正则表达式就是这些运算符或关键字的字面值。
token 的编号原则为:单字符运算符的 token 编号就是其字符的数值,其他类型的 token 则从 256 开始编号。
各类 token 的正则表达式及相应的 action 见下面的 scaner.l 文件,该文件的框架和上一节中的 word-spliter.l 是完全一样的,只不过 token 的类别多了。
%{
#include "token.h"
int cur_line_num = 1;
void init_scanner();
void lex_error(char* msg, int line);
%}
/* Definitions, note: \042 is '"' */
INTEGER ([0-9]+)
UNTERM_STRING (\042[^\042\n]*)
STRING (\042[^\042\n]*\042)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
OPERATOR ([+*-/%=,;!<>(){}])
SINGLE_COMMENT1 ("//"[^\n]*)
SINGLE_COMMENT2 ("#"[^\n]*)
%%
[\n] { cur_line_num++; }
[ \t\r\a]+ { /* ignore all spaces */ }
{SINGLE_COMMENT1} { /* skip for single line comment */ }
{SINGLE_COMMENT2} { /* skip for single line commnet */ }
{OPERATOR} { return yytext[0]; }
"<=" { return T_Le; }
">=" { return T_Ge; }
"==" { return T_Eq; }
"!=" { return T_Ne; }
"&&" { return T_And; }
"||" { return T_Or; }
"void" { return T_Void; }
"int" { return T_Int; }
"while" { return T_While; }
"if" { return T_If; }
"else" { return T_Else; }
"return" { return T_Return; }
"break" { return T_Break; }
"continue" { return T_Continue; }
"print" { return T_Print; }
"readint" { return T_ReadInt; }
{INTEGER} { return T_IntConstant; }
{STRING} { return T_StringConstant; }
{IDENTIFIER} { return T_Identifier; }
<<EOF>> { return 0; }
{UNTERM_STRING} { lex_error("Unterminated string constant", cur_line_num); }
. { lex_error("Unrecognized character", cur_line_num); }
%%
int main(int argc, char* argv[]) {
int token;
init_scanner();
while (token = yylex()) {
print_token(token);
puts(yytext);
}
return 0;
}
void init_scanner() {
printf("%-20s%s\n", "TOKEN-TYPE", "TOKEN-VALUE");
printf("-------------------------------------------------\n");
}
void lex_error(char* msg, int line) {
printf("\nError at line %-3d: %s\n\n", line, msg);
}
int yywrap(void) {
return 1;
}上面这个文件中,需要注意的是,正则表达式中,用双引号括起来的字符串就是原始字符串,里面的特殊字符是不需要转义的,而双引号本身必须转义(必须用 \” 或 \042 ),这是 flex 中不同于常规的正则表达式的一个特性。
除单字符运算符外的 token 的编号则在下面这个 token.h 文件,该文件中同时提供了一个 print_token 函数,可以根据 token 的编号打印其名称。
#ifndef TOKEN_H
#define TOKEN_H
typedef enum {
T_Le = 256, T_Ge, T_Eq, T_Ne, T_And, T_Or, T_IntConstant,
T_StringConstant, T_Identifier, T_Void, T_Int, T_While,
T_If, T_Else, T_Return, T_Break, T_Continue, T_Print,
T_ReadInt
} TokenType;
static void print_token(int token) {
static char* token_strs[] = {
"T_Le", "T_Ge", "T_Eq", "T_Ne", "T_And", "T_Or", "T_IntConstant",
"T_StringConstant", "T_Identifier", "T_Void", "T_Int", "T_While",
"T_If", "T_Else", "T_Return", "T_Break", "T_Continue", "T_Print",
"T_ReadInt"
};
if (token < 256) {
printf("%-20c", token);
} else {
printf("%-20s", token_strs[token-256]);
}
}
#endif下面来编译一下这两个文件, makefile 文件为:
out: scanner
scanner: lex.yy.c token.h
gcc -o $@ $<
lex.yy.c: scanner.l
flex $<将以上 3 个文件保存在终端的当前目录,再输入 make ,编译后生成了 scanner 文件。
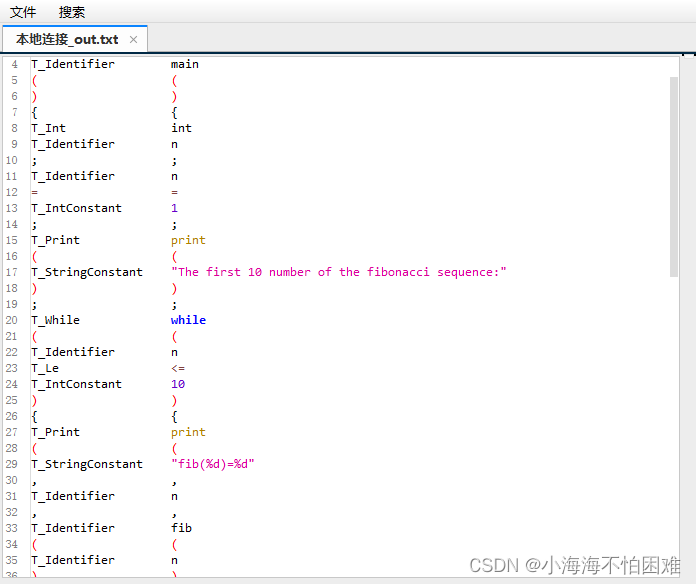
下面来测试一下这个词法分析器,将 samples.zip 文件下载并解压到 samples 目录,此文件包中有很多测试文件,我们先测试一下其中的一个文件,输入:
$ ./scanner < samples/sample_6_function.c > out.txt
再打开 out.txt 文件看看,可以看出 sample_6_function.c 文件的所有 token 都被解析出来了:
下面全部测试一下这些文件,在终端输入以下内容:
for src in $(ls samples/*.c); do ./scanner < $src > $src.lex; done
再在终端输入: bash test.sh 。之后,查看一下 samples 目录下新生成的 ”.lex” 文件。可以看出所有源文件都被解析完成了。
TinyC 语言中只有两类词法错误,一种是未结束的字符串,即只有前面一个双引号的字符串,另外一种就是非法字符,如 ~ @ 等(双引号内部的除外),scanner.l 文件中可以识别出这两种词法错误,同时定位出错误所在的行,详见该文件的 Rules 段的最后两条 Rule 。
2、bison
1、安装bison
1、使用 yum 安装bison
yum install bison
2、查看版本:
bison --version
安装完成后,新建一个文本文件,输入以下内容:
%{
#include "y.tab.h"
%}
%%
[0-9]+ { yylval = atoi(yytext); return T_NUM; }
[-/+*()\n] { return yytext[0]; }
. { return 0; /* end when meet everything else */ }
%%
int yywrap(void) {
return 1;
}将此文件另存为 calc.l 。注意此文件中的 %% 、 %{ 、 %} 的前面不能有任何空格。
再新建一个文本文件,输入以下内容:
%{
#include <stdio.h>
void yyerror(const char* msg) {}
%}
%token T_NUM
%left '+' '-'
%left '*' '/'
%%
S : S E '\n' { printf("ans = %d\n", $2); }
| /* empty */ { /* empty */ }
;
E : E '+' E { $$ = $1 + $3; }
| E '-' E { $$ = $1 - $3; }
| E '*' E { $$ = $1 * $3; }
| E '/' E { $$ = $1 / $3; }
| T_NUM { $$ = $1; }
| '(' E ')' { $$ = $2; }
;
%%
int main() {
return yyparse();
}将此文件另存为 calc.y 。注意此文件中的 %% 、 %{ 、 %} 的前面也不能有任何空格。
将前面两个文件都放在终端的当前目录,再在终端输入:
bison -vdty calc.y
此时可以发现终端下多了三个文件: y.tab.h, y.tab.c, y.output 。
再在终端输入:
flex calc.l
此时终端下又多了一个文件: lex.yy.c 。
最后将 y.tab.c 和 lex.yy.c 一起编译并运行一遍:
gcc -o calc y.tab.c lex.yy.c
./calc然后在终端输入算术表达式并回车:
1+2+3
ans = 6
2*(2+7)+8
ans = 26可以发现回车后,终端会自动输出算术表达式的结果。这个程序就是一个简单的支持加、减、乘、除以及括号的整数计算器。想象一下,如果用 C 语言手工编写一个同样功能的程序,那代码量肯定很大吧。
2、bison原理
下面再来详细的解释一下 calc.l 和 calc.y 代码。
calc.l 文件就是一个词法分析器(或者说扫描器),在第 8 章中已经介绍了 flex 的语法。该扫描器扫描标准输入(键盘),将其分割为一个个的 token ,从其代码中可以看出,它将整数扫描为一个 T_NUM 型的 token ,而将 “-/+*()n” 这些字符扫描为一个单字符 token (其 token_type 的值就是该字符的 ASCII 码),任何其他字符都会被扫描为一个值为 0 的 token 。
再来看 calc.y 文件,这个就是 bison 的自定义语法文件,其格式和 flex 分词模式文件的格式非常相似,共分为 4 段,如下:
%{
Declarations
%}
Definitions
%%
Productions
%%
User subroutines其中的 Declarations 段和 User subroutines 和 flex 文件中是一样的, bison 会将这些代码原样的拷贝到 y.tab.c 文件中; Definitions 段和 flex 中的功能也差不多,也是在这个段定义一些 bison 专有的变量,稍后再解释这个文件中的这个段里的代码;最重要的是 Productions 段,这里面是用户编写的语法产生式,这个文件里定义的产生式用常规的方式书写的格式如下:
S -> S E \n | ε
E -> E + E | E - E | E * E | E / E | T_NUM | ( E )bison 里面 ”:” 代表一个 “->” ,同一个非终结符的不同产生式用 “|” 隔开,用 ”;” 结束表示一个非终结符产生式的结束;每条产生式的后面花括号内是一段 C 代码、这些代码将在该产生式被应用时执行,这些代码被称为 action ,产生式的中间以及 C 代码内部可以插入注释(稍后再详细解释本文件中的这些代码);产生式右边是 ε 时,不需要写任何符号,一般用一个注释 /* empty */ 代替。
bison 会将 Productions 段里的第一个产生式的左边的非终结符(本文件中为 S )当作语法的起始符号,同时,为了保证起始符号不位于任何产生式的右边, bison 会自动添加一个符号(如 S’ )以及一条产生式(如 S’ -> S ),而将这个新增的符号当作解析的起始符号。
产生式中的非终结符不需要预先定义, bison 会自动根据所有产生式的左边来确定哪些符号是非终结符;终结符中,单字符 token ( token type 值和字符的 ASCII 码相同)也不需要预先定义,在产生式内部直接用单引号括起来就可以了(如本文件中的 ‘n’, ‘+’, ‘-‘ 等),其他类型的 token 则需要预先在 Definitions 段中定义好,如本文件中的 token T_NUM, bison 会自动为这种 token 分配一个编号,再写到 y.tab.h 文件中去,打开该文件,可以看到如下代码:
#ifndef YYTOKENTYPE
# define YYTOKENTYPE
enum yytokentype
{
T_NUM = 258
};
#endif
/* Tokens. */
#define T_NUM 258因此在 calc.l 文件中包含此文件就可以使用 T_NUM 这个名称了。
可以在 Definitions 段定义符号的优先级,本文件中,定义了各运算符的优先级,如下:
%left '+' '-'
%left '*' '/'其中的 %left 表明这些符号是左结合的。同一行的符号优先级相同,下面行的符号的优先级高于上面的。
bison 会将语法产生式以及符号优先级转化为一个 C 语言的 LALR(1) 动作表,并输出到 y.tab.c 文件中去,另外,还会将这个动作表以及语法中的相关要素以可读的文字形式输出到 y.output 文件中去,该文件中内容如下:
Grammar
0 $accept: S $end
1 S: S E '\n'
2 | %empty
3 E: E '+' E
4 | E '-' E
5 | E '*' E
6 | E '/' E
7 | T_NUM
8 | '(' E ')'
......
State 0
0 $accept: . S $end
$default reduce using rule 2 (S)
S go to state 1
State 1
0 $accept: S . $end
1 S: S . E '\n'
$end shift, and go to state 2
T_NUM shift, and go to state 3
'(' shift, and go to state 4
E go to state 5
......上面 state x 等表示一个状态以及该状态里面的所有形态,以及该状态的所有动作,由于采用了 LALR(1) 方法构造动作表,因此这些状态里的形态数量和用 LR(1) 法构造的有所不同。
bison 将根据自定义语法文件生成一个函数 int yyparse (void) (在 y.tab.c 文件中),该函数按 LR(1) 解析流程对词法分析得到的 token stream 进行解析,每当它需要读入下一个符号时,它就执行一次 x = yylex() ,每当它要执行一个折叠动作时,这个折叠动作所应用的产生式后面的花括号里面的 C 代码将被执行,执行完后才将相应的状态出栈。
若 token stream 是符合语法的,则解析过程中不会出错, yyparse 函数将返回 0 ,否则,该函数会在第一次出错的地方终止,并调用 yyerror 函数,然后返回 1 。
yyparse 函数不仅维持一个状态栈,它还维持一个符号属性栈,当它执行 shift 动作时,它除了将相应的状态压入状态栈之外,还会将一个类型为 YYSTYPE (默认和 int 相同)、名为 yylval 的全局变量的数值压入到属性栈内,而在 reduce 动作时,可以用 $1, $2, ... $n 来引用属性栈的属性, reduce 动作不仅将相应的状态出栈,还会将同样数量的属性出栈,这些属性和 reduce 产生式的右边的符号是一一对应的,同时,用 $$ 代表产生式左边的终结符,在 reduce 动作里可以设置 $$ 的值,当执行 goto 动作时,除了将相应的状态入栈,还会将 $$ 入栈。
以本程序为例:
(1) 当执行 yylex 函数时(在 calc.l 文件里),在扫描到一个完整的整数后, yylval = atoi(yytext) 将被执行,并返回 T_NUM ;
(2) 当 yyparse 执行 x = yylex() 后,将压入 yylval 的值,如果返回的 x 是 T_NUM,那这个符号已经和(1)中的 atoi(yytext) 这个值绑定起来了;
(3) 当 yyparse 执行 reduce E -> T_NUM 以及后面的 goto 动作时,$$ = $1 被执行,$1(绑定到 T_NUM 的值)将出栈,$$(=$1)将入栈,故符号 E 也被绑定了一个数值;
(4) 当 yyparse 执行 reduce E -> E - E 以及后面的 goto 动作时, $$ = $1 - $3 被执行,同时 $1 ~ $3 将出栈, $$ 将入栈,相当于左边的 E 被绑定了右边的两个 E 的值的差;
(5) 当 yyparse 执行 reduce S -> S E \n 以及后面的 goto 动作时, printf(“ans = %dn”, $2) 被执行,于是绑定到 E 的数值被打印出来。
以下为 yyparse 函数的基本解析流程:
(1) 将初始状态 state0 压入栈顶;
(2) 执行 x = yylex() ,有两种情况:
(2.1) x 不是终结符:输入不合语法,执行 deny 操作,调用 yyerror 函数,返回 1;
(2.2) x 是终结符:转到(3);
(3) 置 X = x;
(4) 设栈顶状态为 I ,有以下五种情况:
(4.1) M[I, X] 为 shift I’ 动作:执行 shift I’ 操作:
将 I’ 压入栈顶,将 yylval (可能在(2)中被赋值)压入属性栈,转到(2);
(4.2) M[I, X] 为 goto I’ 动作:执行 goto I’ 操作:
将 I’ 压入栈顶,将 $$ (可能在(4.3)中被赋值)压入属性栈,转到(3);
(4.3) M[I, X] 为 reduce A -> X1 X2 ... Xn :执行 reduce(A, n) 操作,具体步骤为:
(4.3.1) 执行相应产生式 A -> X1 X2 ... Xn 后面的 C 代码;
(4.3.2) 将栈顶及以下 n 个状态出栈,将属性栈顶及以下 n 个属性出栈,置 X = A ;
(4.3.3) 转到(4);
(4.4) M[I, X] 为 ACCEPT :执行 accept 操作,返回 0 ;
(4.5) M[I, X] 为空白:执行 deny 操作,调用 yyerror 函数,返回 1。
以上流程只是基本流程, bison 会对以上流程进行一些优化以加快解析速度,但大体的流程、相关动作执行的先后顺序以及栈的操作方式是和上面描述的一样的。
以上流程中:如果在第(2)步( yylex 函数内、也就是 flex 文件的 action 中)对 yylval 赋值,那么这个值将和 yylex 返回的终结符绑定;如果在第(4.3)步中(也就是 bison 文件的 action 中)对 $$ 进行赋值,那么这个值将和此 action 的产生式的左边的非终结符绑定;而 bison 文件的 action 中,可以用 $1, $2, ..., $n 来引用和此 action 的产生式右边的第 1 ~ n 个符号所绑定的值。
3、bison使用示例
再来看一个稍微复杂一点的示例,一共有 4 个文件:
词法分析文件: scanner.l
%{
#define YYSTYPE char *
#include "y.tab.h"
int cur_line = 1;
void yyerror(const char *msg);
void unrecognized_char(char c);
%}
OPERATOR [-/+*()=;]
INTEGER [0-9]+
IDENTIFIER [_a-zA-Z][_a-zA-Z0-9]*
WHITESPACE [ \t]*
%%
{OPERATOR} { return yytext[0]; }
{INTEGER} { yylval = strdup(yytext); return T_IntConstant; }
{IDENTIFIER} { yylval = strdup(yytext); return T_Identifier; }
{WHITESPACE} { /* ignore every whitespcace */ }
\n { cur_line++; }
. { unrecognized_char(yytext[0]); }
%%
int yywrap(void) {
return 1;
}
void unrecognized_char(char c) {
char buf[32] = "Unrecognized character: ?";
buf[24] = c;
yyerror(buf);
}
void yyerror(const char *msg) {
printf("Error at line %d:\n\t%s\n", cur_line, msg);
exit(1);
}语法分析文件: parser.y
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char*);
#define YYSTYPE char *
%}
%token T_IntConstant T_Identifier
%left '+' '-'
%left '*' '/'
%right U_neg
%%
S : Stmt
| S Stmt
;
Stmt: T_Identifier '=' E ';' { printf("pop %s\n\n", $1); }
;
E : E '+' E { printf("add\n"); }
| E '-' E { printf("sub\n"); }
| E '*' E { printf("mul\n"); }
| E '/' E { printf("div\n"); }
| '-' E %prec U_neg { printf("neg\n"); }
| T_IntConstant { printf("push %s\n", $1); }
| T_Identifier { printf("push %s\n", $1); }
| '(' E ')' { /* empty */ }
;
%%
int main() {
return yyparse();
}makefile 文件: makefile
CC = gcc
OUT = tcc
OBJ = lex.yy.o y.tab.o
SCANNER = scanner.l
PARSER = parser.y
build: $(OUT)
run: $(OUT)
./$(OUT) < test.c > test.asm
clean:
rm -f *.o lex.yy.c y.tab.c y.tab.h y.output $(OUT)
$(OUT): $(OBJ)
$(CC) -o $(OUT) $(OBJ)
lex.yy.c: $(SCANNER) y.tab.c
flex $<
y.tab.c: $(PARSER)
bison -vdty $<测试文件: test.c
a = 1 + 2 * ( 2 + 2 );
b = c + d;
e = f + 7 * 8 / 9;这个示例对第一个示例进行了一些扩充。
词法分析文件中:
增加了 T_Identifier 类型的 token ,整数类型的 token 名改为了 T_IntConstant ;
增加了一个全局变量 cur_line ,表示扫描所在的位置(行);
增加了错误处理函数 unrecognized_char 和 yyerror 函数,前者在扫描到非法字符时被执行,并将相关信息传递给后者,后者则打印出错误信息以及当前位置,并退出程序;
第二行增加了 define YYSTYPE char * ,上一节中说过了,全局变量 yylval 的类型是 YYSTYPE ,而 YYSTYPE 默认为 int ,添加了这一行后, YYSTYPE 变成了 char * ,这样 yylval 的类型就变成了 char * 了;
当扫描到完整的整数或标识符时, yylval = strdup(yytext) 被执行,扫描到的字符串被拷贝一份传给了 yylval ,到语法分析时,这个字符串将被绑定到终结符 T_IntConstant 或 T_Identifier 上面。
语法分析文件中:
语法规则有所扩充,增加了终结符 T_Identifier 和非终结符 Stmt , Stmt 可表示一个赋值表达式;
符号优先级那一段,增加了 %left U_neg ,表示增加一个符号,该符号为左结合,且优先级在 * 和 / 之上,这个符号在 ‘-‘ E %prec U_neg 那一行被使用,%prec 命令可以给一个产生式定义一个优先级,”%prec U_neg” 表示这个产生式的优先级和 U_neg 一样(而不是等于产生式中最右边的、定义了优先级的符号的优先级),当出现 shift/reduce 冲突时,将利用 U_neg 的优先级和 lookahead 的优先级比较,然后根据比较结果来选择动作;
大部分产生式的后面的 action 都是执行一个 printf 函数,表示这些产生式被 reduce 时所打印的字符串。
makefile 里面是编译这个程序的命令,在终端输入 make 后,将编译生成可执行文件 tcc ,然后用 test.c 文件来测试一下:
./tcc < test.c > test.asm
test.asm 文件中的输出内容如下:
push 1
push 2
push 2
push 2
add
mul
add
pop a
push c
push d
add
pop b
push f
push 7
push 8
mul
push 9
div
add
pop e可以看出 test.c 文件里的所有赋值表达式都被转换成相应的 Pcode 了,是不是很神奇?这个程序相当于我们的 TinyC 前端的一个雏形了。在这个雏形前端中请注意源文件的解析过程中各产生式折叠的先后顺序,中间代码就是按照产生式折叠的顺序生成的。
七、TinyC 前端
bison 中一些常用功能的使用方法,bison 是一个非常强大的语法分析工具,读者还可以阅读一下 bison 的文档进行更深入的学习。本章介绍如何利用 flex 和 bison 实现 TinyC 编译器的前端,建议读者先复习一下 手工编译 TinyC ,再来看本章的代码。
1、第 0.1 版
首先对上一章的雏形版本稍微升级一下,增加变量声明和 print 语句,一共有 5 个文件:
词法分析文件: scanner.l
%{
#define YYSTYPE char *
#include "y.tab.h"
int cur_line = 1;
void yyerror(const char *msg);
void unrecognized_char(char c);
#define _DUPTEXT {yylval = strdup(yytext);}
%}
/* note \042 is '"' */
OPERATOR ([-/+*()=,;])
INTEGER ([0-9]+)
STRING (\042[^\042\n]*\042)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
WHITESPACE ([ \t]*)
%%
{OPERATOR} { return yytext[0]; }
"int" { return T_Int; }
"print" { return T_Print; }
{INTEGER} { _DUPTEXT; return T_IntConstant; }
{STRING} { _DUPTEXT; return T_StringConstant; }
{IDENTIFIER} { _DUPTEXT; return T_Identifier; }
{WHITESPACE} { /* ignore every whitespace */ }
\n { cur_line++; }
. { unrecognized_char(yytext[0]); }
%%
int yywrap(void) {
return 1;
}
void unrecognized_char(char c) {
char buf[32] = "Unrecognized character: ?";
buf[24] = c;
yyerror(buf);
}
void yyerror(const char *msg) {
printf("Error at line %d:\n\t%s\n", cur_line, msg);
exit(-1);
}语法分析文件: parser.y
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char*);
#define YYSTYPE char *
%}
%token T_StringConstant T_IntConstant T_Identifier T_Int T_Print
%left '+' '-'
%left '*' '/'
%right U_neg
%%
S:
Stmt { /* empty */ }
| S Stmt { /* empty */ }
;
Stmt:
VarDecl ';' { printf("\n\n"); }
| Assign { /* empty */ }
| Print { /* empty */ }
;
VarDecl:
T_Int T_Identifier { printf("var %s", $2); }
| VarDecl ',' T_Identifier { printf(", %s", $3); }
;
Assign:
T_Identifier '=' E ';' { printf("pop %s\n\n", $1); }
;
Print:
T_Print '(' T_StringConstant Actuals ')' ';'
{ printf("print %s\n\n", $3); }
;
Actuals:
/* empty */ { /* empty */ }
| Actuals ',' E { /* empty */ }
;
E:
E '+' E { printf("add\n"); }
| E '-' E { printf("sub\n"); }
| E '*' E { printf("mul\n"); }
| E '/' E { printf("div\n"); }
| '-' E %prec U_neg { printf("neg\n"); }
| T_IntConstant { printf("push %s\n", $1); }
| T_Identifier { printf("push %s\n", $1); }
| '(' E ')' { /* empty */ }
;
%%
int main() {
return yyparse();
}makefile 文件: makefile
OUT = tcc
TESTFILE = test.c
SCANNER = scanner.l
PARSER = parser.y
CC = gcc
OBJ = lex.yy.o y.tab.o
TESTOUT = $(basename $(TESTFILE)).asm
OUTFILES = lex.yy.c y.tab.c y.tab.h y.output $(OUT)
.PHONY: build test simulate clean
build: $(OUT)
test: $(TESTOUT)
simulate: $(TESTOUT)
python pysim.py $<
clean:
rm -f *.o $(OUTFILES)
$(TESTOUT): $(TESTFILE) $(OUT)
./$(OUT) < $< > $@
$(OUT): $(OBJ)
$(CC) -o $(OUT) $(OBJ)
lex.yy.c: $(SCANNER) y.tab.c
flex $<
y.tab.c: $(PARSER)
bison -vdty $<测试文件: test.c
int a, b, c, d;
a = 1 + 2 * ( 2 + 2 );
c = 5;
d = 10;
b = c + d;
print("a = %d, b = %d, c = %d, d = %d", a, b, c, d);Pcode 模拟器: pysim.py ,已经在第 4 章中介绍了。
这个版本在上一章的雏形版本的基础上,进行了以下扩充:
词法分析文件中:
增加了 T_StringConstant, T_Int, T_Print 类型的 token ,以及相应的正则表达式;
增加了一个 _DUPTEXT 宏,表示 yylval = strdup(yytext) 。
语法分析文件中:
增加了 VarDecl 和 Print 两个非终结符以及相应的产生式。
本版本的语法分析文件中,同样要注意源文件的解析过程中各产生式的折叠顺序以及相应的 Pcode 生成顺序。
makefile 里面是编译和测试这个程序的命令,在终端输入 make 后,将编译生成可执行文件 tcc ,然后输入 make test ,(相当于 ”./tcc < test.c > test.asm” ) ,将输出 test.asm 文件,内容如下:
var a, b, c, d
push 1
push 2
push 2
push 2
add
mul
add
pop a
push 5
pop c
push 10
pop d
push c
push d
add
pop b
push a
push b
push c
push d
print "a = %d, b = %d, c = %d, d = %d"可以看出 test.c 文件里的所有语句都被转换成相应的 Pcode 了。再用 Pcode 模拟器运行一下这些 Pcode ,在终端输入 “make simulate” (相当于 “python pysim.py test.asm” ) ,将输出:
a = 9, b = 5, c = 10, d = 15
2、第 0.5 版
在第 0.1 版的基础上升级,增加函数定义及调用语句、注释等功能,一共有 5 个文件:
词法分析文件: scanner.l
%{
#define YYSTYPE char *
#include "y.tab.h"
int cur_line = 1;
void yyerror(const char *msg);
void unrecognized_char(char c);
void unterminate_string();
#define _DUPTEXT {yylval = strdup(yytext);}
%}
/* note \042 is '"' */
WHITESPACE ([ \t\r\a]+)
SINGLE_COMMENT1 ("//"[^\n]*)
SINGLE_COMMENT2 ("#"[^\n]*)
OPERATOR ([+*-/%=,;!<>(){}])
INTEGER ([0-9]+)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
UNTERM_STRING (\042[^\042\n]*)
STRING (\042[^\042\n]*\042)
%%
\n { cur_line++; }
{WHITESPACE} { /* ignore every whitespace */ }
{SINGLE_COMMENT1} { /* skip for single line comment */ }
{SINGLE_COMMENT2} { /* skip for single line comment */ }
{OPERATOR} { return yytext[0]; }
"int" { return T_Int; }
"void" { return T_Void; }
"return" { return T_Return; }
"print" { return T_Print; }
{INTEGER} { _DUPTEXT return T_IntConstant; }
{STRING} { _DUPTEXT return T_StringConstant; }
{IDENTIFIER} { _DUPTEXT return T_Identifier; }
{UNTERM_STRING} { unterminate_string(); }
. { unrecognized_char(yytext[0]); }
%%
int yywrap(void) {
return 1;
}
void unrecognized_char(char c) {
char buf[32] = "Unrecognized character: ?";
buf[24] = c;
yyerror(buf);
}
void unterminate_string() {
yyerror("Unterminate string constant");
}
void yyerror(const char *msg) {
fprintf(stderr, "Error at line %d:\n\t%s\n", cur_line, msg);
exit(-1);
}语法分析文件: parser.y
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char*);
#define YYSTYPE char *
%}
%token T_Int T_Void T_Return T_Print T_IntConstant
%token T_StringConstant T_Identifier
%left '+' '-'
%left '*' '/'
%right U_neg
%%
Program:
/* empty */ { /* empty */ }
| Program FuncDecl { /* empty */ }
;
FuncDecl:
RetType FuncName '(' Args ')' '{' VarDecls Stmts '}'
{ printf("ENDFUNC\n\n"); }
;
RetType:
T_Int { /* empty */ }
| T_Void { /* empty */ }
;
FuncName:
T_Identifier { printf("FUNC @%s:\n", $1); }
;
Args:
/* empty */ { /* empty */ }
| _Args { printf("\n\n"); }
;
_Args:
T_Int T_Identifier { printf("arg %s", $2); }
| _Args ',' T_Int T_Identifier
{ printf(", %s", $4); }
;
VarDecls:
/* empty */ { /* empty */ }
| VarDecls VarDecl ';' { printf("\n\n"); }
;
VarDecl:
T_Int T_Identifier { printf("var %s", $2); }
| VarDecl ',' T_Identifier
{ printf(", %s", $3); }
;
Stmts:
/* empty */ { /* empty */ }
| Stmts Stmt { /* empty */ }
;
Stmt:
AssignStmt { /* empty */ }
| PrintStmt { /* empty */ }
| CallStmt { /* empty */ }
| ReturnStmt { /* empty */ }
;
AssignStmt:
T_Identifier '=' Expr ';'
{ printf("pop %s\n\n", $1); }
;
PrintStmt:
T_Print '(' T_StringConstant PActuals ')' ';'
{ printf("print %s\n\n", $3); }
;
PActuals:
/* empty */ { /* empty */ }
| PActuals ',' Expr { /* empty */ }
;
CallStmt:
CallExpr ';' { printf("pop\n\n"); }
;
CallExpr:
T_Identifier '(' Actuals ')'
{ printf("$%s\n", $1); }
;
Actuals:
/* empty */ { /* empty */ }
| Expr PActuals { /* empty */ }
;
ReturnStmt:
T_Return Expr ';' { printf("ret ~\n\n"); }
| T_Return ';' { printf("ret\n\n"); }
;
Expr:
Expr '+' Expr { printf("add\n"); }
| Expr '-' Expr { printf("sub\n"); }
| Expr '*' Expr { printf("mul\n"); }
| Expr '/' Expr { printf("div\n"); }
| '-' Expr %prec U_neg { printf("neg\n"); }
| T_IntConstant { printf("push %s\n", $1); }
| T_Identifier { printf("push %s\n", $1); }
| CallExpr { /* empty */ }
| '(' Expr ')' { /* empty */ }
;
%%
int main() {
return yyparse();
}makefile 文件: makefile, 和第 0.1 版本中唯一不同的只有 “python pysim.py $< -a” 那一行有一个 “-a” 。
测试文件: test.c
// tiny c test file
int main() {
int a, b, c, d;
c = 2;
d = c * 2;
a = sum(c, d);
b = sum(a, d);
print("c = %d, d = %d", c, d);
print("a = sum(c, d) = %d, b = sum(a, d) = %d", a, b);
return 0;
}
int sum(int a, int b) {
int c, d;
return a + b;
}Pcode 模拟器: pysim.py ,已经在第 4 章中介绍了。
这个版本在第 0.1 版本的基础上,进行了以下扩充:
词法分析文件中:
增加了 T_Void 和 T_Return 类型的 token ,以及相应的正则表达式;
增加了单行注释的过滤功能;增加了一个错误处理函数: unterminate_string ,该函数可以检查出未结束的字符串(不匹配的双引号)的词法错误。
语法分析文件中:
增加了 Program, FuncDecl, Args, Actuals, CallExpr 等非终结符以及相应的产生式,请注意各产生式的折叠顺序以及相应的 Pcode 生成顺序。
makefile 里面是编译和测试这个程序的命令,内容和第 0.1 版的基本一样,但增加了一些变量以便于扩充,另外,”python pysim.py...” 那一行最后的命令行参数是 “-a” 。在终端输入 make 后,将编译生成可执行文件 tcc ,然后输入 make test ,(相当于 ”./tcc < test.c > test.asm” ) ,将输出 test.asm 文件,内容如下:
FUNC @main:
var a, b, c, d
push 2
pop c
push c
push 2
mul
pop d
push c
push d
$sum
pop a
push a
push d
$sum
pop b
push c
push d
print "c = %d, d = %d"
push a
push b
print "a = sum(c, d) = %d, b = sum(a, d) = %d"
push 0
ret ~
ENDFUNC
FUNC @sum:
arg a, b
var c, d
push a
push b
add
ret ~
ENDFUNC可以看出 test.c 文件里的所有语句都被转换成相应的 Pcode 了。再用 Pcode 模拟器运行一下这些 Pcode ,在终端输入 “make simulate” (相当于 “python pysim.py test.asm -a” ,注意最后有一个 “-a” ) ,将输出:
c = 2, d = 4
a = sum(c, d) = 6, b = sum(a, d) = 10有兴趣的读者还可以使用 “python pysim.py test.asm -da” 来逐句运行一下这个 Pcode 文件。
3、第 1.0 版
继续在第 0.5 版的基础上升级,增加 if 和 while 语句、比较运算符和逻辑运算符以及 readint 命令,就形成了完整的 TinyC 前端。一共有 7 个文件:
词法分析文件: scanner.l
%{
#define YYSTYPE char *
#include "y.tab.h"
int cur_line = 1;
void yyerror(const char *msg);
void unrecognized_char(char c);
void unterminate_string();
#define _DUPTEXT {yylval = strdup(yytext);}
%}
/* note \042 is '"' */
WHITESPACE ([ \t\r\a]+)
SINGLE_COMMENT1 ("//"[^\n]*)
SINGLE_COMMENT2 ("#"[^\n]*)
OPERATOR ([+*-/%=,;!<>(){}])
INTEGER ([0-9]+)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
UNTERM_STRING (\042[^\042\n]*)
STRING (\042[^\042\n]*\042)
%%
\n { cur_line++; }
{WHITESPACE} { /* ignore every whitespace */ }
{SINGLE_COMMENT1} { /* skip for single line comment */ }
{SINGLE_COMMENT2} { /* skip for single line comment */ }
{OPERATOR} { return yytext[0]; }
"int" { return T_Int; }
"void" { return T_Void; }
"return" { return T_Return; }
"print" { return T_Print; }
"readint" { return T_ReadInt; }
"while" { return T_While; }
"if" { return T_If; }
"else" { return T_Else; }
"break" { return T_Break; }
"continue" { return T_Continue; }
"<=" { return T_Le; }
">=" { return T_Ge; }
"==" { return T_Eq; }
"!=" { return T_Ne; }
"&&" { return T_And; }
"||" { return T_Or; }
{INTEGER} { _DUPTEXT return T_IntConstant; }
{STRING} { _DUPTEXT return T_StringConstant; }
{IDENTIFIER} { _DUPTEXT return T_Identifier; }
{UNTERM_STRING} { unterminate_string(); }
. { unrecognized_char(yytext[0]); }
%%
int yywrap(void) {
return 1;
}
void unrecognized_char(char c) {
char buf[32] = "Unrecognized character: ?";
buf[24] = c;
yyerror(buf);
}
void unterminate_string() {
yyerror("Unterminate string constant");
}
void yyerror(const char *msg) {
fprintf(stderr, "Error at line %d:\n\t%s\n", cur_line, msg);
exit(-1);
}语法分析文件: parser.y
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char*);
#define YYSTYPE char *
int ii = 0, itop = -1, istack[100];
int ww = 0, wtop = -1, wstack[100];
#define _BEG_IF {istack[++itop] = ++ii;}
#define _END_IF {itop--;}
#define _i (istack[itop])
#define _BEG_WHILE {wstack[++wtop] = ++ww;}
#define _END_WHILE {wtop--;}
#define _w (wstack[wtop])
%}
%token T_Int T_Void T_Return T_Print T_ReadInt T_While
%token T_If T_Else T_Break T_Continue T_Le T_Ge T_Eq T_Ne
%token T_And T_Or T_IntConstant T_StringConstant T_Identifier
%left '='
%left T_Or
%left T_And
%left T_Eq T_Ne
%left '<' '>' T_Le T_Ge
%left '+' '-'
%left '*' '/' '%'
%left '!'
%%
Program:
/* empty */ { /* empty */ }
| Program FuncDecl { /* empty */ }
;
FuncDecl:
RetType FuncName '(' Args ')' '{' VarDecls Stmts '}'
{ printf("ENDFUNC\n\n"); }
;
RetType:
T_Int { /* empty */ }
| T_Void { /* empty */ }
;
FuncName:
T_Identifier { printf("FUNC @%s:\n", $1); }
;
Args:
/* empty */ { /* empty */ }
| _Args { printf("\n\n"); }
;
_Args:
T_Int T_Identifier { printf("\targ %s", $2); }
| _Args ',' T_Int T_Identifier
{ printf(", %s", $4); }
;
VarDecls:
/* empty */ { /* empty */ }
| VarDecls VarDecl ';' { printf("\n\n"); }
;
VarDecl:
T_Int T_Identifier { printf("\tvar %s", $2); }
| VarDecl ',' T_Identifier
{ printf(", %s", $3); }
;
Stmts:
/* empty */ { /* empty */ }
| Stmts Stmt { /* empty */ }
;
Stmt:
AssignStmt { /* empty */ }
| PrintStmt { /* empty */ }
| CallStmt { /* empty */ }
| ReturnStmt { /* empty */ }
| IfStmt { /* empty */ }
| WhileStmt { /* empty */ }
| BreakStmt { /* empty */ }
| ContinueStmt { /* empty */ }
;
AssignStmt:
T_Identifier '=' Expr ';'
{ printf("\tpop %s\n\n", $1); }
;
PrintStmt:
T_Print '(' T_StringConstant PActuals ')' ';'
{ printf("\tprint %s\n\n", $3); }
;
PActuals:
/* empty */ { /* empty */ }
| PActuals ',' Expr { /* empty */ }
;
CallStmt:
CallExpr ';' { printf("\tpop\n\n"); }
;
CallExpr:
T_Identifier '(' Actuals ')'
{ printf("\t$%s\n", $1); }
;
Actuals:
/* empty */ { /* empty */ }
| Expr PActuals { /* empty */ }
;
ReturnStmt:
T_Return Expr ';' { printf("\tret ~\n\n"); }
| T_Return ';' { printf("\tret\n\n"); }
;
IfStmt:
If TestExpr Then StmtsBlock EndThen EndIf
{ /* empty */ }
| If TestExpr Then StmtsBlock EndThen Else StmtsBlock EndIf
{ /* empty */ }
;
TestExpr:
'(' Expr ')' { /* empty */ }
;
StmtsBlock:
'{' Stmts '}' { /* empty */ }
;
If:
T_If { _BEG_IF; printf("_begIf_%d:\n", _i); }
;
Then:
/* empty */ { printf("\tjz _elIf_%d\n", _i); }
;
EndThen:
/* empty */ { printf("\tjmp _endIf_%d\n_elIf_%d:\n", _i, _i); }
;
Else:
T_Else { /* empty */ }
;
EndIf:
/* empty */ { printf("_endIf_%d:\n\n", _i); _END_IF; }
;
WhileStmt:
While TestExpr Do StmtsBlock EndWhile
{ /* empty */ }
;
While:
T_While { _BEG_WHILE; printf("_begWhile_%d:\n", _w); }
;
Do:
/* empty */ { printf("\tjz _endWhile_%d\n", _w); }
;
EndWhile:
/* empty */ { printf("\tjmp _begWhile_%d\n_endWhile_%d:\n\n",
_w, _w); _END_WHILE; }
;
BreakStmt:
T_Break ';' { printf("\tjmp _endWhile_%d\n", _w); }
;
ContinueStmt:
T_Continue ';' { printf("\tjmp _begWhile_%d\n", _w); }
;
Expr:
Expr '+' Expr { printf("\tadd\n"); }
| Expr '-' Expr { printf("\tsub\n"); }
| Expr '*' Expr { printf("\tmul\n"); }
| Expr '/' Expr { printf("\tdiv\n"); }
| Expr '%' Expr { printf("\tmod\n"); }
| Expr '>' Expr { printf("\tcmpgt\n"); }
| Expr '<' Expr { printf("\tcmplt\n"); }
| Expr T_Ge Expr { printf("\tcmpge\n"); }
| Expr T_Le Expr { printf("\tcmple\n"); }
| Expr T_Eq Expr { printf("\tcmpeq\n"); }
| Expr T_Ne Expr { printf("\tcmpne\n"); }
| Expr T_Or Expr { printf("\tor\n"); }
| Expr T_And Expr { printf("\tand\n"); }
| '-' Expr %prec '!' { printf("\tneg\n"); }
| '!' Expr { printf("\tnot\n"); }
| T_IntConstant { printf("\tpush %s\n", $1); }
| T_Identifier { printf("\tpush %s\n", $1); }
| ReadInt { /* empty */ }
| CallExpr { /* empty */ }
| '(' Expr ')' { /* empty */ }
;
ReadInt:
T_ReadInt '(' T_StringConstant ')'
{ printf("\treadint %s\n", $3); }
;
%%
int main() {
return yyparse();
}makefile 文件: makefile ,内容和 第 0.5 版是一样的。
测试文件: test.c ,就是第二章的的示例源程序。
#include "for_gcc_build.hh" // only for gcc, TinyC will ignore it.
int main() {
int i;
i = 0;
while (i < 10) {
i = i + 1;
if (i == 3 || i == 5) {
continue;
}
if (i == 8) {
break;
}
print("%d! = %d", i, factor(i));
}
return 0;
}
int factor(int n) {
if (n < 2) {
return 1;
}
return n * factor(n - 1);
}测试文件包:samples.zip ,包含了 7 个测试文件。
测试脚本: test_samples.sh 。
Pcode 模拟器: pysim.py 。
这个版本在第 0.1 版本的基础上,进行了以下扩充:
词法分析文件中:
增加了 T_Void 和 T_Return 类型的 token ,以及相应的正则表达式。
语法分析文件中:
增加了 IfStmt, WhileStmt, BreakStmt, ContinueStmt, ReadInt 等非终结符以及相应的产生式,请注意各产生式的折叠顺序以及相应的 Pcode 生成顺序;
增加了比较运算符、逻辑运算符,以及相应的优先级;
在 Declarations 段,增加了几个全局变量和宏:
int ii = 0, itop = -1, istack[100];
int ww = 0, wtop = -1, wstack[100];
#define _BEG_IF {istack[++itop] = ++ii;}
#define _END_IF {itop--;}
#define _i (istack[itop])
#define _BEG_WHILE {wstack[++wtop] = ++ww;}
#define _END_WHILE {wtop--;}
#define _w (wstack[wtop])这些全局变量和宏配合后面的 if/while 语句产生式中的 action 使用,是该文件中的最精妙的部分,它们的作用是:在生成 if 和 while 语句块的 Pcode 的过程中,给相应的 Label 进行编号。它们给每个 if 语句块和每个 while 语句块一个唯一的编号,使不同的 if/while 语句块的 jmp 不相互冲突。其中 _i 永远是当前的 if 语句块的编号, _w 永远是当前的 while 语句块的编号; ii/ww 永远是目前解析到的 if/while 语句块的总数。
将以上所有文件都放在当前目录,在终端直接输入 make test ,将自动编译生成 TinyC 前端: tcc ,并自动调用 tcc 将 test.c 编译成 test.asm 文件,内容如下,和第 5 章的手工编译的结果差不多吧:
FUNC @main:
var i
push 0
pop i
_begWhile_1:
push i
push 10
cmplt
jz _endWhile_1
push i
push 1
add
pop i
_begIf_1:
push i
push 3
cmpeq
push i
push 5
cmpeq
or
jz _elIf_1
jmp _begWhile_1
jmp _endIf_1
_elIf_1:
_endIf_1:
_begIf_2:
push i
push 8
cmpeq
jz _elIf_2
jmp _endWhile_1
jmp _endIf_2
_elIf_2:
_endIf_2:
push i
push i
$factor
print "%d! = %d"
jmp _begWhile_1
_endWhile_1:
push 0
ret ~
ENDFUNC
FUNC @factor:
arg n
_begIf_3:
push n
push 2
cmplt
jz _elIf_3
push 1
ret ~
jmp _endIf_3
_elIf_3:
_endIf_3:
push n
push n
push 1
sub
$factor
mul
ret ~
ENDFUNC再输入 “make simulate”,将输出:
1! = 1
2! = 2
4! = 24
6! = 720
7! = 5040和第二章中用 gcc 编译并运行此文件的结果完全一样。
再把测试文件包里的所有源文件全部测试一遍,将 samples.zip 解压到 samples 目录下,测试脚本 test_samples.sh 将分别调用 tcc 和 gcc 编译测试文件包中的每一个文件,并分别使用 pysim.py 和 操作系统 运行编译得到的目标文件,内容如下:
for src in $(ls samples/*.c)
do
clear
file=${src%%.c}
echo build with tcc
./tcc < $file.c > $file.asm
python pysim.py $file.asm -a
echo
echo build with gcc
gcc -o $file $file.c
./$file
echo
echo press any key to continue...
read -n 1
done在终端输入 bash ./test_samples.sh ,将分别输出一系列的结果,典型输出如下,可以看到 gcc 和 tcc 编译运行的结果完全一致。
build with tcc, the output are:
The first 10 number of the fibonacci sequence:
fib(1)=1
fib(2)=1
fib(3)=2
fib(4)=3
fib(5)=5
fib(6)=8
fib(7)=13
fib(8)=21
fib(9)=34
fib(10)=55
build with gcc, the output are:
The first 10 number of the fibonacci sequence:
fib(1)=1
fib(2)=1
fib(3)=2
fib(4)=3
fib(5)=5
fib(6)=8
fib(7)=13
fib(8)=21
fib(9)=34
fib(10)=55至此 TinyC 前端完成。
八、TinyC 后端
至此我们的 TinyC 前端已经完成,可以将 TinyC 源程序编译成中间代码 Pcode ,且可以用 Pcode 模拟器来运行 TinyC 前端生成的 Pcode 。接下来编写 TinyC 后端,将中间代码编译、链接成可执行源程序。我们将针对所有 Pcode 命令编写同名的 NASM 宏将 Pcode 翻译成 x86(32位) 汇编指令,然后利用 Nasm 汇编成二进制目标程序,最后用链接器 ld 链接成 Linux 下的 32 位可执行程序。
1、安装NASM
第一步:先判断系统是否已经安装了nasm
打开终端,执行whereis nasm ;如果显示nasm: /usr/bin/nasm ,则已经安装;如果只显示nasm: ,则未安装。
第二步:下载资源
去官网或者谷歌下载最新版本的源码编译http://www.nasm.us/,如nasm-X.XX. ta .gz,X.XX.是版本号。
第三步:开始安装
首先将下载得到的压缩包,解压:tar xzvf nasm-X.XX. ta .gz 。
然后cd nasm-X. XX 并且 输入 ./configure {configure脚本会寻找最合适的C编译器,并生成相应的makefile文件}。
接着输入make 创建nasm和ndisasm 的二进制代码。
最后输入make install 进行安装(这一步需要root权限)。
make install会将 nasm 和ndisasm 装进/usr/local/bin 并安装相应的man pages。
如果想验证是否安装成功的话,输入whereis nasm(见第一步)
2、NASM 简介
NASM 全称 The Netwide Assembler ,是一款基于 x86 平台的汇编语言编译程序,其设计初衷是为了实现编译器程序跨平台和模块化的特性。 NASM 支持大量的文件格式,包括 Linux , BSD , a.out , ELF , COFF , Mach−O , Microsoft 16−bit OBJ , Win32 以及 Win64 ,同时也支持简单的二进制文件生成。它的语法被设计的简单易懂,相较 Intel 的语法更为简单,支持目前已知的所有 x86 架构之上的扩展语法,同时也拥有对宏命令的良好支持。
用 NASM 编写 Linux 下的 hello world 示例程序 hello.nasm 如下:
GLOBAL _start
[SECTION .TEXT]
_start:
MOV EAX, 4 ; write
MOV EBX, 1 ; stdout
MOV ECX, msg
MOV EDX, len
INT 0x80 ; write(stdout, msg, len)
MOV EAX, 1 ; exit
MOV EBX, 0
INT 0x80 ; exit(0)
[SECTION .DATA]
msg: DB "Hello, world!", 10
len: EQU $-msg编译和运行的命令如下( Debian-8.4-amd64 环境下):
$ nasm -f elf32 -o hello.o hello.nasm
$ ld -m elf_i386 -o hello hello.o
$ ./hello
Hello, world!Linux 32位可执行程序中,用 “INT 0x80” 指令来执行一个系统调用,用 “EAX” 指定系统调用编号,用 “EBX, ECX, EDX” 来传递系统调用需要的参数。上面这段汇编代码中,首先执行了编号为 4 的系统调用(write),向 stdout 写了一个长为 len 的字符串(msg),之后,执行编号为 1 的系统调用(exit)。
NASM 拥有对宏命令的良好支持,可以简化很多重复代码的编写。对于上面这个程序,可以编写两个名为 print 和 exit 的宏用来重复使用。新建一个 macro.inc 文件,内容如下:
%MACRO print 1
[SECTION .DATA]
%%STRING: DB %1, 10
%%LEN: EQU $-%%STRING
[SECTION .TEXT]
MOV EAX, 4 ; write
MOV EBX, 1 ; stdout
MOV ECX, %%STRING
MOV EDX, %%LEN
INT 0x80 ; write(stdout, %%STRING, %%LEN)
%ENDMACRO
%MACRO exit 1
MOV EAX, 1
MOV EBX, %1
INT 0x80
%ENDMACRO
GLOBAL _start
[SECTION .TEXT]
_start:新的 hello.nasm 如下:
%include "macro.inc"
print "Hello world!"
print "Hello again!"
exit 0后面这段代码够简洁吧。
上面这段代码中的 %include 命令和 C 语言中的 #inlucde 的作用是一样的,就是把 %include 后面的文件名对应的文件的内容原样的拷贝进来。
下面再来解释一下 NASM 宏的使用。首先看简单一点的 exit 宏。 NASM 中: %MACRO 是宏定义的开始; %MACRO 后面接宏的名称;此处是 “exit” ;宏名后面是宏的参数数量,此处是 “1” ,表示该宏带有一个参数,宏内部中可以用 “%1, %2, %3, ...” 来引用宏的第 1 、 2 、 3 、 ... 个参数; %ENDMACRO 是宏定义的结束。
宏定义好后,若后面的代码中遇到这个宏,则会用宏定义中的内容来替换这个宏。如 hello.nasm 中的 第 5 行 “exit 0”,会被替换成:
MOV EAX, 1
MOV EBX, 0
INT 0x80注意宏定义中的 %1 将被替换为 exit 后面的参数 0。
print 宏定义稍微复杂一点,多了 %%STRING 和 %%LEN ,它们可以看成是宏定义中的局部名称,在每个 print 宏被展开的时候, NASM 会为这种类型的名称生成一个唯一的标志符。我们可以用 nasm -e hello.nasm 来查看 hello.nasm 文件经过预处理后的代码,如下(以下代码经过的适当的缩进和注释处理):
[global _start]
[SECTION .TEXT]
_start:
; print "Hello world!"
[SECTION .DATA]
..@1.STRING: DB "Hello world!", 10
..@1.LEN: EQU $-..@1.STRING
[SECTION .TEXT]
MOV EAX, 4
MOV EBX, 1
MOV ECX, ..@1.STRING
MOV EDX, ..@1.LEN
INT 0x80
; print "Hello again"
[SECTION .DATA]
..@2.STRING: DB "Hello again!", 10
..@2.LEN: EQU $-..@2.STRING
[SECTION .TEXT]
MOV EAX, 4
MOV EBX, 1
MOV ECX, ..@2.STRING
MOV EDX, ..@2.LEN
INT 0x80
; exit 0
MOV EAX, 1
MOV EBX, 0
INT 0x80可以看到,在 ‘print “Hello world!”’ 宏中, %%STRING 被展开为 ..@1.STRING ,而在 ‘print “Hello again!”’ 宏中, %%STRING 被展开为 ..@2.STRING 。
2、用 NASM 宏将 Pcode 命令翻译成 x86 指令 ( print 命令)
上面简单介绍了 NASM 以及它的强大的宏命令,可以实现复杂多样的宏展开。从本节开始,将编写一系列的宏定义,将中间代码 Pcode 命令展开为 x86 汇编指令。建议读者先回顾一下第 3、4 章的内容,再来看本章接下来的内容。
在开始编写宏定义之前,首先说明一下两个约定: (1) 所有 Pcode 命令以及相应的宏名称都小写( FUNC / ENDFUNC 命令除外),而所有 x86 汇编指令都大写; (2) 本书中的 x86 汇编指令,均用 NASM 语法书写。
首先翻译 Pcode 命令中的 print 命令。上一节中定义的 print 宏已经和 Pcode 中的 print 命令在使用的格式上是一模一样的了,但是它还不能实现 %d 格式化输出。我们最终的 print 宏需要使下面这段代码( print.nasm )的输出为 “a = 1, b = 2, c = 3” :
PUSH DWORD 1
PUSH DWORD 2
PUSH DWORD 3
print "a = %d, b = %d, c = %d"
exit 0直接看代码吧。宏文件 macro.inc :
%MACRO print 1
[SECTION .DATA]
%%STRING: DB %1, 10, 0
[SECTION .TEXT]
PUSH DWORD %%STRING
CALL PRINT
SHL EAX, 2
ADD ESP, EAX
%ENDMACRO
%MACRO exit 1
MOV EAX, 1
MOV EBX, %1
INT 0x80
%ENDMACRO
EXTERN PRINT
GLOBAL _start
[SECTION .TEXT]
_start:从宏文件可以看出, print 宏将会被展开为一个 PUSH 命令,一个函数调用命令(CALL PRINT),以及清栈的命令。具体的输出工作将由 PRINT 函数来处理,同时 PRINT 函数还需要返回字符串中含有的 %d 的个数,这样函数调用完毕后可以根据返回值(保存在 EAX 中)来进行清栈(这就是 “SHL EAX, 2” 和 “ADD ESP, EAX” 的作用)。
PRINT 函数可以用 C 语言来编写,然后编译成库文件,最后和目标文件一起链接成可执行文件。PRINT 函数源代码如下( tio.c ):
void SYS_PRINT(char *string, int len);
#define BUFLEN 1024
int PRINT(char *fmt, ...)
{
int *args = (int*)&fmt;
char buf[BUFLEN];
char *p1 = fmt, *p2 = buf + BUFLEN;
int len = -1, argc = 1;
while (*p1++) ;
do {
p1--;
if (*p1 == '%' && *(p1+1) == 'd') {
p2++; len--; argc++;
int num = *(++args), negative = 0;
if (num < 0) {
negative = 1;
num = -num;
}
do {
*(--p2) = num % 10 + '0'; len++;
num /= 10;
} while (num);
if (negative) {
*(--p2) = '-'; len++;
}
} else {
*(--p2) = *p1; len++;
}
} while (p1 != fmt);
SYS_PRINT(p2, len);
return argc;
}
void SYS_PRINT(char *string, int len)
{
__asm__(
".intel_syntax noprefix\n\
PUSH EAX\n\
PUSH EBX\n\
PUSH ECX\n\
PUSH EDX\n\
\n\
MOV EAX, 4\n\
MOV EBX, 1\n\
MOV ECX, [EBP+4*2]\n\
MOV EDX, [EBP+4*3]\n\
INT 0X80\n\
\n\
POP EDX\n\
POP ECX\n\
POP EBX\n\
POP EAX\n\
.att_syntax"
);
}用以下命令将 tio.c 编译成库文件 libtio.a 。
gcc -m32 -c -o tio.o tio.c
ar -crv libtio.a tio.o再将 print.nasm 汇编成目标文件 print.o 。
nasm -f elf32 -P"macro.inc" -o print.o print.nasm
最后将 print.o 链接为可执行文件 print ,链接时指定 tio 库(库文件为 libtio.a ),命令如下:
ld -m elf_i386 -o print print.o -L. -ltio
运行 print 将输出 “a = 1, b = 2, c = 3” 。
以上文件中, print.nasm 中的 CALL PRINT (由 print 宏展开得到)将调用定义在 tio.c 中的 PRINT 函数。在 Linux(32位) 的汇编编程中,如果一个文件需要调用由外部文件定义的函数,那么需要遵循以下约定:
(1) 本文件中需有 EXTERN funcname ,表示需要引用外部函数(函数名为 funcname );
(2) 函数的参数通过栈传递,且按从右向左的顺序入栈,函数的第一个参数要最后一个入栈;
(3) 函数开头的汇编指令为 “PUSH EBP; MOV EBP, ESP” , 函数结尾的汇编指令为 “MOV ESP, EBP; POP EBP; RET” ,因此,在函数体内,第一个参数保存在 EBP+8 处,第二个参数保存在 EBP+12 ,第三个参数保存在 EBP+16 ,以此类推, ... 。
(4) 入栈的参数由调用者负责出栈。
下面结合这四个约定来详细的说明一下 print 宏是如何模拟出 Pcode 中 print 命令的效果的:
(1) 首先,在 macro.inc 中定义了 print 宏,因此 print.nasm 中的代码:
PUSH DWORD 1
PUSH DWORD 2
PUSH DWORD 3
print "a = %d, b = %d, c = %d"将会被展开为下面的形式:
[SECTION .TEXT]
PUSH DWORD 1
PUSH DWORD 2
PUSH DWORD 3
PUSH DWORD %%STRING
CALL PRINT
SHL EAX, 2
ADD ESP, EAX
[SECTION .DATA]
%%STRING: DB "a = %d, b = %d, c = %d", 10, 0(2) 以上代码中的 “CALL PRINT” 将调用定义在 tio.c 中的 PRINT 函数,该函数原型为 int PRINT(char *fmt, ...) ,其中第一个参数 fmt 就是最后一个入栈的参数,也就是字符串 “a = %d, b = %d, c = %d\n\0” 的起始地址。
(3) PRINT 函数中的第一行 int *args = (int*)&fmt 得到 fmt 的地址(注意:不是 fmt 的值),因此, args+1 就是倒数第二个入栈的参数的地址, *(args+1) 就是该参数的值(此处为 3 ), *(args+2) 就是倒数第三个入栈的参数的值(此处为 2 ), ... 。
(4) PRINT 函数首先找到字符串 fmt 的结尾,然后从结尾一直向前扫描该字符串,如果扫描到普通字符,则直接拷贝到 buf 数组中,如果扫描到一个 “%d” ,则执行 num = *(++args) 得到相应的参数的数值,然后将此数值转换为字符串并拷贝到 buf 数组中,按此原则一直扫描到字符串的开头,最后将 buf 数组中的内容打印到终端。
(5) 打印完毕后,PRINT 函数返回 fmt 中含有的 “%d” 的个数(保存在 EAX 中),因此, “CALL PRINT” 后面的 “SHL EAX, 2” 和 “ADD ESP, EAX” 会将所有的入栈的参数都出栈。
3、翻译 Pcode 中的 readint 命令
readint 命令的翻译和 print 命令的翻译方法差不多,也需要利用 C 语言编写库函数。以下为相关的代码:
测试代码 test.nasm :
readint "Please input an number: "
print "Your input is: %d"
exit 0readint 宏,在 macro.inc 文件中:
%MACRO readint 1
[SECTION .DATA]
%%STRING: DB %1, 0
[SECTION .TEXT]
PUSH DWORD %%STRING
CALL READINT
MOV [ESP], EAX
%ENDMACRO
EXTERN PRINT, READINTREADINT 库函数,在 tio.c 文件中:
int STRLEN(char *s);
int SYS_READ(char *buf, int len);
int READINT(char *prompt) {
char buf[BUFLEN], *p = buf, *p_end;
SYS_PRINT(prompt, STRLEN(prompt));
int len = SYS_READ(buf, BUFLEN-1), value = 0, negative = 0;
p_end = buf + len + 1;
while (p != p_end) {
if (*p == ' ' || *p == '\t') {
p++;
} else {
break;
}
}
if (p != p_end && *p == '-') {
negative = 1;
p++;
}
while (p != p_end) {
if (*p <= '9' && *p >= '0') {
value = value * 10 + *p - '0';
*p++;
} else {
break;
}
}
if (negative) {
value = -value;
}
return value;
}
int STRLEN(char *s) {
int i = 0;
while(*s++) i++;
return i;
}
int SYS_READ(char *buf, int len) {
__asm__(
".intel_syntax noprefix\n\
PUSH EBX\n\
PUSH ECX\n\
PUSH EDX\n\
\n\
MOV EAX, 3\n\
MOV EBX, 2\n\
MOV ECX, [EBP+4*2]\n\
MOV EDX, [EBP+4*3]\n\
INT 0X80\n\
\n\
POP EDX\n\
POP ECX\n\
POP EBX\n\
.att_syntax"
);
}makefile 文件:
test: test.o libtio.a
ld -m elf_i386 -o test test.o -L. -ltio
run: test
./test
test.o: test.nasm macro.inc
nasm -f elf32 -P"macro.inc" -o test.o test.nasm
libtio.a: tio.c
gcc -m32 -c -o tio.o tio.c
ar -crv libtio.a tio.o
clean:
rm test.o test tio.o libtio.a将以上四个文件下载下来放到用一个目录,输入 make run 即可编译并运行测试代码。运行过程如下:
$ make run
...
./test
Please input an number: 15
Your input is: 154、翻译 Pcode 中的算术命令、 push/pop 命令以及 jmp/jz 命令
算术命令(add / sub / mul / div / mod / cmpeq / cmpne / cmpgt / cmplt / cmpge / cmple / and / or / not / neg 命令)、 push/pop 命令以及 jmp/jz 命令的操作很简单,因此将其翻译成 x86 指令也很简单,结合第 3 、 4 章中介绍的这些命令对栈的操作步骤,典型的宏定义如下:
%MACRO add 0
POP EAX
ADD DWORD [ESP], EAX
%ENDMACRO
%MACRO sub 0
POP EAX
SUB DWORD [ESP], EAX
%ENDMACRO
%MACRO cmpeq 0
MOV EAX, [ESP+4]
CMP EAX, [ESP]
PUSHF
POP EAX
SHR EAX, 6
AND EAX, 0X1
ADD ESP, 4
MOV [ESP], EAX
%ENDMACRO
%MACRO not 0
MOV EAX, [ESP]
OR EAX, EAX
PUSHF
POP EAX
SHR EAX, 6
AND EAX, 0X1
MOV [ESP], EAX
%ENDMACRO
%MACRO jz 1
POP EAX
OR EAX, EAX
JZ %1
%ENDMACRO
%MACRO jmp 1
JMP %1
%ENDMACRO
%MACRO push 1
PUSH DWORD %1
%ENDMACRO
%MACRO pop 0-1
%IFIDN %0, 0
ADD ESP, 4
%ELSE
POP DWORD %1
%ENDIF
%ENDMACRO所有宏定义见 macro.inc 。
测试文件 test.nasm :
MOV EBP, ESP
SUB ESP, 8
%define a [EBP-4]
%define b [EBP-8]
; a = readint("Please input an number `a`: ")
readint "Please input an number `a`: "
pop a ; ==> POP DWORD [EBP-4]
; b = readint("Please input another number `b`: ")
readint "Please input another number `b`: "
pop b ; ==> POP DWORD [EBP-8]
; print("a = %d", a)
push a ; ==> PUSH DWORD [EBP-4]
print "a = %d"
; print("b = %d", b)
push b ; ==> PUSH DWORD [EBP-8]
print "b = %d"
; print("a - b = %d", a - b)
push a
push b
sub
print "a - b = %d"
; if (a > b) { print("a > b"); } else { print("a <= b") }
push a
push b
cmpgt
jz _LESSEQUAL
print "a > b"
jmp _EXIT
_LESSEQUAL:
print "a <= b"
_EXIT:
exit 05、翻译 Pcode 中的自定义函数命令和变量声明命令
上一节我们已经实现了将简单 TinyC 语句手工翻译成 Pcode ,然后编写了 NASM 宏将这些 Pcode 翻译成 x86 指令,最后汇编、链接成可执行程序。我们已经编写了大部分 Pcode 命令所对应的宏,本节将编写 NASM 宏来翻译 Pcode 中最复杂、也是最难翻译的命令–自定义函数命令和变量声明命令(FUNC / ENDFUNC / arg / ret / $func_name / var)。
具体来说,我们需要将以下 Pcode 翻译成 x86 指令:
; int main() {
FUNC @main:
; int a;
var a
; a = 3;
push 3
pop a
; print("sum = %d", sum(4, a));
push 4
push a
$sum
print "sum = %d"
; return 0;
ret 0
; }
ENDFUNC
; int sum(int a, int b) {
FUNC @sum:
arg a, b
; int c;
var c
; c = a + b;
push a
push b
add
pop c
; return c;
ret c
; }
ENDFUNC最难的部分在于如何避免不同函数中的同名变量的冲突。 NASM 的宏虽然强大,但无法满足如此复杂的需要。为降低翻译的难度,将以上 Pcode 稍微改写一下,保存为 test.pcode :
; int main() {
FUNC @main:
; int a;
main.var a
; a = 3;
push 3
pop a
; print("sum = %d", sum(4, a));
push 4
push a
$sum
print "sum = %d"
; return 0;
ret 0
; }
ENDFUNC@main
; int sum(int a, int b) {
FUNC @sum:
sum.arg a, b
; int c;
sum.var c
; c = a + b;
push a
push b
add
pop c
; return c;
ret c
; }
ENDFUNC@sum首先编写 FUNC 和 ret 宏,放到 macro.inc 文件中,同时在该文件的最后增加调用 @main 函数及退出的指令:
%MACRO FUNC 1
%1
PUSH EBP
MOV EBP, ESP
%ENDMACRO
%MACRO ret 0-1
%IFIDN %0, 1
%IFIDN %1, ~
MOV EAX, [ESP]
%ELSE
MOV EAX, %1
%ENDIF
%ENDIF
LEAVE
RET
%ENDMACRO
EXTERN PRINT, READINT
GLOBAL _start
[SECTION .TEXT]
_start:
CALL @main
PUSH EAX
exit [ESP]然后,编写 main.var, ENDFUNC@main, $sum, sum.arg, sum.var 和 ENDFUNC@sum 宏,保存为 test.funcmacro :
; ==== begin function `main` ====
%define main.varc 1
%MACRO main.var main.varc
%define a [EBP - 4*1]
SUB ESP, 4*main.varc
%ENDMACRO
%MACRO ENDFUNC@main 0
LEAVE
RET
%undef a
%ENDMACRO
; ==== end function `main` ====
; ==== begin function `sum` ====
%define sum.argc 2
%define sum.varc 1
%MACRO $sum 0
CALL @sum
ADD ESP, 4*sum.argc
PUSH EAX
%ENDMACRO
%MACRO sum.arg sum.argc
%define a [EBP + 8 + 4*sum.argc - 4*1]
%define b [EBP + 8 + 4*sum.argc - 4*2]
%ENDMACRO
%MACRO sum.var sum.varc
%define c [EBP - 4*1]
SUB ESP, 4*sum.varc
%ENDMACRO
%MACRO ENDFUNC@sum 0
LEAVE
RET
%undef a
%undef b
%undef c
%ENDMACRO
; ==== end function `sum` ====这些宏会将 @sum 函数展开为如下形式:
@sum:
PUSH EBP
MOV EBP, ESP
SUB ESP, 4*1
PUSH DWORD [EBP + 12] ; push a
PUSH DWORD [EBP + 8] ; push b
add
POP DWORD [EBP - 4*1] ; pop c
MOV EAX, [EBP - 4*1] ; MOV EAX, c
LEAVE
RET最后,改写 makefile 文件中的以下两行:
test.o: test.pcode test.funcmacro macro.inc
nasm -f elf32 -P"macro.inc" -P"test.funcmacro" -o test.o test.pcode将以上四个文件以及库函数文件 tio.c 放到用一个目录,输入 make run 即可编译并运行测试代码。
至此所有 Pcode 命令对应的 NASM 宏编写完毕。
九、TinyC 编译器
1、改进 TinyC 前端
上一章的 TinyC 后端中,为了降低 Pcode 命令的翻译难度,对 arg / var / ENDFUNC 命令的格式进行了改写,因此需要改进 TinyC 前端,使之能生成能被 TinyC 后端所识别的新格式 Pcode 命令。具体来说,对于下面这段源程序 test.c :
int main() {
int a;
a = 3;
print("sum = %d", sum(4, a));
return 0;
}
int sum(int a, int b) {
int c;
c = a + b;
return c;
}改进后 TinyC 前端需要生成一个 Pcode 文件 test.pcode :
FUNC @main:
main.var a
push 3
pop a
push 4
push a
$sum
print "sum = %d"
ret 0
ENDFUNC@main
FUNC @sum:
sum.arg a, b
sum.var c
push a
push b
add
pop c
ret c
ENDFUNC@sum以及一个宏文件 test.funcmacro :
; ==== begin function `main` ====
%define main.varc 1
%MACRO main.var main.varc
%define a [EBP - 4*1]
SUB ESP, 4*main.varc
%ENDMACRO
%MACRO ENDFUNC@main 0
LEAVE
RET
%undef a
%ENDMACRO
; ==== end function `main` ====
; ==== begin function `sum` ====
%define sum.argc 2
%define sum.varc 1
%MACRO $sum 0
CALL @sum
ADD ESP, 4*sum.argc
PUSH EAX
%ENDMACRO
%MACRO sum.arg sum.argc
%define a [EBP + 8 + 4*sum.argc - 4*1]
%define b [EBP + 8 + 4*sum.argc - 4*2]
%ENDMACRO
%MACRO sum.var sum.varc
%define c [EBP - 4*1]
SUB ESP, 4*sum.varc
%ENDMACRO
%MACRO ENDFUNC@sum 0
LEAVE
RET
%undef a
%undef b
%undef c
%ENDMACRO
; ==== end function `sum` ====在TinyC 前端 1.0 版的 parser.y 的基础上,针对函数定义、参数定义以及变量定义的语句进行改写,改进后的语法分析文件 parser.y :
%{
#include <stdio.h>
#include <stdarg.h>
#include <string.h>
#include <stdlib.h>
void init_parser(int argc, char *argv[]);
void quit_parser();
extern FILE* yyin;
FILE *asmfile, *incfile;
#define BUFSIZE 256
#define out_asm(fmt, ...) \
{fprintf(asmfile, fmt, ##__VA_ARGS__); fprintf(asmfile, "\n");}
#define out_inc(fmt, ...) \
{fprintf(incfile, fmt, ##__VA_ARGS__); fprintf(incfile, "\n");}
void file_error(char *msg);
int ii = 0, itop = -1, istack[100];
int ww = 0, wtop = -1, wstack[100];
#define _BEG_IF (istack[++itop] = ++ii)
#define _END_IF (itop--)
#define _i (istack[itop])
#define _BEG_WHILE (wstack[++wtop] = ++ww)
#define _END_WHILE (wtop--)
#define _w (wstack[wtop])
int argc = 0, varc = 0;
char *cur_func_name, *args[128], *vars[128];
void write_func_head();
void write_func_tail();
#define _BEG_FUNCDEF(name) (cur_func_name = (name))
#define _APPEND_ARG(arg) (args[argc++] = (arg))
#define _APPEND_VAR(var) (vars[varc++] = (var))
#define _WRITE_FUNCHEAD write_func_head
#define _END_FUNCDEF write_func_tail
#define YYSTYPE char *
%}
%token T_Void T_Int T_While T_If T_Else T_Return T_Break T_Continue
%token T_Print T_ReadInt T_Le T_Ge T_Eq T_Ne T_And T_Or
%token T_IntConstant T_StringConstant T_Identifier
%left '='
%left T_Or
%left T_And
%left T_Eq T_Ne
%left '<' '>' T_Le T_Ge
%left '+' '-'
%left '*' '/' '%'
%left '!'
%%
Start:
Program { /* empty */ }
;
Program:
/* empty */ { /* empty */ }
| Program FuncDef { /* empty */ }
;
FuncDef:
T_Int FuncName Args Vars Stmts EndFuncDef
| T_Void FuncName Args Vars Stmts EndFuncDef
;
FuncName:
T_Identifier { _BEG_FUNCDEF($1); }
;
Args:
'(' ')' { /* empty */ }
| '(' _Args ')' { /* empty */ }
;
_Args:
T_Int T_Identifier { _APPEND_ARG($2); }
| _Args ',' T_Int T_Identifier { _APPEND_ARG($4); }
;
Vars:
_Vars { _WRITE_FUNCHEAD(); }
;
_Vars:
'{' { /* empty */ }
| _Vars Var ';' { /* empty */ }
;
Var:
T_Int T_Identifier { _APPEND_VAR($2); }
| Var ',' T_Identifier { _APPEND_VAR($3); }
;
Stmts:
/* empty */ { /* empty */ }
| Stmts Stmt { /* empty */ }
;
EndFuncDef:
'}' { _END_FUNCDEF(); }
;
Stmt:
AssignStmt { /* empty */ }
| CallStmt { /* empty */ }
| IfStmt { /* empty */ }
| WhileStmt { /* empty */ }
| BreakStmt { /* empty */ }
| ContinueStmt { /* empty */ }
| ReturnStmt { /* empty */ }
| PrintStmt { /* empty */ }
;
AssignStmt:
T_Identifier '=' Expr ';' { out_asm("\tpop %s", $1); }
;
CallStmt:
CallExpr ';' { out_asm("\tpop"); }
;
IfStmt:
If '(' Expr ')' Then '{' Stmts '}' EndThen EndIf
{ /* empty */ }
| If '(' Expr ')' Then '{' Stmts '}' EndThen T_Else '{' Stmts '}' EndIf
{ /* empty */ }
;
If:
T_If { _BEG_IF; out_asm("_begIf_%d:", _i); }
;
Then:
/* empty */ { out_asm("\tjz _elIf_%d", _i); }
;
EndThen:
/* empty */ { out_asm("\tjmp _endIf_%d\n_elIf_%d:", _i, _i); }
;
EndIf:
/* empty */ { out_asm("_endIf_%d:", _i); _END_IF; }
;
WhileStmt:
While '(' Expr ')' Do '{' Stmts '}' EndWhile
{ /* empty */ }
;
While:
T_While { _BEG_WHILE; out_asm("_begWhile_%d:", _w); }
;
Do:
/* empty */ { out_asm("\tjz _endWhile_%d", _w); }
;
EndWhile:
/* empty */ { out_asm("\tjmp _begWhile_%d\n_endWhile_%d:",
_w, _w); _END_WHILE; }
;
BreakStmt:
T_Break ';' { out_asm("\tjmp _endWhile_%d", _w); }
;
ContinueStmt:
T_Continue ';' { out_asm("\tjmp _begWhile_%d", _w); }
;
ReturnStmt:
T_Return ';' { out_asm("\tret"); }
| T_Return Expr ';' { out_asm("\tret ~"); }
;
PrintStmt:
T_Print '(' T_StringConstant PrintIntArgs ')' ';'
{ out_asm("\tprint %s", $3); }
;
PrintIntArgs:
/* empty */ { /* empty */ }
| PrintIntArgs ',' Expr { /* empty */ }
;
Expr:
T_IntConstant { out_asm("\tpush %s", $1); }
| T_Identifier { out_asm("\tpush %s", $1); }
| Expr '+' Expr { out_asm("\tadd"); }
| Expr '-' Expr { out_asm("\tsub"); }
| Expr '*' Expr { out_asm("\tmul"); }
| Expr '/' Expr { out_asm("\tdiv"); }
| Expr '%' Expr { out_asm("\tmod"); }
| Expr '>' Expr { out_asm("\tcmpgt"); }
| Expr '<' Expr { out_asm("\tcmplt"); }
| Expr T_Ge Expr { out_asm("\tcmpge"); }
| Expr T_Le Expr { out_asm("\tcmple"); }
| Expr T_Eq Expr { out_asm("\tcmpeq"); }
| Expr T_Ne Expr { out_asm("\tcmpne"); }
| Expr T_Or Expr { out_asm("\tor"); }
| Expr T_And Expr { out_asm("\tand"); }
| '-' Expr %prec '!' { out_asm("\tneg"); }
| '!' Expr { out_asm("\tnot"); }
| ReadInt { /* empty */ }
| CallExpr { /* empty */ }
| '(' Expr ')' { /* empty */ }
;
ReadInt:
T_ReadInt '(' T_StringConstant ')'
{ out_asm("\treadint %s", $3); }
;
CallExpr:
T_Identifier Actuals
{ out_asm("\t$%s", $1); }
;
Actuals:
'(' ')'
| '(' _Actuals ')'
;
_Actuals:
Expr
| _Actuals ',' Expr
;
%%
int main(int argc, char *argv[]) {
init_parser(argc, argv);
yyparse();
quit_parser();
}
void init_parser(int argc, char *argv[]) {
if (argc < 2) {
file_error("Must provide an input source file!");
}
if (argc > 2) {
file_error("Too much command line arguments!");
}
char *in_file_name = argv[1];
int len = strlen(in_file_name);
if (len <= 2 || in_file_name[len-1] != 'c' \
|| in_file_name[len-2] != '.') {
file_error("Must provide an '.c' source file!");
}
if (!(yyin = fopen(in_file_name, "r"))) {
file_error("Input file open error");
}
char out_file_name[BUFSIZE];
strcpy(out_file_name, in_file_name);
out_file_name[len-1] = 'a';
out_file_name[len] = 's';
out_file_name[len+1] = 'm';
out_file_name[len+2] = '\0';
if (!(asmfile = fopen(out_file_name, "w"))) {
file_error("Output 'asm' file open error");
}
out_file_name[len-1] = 'i';
out_file_name[len] = 'n';
out_file_name[len+1] = 'c';
if (!(incfile = fopen(out_file_name, "w"))) {
file_error("Output 'inc' file open error");
}
}
void file_error(char *msg) {
printf("\n*** Error ***\n\t%s\n", msg);
puts("");
exit(-1);
}
char *cat_strs(char *buf, char *strs[], int strc) {
int i;
strcpy(buf, strs[0]);
for (i = 1; i < strc; i++) {
strcat(strcat(buf, ", "), strs[i]);
}
return buf;
}
#define _fn (cur_func_name)
void write_func_head() {
char buf[BUFSIZE];
int i;
out_asm("FUNC @%s:", _fn);
if (argc > 0) {
out_asm("\t%s.arg %s", _fn, cat_strs(buf, args, argc));
}
if (varc > 0) {
out_asm("\t%s.var %s", _fn, cat_strs(buf, vars, varc));
}
out_inc("; ==== begin function `%s` ====", _fn);
out_inc("%%define %s.argc %d", _fn, argc);
out_inc("\n%%MACRO $%s 0\n"
" CALL @%s\n"
" ADD ESP, 4*%s.argc\n"
" PUSH EAX\n"
"%%ENDMACRO",
_fn, _fn, _fn);
if (argc) {
out_inc("\n%%MACRO %s.arg %s.argc", _fn, _fn);
for (i = 0; i < argc; i++) {
out_inc("\t%%define %s [EBP + 8 + 4*%s.argc - 4*%d]",
args[i], _fn, i+1);
}
out_inc("%%ENDMACRO");
}
if (varc) {
out_inc("\n%%define %s.varc %d", _fn, varc);
out_inc("\n%%MACRO %s.var %s.varc", _fn, _fn);
for (i = 0; i < varc; i++) {
out_inc("\t%%define %s [EBP - 4*%d]",
vars[i], i+1);
}
out_inc("\tSUB ESP, 4*%s.varc", _fn);
out_inc("%%ENDMACRO");
}
}
void write_func_tail() {
int i;
out_asm("ENDFUNC@%s\n", _fn);
out_inc("\n%%MACRO ENDFUNC@%s 0\n\tLEAVE\n\tRET", _fn);
for (i = 0; i < argc; i++) {
out_inc("\t%%undef %s", args[i]);
}
for (i = 0; i < varc; i++) {
out_inc("\t%%undef %s", vars[i]);
}
out_inc("%%ENDMACRO");
out_inc("; ==== end function `%s` ====\n", _fn);
argc = 0;
varc = 0;
}
void quit_parser() {
fclose(yyin); fclose(asmfile); fclose(incfile);
}词法分析文件 scanner.l 不变,和之前 1.0 版的相同。
将以上 scanner.l, parser.y, test.c 三个文件放在同一目录,输入以下命令生成 TinyC 前端 tcc-frontend :
flex scanner.l
bison -vdty parser.y
gcc -o tcc-frontend lex.yy.c y.tab.c再输入:
./tcc-frontend test.c
将利用 tcc-frontend 编译 test.c ,生成 Pcode 文件 test.asm 以及宏文件 test.inc 。对比一下前面的 test.pcode 和 test.funcmacro 文件,二者几乎是一模一样的。
2、TinyC 编译器
现在可以将 TinyC 前端和 TinyC 后端整合起来了。新建一个空的 tinyc 目录,然后 cd 到此目录,之后新建一个 sources 目录,然后将以下 7 个文件放到 sources 目录下:
scanner.l , 词法分析文件,和上一节相同;
parser.y , 语法分析文件,和上一节相同;
pysim.py , Pcode 模拟器( python 程序),和第 4 章相同;
tio.c , 库函数文件,和上一章最后一节相同;
macro.inc , NASM 宏文件,和上一章最后一节相同;
tcc , 编译 TinyC 源程序的脚本文件;
pysimulate , 模拟运行 Pcode 的脚本文件。
然后在 tinyc 目录下新建一个脚本文件 build.sh ,内容如下:
mkdir -p release
flex sources/scanner.l
bison -vdty sources/parser.y
gcc -o release/tcc-frontend lex.yy.c y.tab.c
rm -f y.* lex.*
gcc -m32 -c -o tio.o sources/tio.c
ar -crv release/libtio.a tio.o > /dev/null
rm -f tio.o
cp sources/macro.inc sources/pysim.py sources/tcc sources/pysimulate release/
chmod u+x release/tcc release/pysimulate
export PATH=$PATH:$PWD/release
echo "export PATH=\$PATH:$PWD/release" >> ~/.bashrc在终端输入 source build.sh 将编译生成 TinyC 前端 tcc-frontend 、库文件 libtio.a ,并放在 release 目录下,同时将 macro.inc, pysim.py, pysimulate, tcc 这四个文件拷贝至 release 目录,最后,将 release 目录输出到 PATH 环境变量中。现在,在终端输入 tcc filename.c 就可以利用 TinyC 编译成可执行程序了,而输入 pysimulate filename.asm -da 则可以用 Pcode 模拟器单步调试中间代码 Pcode 了。
让我们来测试一下第一章的示例代码 test.c 吧,将其放在当前目录,然后在终端输入 tcc test.c ,将生成一个 test-c-build 目录,此目录中包含了中间代码文件 test.asm 、函数定义宏文件 test.inc 、目标文件 test.o 、最终的可执行文件 test 。可以输入 test-c-build/test 来运行可执行文件,也可以输入 pysimulate test-c-build/test.asm -da 用 Pcode 模拟器单步调试中间代码。
脚本文件 tcc 首先调用 tcc-frontend 将输入文件(假设为 test.c )编译为 test.asm 和 test.inc ,然后调用 nasm ,将 test.asm 、 test.inc 和 macro.inc 三个文件一起汇编成 test.o ,最后调用 ld 将 test.o 和 libtio.a 一起链接为最终的可执行程序 test 。 tcc 的内容如下:
#!/usr/bin/env bash
if [ $# != 1 ];
then
echo "Usage: $0 <filename>"
exit 1
fi
if ! [ -f $1 ];
then
echo "Error: File $1 does NOT exists."
exit 1
fi
tccdir=$(dirname $0)
filename=${1%.*}
fileext=${1##*.}
objdir=$filename-$fileext-build
"$(dirname $0)/tcc-frontend" $1
nasm -f elf32 -P"$tccdir/macro.inc" -P"$filename.inc" -o "$filename.o" "$filename.asm"
ld -m elf_i386 -o "$filename" "$filename.o" -L"$tccdir" -ltio
mkdir -p "$objdir"
mv "$filename.asm" "$filename.inc" "$filename.o" "$filename" "$objdir/"脚本文件 pysimulate 将调用 python 和 pysim.py 文件,模拟运行输入的 Pcode 文件,其内容如下:
#!/usr/bin/env bash
if [[ ($# != 1) && ($# != 2) ]];
then
echo "Usage: $0 <filename> [-da]"
exit 1
fi
if ! [ -f $1 ];
then
echo "Error: File $1 does NOT exists."
exit 1
fi
python "$(dirname $0)/pysim.py" $1 $2下面来测试一下测试文件包 samples.zip ,将其解包至 samples 目录,再在当前目录新建一个脚本文件 testall.sh ,内容如下:
for src in $(ls samples/*.c)
do
filename=${src%.*}
fileext=${src##*.}
filenakedname=${filename##*/}
objdir=$filename-$fileext-build
clear
echo build \"$src\" and run
echo
tcc "$src"
"$objdir/$filenakedname"
echo
echo press any key to continue...
read -n 1
done最后在终端输入 bash testall.sh 将对所有文件进行编译、运行。
至此 TinyC 编译器全部完成。
参考文章:
https://www.zhihu.com/question/36756224
https://www.bilibili.com/video/BV1L7411C7K1/vd_source=aa1904eca5bee8c0d2763e8dfa898770
https://study.163.com/course/introduction.htm?courseId=1002830012#/courseDetail?tab=1
https://pandolia.net/tinyc/ch1_overview.html
https://llvm.org/docs/tutorial/MyFirstLanguageFrontend/index.html
https://book.douban.com/subject/6109479/
https://www.cnblogs.com/clover-toeic/p/3755401.html
CS143: Compilers
GitHub - westes/flex: The Fast Lexical Analyzer - scanner generator for lexing in C and C++
The GNU Operating System and the Free Software Movement
自己动手用java写编译器 - 网易云课堂
【教程】从零开始,写个编译器! - 知乎
北京大学编译实践课程在线文档
有限状态自动机FA_ailx10的博客-CSDN博客
词法分析 | 有限状态自动机(FA) - 知乎
编译原理 - 网易云课堂
First集、Follow集、Predict集的简单求法 三个重要集合_ammmme的博客-CSDN博客
FIRST集与FOLLOW集白话版_苏木George的博客-CSDN博客
[编译原理] 期末复习,求FIRST集和FOLLOW集。简单易懂,例题讲解。_first集和follow集例题_所念皆星河73的博客-CSDN博客
通俗易懂LL(1)判别方法_ll1_W.J.Z的博客-CSDN博客
安装Flex在Linux系统上的指南(安装flex linux)-数据库远程运维
configure: error: no acceptable m4 could be found in $PATH_checking for gnu m4 that supports accurate traces._xie_jw的博客-CSDN博客
http://ftp.gnu.org/gnu/m4/m4-1.4.9.tar.gz
linux系统安装bison,解决 These critical programs are missing or too old: bison compiler - 编程之家
https://www.cnblogs.com/san-fu-su/p/4089041.html


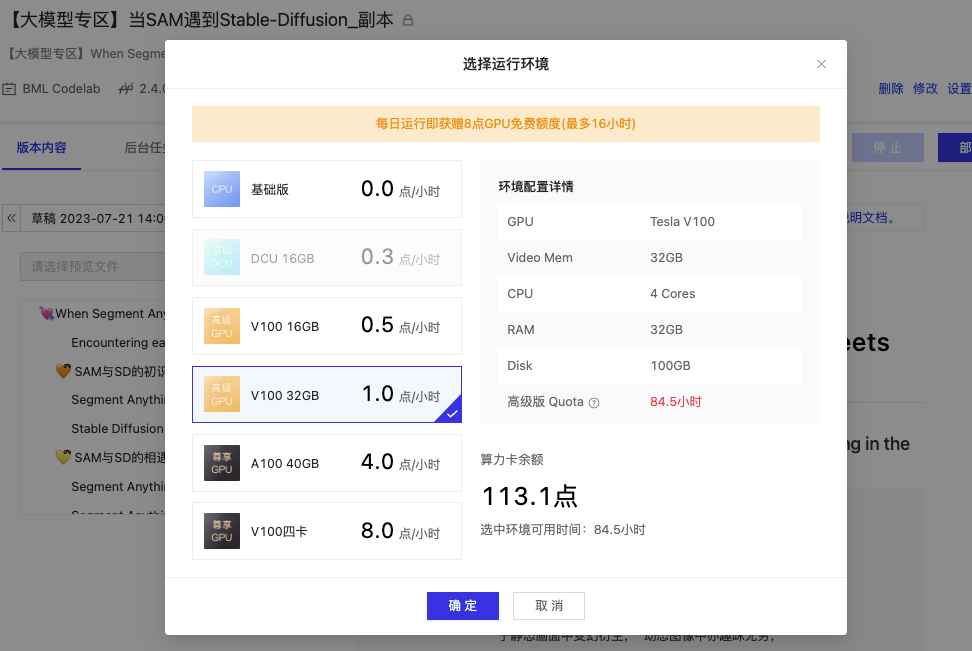
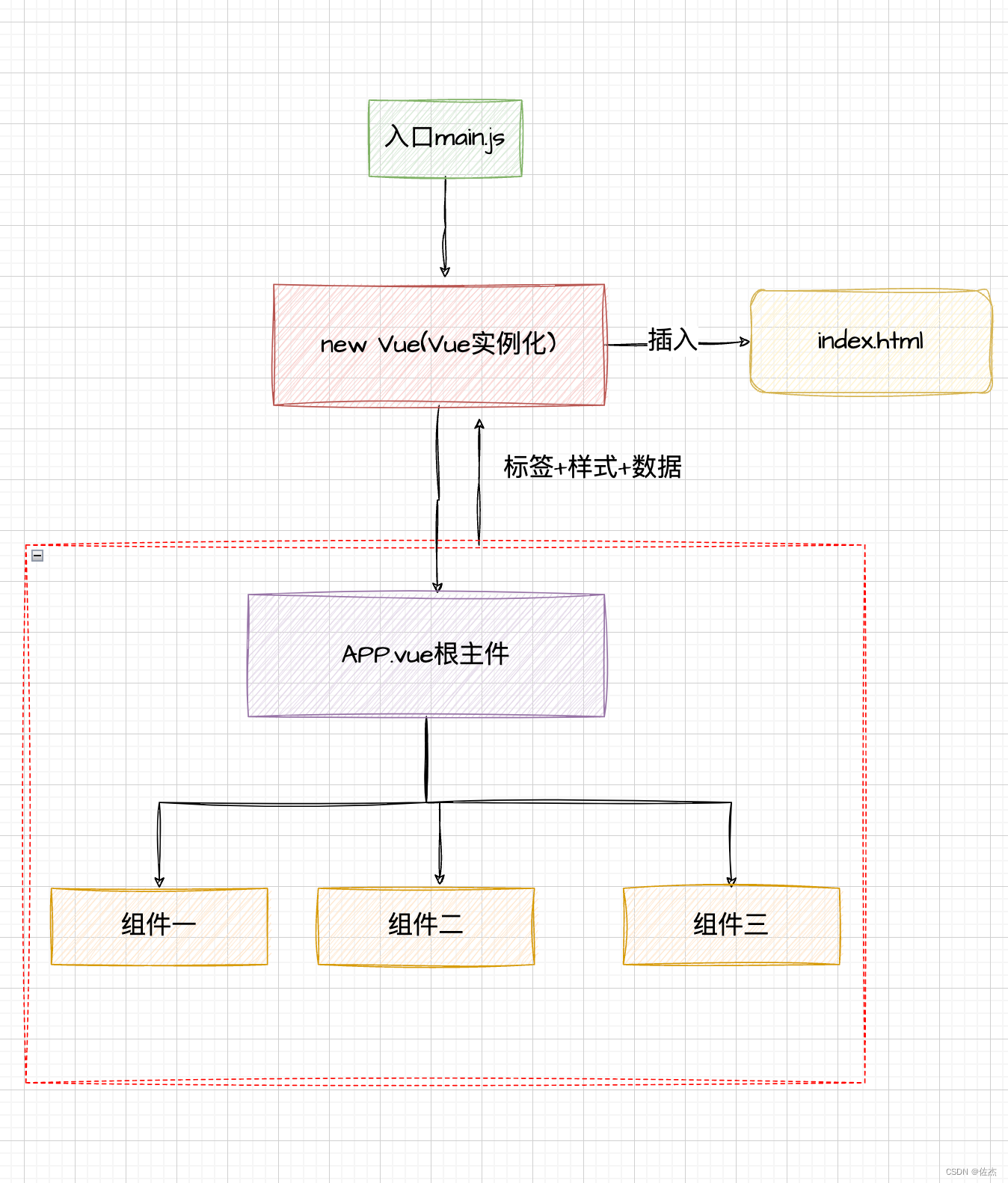






![[回馈]ASP.NET Core MVC开发实战之商城系统(二)](https://img-blog.csdnimg.cn/img_convert/46ea527c059d8e3a208bbe2d58a84c9d.png)